基于增量学习算法的人脸识别跟踪器的制作方法
本发明属于一种基于haar-like特征和增量学习算法的人脸识别跟踪器。
背景技术:
随着计算机成本的降低和计算机视觉技术的发展,计算机视觉领域呈现出了越来越多的应用。其中,人脸识别与追踪是一个关键的应用,在许多领域都起着重要的作用。
人脸识别技术的研究如今已成为一个热门的研究领域,并被广泛应用。例如在公共安全领域,该技术被应用于视频监控、海关身份验证、公安布控等;在金融领域,该技术被应用于银行交易、互联网支付、银行卡办理的身份验证;在日常生活方面,该技术也有一些有趣的应用,例如智能家政机器人,具有人脸识别功能的虚拟游戏等。据相关市场调查,人脸识别技术在产业中占据一定份额,其主动、直接、便捷、可信度高等特点,必定会促进其在接下来的社会发展中持续进步,所以说人脸识别技术前景将十分可观。
人脸识别技术的研究可以追溯至19世纪galton的工作。一百多年过去了,人脸识别技术在飞速进步中。从研究面部的剪影曲线的结构特征,到检测特征脸,再到基于光照锥模型的多姿态、多光照条件人脸识别方法,人脸识别的检测率如今已有了很高的准确率。本文中,我们通过检测人脸的haar-like特征,并使用adaboost机器学习算法,级联多个分类器对机器进行训练,从而更高效、更准确的达到人脸识别目的。
人脸跟踪的传统算法的计算方法是利用奇异值分解来简化运算,但是因为跟踪物体的外形,环境光线会随着时间而变化,所以需要一个更新特征基向量的方法。传统的实现为:
若要根据新增的m张图片改变模型,我们可以通过将[(i_1-i-^‘)…(i_(n+m)-i-^')]矩阵进行奇异值分解u^'σ^'〖v^'〗^t此种方法存在的弊端是每次更新都需要重新计算所有数据的特征基向量。伴随着跟踪时间的增长,每次更新特征基向量的计算量会线性增长,故使用此方法无法实现长时间的人脸跟踪,并且对计算能力的消耗较多。
技术实现要素:
本发明结合haar-like级联分类器与增量学习算法,提供一种识别率高的人脸识别跟踪器。
为了实现上述目的,本发明实例提供的技术方案如下:
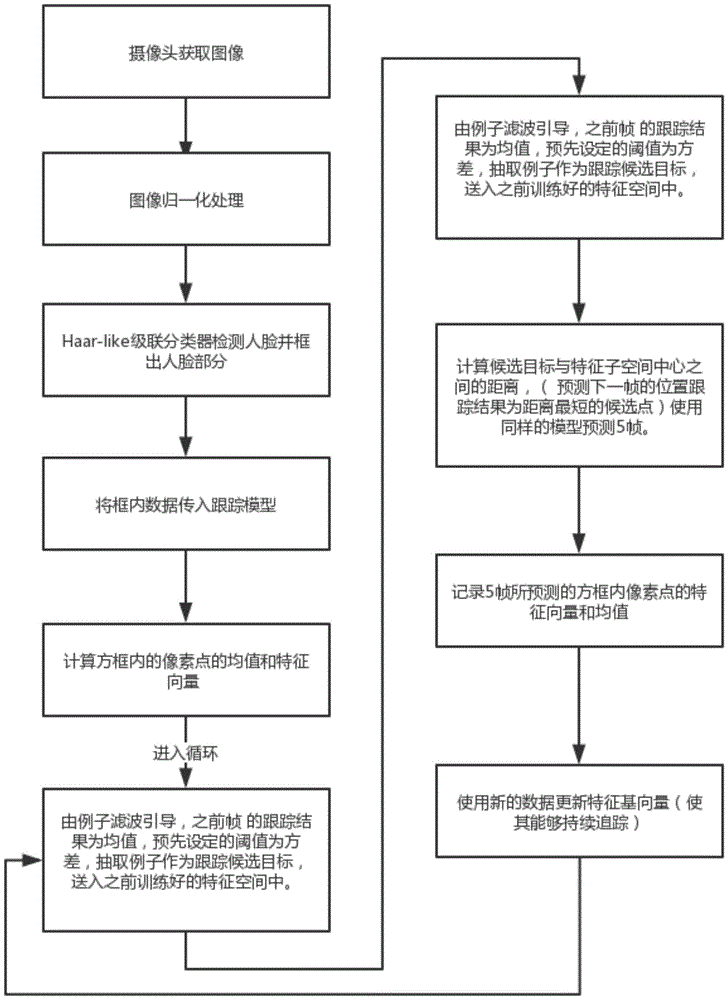
步骤1)对于摄像头所拍摄到的每一帧图像进行归一化处理;
步骤2)使用haar-like级联分类器进行归一化图像的人脸检测,并框出所检测到的人脸,记录框内数据;
步骤3)将方框数据(中点位置,大小)传入追踪器作为第一帧的追踪目标;
步骤4)追踪算法自动识别出人脸作为第一帧;
步骤5)计算方框内的像素点的特征基向量(寻找方框内像素点互相的关系);
步骤6)进入循环,计算物体在初始点为中心的周围点的概率分布;
步骤7)追踪器根据观测模型计算得出的权重,预测下一帧的位置;
