基于光流梯度幅值特征的人脸微表情检测方法与流程
本发明的技术方案涉及用于识别图形记录载体的处理,具体地说是基于光流梯度幅值特征的人脸微表情检测方法。
背景技术:
人脸微表情检测在国家安全、临床医学和司法系统多个领域都有广泛应用,如通过人脸微表情检测辨别恐怖分子之类危险人物,使用人脸微表情检测训练软件对精神分裂症患者进行辅助治疗,通过人脸微表情检测分析罪犯的犯罪心理以帮助侦查审讯等。目前,人脸微表情的研究工作多集中于人脸微表情识别,然而用于识别人脸微表情的视频序列帧需要手动标记,不但耗费大量的人力与时间,而且对标记人员要求较高。因此急需使用计算机视觉、人工智能等先进技术进行人脸微表情自动检测,实现人脸微表情片段的精准定位,以提高人脸微表情识别的效率,扩大人脸微表情检测的应用范围。
当前人脸微表情检测方法主要分为基于规则、基于机器学习与基于深度学习的方法。基于规则的人脸微表情检测方法主要是提取纹理和光流特征,使用特征距离分析,手动制定规则进行人脸微表情检测。文献“towardsreadinghiddenemotions:acomparativestudyofspontaneousmicro-expressionspottingandrecognitionmethods”使用lbp特征与hoof特征进行特征提取,使用特征差异分析方法进行人脸微表情检测。文献“amaindirectionalmaximaldifferenceanalysisforspottingfacialmovementsfromlong-termvideos”提出用于人脸微表情检测的主方向最大差异(maindirectionalmaximaldifference,mdmd)特征,能获得更优的人脸微表情运动信息。但这些基于规则的人脸微表情检测方法所提取特征只能获得一些简单、基本的特征,无法对图像进行深层次的表达。基于机器学习的人脸微表情检测方法同样提取纹理特征、光流特征一类传统特征,使用svm、随机森林方法进行分类。文献“ltp-ml:micro-expressiondetectionbyrecognitionoflocaltemporalpatternoffacialmovements”使用滑动窗口与pca降维提取局部时间(localtemporalpattern,ltp)特征,使用svm进行分类。机器学习分类需要以固定帧数的视频序列为单位提取特征,但人脸微表情发生时间的长短不固定。基于深度学习的人脸微表情检测方法将神经网络引入人脸微表情检测研究。文献“micro-expressiondetectioninlongvideosusingopticalflowandrecurrentneuralnetworks”提取光流特征,使用递归神经网络(rnn)检测包含人脸微表情的视频序列。基于深度学习的人脸微表情检测方法将特征学习融入到了建立模型的过程中,能够减弱手工特征的不完备性,能够提取更具判别性的特征,然而深度学习的人脸微表情检测方法需要大数据集的支撑,人脸微表情数据库的缺乏导致深度学习算法不能很好地用于人脸微表情检测工作。
cn109344744a公开了一种基于深度卷积神经网络的人脸微表情动作单元检测方法,该方法无法保证人脸微表情状态中人脸动作单元组合全覆盖,且仅用于人脸微表情状态判定,无法区分同样含有所定义动作单元组合的普通表情。cn107358206a公开了一种基于感兴趣区域的光流特征矢量模值和角度结合的人脸微表情检测方法,该方法提取的人脸感兴趣中丢失脸颊额头等可能包含人脸微表情运动的区域,提取的特征中可能包含累积噪声,同时监测角度变化与矢量模值变化存在干扰信息,且直接采用最大值计算阈值易受噪声影响。cn104298981a公开了一种人脸微表情的识别方法,方法中使用的cbp-top特征存在计算复杂度高,易受噪声影响且只包含图像纹理信息,时序信息利用率低的缺陷。cn105139039b公开了一种视频序列中人脸微表情的识别方法,该方法中使用欧拉视频放大技术以解决人脸微表情变化幅度小的问题,然而,此方法用于人脸微表情检测过程中会造成其他运动及噪声同时放大的缺陷。cn106548149a公开了一种监控视频序列中人脸微表情图像序列的识别方法,其中所提出的smtctp-wtop特征缺乏连续多帧的时序信息,不同运动方向人脸微表情的此种特征为不同模式,不能通过训练得到有助于人脸微表情检测的模型。
