一种基于启发式优化算法的车间资源调度方法与流程
本发明涉及智能车间资源排产调度技术领域,特别是一种基于多目标约束条件的基于启发式优化算法的车间资源调度方法。
背景技术:
作业车间调度(jobshopschedulingproblem,jsp)是车间调度中最常见的调度类型,是最难的组合优化问题之一,应用领域极其广泛,涉及航母调度,机场飞机调度,港口码头货船调度,汽车加工流水线等,因此对其研究具有重大的现实意义。科学有效的生产调度不但可以提高生产加工过程中工人、设备资源的高效利用,还可缩短生产周期,降低生产成本。
作业车间调度问题是一种满足任务配置和顺序约束要求的资源分配问题,是最困难的组合优化问题之一,同时也视为排序问题。一般说来,不同的任务在只能使用有限的资源条件下要完成,都可以归为排序问题。当然,调度不只是排序,它还根据这个排序,确定任务的开始时间和结束时间。随着工业生产过程的日益复杂与规模的大型化,要求计算机系统不仅要完成直接面向过程的控制和优化,而且要在获取生产全部过程信息基础上,进行指挥调度和综合管理。敏捷制造执行系统是面向敏捷车间的先进生产管理系统,调度及其策略作为其核心功能,也是当前研究的重要内容。有效的生产调度方法和优化技术的研究和应用是实现先进制造和提高生产效益的基础和关键。良好的生产调度能够预先解决生产中的干扰,能够缩短产品在车间的流动时间,减少在制品库存,保证准时交货。因此,对离散车间的调度问题越来越受到关注。
因为在实际的车间生产中,作业调度是具有代表性的组合优化问题之一,属于np-hard问题,由于其解空间属于海量的级别,海量级别的可行解对应着海量的计算,所以一般的解法是无法有效地获得较优秀的可行解的。目前人工排产存在以下几个问题需要解决:能胜任排产岗位的企业工人屈指可数;排产任务复杂超乎想象,单凭个人能力只能实现小范围排产;每一次排产作业都是一项巨大工程。对于大型企业来说迫切需要通过计算机来实现作业排产任务,减轻排产作业人员压力,提高排产准确性。
技术实现要素:
本发明所要解决的技术问题是针对现有技术中车间资源调度问题,提出了一种基于启发式优化算法的车间资源调度方法,该方法不仅能够有效降低资源调度的截止时间违约率,还能节约车间成本,缩短平均任务执行时间。
本发明所要解决的技术问题是通过以下的技术方案来实现的。本发明是一种基于启发式优化算法的车间资源调度方法,其特点是:该方法采用如下步骤实现车间排产:
(1)接收输入的数据,并将数据输入到算法中;
(2)设置好约束条件,用来筛选输出结果;
(3)算法对接收的数据进行运算并输出结果;
算法支持多种约束条件输入,约束条件是众多排产结果的筛选器,将最符合约束条件的结果挑选出来;约束条件包括:最少等待时间、最少超期任务、优先级优先和强制保障优先;其中约束条件都是数字量,取值范围1至5,默认值为3,值越大越优先考虑对应的因子,越小越不重视对应的因子。
本发明所述的一种基于启发式优化算法的车间资源调度方法,其进一步优选的技术方案是:步骤(2)具体包括以下操作:
1.1接口通信协议构建:对整体划分为若干模块,即资源模块,能力模块,任务模块,资源效率模块,以及资源的依赖关系和资源可用模块;获取的数据有生产需要的任务、任务之间的依赖关系、可用的资源、资源的效率及资源的可用时间;对以上数据进行有效且合理的方式进行组合,通过确定的协议进行数据的传输;
1.2.编码:对输入的数据进行编码,染色体的长度为所有工序之和,其中的任一元素是从1到任务数之间的一个随机数,该数字第几次出现表示它所代表的任务的第几道工序;采用在离散资源加工系统具备多重加工能力的基础上,结合基于工序的编码方法,将任务、工序、能力和资源进行融合,根据任务在编码中出现的下标序数,确定该任务加工的工序,最后在相应的设备集中选择设备作为该码字的设备编码;
