一种应用统计方式及大数据进行修正的人工智能模块的制作方法
1.本发明是有关于大数据及人工智能的应用,尤其是一种应用统计方式及大数据进行修正的人工智能模块。
背景技术:
2.随着计算机科技的进步,人工智能已经得到很大的突破。应用人工智能,可以使得计算机具有与专家相同等级的解答能力,甚至某些方面的能力已经超过专业人士。大部分的人工智能由专家系统所达成。而专家系统必须配置数据库,其储存专业的知识,使得专家系统可以应用该专业知识,以及既定的逻辑,再根据推理引擎的推理而得出所需要的答案。所以人工智能所能处理的问题受到其所配置的数据库中所储存的知识的影响。如果所储存的知识脱离现实的情况,则所做出来的推理也会不切实际,甚或错误。
3.另外由于网络科技的进步,人类可以通过计算机系统在网络中应用大数据的技术撷取大量的信息。而某些信息的正确性往往是由所撷取的巨量数据中的分布所决定。如用户欲知道某种产品的喜好度,则可以通过网络撷取数据并且根据不同的族群或年龄层级而得到这些不同的个体中的喜好情况的分布。在将这些分布状况做统计的运算而得到对该产品喜好度的概念。但是纵然母体没有改变,但这些分布仍会随着时间做改变,比如对某个产品的喜好度有所变动。所以相关的人工智能系统如果有处理这一方面的数据,则必须随时更动相关的信息。问题是如果这些所得到数据的变动实际上往往只是统计误差,如果由网络所得到的数据不同即变更数据库中的数据,结果造成频繁的更动,并没有实际上的意义。
4.故本案希望提出一种崭新的大数据、人工智能及统计的整合系统,以解决上述先前技术上的缺陷。
技术实现要素:
5.所以本发明的目的是解决上述现有技术技术上的问题,本发明应用大数据在网络中撷取某一特定议题的分布状况,并根据此分布状况计算其统计量,并且对于不同的时间所得到的统计量进行检定,以确定同一母体之下该统计量是否产生显著的改变,应用此一方式变更储存在人工智能系统中数据库的数据,使得用户可以得到实时且接近事实的信息。
6.为实现上述目的,本发明中提出一种应用统计方式及大数据进行修正的人工智能模块,包括:一电子装置,包括一信息处理系统;该信息处理系统包括:一数据搜寻器,用于在网络或大型数据库中搜寻数据;一数据处理器,该数据处理器与该数据搜寻器连接,主要是对于由该数据搜寻器所搜寻的数据进行整理,其中包括以串流的方式处理所搜寻的数据,并将这些串流的数据形成批次数据,以对该批次数据进行处理;一统计处理器,该统计处理器与该数据处理器连接,对于该数据处理器的批次数据进行统计处理,得到统计分布的数据;一人工智能系统,该人工智能系统与该统计处理器连接;该统计处理器包括一统计运算元件及一统计数据库,该统计运算元件主要是进行统计相关的运算并决定是否需要将
统计量输出;该统计数据库则用于储存不同批次的统计数据;以及该统计运算元件通过统计检定的方法,计算对于一统计项目,于相同母体下所得到不同样本的统计分布是否产生显著的改变,且将统计的结果输出到该人工智能系统;如果产生显著的改变时,则该人工智能系统改变其所储存的数据。
7.一个优选的方案是,该数据处理器包括:至少一串流数据处理元件,该串流数据处理元件与该数据搜寻器连接,并由该数据搜寻器接收串流数据,并应用串流处理的方式实时处理并产生所要的结果;一批次数据处理元件,该批次数据处理元件与该串流数据处理元件连接,并接收来自该串流数据处理元件的串流数据,将这些串流数据累积成批次数据,以对该批次数据进行必要的运算;以及一大数据记忆元件,该大数据记忆元件与该批次数据处理元件连接,用于储存系统中所有的数据;其中该数据处理器针对某一同类型的数据应用该串流数据处理元件收集之后再输入该批次数据处理元件,并依据时间或内容形成不同的批次数据,必要时将所形成的批次数据储存在该大数据记忆元件中。
8.一个优选的方案是,由该串流数据处理元件针对一设定的项目依据不同的属性,随着时间做间断性或连续性的声量搜寻,然后再将这些串流数据输入该批次数据处理元件,由该批次数据处理元件将某一段时间的数据累积形成批次数据;由该批次数据能够得到不同属性对于该搜寻项目的发声数量所形成的分布,并将计算这些分布的统计量,并将这些统计量输出。
9.一个优选的方案是,统计处理器对于同一母体在不同时间所得到的两个统计量通过统计检定,以检定其误差是否在能够接受的显著水平α(significance level)内。
10.一个优选的方案是,该统计处理器将不同时间的统计数据按照时间轴列出,因此用户能够观察不同时间中趋势的变动。