总之,在人脸微表情检测的现有技术中,存在提取的人脸图像运动特征中无法捕捉微小的人脸微表情运动,特征中包含过多干扰信息,易受头部偏移,眨眼运动和累积噪声影响及特征距离分析中单帧噪声影响的缺陷。
技术实现要素:
本发明所要解决的技术问题是:提供基于光流梯度幅值特征的人脸微表情检测方法,该方法首先根据人脸关键点拟合人脸边缘提取人脸感兴趣区域,用flownet2网络提取视频序列中人脸图像帧间的光流场,然后提取人脸感兴趣区域的光流梯度幅值特征,再计算及处理特征距离并进行噪声消除,完成基于光流梯度幅值特征的人脸微表情检测,克服了在人脸微表情检测的现有技术中,存在提取的人脸图像运动特征中无法捕捉微小的人脸微表情运动,特征中包含过多干扰信息,易受头部偏移,眨眼运动和累积噪声影响及特征距离分析中单帧噪声影响的缺陷。
本发明解决该技术问题所采用的技术方案是:基于光流梯度幅值特征的人脸微表情检测方法,首先根据人脸关键点拟合人脸边缘提取感兴趣区域,用flownet2网络提取视频序列中人脸图像帧间光流场,然后提取人脸感兴趣区域的光流梯度幅值特征,再计算及处理特征距离并进行噪声消除,完成基于光流梯度幅值特征的人脸微表情检测,具体步骤如下:
第一步,提取人脸感兴趣区域:
输入人脸图像视频序列,根据人脸关键点拟合人脸边缘提取感兴趣区域,即使用dlib检测器检测人脸图像中81个标号的人脸关键点,包括在经典dlib人脸检测器中已有的68个人脸关键点和在此基础上增加的前额13个人脸关键点,其中标号为1-17及69-81的人脸关键点为人脸边缘关键点,使用这些人脸边缘关键点进行椭圆拟合得到椭圆方程q,椭圆方程q的拟合目标函数如公式(1)所示,
公式(1)中,[p,q]为用于拟合椭圆的人脸关键点坐标,α,β,χ,δ,ε为椭圆方程q的系数,f(α,β,χ,δ,ε)为包含系数α,β,χ,δ,ε的拟合目标函数,k表示用于拟合椭圆的第k个关键点,k为用于拟合椭圆的人脸关键点个数,
当以下公式(2)成立时,
得到f(α,β,χ,δ,ε)的最小值,此时求得椭圆方程q的系数α,β,χ,δ,ε,由此得到椭圆方程q,
使用眼睛部分标号为37,39,40,42,43,44,47,49的人脸关键点进行眼睛部分区域去除,其中使用标号为37,40的人脸关键点的纵坐标与标号为39,42的人脸关键点的横坐标组成右眼矩形区域,使用标号为43,46的人脸关键点的纵坐标与标号为44,47的人脸关键点的横坐标组成左眼矩形区域,
椭圆方程q所包含的椭圆区域去除上述右眼矩形区域和左眼矩形区域即为提取的人脸感兴趣区域,所提取的人脸感兴趣区域为拟合人脸边缘的椭圆形感兴趣区域;
第二步,提取人脸图像的光流梯度幅值特征:
对上述第一步所提取的人脸感兴趣区域中的人脸图像提取光流梯度幅值特征,步骤如下,
第(2.1)步,用flownet2网络提取视频序列中人脸图像帧间光流场:
首先构建flownet2网络的三层堆叠网络,第一层使用flownetc网络,第二层和第三层均使用flownets网络,再使用融合网络融合三层堆叠网络结果与根据flownets网络改进的flownetsd网络结果得到人脸图像帧间光流场,
将现有的人脸微表情数据库中的人脸图像样本编制为视频序列,其中每个视频序列表示为{f1,...,ft,...,fs},其中s为每个视频序列中所包含的人脸图像的总帧数(以下相同),ft为当前视频序列中的第t帧人脸图像,每个视频序列以第一帧人脸图像为参考帧提取光流场,当flownet2网络输入为f1与ft时,得到第t帧人脸图像的光流场,将第一步所提取的人脸感兴趣区域与人脸图像的光流场结合,得到每帧人脸图像感兴趣区域中的光流场由水平光流分量h与垂直光流分量v组成,
水平光流分量h如下公式(3)所示,
公式(3)中,hi,j为人脸图像感兴趣区域中坐标为[i,j]像素的水平光流分量,m为人脸图像感兴趣区域中包含像素的行数(以下相同),n为人脸图像感兴趣区域中包含像素的列数(以下相同),
垂直光流分量v如下公式(4)所示,
公式(4)中,vi,j为人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量,
由此完成用flownet2网络提取人脸图像感兴趣区域的光流场;
第(2.2)步,提取人脸感兴趣区域的光流梯度幅值特征:
用如下公式(5-1)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的水平光流分量hi,j在x方向的梯度值h(x)i,j,
用如下公式(6-1)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的水平光流分量hi,j在y方向的梯度值h(y)i,j,
用如下公式(5-2)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量vi,j在x方向的梯度值v(x)i,j,
用如下公式(6-2)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量vi,j在y方向的梯度值v(y)i,j,
上述公式(5-1)、(5-2)、(6-1)和(6-2)中,i为像素横坐标,j为像素纵坐标,
进一步用如下公式(7)计算坐标为[i,j]像素的水平光流分量hi,j的梯度幅值m(h)i,j,
进一步用如下公式(8)计算人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量vi,j的梯度幅值m(v)i,j,
根据水平光流分量hi,j的梯度幅值m(h)i,j与垂直光流分量vi,j的梯度幅值m(v)i,j,通过如下公式(9)计算人脸图像感兴趣区域中坐标为[i,j]像素的光流梯度幅值mi,j,
根据光流梯度幅值mi,j计算出第t帧人脸图像感兴趣区域的光流梯度幅值直方图bt,如下公式(10)所示,
bt={b1,b2,...,br,...,bc}(10),
公式(10)中,br为第r个组的频数,c为光流梯度幅值直方图中包含的组数;
根据如下公式(11)计算一帧人脸图像感兴趣区域的光流梯度幅值直方图中每组的频数,
br=br+1,当mi,j∈[minr,maxr](11),
公式(11)中,br为第r个组的频数,minr为第r个组的左边界值,maxr为第r个组的右边界值;
将第t帧人脸图像感兴趣区域的光流梯度幅值直方图bt作为第t帧人脸图像的人脸图像特征feat,则每个视频序列的光流梯度幅值特征为如下公式(12)所示,
fea=[fea1,…,feat,…,feas](12),
公式(12)中,s为每个视频序列样本中所包含人脸图像的总帧数(以下相同),
由此完成提取人脸图像的光流梯度幅值特征;
第三步,光流梯度幅值特征距离分析:
第(3.1)步,计算及处理特征距离:
a.计算特征距离:
根据上述第(2.2)步中求得的每个视频序列的光流梯度幅值特征fea=[fea1,…,feat,…,feas],每个视频序列的特征距离向量表示为diff=[diff1,…,difft,…,diffs],
特征距离由以下公式(13)计算,
difft(v)=e(feat,feat+n/2+v),v=1,2,3,4,5(13),
公式(13)中,n为由视频序列帧率与人脸微表情持续时间计算的人脸微表情序列最大帧数(以下相同),difft(v)为第t帧人脸图像与第t+n/2+v帧人脸图像之间的特征距离值(以下相同),feat+n/2+v为第t+n/2+v帧的人脸图像特征,v是特指第t+n/2帧后的1-5帧人脸图像,
第t帧人脸图像与第t+n/2+v帧人脸图像之间的特征距离计算如公式(14)所示,
公式(14)中,d为特征向量的维数,feat(r)表示第t帧人脸图像的光流梯度幅值直方图的第r组的频数,feat+n/2+v(r)为第t+n/2+v帧人脸图像的光流梯度幅值直方图的第r组的频数,
根据上述公式(14)求得的第t帧人脸图像与t+n/2+v帧人脸图像之间的特征距离,进行第t帧人脸图像的特征距离值计算,操作方法是,使用第t帧人脸图像与第t+n/2帧人脸图像周围五帧人脸图像的特征距离平均值来代替第t帧人脸图像与第t+n/2帧人脸图像之间的特征距离,如公式(15)所示,
公式(15)中,difft为最终求得的视频序列中第t帧人脸图像的特征距离平均值,
b.处理特征距离:
依据上述a中的每个视频序列的特征距离向量diff=[diff1,…,difft,…,diffs],绘制每个视频序列的特征距离曲线,将所得每个视频序列的特征距离曲线进行高斯平滑,高斯平滑后,得到新的每个视频序列的特征距离向量如下公式(16)所示,
diffnew=[diff1’,…,difft’,…,diffs’](16),