步骤8)记录所预测的方框内像素点的特征基向量;
步骤9)每5帧更新一次。使用新的数据更新特征基向量(使其能够持续追踪),进行新的循环。
作为本发明的进一步改进,所述步骤(1)具体包括:通过公式
对图像进行光照修正,其中
作为本发明的进一步改进,所述步骤(2)中的haar-like级联器在训练过程中提取图像特征值的原理主要包括:
提取图像的haar-like特征。haar-like特征有很多种分类,例如边缘特征,线特征,中心环绕特征等。一张图片由多个像素点组成,不同颜色的像素点具有不同的值。在归一化处理后,图片中的像素分为黑色和白色。将图片中某一区域黑色部分所包含所有像素的值之和减去白色部分所有像素的值之和,所得到的值即为该区域图像的特征值;
为了更加高效的计算图像的特征值,我们使用积分图来加快像素值的计算。积分图的定义如下:
其中(x,y)为图像上的一点的坐标,公式所表示的含义是:在位置(x,y)上,对应的积分图中的像素为该位置的左上角所有的像素之和;(x,y),(x′,y′)均表示像素坐标;我们使用以下两个递归公式计算积分图:
s(x,y)=s(x,y-1)+i(x,y)
ii(x,y)=ii(x-1,y)+s(x,y)
其中初始值s(x,-1)=0,ii(-1,y)=0。s(x,y)表示每行像素值的总和。计算的流程为:先计算每行的像素值总和,再计算所有列的总和。至此我们就可以使用积分图来加速计算某标定区域内像素之和,高效提取图片的特征值;
作为本发明的进一步改进,所述步骤(2)中的haar-like级联器的训练过程原理主要包括:
使用多个弱分类器组合形成一个强分类器进而提高分类的准确率。其中弱分类器的定义如下:
公式中pi表示控制不等式方向的参数,fj(x)表示输入的像素窗口,该窗口是被训练图像的一部分,称为窗口。例如18*18像素的窗口,通过fj提取特征,并通过阈值θj判定该窗口是否为所要检测的目标。本专利中索要检测的目标为人脸;
假设训练样本图像为(x1,y1),…,(xn,yn),其中yi=0或1,1表示正样本,0表示负样本。假设有l个正样本,m个负样本,首先初始化权重
其中
将多个强分类器级联在一起,第一个强分类器的输入为所有子窗口,该强分类器进行分类,去除掉部分子窗口,将剩余子窗口传递给下一个分类器。当任何一个强分类器拒绝某一个子窗口时,后续分类器便可无需再次处理该窗口。这样能有效降低每个分类器需要处理的子窗口数量,从而提高识别精度。
跟踪算法基于的数据是上一帧图像的均值和特征向量,并且根据预测出的新数据的均值和特征向量,对模型进行更新。
首先,算法需要将特征基向量u初始化为空白向量,然后计算第一帧窗口内人脸的均值为μ,此时模型所包含的数据数量n=1.
