一种基于关系指导及双通道交互机制的问题生成方法与流程
本发明涉及自然语言处理问题生成领域,具体涉及一种基于关系指导及双通道交互机制的问题生成方法。
背景技术:
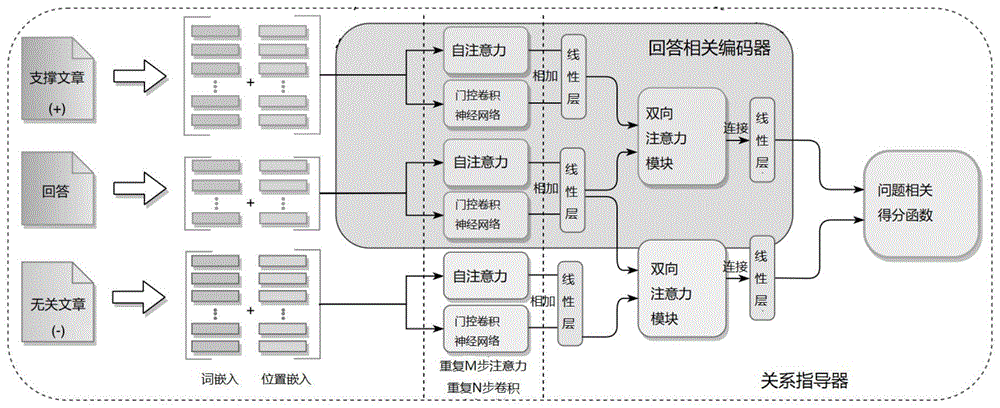
:基于文章的问题生成是一项挑战性的任务,需要在给定回答和一段文本的基础上生成正确且通顺的问题。问题生成目前在自然语言处理领域越来越受到重视,也有着许多成功的应用领域,比如为问题回答系统提供有价值的问题、自动生成作业的题目、以及在对话系统中自动提出问题来得到反馈。目前基于神经网络的问题生成方法主要包含两个步骤,第一步是用监督神经网络或者人为规则从文章中提取出几个重要的句子,第二步是用一个编码器-解码器框架根据提取出的句子生成问题。现有的技术主要存在以下缺陷:训练监督神经网络需要的数据集需要大量人力进行标注,同时现有的问题-回答数据集在问题类型、语言风格等方面有着很强的差异;人为设计的规则并不高效而且很难迁移到新的领域;现有的方法利用编码器-解码器神经网络虽然取得了较好的效果,但是只提取了与回答相关的几个句子来生成问题,而忽视了回答和全文之间的联系。为了克服这些缺陷,本发明将利用全文的信息来生成回答相关的问题。技术实现要素:本发明的目的在于解决现有技术中的问题,为了克服现有技术仅仅根据与回答相关的几个句子来生成问题,而忽视了回答和全文之间的联系的问题,本发明提供了一种基于关系指导及双通道交互机制的问题生成方法,提出一种利用弱监督标注来提高问题生成质量的端到端的框架,不同于现有的编码器-解码器模型,本发明利用弱监督标注来对相关文章和回答的范围之间的关系建模,并且将学习到的关系转移到问题生成系统。具体来说,本发明将设计名为关系指导器的判别器来判断一篇文章是否提供了充分的信息来得到该回答。从另一个角度,关系指导器旨在从文章中找到有助于理解回答的内容以及确定对获取回答无关的欺骗性文章。之后,本发明设计了一个双通道交互模块,该模块包含对原有通道以及关系指导器通道输出的表示的多步建模,以及一个决定两个通道信息通量的控制门。最后,本发明将把关系指导器和双通道交互模块纳入编码器-解码器框架来预测问题。本发明所采用的具体技术方案是:基于关系指导及双通道交互机制的问题生成方法,包括以下步骤:1、针对一组回答、支撑文章和无关文章,构建包含答案和对应文章之间关系的关系指导器,所述关系指导器中包含了回答相关编码器和问题相关得分函数;2、对步骤1得到的关系指导器进行预训练,得到训练好的关系指导器,将关系指导器中的回答相关编码器的权重参数固定,得到参数固定的回答相关编码器;3、构建问题生成网络,所述问题生成网络包括词嵌入、上下文编码器、双通道交互模块、问题生成器和步骤2得到的参数固定的回答相关编码器;4、针对一组回答和文章,通过问题生成网络中的词嵌入、上下文编码器和步骤2得到的参数固定的回答相关编码器,得到文章、回答以及回答相关的文章的上下文表示;5、将步骤4得到的文章、回答以及回答相关的文章的上下文表示输入问题生成网络的双通道交互模块,得到文章的联合表示g;6、将步骤5得到文章的联合表示的输入问题生成网络的问题生成器,解码生成问题;问题生成是一个解码的过程。问题生成器利用基于注意力机制的长短期记忆解码器来解决词汇外的问题。编码器注意力记忆是步骤5中得到的文章的联合表示g。之后,在每个解码步骤中,将注意力结果和之前的词嵌入插入解码单元,其中编码器输出的注意力结果被用于初始化解码器中长短期记忆的隐藏状态。7、经过训练,得到最终的问题生成网络模型,该模型在给定回答和一段文章的基础上生成对应的问题。本发明具备的有益效果:本发明提出了一种利用弱监督标注来提高问题生成质量的端到端的框架,不同于现有的编码器-解码器模型,本发明利用弱监督标注来对相关文章和回答的范围之间的关系建模,并且将学习到的关系转移到问题生成系统。具体来说,本发明设计了名为关系指导器的判别器来判断一篇文章是否提供了充分的信息来得到该回答。