一种基于自然语言处理的人机验证方法和系统与流程
本发明涉及安全防护和自然语言处理技术领域,特别是指一种基于自然语言处理的人机验证方法和系统。
背景技术:
即使现在互联网已经渗透到我们生活的方方面面,但它依然只是现实的物理世界在虚拟的网络空间上按比特信息编码后的投射。
这就意味着自动化程序同样可以模仿人的行为,同时,因为机器速度更快且不知疲倦,它会被用于批量在论坛、网站、app中发布营销信息。而且,在监管不足的情况下,利润更高的行业往往底线更低。一些自动化程序还会尝试以「撞库」的方式窃取用户帐号、密码,给网站带来巨大的安全隐患。
验证码正是为了解决这样的问题而生的。它也是个自动化程序,不过存在目的是区分用户到底是机器人还是真实的人。这些验证码有一个共同的原则:人类很容易识别,但对计算机来说非常困难。
其次,验证码本身就被被称为一种「图灵测试」,所以它在设计之初就有促进人工智能发展的初衷。目前的人机验证机制大多通过图像识别等方式来提供验证,而对于图像的人工智能技术已经日趋完善。然而,市面上仍然存在打码机器人众多、人机验证识别度低和自然语言处理类型人机识别验证缺失等问题。
技术实现要素:
本发明的主要目的在于克服现有技术中的上述缺陷,提出一种基于自然语言处理的人机验证方法和系统。
本发明采用如下技术方案:
一种基于自然语言处理的人机验证方法,其特征在于,包括如下步骤:
s1:构建验证集的语料库;
s2:根据语料库构建词向量模型;
s3:根据语料库和词向量模型构建人机验证模型;
s4:对验证集采用模板法随机生成验证码;
s5:将采集到的验证答案输入人机验证模型,判断是否满足要求,若否,则重复该步骤,若是,则验证通过。
优选的,步骤s1具体包括如下:
s11:使用scrapy框架爬取网络上的资讯、小说、百科和论文获得文本语料;
s12:下载基于维基百科、百度百科和搜狗提供的文本语料;
s13:对所有文本语料进行文本清洗;
s14:使用jieba对清洗后的文本语料进行分词操作;
s15:通过现有语料标注或人工标注构建所述语料库。
优选的,步骤s2中,采用word2vec构建词向量模型。
优选的,步骤s3中,具体包括:
s31:采用所述词向量模型计算验证集中语料的文本向量距离,其包含杰卡德系数、tf-idf词袋模型和编辑距离;
s32:获取验证集中文本词性和句子成分。
优选的,步骤s31具体包括:
s311:计算杰卡德系数,比较验证集的文本语料之间的相似性与差异性;
s312:计算步骤s2获得的tf矩阵中两个向量的相似度;
s313:计算tf-idf系数,在词频tf的基础上再加入idf逆文档频率的信息;
s314:计算验证集中不同文本语料之间的编辑距离。
优选的,步骤s32具体包括:
s321:通过语料库的文本语料得到文本语料中各分词的词性及句子成分;
s322:通过语料统计,得到语料库中未曾记录的词语的起始概率、发射概率和转移概率;
s323:使用viterbi算法,将对输入的句子进行分词转化得到语料库中词性标注种类和个数。
优选的,步骤s4具体包括:
s41:随机从验证集中抽取一个句子;
s42:对抽取到的句子自动进行句子结构的划分,形式为<ei,r,ej>,ei、ej为实体,r为关系;
s43:依据句子结构划分借助已有的问题模板进行问题生成。
优选的,步骤s5具体包括:
s51:判断用户输入的验证答案是否符合自然语法;
s52:判断用户输入验证答案和抽取的句子相似度是否达到80%;
s53:若达到相似的要求,则验证通过;否则,返回步骤s4。
优选的,还包括步骤s6,利用pcr回归建模,通过交叉验证对验证集进行优化、合并,具体包括如下:
s61:服务器存储收集来的各种通过人机验证的语料;
s62:选取通过次数较多的语料,输入到pcr回归模型中进行交叉验证结果正确性;
s63:将通过交叉验证的语料输入训练好的tf-idf词袋模型进行训练;
s64:将通过交叉验证的语料合并至已有验证集。
一种基于自然语言处理的人机验证系统,其特征在于,应用上述的一种基于自然语言处理的人机验证方法,包括:
验证集模块,设有验证集,其包括语料库和词向量模型;
验证码生成模块,对验证集采用模板法随机生成验证码;
人机界面模块,提供操作界面以供显示验证码和输入验证答案;
人机验证模型模块,用于根据输入的验证答案,判断是否满足要求。
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
1、降低互联网受到恶意攻击的风险,可用于登陆、注册等网络场景下对用户进行人机验证,有效防止了机器人爬虫。