运用动态模型来预测下一帧中人脸的位置。到t时刻,如已有被观测的图像{i1,…,it},则需要预测隐状态变量xt的值。
用贝叶斯定理可以得到
p(xt|it-1)∝p(it|xt)∫p(xt|xt-1)p(xt-1|it-1)dxt-1
整个追踪的过程由观测模型p(it|xt-1)主导,我们用一种粒子滤波算法的变体来模拟物体位置的分布。
在t时刻仿射变换的六个参数:xt=(xt,yt,θt,st,αt,φt)分别代表了x,y方向的位移,旋转角度,比例,纵横比以及偏斜分布。
xt中的每个参数都独立地以它前一时刻,即xt-1时刻相应的高斯分布模拟。因此,物体在不同帧之间的运动可以看作仿射变换。我们可以得到:p(xt|xt-1)=n(xt;xt-1,ψ)。ψ是包含了每个仿射变换参数的方差的对角协方差矩阵(假设每个放射参数的方差不随时间变化)。为了更有效的进行追踪,我们将平衡粒子滤波器的复杂度,比如ψ所含元素的大小以及粒子数量的选取。
接下来,我们根据pca算法的概率特性模拟观测图像:
假设图像it由xt预测得到,是由目标图像以μ为中心扩展到空间u的子空间,一个样本从这个子空间产生的概率与它到子空间参考点的位置的距离成反比,并且这个距离可以被分解为样本到子空间的距离dt和投射的样本到子空间中心的距离dw。
则样本能从子空间产生的概率:
由此我们可以得到样本由子空间产生的概率为:
为了减少噪声,我们使用了一个鲁棒的误差范数:
由1.可得p(x|z)~n(wz+μ,σ2id)
并且,可以计算出由模型正确预测观察样本x的概率p(x):
p(x)=∫p(x|z)p(z)dz~n(μ,wlwt+σ2id),
根据sherman-morrison-woodbury公式,得到:
在概率pca模型中,w和d对应特征向量和样本协方差矩阵特征值的对角矩阵。将5的表达式可知,当观测噪声σ2增加时,dt的分布减少,并且我们同时使用dt和dw来计算p(x)。
运用所预测窗口中图像的数据来更新模型,具体方法如下。
如已有数据模型为一个d×n的矩阵a={i1,…,in},其中每列in代表一帧的数据。我们已经对a进行了奇异值分解,算式为a=u∑vt.算法已预测的新数据b为一个d×m的矩阵。此时我们要用一种高效的增量算法将b中的数据添加到a和b的联合特征基向量中,也就是他们的奇异值分解[ab]=u′σ′v′t中的u′.我们可以通过以下公式:
其中,
我们使一个大小为k+m的方阵
最后,特征基向量u得以更新:
在更新的过程中设置遗忘因子,更新新的向量并且将之前的信息的权重降低,已达到有效的学习新的信息,改变模型,适应物体光线,角度的变化。具体实现如下:
设置参数f∈[0,1],更新特征基向量后将之前的特征值与f相乘,计算
经过以上步骤,算法可以持续运行,而且有较强的鲁棒性,不易受物体外形,角度,光线的变化而影响跟踪的效果。
本发明巧妙地利用了图像的haar-like特征以及adaboost算法,利用多个分类器级联所带来的识别速度与识别准确率上的优势,通过使用合适的训练集训练,获得高精确度的人脸识别效果。同时,通过利用增量学习算法,可以在消耗较少计算资源的情况下,获得高准确度,高鲁棒性的人脸跟踪表现。
附图说明
图1是人脸识别跟踪器工作原理流程图
具体实施方式
以下将结合附图所示的各实施方式对本发明进行详细描述。但这些实施方式并不限制本发明,本领域的普通技术人员根据这些实施方式所做出的结构、方法、或功能上的变换均包含在本发明的保护范围内。
本发明公开了一种一种基于haar-like特征和增量学习算法的人脸识别跟踪器。具体实施步骤包括:
步骤1)对于摄像头所拍摄到的每一帧图像进行归一化处理;
步骤2)使用haar-like级联分类器进行归一化图像的人脸检测,并框出所检测到的人脸,记录框内数据;
步骤3)将方框数据(中点位置,大小)传入追踪器作为第一帧的追踪目标;
步骤4)追踪算法自动识别出人脸作为第一帧;
步骤5)计算方框内的像素点的特征基向量(寻找方框内像素点互相的关系);
步骤6)进入循环,计算物体在初始点为中心的周围点的概率分布;
步骤7)追踪器根据观测模型计算得出的权重,预测下一帧的位置;
步骤8)记录所预测的方框内像素点的特征基向量;