公式(16)中,diffnew为平滑后的每个视频序列的特征距离向量,
通过以下公式(17)计算特征距离筛选阈值t,
t=mean(diffnew)+ρ×(max(diffnew)-mean(diffnew)),ρ=0.1,0.2,...,1(17),
公式(17)中,mean(diffnew)为特征距离向量的平均值,max(diffnew)为特征距离向量的最大值,ρ为阈值调节参数,
当difft'低于特征距离筛选阈值t时,则表示第t帧人脸图像不包含在人脸微表情片段内,则将其预测标签设置为0,否则设置为1,由此完成计算及处理特征距离,得到初步人脸图像预测标签label如下公式(18)所示,
label=[label1,label2,...,labelt,...,labels](18),
公式(18)中,labelt为第t帧人脸图像的初步预测标签;
第(3.2)步,噪声消除:
对上述第(3.1)步得到的初步人脸图像预测标签label,进行消除单帧噪声及持续时间过滤的后续处理,具体操作如下:
a.消除单帧噪声处理:
消除单帧噪声处理是指将在连续预测标签为1的人脸图像帧中存在的单帧预测标签为0的人脸图像帧的单帧预测标签修改为1,和将在连续预测标签为0的人脸图像帧中存在的单帧预测标签为1的人脸图像帧的单帧预测标签修改为0,消除单帧噪声处理的公式(19)如下所示,
labelt'为消除单帧噪声处理后视频序列中第t帧人脸图像的预测标签,labelt-1为视频序列中第t-1帧人脸图像的初步预测标签,labelt+1为视频序列中第t+1帧人脸图像的初步预测标签,
由此得到经过消除单帧噪声处理后的人脸图像预测标签label',如下公式(20)所示,
label'=[label1',label2',...,labelt',...,labels'](20),
b.持续时间过滤处理:
对上述消除单帧噪声处理后得到的人脸图像预测标签label'进行人脸微表情持续时间过滤处理,根据帧率计算人脸微表情持续帧数,将得到的结果中持续时间在1/25秒~1/3秒的范围外的预测人脸微表情序列滤除,即完成持续时间过滤处理,持续时间过滤处理的公式(21)如下所示,
公式(21)中,labelt”为视频序列中第t帧人脸图像的最终预测标签(以下相同),labelvideo(d)=[labela',labela+1',...,labelb']为视频序列中第d段经过消除单帧噪声处理后的连续的预测标签为1的人脸图像视频序列帧,其中a,b分别为第d段连续预测标签为1的视频序列的起始位置与结束位置,
经过上述第(3.1)步的计算及处理特征距离和第(3.2)步的噪声消除后处理过程,得到视频序列中人脸图像的最终预测标签结果label”如下公式(22)所示,
label”=[label1”,label2”,...,labelt”,...,labels”](22),
第四步:基于光流梯度幅值特征的人脸微表情检测:
在上述第三步光流梯度幅值特征距离分析中获得人脸图像最终预测结果后,需要将预测标签与实际标签进行对比得到量化结果,考虑存在误差的情况,将视频序列中实际标签为人脸微表情的视频序列帧范围设置为[onset-n/4,offset+n/4],其中onset与offset分别为实际标签中标记的人脸微表情片段的起始帧与结束帧,将每个视频序列在此范围内的视频序列帧标记为正,其他视频序列帧标记为负,再将上述第三步中获得的人脸图像预测标签与实际标签对比,并计算出以下各项评价指标,即用公式(23)计算出预测标签为正的正样本占所有实际为正样本的比例tpr,即召回率rec,用公式(24)计算出预测标签为正的负样本占所有实际为负样本的比例fpr,用公式(25)计算出预测标签为正的正样本占所有预测标签为正的样本的比例pre,
用公式(26)计算出rec和pre的调和均值f1,
公式(23)-(26)中,tp为当预测标签为正时,实际标签也为正的视频序列帧数量,fp为当预测标签为正时,实际标签为负的视频序列帧数量,tn为当预测标签为负时,实际标签也为负的视频序列帧数量,fn为当预测标签为负时,实际标签为正的视频序列帧数量;
上述各项评价指标计算完成后,至此全部完成了基于光流梯度幅值特征的人脸微表情检测。
上述基于光流梯度幅值特征的人脸微表情检测方法,所述dlib检测器及其检测方法和帧率计算的方法是本技术领域公知的,其他操作方法是本技术领域的技术人员所能掌握的。