1.3解码:从左往右解码一个染色体序列,一个长度为n的染色体,从左至右元素依次为1、2、3......n/2、1、2、3、......n/2、n/2-1、n/2-2……2、1;它表示的是:第一个元素为1,表示任务1的第一道工序;然后再以第n/2+1个元素1为例,它表示任务1的第二道工序,后面依次重复;
1.4.初始化种群:采用模糊聚类分析的方法将加工数据分成多个类或者簇,按照“最小化类间相似性,最大化类内相似性”原则,使各个类之间的数据差别应尽可能的大,类内之间的数据应尽可能的小,筛选出这些异常特征数据,并进行相应的有效处理;处理完毕之后,接着产生一个若干个个体大小的种群,每一个个体用一条染色体表示,即表示一个可行的资源调度;
1.5适应度计算:适用度函数将最少等待时间、最少超期任务、优先级优先和强制保障四个约束条件进行综合考虑,并对四个约束条件在参数上设置不同的权重值,其权重值得取值范围1至5;每个染色体的适应度值代表着该染色体的优势排名;
1.6.选择:在每一个连续的父代和子代中,子代继承父代的部分染色体,然后基于子代的适应度值来选择新产生的个体,并按照适应度进行排序,排名越靠前也就是适应度越大的个体被选中的概率越大;使用基于粒子群算法的精英策略来选择交叉和变异步骤所需的候选染色体:首先根据建立的种群,将单个染色体作为粒子,开始粒子的寻优迭代,接着对粒子最优位置以及粒子群的最优位置进行计算并对结果进行分析,最后找出符合预期的个体;
1.7交叉和变异:采用顺序交叉算子,第一步,从上一步选择的一对染色体中随机选出基因的起止位置;第二步,生成一个子代并保证子代中被选中的基因位置与父代相同;第三步,先找出第一步选中的基因在另一个父代中的位置,再将其余基因按顺序放入上一步生成的子代中。
以上所述的一种基于启发式优化算法的车间资源调度方法,其进一步优选的技术方案是:步骤1.7中,变异是为了能跳出局部最优解,根据变异概率进行染色体的变异,采用如下方式来构建变异操作:
(1)依据变异概率确定需要产生的子代个体的个数;
(2)随机选择种群中的某一个体作为变异个体;
(3)随机产生一个在机台数量范围之内的随机数表示选取的一个机台;
(4)再产生2个在机台加工数量范围之内的随机数作为同机台等基因的变异点,将2个变异点的基因进行互换,产生新的子代个体;重复前述步骤(2)~(4),直至产生所有子代个体。
与现有技术相比,本发明具有以下有益效果:
1、本发明方法对提交的数据,通过使用遗传算法对数据进行处理,再一定的约束条件下(如最少等待,最少超期等)得到一组局部最优的解;
2、本发明可以克服现有人工排产中存在的问题和缺陷,在启发式算法的研究基础上,综合运用,以达到提高交货时间精确,减少耗费的资源,提高投资回报率,减少企业指定生产计划所需要的时间,提高企业的生产效率。
3、本发明方法中采用的算法对求解作业车间调度问题具有较好的效果,系统通过模拟生物进化,包括遗传、突变、选择等,来不断地产生新个体,并在算法终止时求得最优个体,即最优解。
(1)采用启发式算法来生成生产计划大幅减少了制定生产计划所花费的时间,提高了企业对新订单的快速反应能力;
(2)算法的精确性保证了生产计划的准确性,降低了企业因制定生产计划出现错误而不得不遭受的损失;
(3)由于aps系统精确制订了相应的生产计划,物料信息是精确的,制定计划的完成时间是根据产品的交付日期而定的,生产的产品一般可以直接交货而不需要入库保存,所以可以大幅降低原材料和制成品的库存压力;
(4)优化了企业对生产资料的利用,基本上消除了停工期,将延期交货的可能性降到最低;
(5)管理人员只需要按一定的格式输入加工信息和生产资料信息就可以迅速制定生产计划,大幅降低了企业制定生产计划的难度和工作量,降低了企业的人力。
