一种融合聚类与密度估计的窃电检测方法及系统与流程
本发明属于用电检测领域,涉及一种异常用电的检测方法及系统,特别是一种融合聚类与密度估计的窃电检测方法及系统。
背景技术:
随着经济的发展,电力已经成为人们生活中不可或缺的一部分。特别是近年来,用数据呈现出爆发式增长,使得异常用电检测变得尤其重要。用户的异常用电行为不仅影响了供电公司的收入,还阻碍了智能电网的发展。
电力销售是供电公司主要的经济来源,然后再投入到发电站、输电线路、供电设备的建设以及电网的运营中,用于维持整个电力行业的稳定运行和进一步的发展壮大。而所谓智能电网就是通过各种技术手段对电表终端采集到的用电数据进行分析、利用和决策,以达到提高资源利用率、维持电网安全稳定运行、减少输电损耗,减少对环境影响等目的。然而以窃电为主体的异常用电行为严重损害了供电公司的利益,破坏市场用电秩序,也影响了电网的稳定运行。
对电网来说,异常用电行为增加了线损,给供电公司造成极大的负担。而且大多数窃电行为都是通过私拉电线、更改电能表的内部计量方式,达到少交电费的目的。这不仅损害了基础电力设施,还严重威胁到电网的安全稳定运行。电力本身就是一种高危产品,窃电行为具有极大的安全隐患,容易引发火灾,威胁到人民群众的人身财产安全,给社会的和谐带来不稳定因素。据反窃电工作越来越具体化与目标明确化,且主要以远程侦查为发展目标,由此减轻涉外人员的工作强度;同时带来的问题是,如何在不增加电力企业经济压力的前提下,实现对窃电行为的全面侦查,特别随着用电信息采集系统和sgl86营销业务应用系统的全覆盖应用,“数据海量,信息匮乏”的现象正反映了反窃电工作的尴尬处境。
传统的窃电检测主要依靠人工进行,这种方式不仅需要大量的人力资源,增加了电网公司运营成本,而且检测效率较低,滞后于窃电行为的发生,存在取证难的问题;在一般的窃电检测方法中,常常是直接通过提取与窃电相关的指标数据,如电流、电压,然后分析这些数据是否异常进行判断,但是在实际中需要对所有用户的电压电流都需要检测,导致检测效率比较低;如果只从窃电行为分析,由于样本数目少会导致偏差比较大。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种融合聚类与密度估计的窃电检测方法。
本发明解决其技术问题是采取以下技术方案实现的:
一种融合聚类与密度估计的窃电检测方法,其特征在于:包括如下步骤:
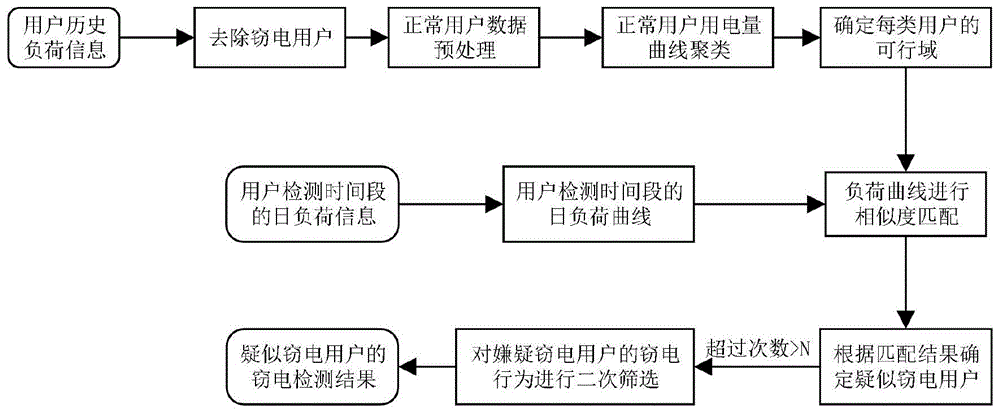
步骤一,对窃电嫌疑用户进行初步检测,对非窃电嫌疑用户进行排除:获取用户历史负荷信息,采用减法聚类进行聚类数目与聚类中心的确定,采用模糊c聚类均值算法对确定的聚类中心与聚类数目进行聚类,并确定特征曲线,确定每类用户的可行域,通过采用将相关系数与欧氏距离相结合进行用户的相似性度量进行初步检测窃电嫌疑用户,将某类中无窃电嫌疑用户进行排除;
步骤二,对疑似窃电用户进行二次检测:对初步确定的窃电嫌疑用户采用基于密度估计的异常点检测算法进行二次筛选;
步骤三,对两次筛选最终确定的用户,再进行人工排查。
而且,所述聚类数目与聚类中心的确定方法为:
步骤(1),将所有的样本点作为聚类中心的候选点,计算每个数据点的密度指标:
式中,ra是一个正数,定义了该点的邻域半径,半径以外的数据点对该点的密度指标贡献甚微,取