本发明的有益效果是:与现有技术相比,本发明的突出的实质性特点和显著进步如下:
(1)本发明方法利用flownet2网络提取视频序列中人脸图像帧间的光流场,提出的光流梯度幅值特征消除了头部偏移运动噪声,使用的特征距离计算方法,描述了运动产生的特征差异,并取特征距离均值来消除单帧噪声的影响,不包含其他干扰信息,更加适用于人脸微表情检测,并且有效避免了视频序列中的累积误差,克服了现有技术中,存在提取的人脸微表情运动特征中无法捕捉微小的人脸微表情运动,特征中包含过多干扰信息,易受头部偏移,眨眼运动和累积噪声影响及特征距离分析中单帧噪声影响的缺陷。
(2)本发明方法提出人脸边缘81个关键点拟合椭圆提取人脸感兴趣区域,仅提取人脸范围内的特征,有效避免了人脸范围外的运动噪声与眨眼噪声有助于去除人脸区域外及人脸边缘运动噪声,减弱了眼部运动对人脸微表情检测的影响。
(3)本发明方法使用了flownet2网络进行光流场的计算,提高了传统光流算法提取光流场的效率。
(4)本发明方法与cn109344744a基于深度卷积神经网络的人脸微表情动作单元检测方法相比,cn109344744a通过检测运动单元组合进行人脸微表情状态判断,无法保证人脸微表情状态中人脸动作单元组合全覆盖,且无法区分同样含有所定义动作单元组合的普通表情。本发明方法检测人脸区域内所有运动,不会出现未定义组合情况,且通过人脸微表情持续时间特性可与普通表情进行区分。
(5)本发明方法与cn107358206a一种基于感兴趣区域的光流特征矢量模值和角度结合的人脸微表情检测方法相比,cn107358206a提取的人脸感兴趣区域中丢失脸颊额头等可能包含人脸微表情运动的区域,且采用最大值计算阈值易受噪声影响。本发明方法提取完整人脸区域,不会丢失人脸微表情运动信息,且提出的阈值计算更加合理。
(6)本发明方法与cn104504366a基于光流特征的笑脸识别系统及方法相比,cn104504366a提取的光流特征仅使用光流角度信息,人脸微表情运动仅通过角度无法进行检测,本发明方法提出的光流梯度幅值特征包含完整的运动信息与时序信息,更加具有判别性,更有利于人脸微表情检测。
附图说明
下面结合附图和实施例对本发明进一步说明。
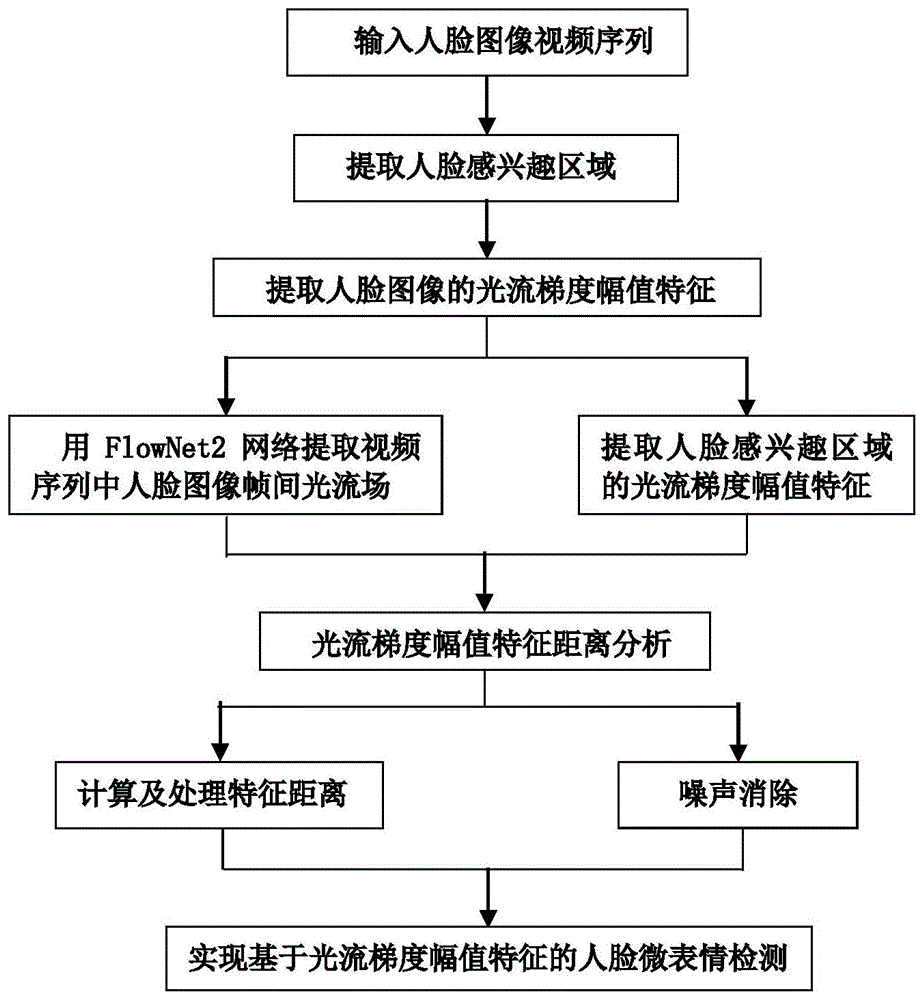
图1是本发明方法的流程示意图。
图2是人脸感兴趣区域提取部分示例图,其中:
图(2-1)是检测的人脸81个关键点示例图。
图(2-2)是提取的人脸感兴趣区域示例图。
图3是提取光流场用的flownet2网络结构图。
图4是casmeⅱ数据库视频序列样本中一帧人脸图像感兴趣区域的光流梯度幅值特征的可视化示例图。
图5是本发明方法中两帧人脸图像之间特征距离计算与后处理过程示例图,其中,(a)为单个视频序列的特征距离曲线,(b)为高斯平滑后的特征距离曲线,(c)为阈值筛选后初步人脸图像预测结果,(d)为噪声消除后人脸图像预测结果。
具体实施方式
图1所示实施例表明,本发明方法基于光流梯度幅值特征的人脸微表情检测方法的流程是:输入人脸图像视频序列→提取人脸感兴趣区域→提取人脸图像的光流梯度幅值特征:用flownet2网络提取人脸图像帧间的光流场;提取人脸感兴趣区域的光流梯度幅值特征→光流梯度幅值特征距离分析:计算及处理特征距离;噪声消除→实现基于光流梯度幅值特征的人脸微表情检测。
图2显示了人脸感兴趣区域提取部分,其中,
图(2-1)显示了人脸感兴趣区域提取部分的标号为1-81的人脸81个关键点,其中人脸轮廓关键点的标号为1-18与69-81,眼睛轮廓关键点标号为37-48,是为提取感兴趣区域选用的关键点。
图(2-2)显示了所提取的人脸感兴趣区域为完整拟合人脸边缘的椭圆形感兴趣区域。
图3显示了本发明方法中的提取光流场用的flownet2网络结构,输入参考帧图像与当前帧图像→第一层使用flownetc网络→第二层flownets网络→第三层flownets网络,得到三层堆叠网络结果,将参考帧图像和当前帧图像输入flownet-sd网络得到部分结果→融合网络,两个结果输入融合网络层获得人脸图像帧间光流场。
图4显示了casmeⅱ数据库视频序列样本中一帧图像感兴趣区域内的光流梯度幅值特征的可视化示例图,椭圆形为人脸感兴趣区域,两个空白矩形为去除的眼睛部分。