4、本发明在初始化种群时使用了模糊聚类分析的方法对数据进行预处理,一定程度上降低了算法的运行时间,提升了运算结果质量,摆脱了算法对初始种群的选择所具有的一定的依赖性。本发明在选择染色体使用粒子群算法结合精英策略的方法选择操作的染色体,克服了早熟的问题,增强了算法对解空间的探索能力。本发明稳定性更强,不需要多次运行算法,结果可靠性更强,通常可以稳定的得到符合预期结果的解。对于最终的非线性约束,采用预设权重值的方式,较少了对参数的依赖。
附图说明
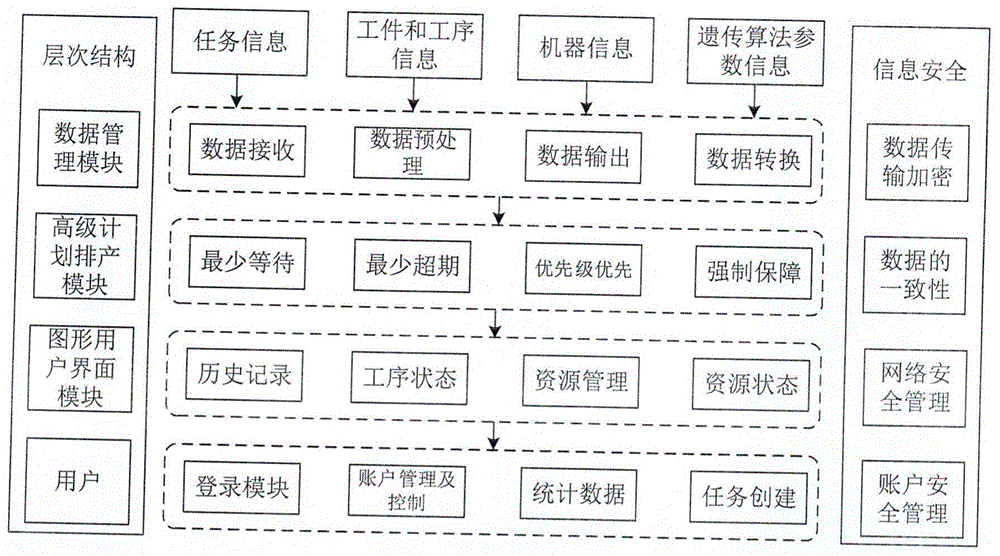
图1排产算法功能结构图;
图2算法运算及择优流程图。
具体实施方式
为了体现本发明的技术方案以及其相对于传统方案的优点,以下结合附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
下面结合附图对本发明的具体实施作进一步的详细阐明。
实施例:
基于启发式优化算法的车间资源调度方法,其结构图如图1所示,包括输入运算数据,运算和输出结果三个部分。
为了克服实际任务过程中存在的复杂情况,发明人通过使用启发式优化算法结合贪心算法进行任务择优,以达到输出一个符合约束条件的解的目的,采用如下步骤实现对车间资源的排产:
步骤01.接收输入的数据,并将数据输入到算法中。
步骤02.设置好约束条件,用来筛选输出结果。
步骤03.算法对接收的数据进行运算并输出结果。
所述步骤02具体描述为以下:
算法支持多种约束条件输入,约束条件是众多排产结果的筛选器,将最符合约束条件的结果挑选出来。
约束条件包括:最少等待时间(指两个任务之间的间隔时间总和最小,呈现的结果是排列紧密)、最少超期任务(指进入排产的作业任务,超期任务的总数最小)、优先级优先(指在同等交货期或者相差较小范围内,优先安排任务优先级高的任务)、强制保障优先(指有些任务具有时效性,超过最迟完成时间则任务没有意义,那么排产算法必须优先保障这类的任务。如有些工序使用的材料只能保存10天)。
其中约束条件都是数字量,取值范围1至5,默认值为3,值越大越优先考虑对应的因子,越小越不重视对应的因子。
所述步骤03如图2所示,具体描述为以下:
1.编码
本发明采用的是在离散资源加工系统具备多重加工能力的基础上,结合基于工序编码方法,将任务、工序、能力和资源进行有机融合,采用这种二维编码的方法,有效地减少了算法的运行时间和空间。首先根据任务在编码中出现的下标序数,确定该任务加工的工序,最后在相应的设备集中选择设备作为该码字的设备编码。
2.初始化种群
由于实际生产过程中较为复杂,拿到的数据往往具有异常数据或者无效数据。为了提升预算的运行效率并得到一个符合预期的结果,本发明采用模糊聚类分析的方法将加工数据分成多个类或者簇,按照“最小化类间相似性,最大化类内相似性”原则,使各个类之间的数据差别应尽可能的大,类内之间的数据应尽可能的小,筛选出这些异常特征数据,并进行相应的有效处理。例如资源r加工任务a需要3个单位时间,而加工任务b需要30个单位时间,两者间花费时间为10倍,考虑其可能为异常数据,使用非异常资源进行加工。预处理完毕之后,接着产生一个若干个个体大小的种群,每一个个体用一条染色体表示,即表示一个可行的资源调度。
3.适应度计算
本发明的适用度函数将最少等待时间、最少超期任务、优先级优先和强制保障四个约束条件进行综合考虑,并对四个约束条件在参数上设置不同的权重值,其权重值得取值范围1至5,默认值为3,值越大越优先考虑对应的因子,越小越不重视对应的因子。设fitness为对应个体的适应度,fulfilltime为最短加工时间,outnum为最小超期任务,priority为优先级优先,对于强制保障则采用优先级高的必须强制优先完成。其适应度函数为,其中wg1,wg2,wg3分别为最短加工时间的权重,最小超时的权重及优先级优先的权重。
下面以最短时间计算为例进行说明从左到右遍历个体的染色体序列w1,w2,…,wi,。。。,wn,其中wi表示第i个作业任务的编码,则wi对应的当前工序