从另一个角度,关系指导器旨在从文章中找到有助于理解回答的内容以及确定对获取回答无关的欺骗性文章。之后,本发明设计了一个双通道交互模块,该模块包含对原有通道以及关系指导器通道输出的表示的多步建模,以及一个决定两个通道信息通量的控制门。最后,本发明把关系指导器和双通道交互模块融入编码器-解码器框架来预测问题。现有的问题生成方法只提取了与回答相关的几个句子来生成问题,而忽视了回答和全文之间的联系。本发明利用了全文的信息来生成回答相关的问题,克服了现有问题的相关缺陷。附图说明图1为关系指导器的结构示意图;图2为问题生成网络的整体结构示意图。具体实施方式下面结合附图和具体实施方式对本发明做进一步阐述和说明。如图1及图2所示,本发明一种基于关系指导及双通道交互机制的问题生成方法,包括以下步骤:步骤一、针对一组回答、支撑文章和无关文章,构建包含答案和对应文章之间关系的关系指导器,所述关系指导器的结构示意图如图1所示,包括词嵌入、位置嵌入、回答相关问题编码器和问题相关得分函数,其中回答相关问题编码器由自注意力单元、门控卷积神经网络单元、双向注意力模块、全连接的前馈层和relu激活函数组成;关系指导器的具体工作流程如下:将回答、支撑文章和来自搜索引擎的无关文章组成三元组作为输入序列,三元组中的每一个词都用一个预训练的词嵌入表示,并采用位置嵌入对词的位置进行编码,将词嵌入和位置嵌入的结果相加,得到三元组的最终表示(p+,a,p-),其中a为回答的最终表示,p+为支撑文章的最终表示,p-为无关文章的最终表示;将三元组的最终表示(p+,a,p-)输入回答相关编码器,所述回答相关编码器包括自注意力单元、门控卷积神经网络单元和双向注意力模块;三元组的最终表示(p+,a,p-)由门控卷积神经网络和自注意力机制按以下公式编码:其中,[·]m和[·]n表示自注意力单元或门控卷积神经网络单元的重复次数分别为m次和n次,每个自注意力单元selfatt(·)和门控卷积神经网络单元gatedcnn(·)利用了残差机制以及层归一化函数,f(·)是一个全连接的前馈层,将relu作为激活函数;为编码后的支撑文章的最终表示,为编码后的无关文章的最终表示,为编码后的回答的最终表示;将和输入双向注意力模块,按照以下公式获得支撑文章和答案之间的相似性矩阵s∈rn×m:其中,ws是一个可训练的矩阵,为编码后的支撑文章的最终表示中的第i个向量,为编码后的回答的最终表示中的第j个向量,[;]表示向量的连接,⊙表示向量的按位相乘,sij为编码后的支撑文章的最终表示中的第i个向量和编码后的回答的最终表示中的第j个向量之间的相似性表示;计算关于的注意力加权向量计算关于的注意力加权向量g:βi=softmax(maxrow(sij))将g按照以下公式结合,得到双向注意力增强的支撑文章增强表示同理,将和输入双向注意力模块,得到双向注意力增强的无关文章增强表示1.3)采用前馈层获取支撑文章增强表示、无关文章增强表示的分数,通过以下问题相关得分函数进行计算:其中,w(p+,a)是一个可训练的权重矩阵,是支撑文章-回答组合的相关性分数,是无关文章-回答组合的相关性分数,meanpooling是平均池化操作,sigmoid为sigmoid激活函数;步骤二、对步骤一得到的关系指导器进行预训练,得到训练好的关系指导器,将关系指导器中的回答相关编码器的权重参数固定,得到参数固定的回答相关编码器;步骤三、构建问题生成网络,如图2所示,所述问题生成网络包括词嵌入、上下文编码器、双通道交互模块、问题生成器和步骤二得到的参数固定的回答相关编码器;所述问题生成网络的具体工作流程如下:(1)针对一组回答与文章,采用词嵌入,得到文章的表示和回答的表示;(2)将文章的表示和回答的表示分别输入上下文编码器,由两个共享权重的双向长短期记忆模块进行上下文编码,输出文章的上下文表示和回答的上下文表示;(3)将文章的表示和回答的表示输入步骤二得到的参数固定的回答相关编码器,输出回答相关的文章的上下文表示。