图5示例了本发明方法中两帧人脸图像之间特征距离计算与后处理的过程,其中,(a)为单个视频序列的特征距离曲线,横坐标表示视频序列的帧数,纵坐标表示每帧人脸图像的特征距离;(b)为高斯平滑后的特征距离曲线,横坐标表示视频序列的帧数,纵坐标表示每帧人脸图像的特征距离;(c)为阈值筛选后初步人脸图像预测结果,横坐标表示视频序列的帧数,纵坐标为0时,表示预测结果为人脸非微表情帧,纵坐标为1时,表示预测结果为人脸微表情帧;(d)为噪声消除后人脸图像预测结果,横坐标表示视频序列的帧数,纵坐标为0时,表示预测结果为人脸非微表情帧,纵坐标为1时,表示预测结果为人脸微表情帧。
实施例
基于光流梯度幅值特征的人脸微表情检测方法,首先根据人脸关键点拟合人脸边缘提取感兴趣区域,用flownet2网络提取视频序列中人脸图像帧间的光流场,然后提取人脸感兴趣区域的光流梯度幅值特征,再计算及处理特征距离并进行噪声消除,完成基于光流梯度幅值特征的人脸微表情检测,具体步骤如下:
第一步,提取人脸感兴趣区域:
输入人脸图像视频序列,根据人脸关键点拟合人脸边缘提取感兴趣区域,即使用dlib检测器检测人脸图像中81个标号的人脸关键点,包括在经典dlib人脸检测器中已有的68个人脸关键点和在此基础上增加的前额13个人脸关键点,其中标号为1-17及69-81的人脸关键点为人脸边缘关键点,使用这些人脸边缘关键点进行椭圆拟合得到椭圆方程q,椭圆方程q的拟合目标函数如下公式(1)所示,
公式(1)中,[p,q]为用于拟合椭圆的人脸关键点坐标,α,β,χ,δ,ε为椭圆方程q的系数,f(α,β,χ,δ,ε)为包含系数α,β,χ,δ,ε的拟合目标函数,k表示用于拟合椭圆的第k个关键点,k为用于拟合椭圆的人脸关键点个数,
当以下公式(2)成立时,
得到f(α,β,χ,δ,ε)的最小值,此时求得椭圆方程q的系数α,β,χ,δ,ε,由此得到椭圆方程q,
使用眼睛部分标号为37,39,40,42,43,44,47,49的人脸关键点进行眼睛部分区域去除,其中使用标号为37,40的人脸关键点的纵坐标与标号为39,42的人脸关键点的横坐标组成右眼矩形区域,使用标号为43,46的人脸关键点的纵坐标与标号为44,47的人脸关键点的横坐标组成左眼矩形区域,
椭圆方程q所包含的椭圆区域去除上述右眼矩形区域和左眼矩形区域即为提取的人脸感兴趣区域,所提取的人脸感兴趣区域为拟合人脸边缘的椭圆形感兴趣区域;
第二步,提取人脸图像的光流梯度幅值特征:
对上述第一步所提取的人脸感兴趣区域中的人脸图像提取光流梯度幅值特征,步骤如下,
第(2.1)步,用flownet2网络提取视频序列中人脸图像帧间光流场:
首先构建flownet2网络的三层堆叠网络,第一层使用flownetc网络,第二层和第三层均使用flownets网络,再使用融合网络融合三层堆叠网络结果与根据flownets网络改进的flownetsd网络结果得到人脸图像帧间光流场,
将现有的人脸微表情数据库中的人脸图像样本编制为视频序列,其中每个视频序列表示为{f1,...,ft,...,fs},其中s为每个视频序列中所包含的人脸图像的总帧数(以下相同),ft为当前视频序列中的第t帧人脸图像,每个视频序列以第一帧人脸图像为参考帧提取光流场,当flownet2网络输入为f1与ft时,得到第t帧人脸图像的光流场,将第一步所提取的人脸感兴趣区域与人脸图像的光流场结合,得到每帧人脸图像感兴趣区域中的光流场,由水平光流分量h与垂直光流分量v组成,本实施例中的人脸微表情数据库为casmeⅱ数据库,
水平光流分量h如下公式(3)所示,
公式(3)中,hi,j为人脸图像感兴趣区域中坐标为[i,j]像素的水平光流分量,m为人脸图像感兴趣区域中包含像素的行数(以下相同),n为人脸图像感兴趣区域中包含像素的列数(以下相同),
垂直光流分量v如下公式(4)所示,
公式(4)中,vi,j为人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量,
由此完成用flownet2网络提取人脸图像感兴趣区域的光流场;
第(2.2)步,提取人脸感兴趣区域的光流梯度幅值特征:
用如下公式(5-1)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的水平光流分量hi,j在x方向的梯度值h(x)i,j,