步骤(2),根据第k次选出的聚类中心,对每个数据点的密度指标进行修正:
式中,rb是一个正数,定义了一个密度指标函数显著减小的领域,取rb=1.2ra,选出密度指标最高的数据点xck+1作为新的聚类中心;
步骤(3),判断退出条件是否成立,
若不成立,则转到步骤(2),式中δ<1是事先给定的参数,此参数决定了最终产生的初始化聚类中心数目,δ越小,则产生的聚类数越多。
而且,还包括对聚类有效性的判断,该方法为:采用在xie-beni指数的基础上结合类内离散的聚类有效性函数进行判断,该指数的求解公式为:
该指数的最小值对应最优的聚类结果与最合适的类别个数,其中
而且,对所述确定的聚类中心与聚类数目进行聚类的方法为:
在进行负荷聚类过程中,以各个样本到所有聚类中心的距离加权平方和为目标函数,定义为:
式中,vi为第i个聚类中心的向量,矩阵v表示向量的集合,为c×m的矩阵,μij为隶属度矩阵,w为加权指数,取值范围为[1,+∞),w的值决定聚类效果的模糊程度,当w=1时c聚类均值算法fcm变为k聚类均值算法hcm,w趋向于无穷时,c聚类均值算法获得的各个聚类中心则会退化成数据的中心;
w的取值采用如下公式获得:
对于标准fcm算法,标准化后的隶属度μij的取值范围为[0,1],并且满足:
利用拉格朗日乘数法优化目标函数,以式(7)为约束条件可以得到使目标函数取得局部极小值的必要条件为:
而且,所述初步检测窃电嫌疑用户的方法为:
采用基于时间序列的相似性度量历史曲线以及待测曲线的匹配度,将相关系数和欧式距离进行综合考虑,定义两条曲线的匹配度w:
m=ω1r+ω2lnd(9)
式中:r为用户考察日的负荷曲线与其负荷特征曲线的相关系数:
本发明的优点和积极效果是:
1、本融合聚类与密度估计的窃电检测方法,首先将减法聚类与fcm相结合,可直接根据密度指标来选取聚类中心,解决了fcm算法对聚类初值敏感的问题,保证最后的聚类结果为最优解;采用将相关系数与欧氏距离相结合进行用户的相似性度量,可以保证度量的客观性与准确性。
2、本融合聚类与密度估计的窃电检测方法,采用密度估计进行窃电用户的二次检测,同时考虑用户负荷的横向连续性与纵向连续性,在整体上对窃电数据进行识别,避免了对同时判断多个用户的检测效果不佳的缺点,同时可以保证获得的是全局最优解。本方法可在现有的计量装置下,仅通过分析用电数据特征发现窃电用户,降低防窃电成本,检测窃电用户的准确率很高。
附图说明
图1是本发明的流程图;
图2是本发明步骤一的流程图;
图3为本发明步骤二的流程图。
具体实施方式
以下结合附图对本发明的实施例做进一步详述:
一种融合聚类与密度估计的窃电检测方法,其创新之处在于:包括如下步骤:
步骤一,获取用户历史负荷信息,去除窃电用户,并通过采用减法聚类进行聚类数目与聚类中心的确定,采用模糊c聚类均值算法对确定的聚类中心与聚类数目进行聚类,并确定特征曲线,确定每类用户的可行域;获取用户检测时间段的日负荷信息,并形成日负荷曲线,通过采用将相关系数与欧氏距离相结合进行用户的相似性度量进行初步检测窃电嫌疑用户,将某类中无窃电嫌疑用户进行排除;
步骤二,对疑似窃电用户进行二次检测:对初步确定的窃电嫌疑用户采用基于密度估计的异常点检测算法进行二次筛选;
