基于关系视觉注意机制的场景图产生方法与流程
本发明属于计算机视觉领域,特别涉及一种场景图产生方法,可用于图像描述与视觉问答任务。
背景技术:
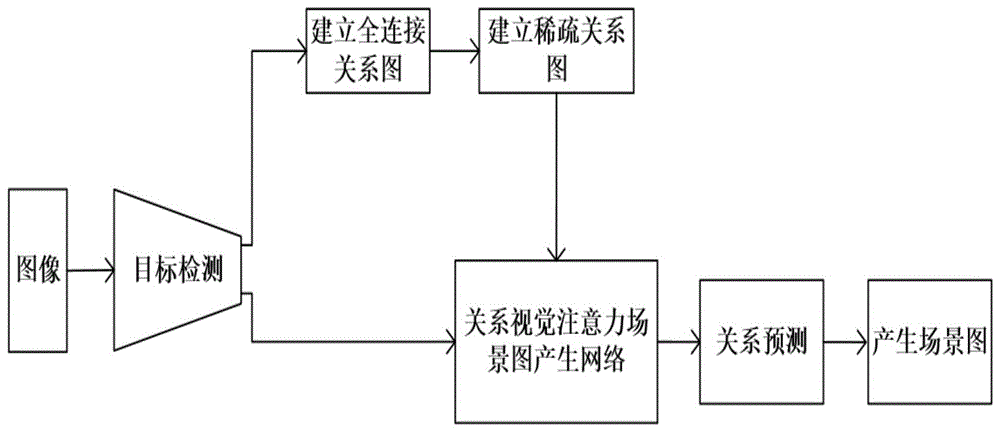
:随着深度学习的发展,目前计算机对于图像的理解已经达到新的高度。从目标检测到语义分割,再到实例检测,计算机视觉已经取得非常大的进步。但对于更深层次的图像理解仍然有许多问题。由于图像中的目标间关系并不是独立存在的,目标检测等任务并不能掌握实例间的关系,比如人背着包与人拿着包,虽然通过目标检测出的类别可能相同,但是他们之间的关系类别是不同的。为了使计算机进一步像人类一样理解图像,johnsn等人提出了场景图任务。并提供了一种场景图的评估方法。简单来说,场景图任务用于产生两目标间的关系。不仅需要检测出图中包含的目标,而且需要能够推理出目标间的关系。在此基础上,进一步可以将场景图的结果运用于更高层级图像理解任务。场景图任务是将图像映射到一组关系的拓扑结构中,它在目标检测任务的基础上,对图像中复杂多样的目标间关系进行检测。随着深度学习的发展,尽管在图像分类,目标检测方面取得了很大的进展,但是对图像的认知不能仅仅满足于识别图像,需要进一步去理解图像中丰富的语义信息。并且其关系不受实例的图像特征,类别变换影响,很难仅根据提取到的实例信息掌握目标间存在的关系特征。早期,人们将不同的短语视为单独的一类,这样会导致类别数很大,学习困难。所以,现在更多将每一种谓词作为一类,尽管主宾的类别不同,但在对关系进行预测时可以从数据集中获取大量的先验信息。目前,产生场景图的方法是:先通过目标检测得到目标框,再提取框内特征进行信息传递与更新,最后进行关系的分类。具体方法可分为两种:第一种是对检测出的关系进行两两组合,并在交互信息时只利用两两组合的目标特征,即先通过目标检测,检测出图像中存在的所有目标;再通过建立一个信息传递网络,对一个关系中的主语、宾语进行特征交互与更新;最终利用特征进行关系的分类。第二种是首先利用目标检测出的所有目标,通过lstm或self-attention机制,将所有目标对应的图像特征作为输入,进行所有目标特征的同时更新;然后将特征两两组合进行关系分类。上述两种方法由于都没有建立一个合适的注意力机制,使得网络用于最终分类关系的特征没有真正的关注于两目标发生关系的区域,导致网络的可解释性较差。技术实现要素:本发明目的在于针对上述现有技术的不足,提供一种基于关系视觉注意机制的场景图产生方法,以将冗余关系检测与最终用于分类的特征关注于图像的合理区域,提高网络的可解释性。为了达到上述目的,本发明采用的技术方案包括如下步骤:(1)输入包含k张图像和标签集合y的数据集x,利卷积神经网络vgg16得到k张图像的特征集合:s={s1,s2,...,si,...,sk},其中si是第i张图像的特征,i∈{1,2,...,k};(2)对(1)中的特征集合s进行目标检测,得到目标类别l,目标框b与目标特征t:l={l1,l2,...,li,...,lk},b={b1,b2,…,bi,…,bk},t={t1,t2,…,ti,…,tk},其中:为第i张图像中目标类别集合,为第i张图像中目标框集合,为第i张图像中目标特征集合;和分别表示第i张图像中第j个目标的类别、目标框和特征,j∈{1,2,...,n},n为图像中目标的数量;(3)将目标特征集合ti中的每个元素作为节点,并对这些节点进行两两连接,建立全连接关系图gi;(4)根据(2)中得到的第i张