基于少量欺诈样本的银行高风险欺诈客户识别方法与流程
本发明涉及到银行管理系统中的客户数据处理技术领域,具体涉及到对银行高风险欺诈客户信息识别方法改进方面。
背景技术:
机器学习是一种重要的金融科技创新手段,近年来在国内外金融机构和金融科技企业中被尝试应用到风险防范、反欺诈等领域。逻辑回归、树模型等常被用于银行机构,针对大规模数据集挖掘深层次业务场景特征进而建立有监督、无监督等类型的学习模型,以提升欺诈识别能力。有监督模型能降低人工成本同时达到较稳定的效果,但对数据集要求高(标签准确且完整),无监督模型需要引入后续的数据分析,花费更多的人力成本。银行欺诈风险呈现出更加隐蔽、专业的特点,发展出更多的作案手法和表现形式。现今欺诈客户样本极具代表性,而剩余未标记欺诈的客户数据未必代表一定无欺诈行为,即未标记为欺诈样本中混杂着欺诈客户与未欺诈客户,如果每一条数据都用人工标记过于浪费成本。传统欺诈检测,例如依赖专家规则、黑名单库等方法,已经不能适应新的欺诈挑战。
技术实现要素:
综上所述,本发明的目的在于解决现有的学习模型对大规模数据识别存在效率低,且容易出现存在欺诈客户未被发现的技术不足,而提出基于一种少量欺诈样本的银行高风险欺诈客户识别方法。
为解决本发明提出的技术问题,采用的技术方案为:
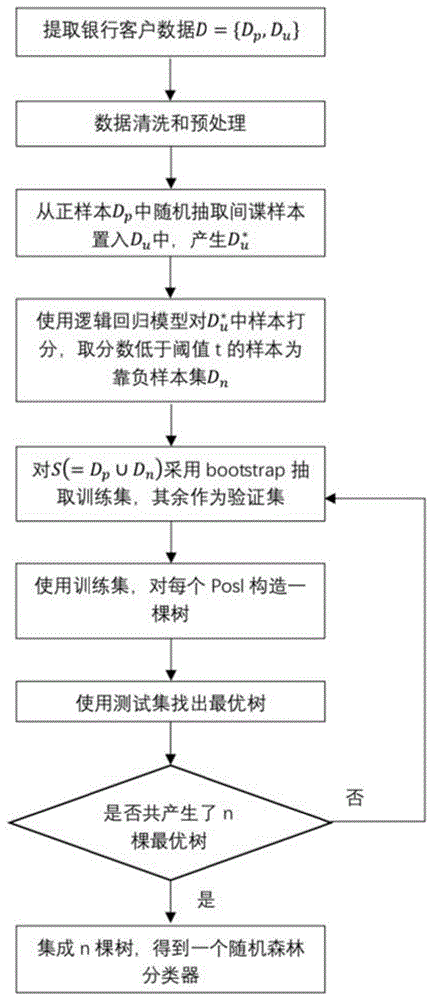
基于少量欺诈样本的银行高风险欺诈客户识别方法,其特征在于所述方法包括有如下步骤:
s1:提取银行客户数据d,d={dp,du},其中dp表示已标记为“欺诈”的客户,du表示未标记为“欺诈”的客户群体;dpi=<ai,yi>,dui=<ai>,其中ai为某客户的特征变量,yi为对应类别;yi=+1代表“欺诈”,yi=-1代表“非欺诈”);aa为所有客户的特征变量组成的矩阵;
s2:对原始数据进行数据预处理和数据清洗;
s3:从dp中随机抽出s%的样本作为间谍样本,并放入du中产生新的数据集
s4:利用
s5:用dp和dn,对应类别分别为yi=+1和yi=-1;训练随机森林模型,posl为样本s(=dp∪dn)中正样本的比例,使用bootstrap从s中抽取样本做训练集,最终约有
s6:将posl分别设置为0.1-0.9,步长为0.1,对应每个posl,使用训练集数据构造一棵树tj,j=1...9
s7:利用验证集数据从步骤s6产生的9棵树中找出最优树f。
s8:重复步骤s5到步骤s7直到得到n棵最优树,集成后得到一个包含n棵树的随机森林,利用上述训练得到的随机森林,对银行客户数据进行输入预测,预测类别yi=+1的客户认定为高风险欺诈客户。
作为对本发明作进一步限定的技术方案包括有:
步骤s2中所述的数据预处理和数据清洗包括:检查数据质量,清除重复数据和异常数据,填补解释变量a的缺失值并进行归一化,并将类别变量转化为数值型变量。
步骤s4中的阈值t优选为15%。
其中,步骤s6中构造一棵树tj的步骤如下:
s61、从属性集合a中随机有放回抽样形成新的属性空间a′;
s62、对属性空间a′中的每个属性aj,计算信息增益,|p|和|u|分别表示训练集中正样本个数和未标记样本个数,|pnode|和|unode|分别表示节点数据中正样本个数和未标记样本个数,信息增益计算方法如下:
p-1=1-p1
s63、具有最大信息增益的属性选作分割属性并从分割点伸展出子节点;
s64、对每个子节点重复步骤s61至步骤s63,直到树无法分裂生长完全。
其中,步骤s7中找出最优树的步骤如下:
s71:将tj,j=1...9分别作用于测试集上,计算测试集中正样本个数|pv|,未标记样本个数|uv|,假负数|fuv|,以及假正数|fpv|;
s72:计算评估指数:
s73:最小评估指数对应的树为最优树。
本发明的有益效果为:本发明基于少量欺诈客户样本,通过引入间谍样本找到可靠负样本集进行建模,有提纯未标记数据集的作用,相比直接建模精度更高,也克服了有监督模型需从未标记数据池中标记欺诈客户要消耗大量时间和人力资源的问题。另一方面,通过遍历不确定的正样本比例posl,最优树集成形成随机森林,兼具随机森林并行算法的快速高效和更高的精度;运用半监督学习和随机森林结合的高风险欺诈客户识别技术,以减少人工标记样本的成本,提高识别高风险客户的效率。
附图说明
图1为本发明的识别方法步骤流程图。
具体实施方式
以下结合附图和本发明具体实施例对本发明的技术方案作进一步说明。参照图1中所示,本发明基于少量欺诈样本的银行高风险欺诈客户识别方法包括有如下步骤:
s1:提取银行客户数据d,d={dp,du},其中dp表示已标记为“欺诈”的客户,du表示未标记为“欺诈”的客户群体;dpi=<ai,yi>,dui=<ai>,其中ai为某客户的特征变量,yi为对应类别;yi=+1代表“欺诈”,yi=-1代表“非欺诈”);aa为所有客户的特征变量组成的矩阵。
s2:对原始数据进行数据预处理和数据清洗;所述的数据预处理和数据清洗包括:检查数据质量,清除重复数据和异常数据,填补解释变量a的缺失值并进行归一化,并将类别变量转化为数值型变量。
s3:从dp中随机抽出s%的样本作为间谍样本,并放入du中产生新的数据集
s4:利用
s5:用dp和dn,对应类别分别为yi=+1和yi=-1;训练随机森林模型,posl为样本s(=dp∪dn)中正样本的比例,使用bootstrap(随机有放回抽样的方式)从s中抽取样本做训练集,最终约有
s6:将posl分别设置为0.1-0.9,步长为0.1,对应每个posl,使用训练集数据构造一棵树tj,j=1...9,构造一棵树tj的步骤如下:
s61、从属性集合a中随机有放回抽样形成新的属性空间a′;
s62、对属性空间a′中的每个属性aj,计算信息增益,|p|和|u|分别表示训练集中正样本个数和未标记样本个数,|pnode|和|unode|分别表示节点数据中正样本个数和未标记样本个数,信息增益计算方法如下:
p-1=1-p1
s63、具有最大信息增益的属性选作分割属性并从分割点伸展出子节点;
s64、对每个子节点重复步骤s61至步骤s63,直到树无法分裂生长完全。
s7:利用验证集数据从步骤s6产生的9棵树中找出最优树f。找出最优树的步骤如下:
s71:将tj,j=1...9分别作用于测试集上,计算测试集中正样本个数|pv|,未标记样本个数|uv|,假负数|fuv|,以及假正数|fpv|;
s72:计算评估指数:
s73:最小评估指数对应的树为最优树。
s8:重复步骤s5到步骤s7直到得到n棵最优树,集成后得到一个包含n棵树的随机森林,利用上述训练得到的随机森林,对银行客户数据进行输入预测,预测类别yi=+1的客户认定为高风险欺诈客户。
实际应用中,银行数据量大,欺诈客户占比小,标签获取效率较低,且可能存在未发现的欺诈客户,因此本发明引入半监督学习方法配合随机森林优化框架,找到可靠负样本集进而形成由最优树集成的随机森林,在只有少量的已标记欺诈的客户数据的条件下,达到较高的高风险欺诈客户的识别精度,避免了未标记数据不纯导致有监督模型精度受限的问题,也有助于银行业务人员针对性的查验;减少人工标记样本的成本,提高识别高风险客户的效率。
- 还没有人留言评论。精彩留言会获得点赞!