步骤三,对两次筛选最终确定的用户,再进行人工排查。
各步骤的具体方法为:
首先采用基于减法聚类的fcm算法进行聚类。在使用fcm之前,先使用减法聚类找到初始聚类中心,不但可以避免陷入局部最优解,而且还可以根据每个数据点中各个维对聚类中心的影响自动产生较好的聚类数,不必事先确定要聚类的个数。首先根据选择的聚类算法,对历史数据进行聚类,提取历史数据的聚类曲线及负荷的特征曲线,然后根据负荷曲线及历史负荷数据确定负荷数据能在特征曲线上下波动的范围,确定每类用户的可行域范围。当每类用户的用电量超过其可行域,则对该用户进行标记,当该用户的标记次数多余n次时,则对该用户进行二次检测。
1)聚类数与聚类中心的确定
本发明聚类中心与聚类数的确定采用减法聚类,该方法是把所有的样本点作为聚类中心的候选点,计算每个数据点的密度,然后根据每个数据点的密度大小来确定初始聚类中心。
考虑m维空间的n个数据点,xi(1,2,...,)则减法聚类过程为:
(1)计算每个数据点的密度指标
式中,ra是一个正数,定义了该点的邻域半径。半径以外的数据点对该点的密度指标贡献甚微,取
(2)根据第k次选出的聚类中心,对每个数据点的密度指标进行修正
式中,rb是一个正数,定义了一个密度指标函数显著减小的领域,为避免出现相距很近的聚类中心,这里取rb=1.2ra。选出密度指标最高的数据点xck+1作为新的聚类中心。在获得初始聚类中心v0后,基于式(5)可获得初始化隶属度矩阵u0。
(3)判断退出条件是否成立
若不成立,则转到步骤(2)。式中δ<1是事先给定的参数,此参数决定了最终产生的初始化聚类中心数目,δ越小,则产生的聚类数越多。
2)有效性的判断
有效性是判断聚类效果好坏的一个指标,一个理想的聚类应该是保证类内紧致、类间离散。本发明采用在xie-beni指数的基础上结合类内离散的聚类有效性函数,该指数较xie-beni有更好的鲁棒性和稳定性,求取公式如下:
该指数的最小值对应最优的聚类结果与最合适的类别个数。该指数在分子中加入惩罚项
3)根据确定的聚类中心与聚类数目进行聚类
在进行负荷聚类过程中,以各个样本到所有聚类中心的距离加权平方和为目标函数,定义为:
式中,vi为第i个聚类中心的向量,矩阵v表示向量的集合,为c×m的矩阵。μij为隶属度矩阵。w为加权指数,取值范围为[1,+∞),w的值决定聚类效果的模糊程度,当w=1时fcm变为hcm(硬聚类算法),w趋向于无穷时,fcm聚类算法获得的各个聚类中心则会退化成数据的中心。
由于目标函数jw(u,v)随加权指数w单调递减,通常存在一个拐点,这个拐点处于附近,整个算法的迭代次数随w的取值呈现出振荡性变化趋势,在附近恰好取到一个极小值,此时算法具有较好的收敛性,w的取值可以采用如下公式获得:
对于标准fcm算法,标准化后的隶属度μij的取值范围为[0,1],并且满足:
利用拉格朗日乘数法优化目标函数,以式(7)为约束条件可以得到使目标函数取得局部极小值的必要条件为:
4)窃电检测
由于用户的负荷曲线是由一系列与时间顺序相关的负荷值所组成,因此可以采用基于时间序列的相似性来度量两条曲线的匹配度。本发明将相关系数和欧式距离进行了综合考虑,定义两条曲线的匹配度w:
m=ω1r+ω2lnd(9)
式中:r为用户考察日的负荷曲线与其负荷特征曲线的相关系数:
