基于多维特征提取无监督EEG信号分类方法与流程
本发明属于eeg信号分类技术领域,具体涉及一种基于多维特征提取无监督eeg信号分类方法。
背景技术:
目前eeg信号多用于有监督的特征学习,但是由于生理信号取样困难,而且eeg信号取样时间要求十分严格,样本中误差较大且存在大量冗余数据。在监督学习过程中,一旦误差较大的样本被作为验证集数据计算损失函数,效果误差十分严重,生成模型将没有任何意义。
技术实现要素:
本发明的目的是提一种基于多维特征提取无监督eeg信号分类方法,以减少eeg信息的冗余,并便于利用eeg信号的内在连续性属性,更好的提高分类的正确率。
本发明提供了一种基于多维特征提取无监督eeg信号分类方法,包括:
步骤1,基于脑电采集设备采集eeg信号;
步骤2,对采集到的eeg信号进行预处理;
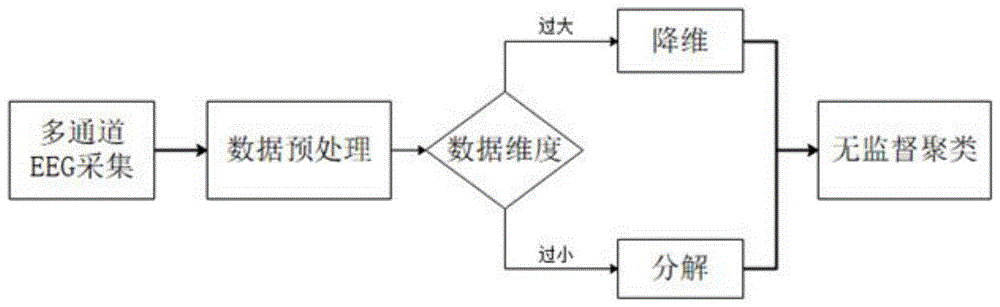
步骤3,进行数据维度判定,若当数据维度过大,分类类数比较小,先使用降维算法,进行数据压缩,然后基于聚类算法进行分类;若数据维度不多,且最终分出的类别较多,采用数据分解算法,将数据进行扩充,再进行无监督分类。
进一步地,所述步骤1包括:
采用脑电采集设备,采集64个点位的脑电信号,采样频率为1000hz,电极阻抗要求均控制在50kω以下。
进一步地,所述步骤2包括:
将eeg信号通过0.5~40hz的带通滤波器;去除伪迹和噪声,伪迹包括眼动伪迹、肌电伪迹、心电伪迹,噪声为50hz工频干扰;进行基线校正;将eeg信号截取成非重叠的若干段,进行滤波,按照频谱提取alpha(8-13hz)、beta(13-30hz)、theta(4-7hz)。
进一步地,所述步骤3包括:
根据分类需求进行预分类处理,基于分类效果建模,进行预判断,并基于该分类效果,进行特征挖掘,若数据分的开,有部分冗余,进行降维处理,以使聚类效果更加明显。
进一步地,所述步骤3还包括:
基于小波分解算法分解eeg信号,提取高频和低频信息量;
基于emd本征模态分解提取eeg信号的多层边缘信息。
进一步地,步骤3中所述聚类算法采用som神经网络聚类算法。
与现有技术相比本发明的有益效果是:
分类模型不依赖于硬件设备的灵敏度,对采集信号的质量要求低;允许可控范围的延时效果,对时间的灵敏度要求不算高。计算速度快,相比于传统的监督学习模型,收敛可控。阈值自己可以人工注入,检测需求可以根据适用的实际环境进行调控。
附图说明
图1是本发明基于多维特征提取无监督eeg信号分类方法的流程图;
图2是本发明数据预处理流程图。
图3为本发明使用的两种类型的降维算法流程图。
具体实施方式
下面结合附图所示的各实施方式对本发明进行详细说明,但应当说明的是,这些实施方式并非对本发明的限制,本领域普通技术人员根据这些实施方式所作的功能、方法、或者结构上的等效变换或替代,均属于本发明的保护范围之内。
参图1所示,无监督eeg信号分类模型,首先要采集大量eeg信号,进行预处理,当数据维度过于大,分类类数比较小,可以使用先降维的方法,进行数据压缩,然后再进行分类,当数据维度并不多,且最终分出的类别较多,可采用数据分解,可以将数据进行扩充,最后再进行无监督分类。分类模型不依赖于硬件设备的灵敏度,对采集信号的质量要求低;允许可控范围的延时效果,对时间的灵敏度要求不算高。计算速度快,相比于传统的监督学习模型,收敛可控。阈值自己可以人工注入,检测需求可以根据适用的实际环境进行调控,例如,设备故障检测上可以将灵敏度调大,有类似反应可以作为反馈信号,医学上运用可以将灵敏度调小,有明显的信号才可以作为一个正确分类效果。
具体包括:
1、多通道eeg数据采集
采用neuroscan的脑电采集设备,采集64个点位的脑电信号,采样频率为1000hz,电极阻抗要求均控制在50kω以下。实验在安静环境内进行,实验室的温度控制在(23±2)℃,采集时要求手机关机,避免电磁干扰。
测试者头戴采集设备,打开软件,进行数据采集。同时记录下测试者的心理状态。
将标签和eeg数据保存在同一个文件夹下,文件名要相互关联。
2、数据预处理
参图2所示,将所采集数据进行预处理。首先将eeg信号通过0.5~40hz的带通滤波器;其次去除干扰也就是各种伪迹和噪声,伪迹主要包括眼动伪迹、肌电伪迹、心电伪迹,噪声主要是50hz工频干扰;之后再进行基线校正;然后将eeg信号截取成非重叠的若干段,最后进行滤波,按照频谱提取alpha(8-13hz)、beta(13-30hz)、theta(4-7hz)。
3、数据维度判定
根据分类需求,首先进行预分类处理,针对分类效果,进行建模,进行一个预判断,针对该分类效果,进行特征挖掘;倘若数据分的开,有部分冗余,可进行降维处理,使得聚类效果更加明显。