11.一个优选的方案是,对于同一搜寻项目中,如果同一段时间所得到的数据量的增加与前段时间所得到的数据量的变动达到一设定值时,也就是网络声量有明显的改变时,该统计处理器输出此一结果到下一级的单元中。
12.一个优选的方案是,该统计处理器对于由该数据处理器的批次数据处理元件所得到的批次数据或储存在该数据处理器的一大数据记忆元件中的批次数据进行统计处理,得到统计分布的数据。
13.一个优选的方案是,该至少一串流数据处理元件为并连到该数据搜寻器的多个串流数据处理元件,因此能够在不同的网络中撷取不同的数据。
14.一个优选的方案是,该人工智能系统包括:一数据库,其与该统计处理器连接,其中该数据库接收来自该统计处理器的统计数据;该数据库显示一组事实,其作为该人工智能系统的一项基本数据;一逻辑库,其中储存专家的思考逻辑,这些逻辑结合用户输入的所欲得到答案的问题,这个问题并结合所储存的逻辑而形成一段叙述;一推理引擎,该推理引擎与该逻辑库及该数据库连接,用于接收来自该逻辑库的一段叙述,并将该段叙述与该数据库中的数据进行比对,以得到一专家的解答;以及
一用户界面,该用户界面与该推理引擎及该逻辑库连接,用户通过该用户界面输入所欲得到答案的问题。
15.一个优选的方案是,该统计处理器还包括一统计数据库,用于储存不同批次的统计数据。由下文的说明可更进一步了解本发明的特征及其优点,阅读时并请参考附图。
附图说明
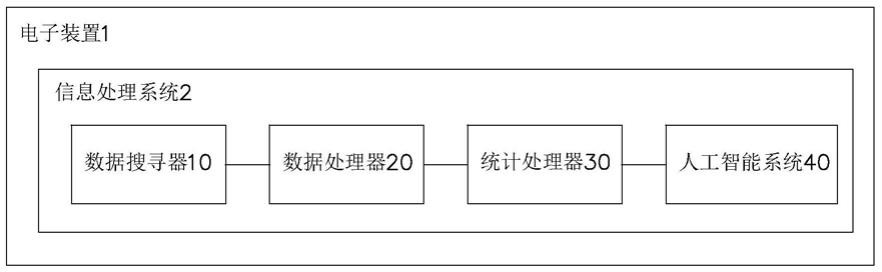
16.图1显示本发明的主要组件的架构方块图。
17.图2显示本发明的数据搜寻器、数据处理器、统计处理器及人工智能系统的组件连接架构方块图。
18.图3显示本发明的数据搜寻器、数据处理器、统计处理器及人工智能系统的数据传送的应用示意图。
19.附图标记说明1、电子装置,2、信息处理系统,3、网络或大型数据库,10、数据搜寻器,20、数据处理器,21、串流数据处理元件,22、 批次数据处理元件,23、大数据记忆元件,30、统计处理器,31、统计运算元件,32、 统计数据库,40、人工智能系统,41、数据库,42、逻辑库,43、推理引擎,44、用户界面,60、信息装置,90、串流数据,92、批次数据。
具体实施方式
20.就本案的结构组成,及所能产生的功效与优点,配合说明书附图,举本案的一较佳实施例详细说明如下。
21.请参考图1至图3所示,显示本发明的应用统计方式及大数据进行修正的人工智能模块,包括下列组件:一电子装置1,包括一信息处理系统2(如图1所示)。该信息处理系统2包括:一数据搜寻器10,主要用于在网络或大型数据库3中搜寻数据,该数据的型态包括人与人沟通的数据(如社交媒体)、人与机器沟通的数据(如web或智能型装置)、机器对机器沟通的数据(如物联网或商业事务数据)。数据的来源可以分为内部或外部数据,数据是通过输入点输入传送到后端。
22.一数据处理器20,该数据处理器20与该数据搜寻器10连接,主要是对于由该数据搜寻器10所搜寻的数据进行整理,其中包括以串流的方式处理所搜寻的数据,并将这些串流的数据形成批次数据,以对该批次数据进行处理。如图2所示,该数据处理器20包括:至少一串流数据处理元件21,该串流数据处理元件21与该数据搜寻器10连接,并由该数据搜寻器10接收串流数据90(如图3所示),并应用串流处理的方式实时处理并产生所要的结果。
23.该至少一串流数据处理元件21可以是并连到该数据搜寻器10的多个串流数据处理元件21,因此可以在不同的网络中撷取不同的数据,如一串流数据处理元件21撷取facebook中的数据,另一串流数据处理元件21撷取line中的数据。
24.一批次数据处理元件22,该批次数据处理元件22与该串流数据处理元件21连接,并接收来自该串流数据处理元件21的串流数据90,将这些串流数据90累积成批次数据92,以对该批次数据92进行必要的运算。
25.一大数据记忆元件23,该大数据记忆元件23与该批次数据处理元件22连接,用于储存系统中所有的数据。
26.其中该数据处理器20针对某一同类型的数据应用该串流数据处理元件21收集之后再输入该批次数据处理元件22,并依据时间或内容或属性形成不同的批次数据,必要时可以将所形成的批次数据储存在该大数据记忆元件23中。