用如下公式(6-1)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的水平光流分量hi,j在y方向的梯度值h(y)i,j,
用如下公式(5-2)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量vi,j在x方向的梯度值v(x)i,j,
用如下公式(6-2)计算上述第(2.1)步中的人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量vi,j在y方向的梯度值v(y)i,j,
上述公式(5-1)、(5-2)、(6-1)和(6-2)中,i为像素横坐标,j为像素纵坐标,
进一步用如下公式(7)计算坐标为[i,j]像素的水平光流分量hi,j的梯度幅值m(h)i,j,
进一步用如下公式(8)计算人脸图像感兴趣区域中坐标为[i,j]像素的垂直光流分量vi,j的梯度幅值m(v)i,j,
根据水平光流分量hi,j的梯度幅值m(h)i,j与垂直光流分量vi,j的梯度幅值m(v)i,j,通过如下公式(9)计算人脸图像感兴趣区域中坐标为[i,j]像素的光流梯度幅值mi,j,
根据光流梯度幅值mi,j计算出第t帧人脸图像感兴趣区域的光流梯度幅值直方图bt,如下公式(10)所示,
bt={b1,b2,...,br,...,bc}(10),
公式(10)中,br为第r个组的频数,c为光流梯度幅值直方图中包含的组数,本实施例中c=50;
根据如下公式(11)计算一帧人脸图像感兴趣区域的光流梯度幅值直方图中每组的频数,
br=br+1,当mi,j∈[minr,maxr](11),
公式(11)中,br为第r个组的频数,minr为第r个组的左边界值,maxr为第r个组的右边界值;
将第t帧人脸图像感兴趣区域的光流梯度幅值直方图bt作为第t帧人脸图像的人脸图像特征feat,则每个视频序列的光流梯度幅值特征为如下公式(12)所示,
fea=[fea1,…,feat,…,feas](12),
公式(12)中,s为每个视频序列样本中所包含人脸图像的总帧数(以下相同),
由此完成提取人脸图像的光流梯度幅值特征;
第三步,光流梯度幅值特征距离分析:
第(3.1)步,计算及处理特征距离:
a.计算特征距离:
根据上述第(2.2)步中求得的每个视频序列的光流梯度幅值特征fea=[fea1,…,feat,…,feas],每个视频序列的特征距离向量表示为diff=[diff1,…,difft,…,diffs],
特征距离由以下公式(13)计算,
difft(v)=e(feat,feat+n/2+v),v=1,2,3,4,5(13),
公式(13)中,n为由视频序列帧率与人脸微表情持续时间计算的人脸微表情序列最大帧数(以下相同),difft(v)为第t帧人脸图像与第t+n/2+v帧人脸图像之间的特征距离值(以下相同),feat+n/2+v为第t+n/2+v帧的人脸图像特征,v是特指第t+n/2帧后的1-5帧人脸图像,本实施例中,casmeⅱ数据库帧率为200fps,则n=65,
第t帧人脸图像与第t+n/2+v帧人脸图像之间的特征距离计算如公式(14)所示,
公式(14)中,d为特征向量的维数,feat(r)表示第t帧人脸图像的光流梯度幅值直方图的第r组的频数,feat+n/2+v(r)为第t+n/2+v帧人脸图像的光流梯度幅值直方图的第r组的频数,本实施例中d=50;
根据上述公式(14)求得的第t帧人脸图像与t+n/2+v帧人脸图像之间的特征距离,进行第t帧人脸图像的特征距离值计算,操作方法是,使用第t帧人脸图像与第t+n/2帧人脸图像周围五帧人脸图像的特征距离平均值来代替第t帧人脸图像与第t+n/2帧人脸图像之间的特征距离,如公式(15)所示,
公式(15)中,difft为最终求得的视频序列中第t帧人脸图像的特征距离平均值,
b.处理特征距离:
依据上述a中的每个视频序列的特征距离向量diff=[diff1,…,difft,…,diffs],绘制每个视频序列的特征距离曲线,将所得每个视频序列的特征距离曲线进行高斯平滑,高斯平滑后,得到新的每个视频序列的特征距离向量为如下公式(16)所示,
diffnew=[diff1’,…,difft’,…,diffs’](16),
公式(16)中,diffnew为平滑后的每个视频序列的特征距离向量,
通过以下公式(17)计算特征距离筛选阈值t,