4、降维算法
所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数f:x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然提高维度也是可以的)。f可能是显式的或隐式的、线性的或非线性的。
目前大部分降维算法处理向量表达的数据,也有一些降维算法处理高阶张量表达的数据。之所以使用降维后的数据表示是因为在原始的高维空间中,包含有冗余信息以及噪音信息,在实际应用例如图像识别中造成了误差,降低了准确率;而通过降维,可以减少冗余信息所造成的误差,提高识别(或其他应用)的精度,并通过降维算法寻找数据内部的本质结构特征。
降维算法分为线性降维和非线性降维,本实施使用的两种类型的降维算法如图3所示。
5、分解算法
分解算法主要增加数据信息量,从而增加数据维度,便于在聚类过程中产生更好的聚类效果。将小波分解用于eeg分解,提取高频和低频信息量,通过emd本征模态分解提取eeg信号的多层边缘信息。
6、聚类算法
将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。在许多应用中,一个簇中的数据对象可以被作为一个整体来对待。
聚类是一种机器学习技术,它涉及到数据点的分组。给定一组数据点,本实施例使用聚类算法将每个数据点划分为一个特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督学习的方法。
k-means算法是一种最基本的基于距离的划分的聚类算法。k-means算法在对所给数据集进行聚类时,采用的是“非此即彼”的硬聚类方式。
fcm算法是一种基于划分的模糊聚类算法。该算法是采用隶属度来确定每个数据点属于某个聚类程度的一种方法。相比于k-means算法,fcm则是一种柔性的模糊划分法。
canopy算法是不需要事先指定聚类数目的粗聚类方法。在对聚类的精度要求相对较低,速度要求相对较高的情况下,可直接采用canopy聚类算法直接对数据样本进行处理。或者有精度要求的情况下,可以用它来作为k-means或fcm聚类算法的预处理步骤,先得到k值,再进行精确的聚类。所以canopy算法具有很高的实际应用价值。
层次聚类算法是将所有的数据集自底向上合并成一棵树或自顶向下分裂成一棵树的过程,这两种方式分别称为凝聚和分裂。对凝聚层次聚类算法,在初始阶段,将每个样本点分别当作其类簇,然后合并这些原子类簇直到达到预期的类簇数或者其他终止条件;而对于分裂层次的聚类算法,在初始阶段,将所有的样本点当作同一类簇,然后分裂这个大类簇直至达到预期的类簇数或者其他终止条件。
lda文本聚类算法基于lda主题模型。lda主题模型是一种概率生成模型。lda主题模型是一个生成性的三层贝叶斯网络,将词和文章通过潜在主题相关联。与许多其他的概率模型类似,lda中也做了词袋假设,即在模型中不考虑特征词的顺序,只考虑它们的出现次数。
dbscan算法是一种基于密度的空间聚类算法。该算法要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定领域密当改变聚类的数目时,不需要再次计算数据点的归属。度阈值,即将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连点的最大集合。
em算法是在em算法容易陷入局部最优解;概率模型中寻找参数最大似然估计的方法。其中概率模型依赖于无法观测的隐藏变量。
本发明具有如下技术效果:
1.排除干扰能力强。可以排除掉采集的电磁噪声污染。
2.计算速度快,效率较高。基于聚类算法,由于其速度与数据对象的个数无关,而只依赖于数据空间中每个维上单元的个数,所以计算速度较快,而且对硬件设备要求不会太高。
3.提取有用信息效率高。数据降维,直观地好处是维度降低了,便于计算和可视化,其更深层次的意义在于有效信息的提取综合及无用信息的摈弃。
4.可以挖掘出新的特征因素。分解算法,不同属性的小波分解,还有本征模态分解。都可以较强发掘隐含的信息量。
5.som神经网络聚类,是针对eeg信号专门的聚类算法。som神经网络其本质是由输入层以及输出层这两层神经元网络组合构成的,som神经网络的神经元的节点全部都在一个层面上,并且呈现出一种规则的排列。在一些eeg聚类方面去有一些显著效果。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
- 还没有人留言评论。精彩留言会获得点赞!