(4)将步骤(3)得到的文章的上下文表示、回答的上下文表示和回答相关的文章的上下文表示输入双通道交互模块;所述双通道交互模块包括两个通道:原交互通道和转移交互通道;所述原交互通道由原交互单元和上下文编码器依次连接组成,转移交互通道由转移交互单元和上下文编码器依次连接组成,所述原交互单元、转移交互单元、上下文编码器的输出侧还分别连接一个线性层和relu激活函数;将文章的上下文表示和回答的上下文表示输入双通道交互模块的原交互通道,将文章-回答组合的相关性分数和回答的上下文表示输入双通道交互模块的转移交互通道,所述双通道交互模块中的原交互单元、转移交互单元以及两个上下文编码器均采用残差机制,重复k步,得到原交互通道的输出x和转移交互通道的输出y;所述原交互单元和转移交互单元均采用双向注意力模块。(5)采用控制门,将原交互通道的输出x和转移交互通道的输出y根据以下公式结合,得到文章的联合表示g:g=σ(wg[x;y]+bg)g=g·x+(1-g)·y其中,wg和bg是可训练的参数,σ是激活函数,g是控制门,g是文章的联合表示,·表示矩阵按位相乘,[;]表示向量的连接。(6)将步骤(5)得到的文章的联合表示g输入问题生成器,解码生成问题;问题生成是一个解码的过程,问题生成器利用基于注意力机制的长短期记忆解码器来解决词汇外的问题。编码器注意力记忆是步骤(5)中得到的文章的联合表达g,之后,在每个解码步骤中,将注意力结果和之前的词嵌入插入解码单元,其中编码器输出的注意力结果被用于初始化解码器中长短期记忆的隐藏状态。下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。实施例本发明在msmarco数据集以及squad数据集上进行实验。msmarco数据集是bing收集的大规模数据集,包含从3563535个网络文档中提取的1010916个问题、8841823个相关文章。本发明利用msmarco来训练关系指导器。在msmarco数据集中,每个问题-答案组合后还有10篇从搜索引擎上获取的文章,一些文章不足以得出可以回答该问题的答案。本发明将这些无关文章标记为负样本,将支撑文章标记为正样本。squad数据集是最具影响力的阅读理解数据集之一,包含对536篇wikipedia文章的超过10万个问题,以及在文章中包含的答案范围。本发明将整个squad数据集在文章层面划分为训练集(80%)、开发集(10%)以及测试集(10%)。为了客观地评价本发明的算法的性能,本发明在所选出的测试集中,使用了bleu1、bleu2、bleu3、bleu4、rouge-l、meteor这六种指标来对于本发明的效果进行自动评价,且引入了三个人工评价指标流利度、准确率、turing@1来验证模型的效果。按照具体实施方式中描述的步骤,针对六个指标的自动评价的结果如表1所示,对比其他4种现有方法针对流利度标准所得的实验结果如表2所示,对比其他4种现有方法针对accuracy标准所得的实验结果如表3所示,对比其他4种现有方法针对turing@1标准所得的实验结果如表4所示,本方法表示为:表1针对六个指标的自动评价的结果bleu1bleu2bleu3bleu4rouge-lmeteor本发明32.6522.1415.8612.0332.3620.25表2针对流利度标准所得的实验结果模型seq2seqseq2seq+attentionseq2seq+attention+copy本模型流利度1.092.833.844.14表3针对准确率标准所得的实验结果模型seq2seqseq2seq+attentionseq2seq+attention+copy本模型准确率0.010.210.330.53表4针对turing@1标准所得的实验结果模型seq2seqseq2seq+attentionseq2seq+attention+copy本模型turing@10.8%7.8%32.6%58.9%当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1