27.一统计处理器30,该统计处理器30与该数据处理器20连接,对于由该数据处理器20的批次数据处理元件22所得到的批次数据92或储存在该大数据记忆元件23中的批次数据92进行统计处理,得到统计分布的数据,如均值、标准偏差、变异数等等。该统计运算元件通过统计检定的方法,计算对于一统计项目,于相同母体下所得到不同样本的统计分布是否产生显著的改变,且将统计的结果输出到该人工智能系统;如果产生显著的改变时,则该人工智能系统改变其所储存的数据。
28.其中该统计处理器30包括一统计运算元件31及一统计数据库32,该统计运算元件31主要是进行上述统计相关的运算;该统计数据库32则用于储存不同批次的统计数据。
29.比如在对于某项新产品的喜好度分析中,通过该数据搜寻器10,应用大数据的数据搜寻得到不同年龄层次对该产品的喜好。首先由该串流数据处理元件21针对一设定的项目(该项新产品)依据不同的属性(如不同的年龄层次),随着时间做间断性或连续性的声量搜寻,然后再将这些串流数据输入该批次数据处理元件22。由该批次数据处理元件22将某一段时间的数据累积形成批次数据。由该批次数据可以得到不同属性(如不同的年龄层次)对于该搜寻项目的发声数量(sov,sound of voice, 即网络上相关的发表)所形成的分布。可以将这些分布计算其统计量,并将这些统计量输出。基本上对于同一母体的统计量由于趋势的改变,该统计量也会跟着改变。但是如果对于同一母体在不同时间所得到的两个统计量通过统计检定其误差在可以接受的显著水平α(significance level)内时,则认为母体中不同属性的发声数量并没有随着时间有显著的改变。如果同一母体在不同时间所得到的两个统计量通过统计检定其误差超过可以接受的显著水平α外时,则认为母体中不同属性的发声数量已随着时间有显著的改变,所以需修正对该母体特性的相关叙述。
30.本案尚可将不同时间的统计数据按照时间轴列出,因此用户可以观察不同时间中趋势的变动。
31.另外,对于同一搜寻项目中,如果同一段时间所得到的数据量的增加与前段时间所得到的数据量的变动达到一设定值时,也就是网络声量有明显的改变时,也输出到下一级的单元中。
32.一人工智能系统40,该人工智能系统40与该统计处理器30连接,包括:一数据库41,其与该统计处理器30连接,其中该数据库41接收来自该统计处理器30的统计数据。该数据库41储存众多的判断性陈述。根据这些判断性陈述,该人工智能系统40判断一专业问题并给予答案。当该统计处理器30对同一母体中不同时间所得到样本的统计分布作检定,而认为有显著的改变时,则相关的判断性陈述也跟着改变。
33.一逻辑库42,其中储存专家的思考逻辑,这些逻辑结合用户输入的所欲得到答案的问题,这个问题并结合所储存的逻辑而形成一段叙述。
34.一推理引擎43,该推理引擎43与该逻辑库42及该数据库41连接,接收来自该逻辑库42的一段叙述,并将该段叙述与该数据库41中的数据进行比对,以得到一专家的解答。
35.一用户界面44,该用户界面44与该推理引擎43及该逻辑库42连接,用户可通过信息装置60连接到该用户界面44,并通过该用户界面44输入所欲得到答案的问题,并由该推理引擎得到人工智能系统40所推理的答案。
36.比如该数据库41中储存的判断性陈述为「红灯停止」、「绿灯通行」。该逻辑库42中储存的逻辑为「如果
…
,则
…
」。当用户输入的问题为「遇到红灯」,则将用户输入的此问题输入到该逻辑库42中以形成「如果遇到红灯,则
…
」的叙述。此段叙述被输入该推理引擎43中,该推理引擎43由该数据库41中即得到「遇到红灯,则必须停止」的信息,因此该人工智能系统40将此一信息再传送予用户,所以得到专家的解答。
37.本案的优点是应用大数据在网络中撷取某一特定议题的分布状况,并根据此分布状况计算其统计量,并且对于不同的时间所得到的统计量进行检定,以确定同一母体之下该统计量是否产生显著的改变,应用此一方式变更储存在人工智能系统中数据库的数据,使得用户可以得到实时且接近事实的信息。
38.综上所述,本案人性化的体贴设计,相当符合实际需求。其具体改进现有缺失,相较于现有技术技术明显具有突破性的进步优点,确实具有功效的增进,且非易于达成。本案未曾公开或揭露于国内与国外的文献与市场上,已符合专利法规定。
39.上列详细说明针对本发明之一可行实施例的具体说明,惟该实施例并非用以限制本发明的专利范围,凡未脱离本发明技艺精神所为的等效实施或变更,均应包括于本案的专利范围中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1