而第m台机器的加工时间为:
machineworktimem=starttimew,p+t
作业任务wi的第p道工序的结束时间为:
endtimem=starttimew,p+t
最后加工完所有工件的最短加工时间fulfilltime为:
在机器选择过程中使用局部贪心算法,在进行wi工序选择对应的资源机器进行处理,在有处理该工序的集合中进行选择,找出当前机器生产时间较小的作为当前工序的处理机器,选择公式如下:
车间调度执行的顺序是按染色体编码序列的顺序从左向右执行,由调度问题的执行位置和染色体编码序列可知要加工作业的任务号i,然后通过任务号在染色体序列的当前位置获得该任务所在的工序号j,由作业任务号和工序号从二维数组machinematrix[][]和timematrix[][]获得第i个作业任务的第j道工序所使用的机器号和所耗费的时间,然后更新第i个作业任务第j道工序的开始时间为第i个作业任务第(j-1)道工序的结束时间或该工序将要使用机器的最近空闲时间点的之中的较大者,更新第i个工件第j道工序的结束时间为该工序的完工时间,即开始时间与加工时间之和,更新该工序所使用机器的最近空闲时间点为第i个任务第j道工序的加工完成时间。如果该工序的完工时间大于当前的最大完工时间,更新最大完工时间的值,直至染色体序列中的所有工序至所有工序被加工完毕,最终可以获得完成车间调度所需的最大完工时间。
相应的计算出最小超期任务数量、优先级优先的加权数后通过上述计算适应度的函数计算出适应度。
4.选择
在每一个连续的父代子代中,父代染色体的一部分被继承来产生新的一代,然后基于子代的适应度值来选择新产生的个体,适应度越大的个体越有可能被选中,本发明使用基于粒子群算法的精英策略来选择交叉和变异步骤所需的候选染色体。首先根据建立的种群,将单个染色体作为粒子,开始粒子的寻优迭代,接着对粒子最优位置以及粒子群的最优位置进行计算并对结果进行分析,最后找出符合预期的个体。所谓的精英策略就是适应度越大的个体被选中的可能性越大。精英策略避免了优秀基因的损失,保证了种群朝着更高的质量进行进化,而轮盘赌策略有效地防止了求解陷入了局部最优化的陷阱,两者相辅相成,加速了种群的迭代和有效解的产生。
5.交叉和变异
该步骤用来产生新的个体,将两个待交叉的不同的染色体根据交叉概率按一定的方式交换其部分基因。本发明对三种交叉算子进行测试:顺序交叉(ox)、循环顺序交叉(cox)、混合顺序交叉(mox)和两种变异算子:逆转变异(obm)、互换变异(sbm),最终采用效率高、效果好的顺序交叉算子来对染色体进行交叉。
染色体按照变异概率进行染色体的变异,变异的作用主要是使算法能跳出局部最优解,因此不同的变异方式对算法能否求得全局最优解有很大的影响。与交叉操作类似,如果随机将染色体中基因变异成基因可取范围内的其它值,会破坏染色体的稳定性,并且产生非法解。所以为了保证染色体的稳定性,可采用如下方式来构建变异操作,设计步骤流程可表述如下:
(1)依据变异概率确定需要产生的子代个体的个数。
(2)随机选择种群中的某一个体作为变异个体。
(3)随机产生一个在机台数量范围之内的随机数表示选取的一个机台。
(4)再产生2个在机台加工数量范围之内的随机数作为同机台等基因的变异点,将2个变异点的基因进行互换,产生新的子代个体。
重复步骤(2)~(4),直至产生所有子代个体。
6.停止条件和解码
当程序的总运行时间达到给定上限或者种群进化的次数达到200次时,程序停止运行,然后本发明从左往右解码一个染色体序列,下面一个长度为6的染色体为例来说明解码规则。该染色体从左至右元素依次为1、2、3、1、2、3、2、1。它表示的是:第一个元素为1,表示任务1的第一道工序。然后再以第4个元素1为例,它表示任务1的第二道工序,后面依次重复。
- 还没有人留言评论。精彩留言会获得点赞!