t=mean(diffnew)+ρ×(max(diffnew)-mean(diffnew)),ρ=0.1,0.2,...,1(17),
公式(17)中,mean(diffnew)为特征距离向量的平均值,max(diffnew)为特征距离向量的最大值,ρ为阈值调节参数,
当difft'低于特征距离筛选阈值t时,则表示第t帧人脸图像不包含在人脸微表情片段内,则将其预测标签设置为0,否则设置为1,由此完成计算及处理特征距离,得到初步人脸图像预测标签label如下公式(18)所示,
label=[label1,label2,...,labelt,...,labels](18),
公式(18)中,labelt为第t帧人脸图像的初步预测标签;
第(3.2)步,噪声消除:
对上述第(3.1)步得到的初步人脸图像预测标签label,进行消除单帧噪声及持续时间过滤的后续处理,具体操作如下:
a.消除单帧噪声处理:
消除单帧噪声处理是指将在连续预测标签为1的人脸图像帧中存在的单帧预测标签为0的人脸图像帧的单帧预测标签修改为1,和将在连续预测标签为0的人脸图像帧中存在的单帧预测标签为1的人脸图像帧的单帧预测标签修改为0,消除单帧噪声处理的公式(19)如下所示,
公式(19)中,labelt'为消除单帧噪声处理后视频序列中第t帧人脸图像的预测标签,labelt-1为视频序列中第t-1帧人脸图像的初步预测标签,labelt+1为视频序列中第t+1帧人脸图像的初步预测标签,
由此得到经过消除单帧噪声处理后的人脸图像预测标签label'如下公式(20)所示,
label'=[label1',label2',...,labelt',...,labels'](20),
b.持续时间过滤处理:
对上述消除单帧噪声处理后得到的人脸图像预测标签label'进行人脸微表情持续时间过滤处理,根据帧率计算人脸微表情持续帧数,将得到的结果中持续时间在1/25秒~1/3秒的范围外的预测人脸微表情序列滤除,即完成持续时间过滤处理,持续时间过滤处理的公式(21)如下所示,
公式(21)中,labelt”为视频序列中第t帧人脸图像的最终预测标签(以下相同),labelvideo(d)=[labela',labela+1',...,labelb']为视频序列中第d段经过消除单帧噪声处理后的连续的预测标签为1的人脸图像视频序列帧,其中a,b分别为第d段连续预测标签为1的视频序列的起始位置与结束位置,
经过上述第(3.1)步的计算及处理特征距离和第(3.2)步的噪声消除的后处理过程,得到视频序列中人脸图像的最终预测标签结果label”如公式(22)所示,
label”=[label1”,label2”,...,labelt”,...,labels”](22),
第四步:基于光流梯度幅值特征的人脸微表情检测:
在上述第三步光流梯度幅值特征距离分析中获得人脸图像最终预测结果之后,需要将预测标签与实际标签进行对比,以得到量化结果,这里考虑存在误差的情况,将视频序列中实际标签为人脸微表情的视频序列帧范围设置为[onset-n/4,offset+n/4],其中onset与offset分别为实际标签中标记的人脸微表情片段的起始帧与结束帧,本实施例中,casmeⅱ数据库帧率为200fps,则n=65,将每个视频序列在此范围内的视频序列帧标记为正,其他视频序列帧标记为负,再将上述第三步中获得的人脸图像预测标签与实际标签对比,并计算出以下各项评价指标,即用公式(23)计算出预测标签为正的正样本占所有实际为正样本的比例tpr,即召回率rec,用公式(24)计算出预测标签为正的负样本占所有实际为负样本的比例fpr、用公式(25)计算出预测标签为正的正样本占所有预测标签为正的样本的比例pre,
用如下公式(26)计算出rec和pre的调和均值f1,
公式(23)-(26)中,tp为当预测标签为正时,实际标签也为正的视频序列帧数量,fp为当预测标签为正时,实际标签为负的视频序列帧数量,tn为当预测标签为负时,实际标签也为负的视频序列帧数量,fn为当预测标签为负时,实际标签为正的视频序列帧数量;
上述各项评价指标计算完成后,至此全部完成基于光流梯度幅值特征的人脸微表情检测。
本实施例中,所述dlib检测器及其检测方法和帧率计算的方法是本技术领域公知的,其他操作方法是本技术领域的技术人员所能掌握的。
- 还没有人留言评论。精彩留言会获得点赞!