图像的目标类别集合li和目标框集合bi,对全连接关系图gi进行稀疏化,建立稀疏关系图g′i;(5)将稀疏关系图g′i中每一条边相连的两个节点分别标记为主语节点和宾语节点,构建稀疏关系图g′i中所有边的主宾对集合:ri={(s1,o1),(s2,o2),...,(se,oe),...,(sm,om)},其中se表示稀疏关系图g′i中第i条边的主语节点,oe表示稀疏关系图g′i中第i条边的宾语节点,m为稀疏关系图gi′中边的条数,e∈{1,2,...,m};(6)利用主宾对集合ri中的每个元素(se,oe)和目标框集合bi中对应的目标框得到并集特征ue,并建立关系集合r′i={(s1,o1,u1),(s2,o2,u2),...,(se,oe,ue),...,(sm,om,um)};(7)对数据集x中的所有图像执行(3)-(6),得到数据集关系集合r:r={r′1,r′2,...,r′i,...,r'k},并将其划分为训练集rz与测试集rs,按照同样的划分方式将标签集合y划分为训练集标签集合yz与测试集标签集合ys;(8)构造基于关系视觉注意机制的场景图生成网络,其中,场景图生成网络包括主语关系注意力函数atts,宾语关系注意力函数atto,主语关系注意力转移函数fs→r和宾语注意力转移函数fo→r;(9)将(7)中训练集rz与训练集标签yz按批次进行划分,得到训练批次集合rb与标签批次集合yb:其中表示训练集rz的第h个批次,表示训练集标签yz的第h个批次,h∈{1,2,...,v},γ表示批次大小,|rz|表示训练集rz的数量,v表示批次数量;(10)按批次将输入到(8)构建的场景图生成网络中,生成关系预测总集合:p={p1,p2,...,pa,...,pγ},其中,pa为第a张图像的关系预测集合,表示第a张图像的第e个关系预测,a∈{1,2,...,γ};(11)根据pa和标签批次集合计算交叉熵损失:并通过随机梯度下降优化方法最小化交叉熵损失λ,得到训练好的场景图生成网络,其中,m表示批次中第a张图像的关系数量,标签批次集合ya表示第a张图像的标签集合,表示第a张图像的第j个关系的标签;(12)将测试集rs输入到(11)训练好的场景图生成网络中,生成测试集rs对应的关系预测集合ps,并根据该关系预测集合ps构造出场景图。与现有技术相比,本发明的有益效果是:1)本发明通过利用数据集中存在的先验信息与目标检测得到的目标类别信息、目标框信息,对全连接关系图进行稀疏化,并且在不减少准确率的情况下,可以在很大程度上去掉无效边,与现有方法相比,避免了对无效边的预测与特征冗余交互,提高了场景图分类评价指标与关系分类评价指标的准确率。2)本发明由于构建了基于关系视觉注意机制的场景图生成网络,并通过学习两个关系注意力转移函数,使得用于分类的特征真正关注于关系发生的区域,学习到准确的关系表征,相较于现有方法,本发明构造的场景图生成网络具有较强的可解释性。附图说明图1为本发明的实现流程图;图2为现有技术的目标检测结果图;图3为本发明中利用图2的目标检测结果产生的全连接关系图;图4为本发明中产生的稀疏关系图;图5为本发明中基于关系视觉注意机制的场景图生成网络;图6为用现有方法学习到的关系表征进行可视化产生的结果图;图7为输入的测试集图像;图8为产生的全连接关系图;图9为产生的稀疏关系图;图10为本发明最终产生的场景图。具体实施方式下面通过附图,对本发明的实施例和效果做进一步详细描述。