其中xi,li为用户考察日时刻i的负荷值,li为其负荷特征曲线相应时刻的值,
2.基于密度估计的异常检测算法窃电的二次检测
1)数据密度估计方法的基本原理如下:
(1)假设有一个数据点总数为m的二维数据集z。
(2)产生一个称为种子群的数据集s,其所含的种子个数n需事先确定,且需保证各个种子与其相邻种子之间的距离恒等,此外还需要保证种子群的范围能够包含数据集z。
(3)每个数据点zj(j∈{1,2,...,m})均附有一个初值为0的种子吸附计数器cj,用于累计该数据点吸附的种子数目。
(4)对于每个种子si(i∈{1,2,...,n})分别计算它与数据集z的各个数据点之间的距离,假设距离种子si最近的数据点为zk。采用欧式距离确定距离种子si的最近数据点zk的排序(即下标k)的过程可表示如下:
k=argmin(||si-zj||2)(10)
式中,i∈{1,2,...,n},j∈{1,2,...,m},式(1)的含义为目标函数值最小时的j值为k。
(5)依据式(10)确定距离种子si最近的数据点zk,将该数据点所附带的种子吸附计数器ck加1.如果存在p个数据点与种子si距离相等且均为最近,则等比例地分配给这些数据点,即距离最近的每个数据点的种子吸附计数器均累加1/p.
(6)对于种子群s中的每个种子均按式(10)确定距其最近的数据点,然后按上述规则更新相应数据点种子吸附计数器的值,直至所有种子都计算完为止。
2)识别原理
前已述及,每个数据点附带一个种子吸附计数器,用来累计每个数据点吸附的种子数目,这样,就有以下两点结论:
(1)如果某个数据点的种子吸附计数器的值大,则表明该数据点吸附的种子多,即该数据点的邻域内与其竞争分享这些种子的数据点不多,该数据点密度低;
(2)若某一数据点的邻域内存在许多数据点,那么该数据点与其周围的数据点在吸附种子时就存在较为激烈的竞争,每个数据点所吸附的种子数目就较少。
数据点的密度较低表示在其邻域内出现数据点的概率较小,这样就可把种子吸附计数器值高于某个设定值的数据点归为不良数据,在本发明中把此设定值称为种子吸附阈值.
3)参数确定
该算法中需确定两个参数,即种子数目和种子吸附阈值.
2.3.1种子数目的确定
(1)计算每个数据点与其它数据点之间的最短距离:
di=min(||zi-zj||2)(11)
式中:i,j∈{1,2,...,m}且j≠i
(2)按下式确定所有数据点与其它数据点间最短距离的均值
(3)确定种子范围,即为了确保种子范围能够包括所有数据点,假设数据集某维的取值范围为zmin~zmax,则种子集此维的上下界smax与smin应满足:
(4)在确定了种子距离和种子范围之后,即可计算出种子数目。
2.3.2种子吸附阈值的确定
种子吸附阈值可根据所得全部种子吸附值的总体分布来确定,这里采用下述方法:先把种子吸附值按从大到小的次序排列,给定某个百分位数作为种子吸附阈值,判断检测效果,直到找到一个合适的吸附阈值,使得窃电检测取得一个好的效果,能够准确的判断窃电用户。
两次检测最终确定的用户为窃电嫌疑用户则大概率是窃电用户,可进行人工排查,通过检测如果确实为窃电用户,则将该用户的特征输入到窃电特征库。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!