2、生成并公开自然语言训练语料集用于自然语言处理领域促进当代人工智能产业发展。
附图说明
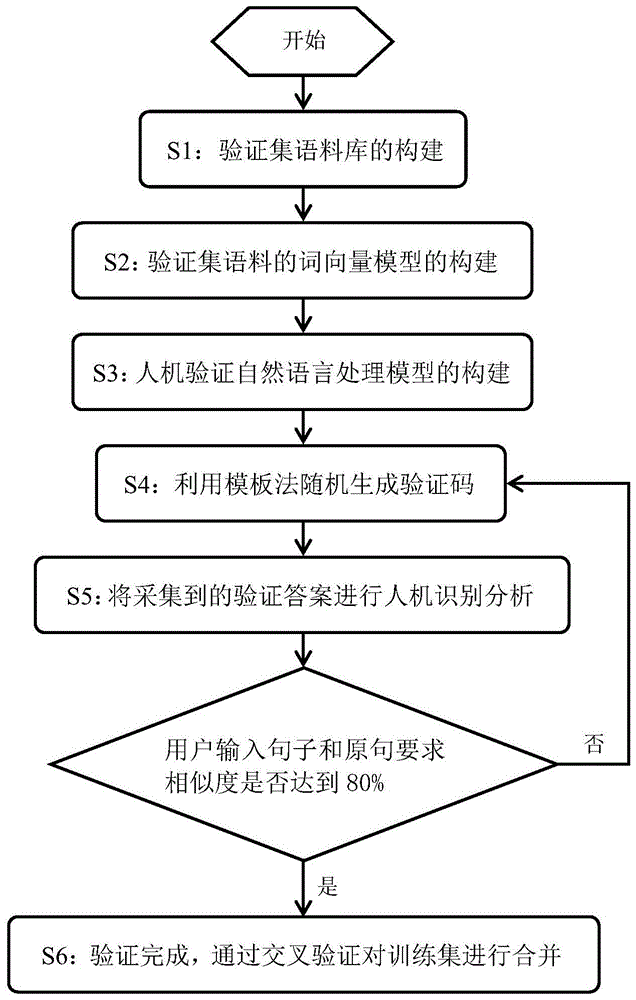
图1为本发明流程图。
以下结合附图和具体实施例对本发明作进一步详述。
具体实施方式
以下通过具体实施方式对本发明作进一步的描述。
本发明的一种基于自然语言处理的人机验证系统及方法,包括以下步骤:(1)验证集语料库的构建;(2)验证集语料的词向量模型的构建;(3)人机验证自然语言处理模型的构建;(4)利用模板法随机生成验证码;(5)将采集到的验证答案进行人机识别分析;(6)利用pcr回归建模,通过交叉验证对验证集进行优化、合并。
参见图1,一种基于自然语言处理的人机验证方法,包括如下步骤:
s1:构建验证集的语料库。其具体包括如下:
s11:使用scrapy框架爬取网络上的资讯、小说、百科和论文获得文本语料;
s12:下载基于维基百科、百度百科和搜狗提供的文本语料;
s13:对所有文本语料进行文本清洗。文本清洗包括文本标准化、符后标准化、停词去除、词性分析、命名实体、变形标准化等。
s14:使用jieba对清洗后的文本语料进行分词操作。
s15:通过现有语料标注或人工标注构建所述语料库。
s2:根据语料库构建词向量模型,具体的,本发明采用word2vec构建词向量模型。
s3:根据语料库和词向量模型构建人机验证模型。其具体包括:
s31:采用词向量模型计算验证集中语料的文本向量距离,其包含杰卡德系数、tf-idf词袋模型和编辑距离。tf-idf词袋模型中包含tf-idf系数及余弦相似度。本步骤具体包括:
s311:计算杰卡德系数,比较验证集的文本语料之间的相似性与差异性;
s312:计算步骤s2获得的tf矩阵中两个向量的相似度,即采用word2vec构建的两个单词的词向量;
s313:计算tf-idf系数,在词频tf的基础上再加入idf逆文档频率的信息;
s314:计算验证集中不同文本语料之间的编辑距离。
s32:获取验证集中文本词性(863词性标注集)和句子成分(分词标注集)。
步骤s32具体包括:
s321:通过步骤s15中已有语料库的文本语料统计得到文本语料中各分词的词性及句子成分;
s322:通过前文的语料统计,得到语料库中未曾记录的词语的起始概率、发射概率和转移概率。未曾记录的词语即步骤s15中现有语料标注或人工标注构建的语料库中未曾记录的词语。起始概率是指某一个词性出现的次数/语料库总词性标记数,发射概率是指该词语不同词性出现的次数/该词语总共出现的总次数,转移概率是指词性出现时的前一个词性的次数/该词性出现的总次数。
s323:使用viterbi算法,将对输入的句子(即观测序列)进行分词转化得到语料库中词性标注种类和个数(隐藏序列)。
s4:对验证集采用模板法随机生成验证码。具体包括:
s41:随机从验证集中抽取一个句子;
s42:对抽取到的句子自动进行句子结构的划分,形式为<ei,r,ej>,ei、ej为实体,r为关系;
s43:依据句子结构划分借助已有的问题模板进行问题生成。
s5:将采集到的验证答案输入人机验证模型,判断是否满足要求,若否,则重复该步骤,若是,则验证通过。
步骤s5具体包括:
s51:判断用户输入的验证答案是否符合自然语法;
s52:判断用户输入验证答案和抽取的句子相似度是否达到80%;
s53:若达到相似的要求,则验证通过;否则,返回步骤s4。
进一步的,本发明还包括步骤s6,利用pcr回归建模,通过交叉验证对验证集进行优化、合并,具体包括如下:
s61:服务器存储收集来的各种通过人机验证的语料,即用户在网页上进行人机验证的答案;
s62:选取通过次数较多的语料,输入到pcr回归模型中进行交叉验证结果正确性;
s63:将通过交叉验证的语料输入训练好的tf-idf词袋模型进行训练;
s64:将通过交叉验证的语料合并至已有验证集。
本发明还提出一种基于自然语言处理的人机验证系统,应用上述的基于自然语言处理的人机验证方法,包括:
验证集模块,设有验证集,其包括语料库和词向量模型;
验证码生成模块,对验证集采用模板法随机生成验证码;
人机界面模块,提供操作界面以供显示验证码和输入验证答案;
人机验证模型模块,用于根据输入的验证答案,判断是否满足要求。
本发明提出的基于自然语言处理的人机验证系统及方法充分挖掘了自然语言的内在潜力,降低了用户验证难度,增加了人机验证的趣味性和破解难度,提升了人机验证的效率、准确度和安全性。
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
- 还没有人留言评论。精彩留言会获得点赞!