本发明在注意力机制的基础上,结合场景图任务中产生每对关系需要有主语和宾语交互的特点,考虑发生关系的地方必定在两目标间有所接触或相接近的区域;在目标检测的基础上提出了关系注意力转移函数,通过交替迭代的学习关系注意力转移函数,使得最终不仅能够学习到较好的关系表征,并且该关系表征能够较好的对应于两目标真正发生关系的区域。其实施方案是先构建数据集的图像特征;获取目标类别,目标框与目标特征;再构造全连接关系图,并对进行稀疏化得到稀疏关系图;再构建关系对集合,构造并训练基于关系视觉注意机制的场景图生成网络,该网络包括,场景图生成网络包括主语关系注意力函数,宾语关系注意力函数,关系注意力转移函数和注意力转移函数;然后输入关系对集合,得到关系的分类结果;最终由各个目标作为节点,目标间的关系作为边,产生场景图。参照图1,本实施例的实现步骤如下:步骤1,获取图像特征。1.1)从公开网址下载coco数据集、imagegenome数据集、imagegenome数据集标签集合y和vgg16网络模型;1.2)利用coco数据集对vgg16网络模型进行训练:(1.2a)使用vgg16网络模型默认的初始学习率,并设置迭代次数d=3000,批次大小为8;(1.2b)将coco数据集按批次输入到vgg16网络模型中;(1.2c)利用批次随机梯度下降算法进行vgg16网络模型训练;(1.2d)重复执行(1.2b)-(1.2c),直到达到迭代次数,得到训练好的vgg16网络模型;(1.3)将包含k张图像的imagegenome数据集输入到训练好的vgg16网络模型中,得到k张图像的特征集合:s={s1,s2,…,si,…,sk},其中si是第i张图像的特征,i∈{1,2,...,k}。步骤2,进行目标检测。从公开网址下载训练好的faster-rcnn网络模型,将特征集合s输入到训练好的faster-rcnn网络模型中进行目标检测,得到目标类别l,目标框b与目标特征t,分别表示如下:l={l1,l2,…,li,...,lk},b={b1,b2,...,bi,...,bk},t={t1,t2,...,ti,...,tk},其中:为第i张图像中目标类别集合,为第i张图像中目标框集合,为第i张图像中目标特征集合;和分别表示第i张图像中第j个目标的类别、目标框和特征,j∈{1,2,...,n},n为图像中目标的数量,每个目标框由{{x1,y1,x2,y2}}四个坐标进行标注,如图2所示,其中目标框即根据四个坐标产生。步骤3,建立全连接关系图。将图2中的每个目标框标注出的目标作为节点,对这些节点进行两两连接作为边,得到全连接关系图gi,如图3所示,其中每条边表示目标间的关系。步骤4,建立稀疏关系图。4.1)从全连接关系图gi中取一条边e以及对应的两节点,将该边标记为已访问;4.2)判定为两节点是否存在关系:若两节点对应的目标框不存在交集,或两节点中没有作为一对关系中的主语、宾语出现过,则在全连接关系图gi中将边e去掉;否则,在全连接关系图gi中保留边e;4.3)重复4.1)-4.3)直到全连接关系图gi中每条边都标记为已访问,得到稀疏关系图g′i,如图4所示;对比稀疏关系图4与全连接关系图3可知,图4去掉的边即被认为两节点间不存在关系,不需要再进行检测。步骤5,获取主宾对集合。5.1)从稀疏关系图g′i取一条边e以及对应的两节点,将该边标记为已访问;5.2)对两节点进行主语和宾语标记,若节点对应的类别属于人这一类别时,则将该节点标记为主语,否则,标记为宾语;5.3)判断两节点的标记是否相同:若两节点标记相同,则每个节点分别被标记为一次主语和一次宾语,即边e产生两个主宾对;否则,边e产生一个主宾对;5.4)重复5.1)-5.3),直到稀疏关系图g′i中每条边都标记为已访问,得到主宾对集合ri。步骤6,获取并集区域特征。由于两个目标发生关系处肯定存在于两目标框的并集区域,所以只需要在并集区域特征内建立关系注意力机制即可学习到准确的关系表征;本实例利用主宾对集合ri中的每个元素(se,oe)和目标框集合bi中对应的目标框得到并集特征ue,并建立关系集合r′i,具体步骤如下:6.1)从主宾对集合r′i中取出一个主宾对(se,oe),标记该主宾对已访问;6.2)从目标框集合bi中取出与对应主宾对(se,oe)的两个目标框和6.3)计算两目标框和的并集框6.4)利用并集框对图像特征si进行roi-pooling操作,得到并集区域特征ue;6.5)重复6.1)-6.4)直到ri中的主宾对都被标记为已访问,得到关系集合ri′:r′i={(s1,o1,u1),(s2,o2,u2),...,(se,oe,ue),...,(sm,om,um)}。步骤7,得到数据集关系集合r。7.1)对imagegenome数据集中的所有图像执行步骤3-步骤6,得到数据集关系集合r:r={r′1,r′2,...,r′i,...,r'k},7.2)将关系集合r按照7:3的比例划分为训练集rz与测试集rs,按照同样的划分方式将imagegenome数据集中的标签集合y划分为训练集标签集合yz与测试集标签集合ys。步骤8,构造基于关系视觉注意机制的场景图生成网络。8.1)构造主语关系注意力函数atts和宾语关系注意力函数atto,该atts和atto各包括一个卷积层和内积操作,卷积层的卷积核大小为3×3,步长为1,特征映射图数目为512,atts输入为se,输出为主语关系注意力矩阵集合atto输入为oe,输出为宾语关系注意力矩阵集合8.2)构造主语关系注意转移函数fs→r和宾语注意转移函数fo→r,fs→r表示从主语转移到发生关系处,fo→r表示从宾语转移到发生关系处,这两个转移函数分别利用主语,宾语特征与并集特征学习不同的注意力转移机制,使得学习到的转移权重关注于发生关系处,其中,函数fs→r和fo→r各包括第一卷积层、第二卷积层、第三卷积层,滤波器尺寸分别为3,3,3,步长分别为1,1,1,特征映射图数目分别为512,512,512,fs→r函数的输入为(8.1)中的主语关系注意力矩阵集合输出为t+1时刻的主语转移表征集合fo→r函数的输入为(8.1)中的宾语关系注意力矩阵集合输出为t+1时刻的宾语转移表征集合8.3)将se和8.2)中得到的主语关系表征集合输入到atts,输出为宾语关系注意力矩阵集合将oe和8.2)中得到的宾语关系表征集合输入到atto,输出为主语关系注意力矩阵集合其中,t∈{1,2,...,t},t表示设定的迭代次数;8.4)执行8.2)-8.3)共t次,共产生t个迭代结果;8.5)对第t个迭代输出的两个结果先进行通道拼接操作,再进行卷积操作与池化操作,最后进行全连接操作,构成场景图生成网络,如图5所示。步骤9,进行批次划分。将训练集rz与训练集标签yz按批次进行划分,得到训练批次集合rb与标签批次集合yb:其中表示训练集rz的第h个批次,表示训练集标签yz的第h个批次,h∈{1,2,...,v},γ表示批次大小,|rz|表示训练集rz的数量,v表示批次数量;步骤10,得到关系预测。将训练集批次输入到(8)构建的场景图生成网络中,生成关系预测总集合:p={p1,p2,...,pa,...,pγ},其中,pa为第a张图像的关系预测集合,表示第a张图像的第e个关系预测,a∈{1,2,...,γ}。步骤11,对场景图生成网络进行训练。11.1)设置迭代次数d=20000,初始学习率lr=0.0001;11.2)根据预测结果集合p与标签批次集合计算交叉熵损失λ:其中,m表示批次中第a张图像的关系数量,pa表示第a张图像的预测集合;表示第a张图像的标签集合,表示标签批次集合中第a张图像的第j个关系的标签;11.3)通过随机梯度下降优化方法最小化交叉熵损失λ,更新场景图生成网络;11.4)重复11.1)-11.3),直到达到迭代次数d。步骤12,产生场景图。12.1)从测试集rs中抽取一个关系集合ri,并标记该关系集合为已访问;12.2)将关系集合ri输入到训练好的场景图生成网络中,得到关系预测12.3)利用关系预测与关系集合ri,构建拓扑结构并画出场景图;12.4)重复执行步骤12.1)-(12.3),直到测试集中所有的关系集合标记为已访问,得到测试集rs中所有关系集合的场景图,即最终的场景图。本发明的效果可通过以下仿真结果进一步说明。1.仿真条件仿真的硬件平台为一台hpz840工作站,其操作系统为ubuntu16.04,并搭载一块显存为12g的nvidia-tianxgpu;软件平台为cuda8.0、cudnn7.0和tensorflow1.10。仿真所使用的数据集为imagegenome数据集,数据集中包含108,007张图像,平均每张图像包含38个目标和33关系对。由于数据集标签的混淆,需要对数据集进行清理。清理后的数据集中的每张图像平均包含25个目标和22个关系对,本仿真只利用出现频率最高的150类实例和50类关系,最终,每张图像平均包含11.5个目标和6.2个关系对。2.仿真内容与结果:仿真1,在上述仿真条件下进行如下步骤的仿真实验:首先,利用训练集图像对场景图生成网络进行训练得到训练好的场景图生成网络;其次,将图7的测试集图像输入目标检测网络中,建立全连接图,如图8所示;然后,对全连接图进行稀疏化,得到稀疏关系图,如图9所示;最后,通过训练好的场景图生成网络预测稀疏关系图中的每一条边,构建出场景图,结果如图10所示。仿真2,对测试集图像,分别利用现有方法和本发明产生的关系分类特征进行可视化,结果如图6所示,其中图6(a)为输入的图像,图6(b)为用现有方法对6(a)可视化产生的效果图,图6(c)为用本发明对6(a)可视化产生效果图。仿真3,对测试集中所有图像进行场景图生成,并通过关系分类评价指标和场景图分类评价指标计算准确率,结果如表1所示,其中r@20,r@50,r@100分别表示取按预测置信度进行排序的前20个,前50个,前100个计算的准确率。表1任务名称r@20r@50r@100关系分类59.3%64.8%67.8%场景图分类33.4%36.3%37.2%2.仿真结果分析:由仿真1可以看出,本发明可以对全连接关系图进行合理的稀疏化,并能的产生较好的场景图;由仿真2可以看出,本发明的关系分类特征相比于现有方法的关系分类特征能够更好地关注到两个目标发生关系的区域,从而提高了网络的可解释性;由仿真3可以看出,在关系分类与场景图分类两种评价标准中,本发明均取得了较好的结果。综上所述,本发明不仅通过对全连接关系图的稀疏化减少了计算量,而且通过场景图生成网络使得用于最终分类的特征关注到真正发生关系的区域,提高了网络的可解释性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1