步骤9)每5帧更新一次。使用新的数据更新特征基向量(使其能够持续追踪),进行新的循环。
所述步骤(1)具体包括:通过公式
对图像进行光照修正,其中
所述步骤(2)中的haar-like级联器在训练过程中提取图像特征值的原理主要包括:
提取图像的haar-like特征。haar-like特征有很多种分类,例如边缘特征,线特征,中心环绕特征等。一张图片由多个像素点组成,不同颜色的像素点具有不同的值。在归一化处理后,图片中的像素分为黑色和白色。将图片中某一区域黑色部分所包含所有像素的值之和减去白色部分所有像素的值之和,所得到的值即为该区域图像的特征值;
为了更加高效的计算图像的特征值,我们使用积分图来加快像素值的计算。积分图的定义如下:
其中(x,y)为图像上的一点的坐标,公式所表示的含义是:在位置(x,y)上,对应的积分图中的像素为该位置的左上角所有的像素之和;我们使用以下两个递归公式计算积分图:
s(x,y)=s(x,y-1)+i(x,y)
ii(x,y)=ii(x-1,y)+s(x,y)
其中初始值s(x,-1)=0,ii(-1,y)=0。s(x,y)表示每行像素值的总和。计算的流程为:先计算每行的像素值总和,再计算所有列的总和。至此我们就可以使用积分图来加速计算某标定区域内像素之和,高效提取图片的特征值;
所述步骤2中的haar-like级联器的训练过程原理主要包括:
使用多个弱分类器组合形成一个强分类器进而提高分类的准确率。其中弱分类器的定义如下:
公式中pi表示控制不等式方向的参数,fj(x)表示输入的像素窗口,该窗口是被训练图像的一部分,称为窗口。例如18*18像素的窗口,通过fj提取特征,并通过阈值θj判定该窗口是否为所要检测的目标。本专利中索要检测的目标为人脸;
假设训练样本图像为(x1,y1),…,(xn,yn),其中yi=0或1,1表示正样本,0表示负样本。假设有l个正样本,m个负样本,首先初始化权重
其中
将多个强分类器级联在一起,第一个强分类器的输入为所有子窗口,该强分类器进行分类,去除掉部分子窗口,将剩余子窗口传递给下一个分类器。当任何一个强分类器拒绝某一个子窗口时,后续分类器便可无需再次处理该窗口。这样能有效降低每个分类器需要处理的子窗口数量,从而提高识别精度。
所述步骤(6)具体包括:
跟踪算法基于的数据是上一帧图像的均值和特征向量,并且根据预测出的新数据的均值和特征向量,对模型进行更新。
首先,算法需要将特征基向量u初始化为空白向量,然后计算第一帧窗口内人脸的均值为μ,此时模型所包含的数据数量n=1.
运用动态模型来预测下一帧中人脸的位置。到t时刻,如已有被观测的图像{i1,…,it},则需要预测隐状态变量xt的值。
用贝叶斯定理可以得到
p(xt|it-1)∝p(it|xt)∫p(xt|xt-1)p(xt-1|it-1)dxt-1
整个追踪的过程由观测模型p(it|xt-1)主导,我们用一种粒子滤波算法的变体来模拟物体位置的分布。
在t时刻仿射变换的六个参数:xt=(xt,yt,θt,st,αt,φt)分别代表了x,y方向的位移,旋转角度,比例,纵横比以及偏斜分布。
xt中的每个参数都独立地以xt-1时刻相应的高斯分布模拟。因此,物体在不同帧之间的运动可以看作仿射变换。我们可以得到:p(xt|xt-1)=n(xt;xt-1,ψ)。ψ是包含了每个仿射变换参数的方差的对角协方差矩阵(假设每个放射参数的方差不随时间变化)。为了更有效的进行追踪,我们将平衡粒子滤波器的复杂度,比如ψ所含元素的大小以及粒子数量的选取。
接下来,我们根据pca算法的概率特性模拟观测图像:
假设it由xt预测得到,是由目标图像以μ为中心扩展到u的子空间,一个样本从这个子空间产生的概率与它到子空间参考点的位置的距离成反比,并且这个距离可以被分解为样本到子空间的距离dt和投射的样本到子空间中心的距离dw。
则样本能从子空间产生的概率:
由此我们可以得到样本由子空间产生的概率为:
为了减少噪声,我们使用了一个鲁棒的误差范数:
由1.可得p(x|z)~n(wz+μ,σ2id)
并且,可以计算出由模型正确预测观察样本x的概率p(x):
p(x)=∫p(x|z)p(z)dz~n(μ,wlet+σ2id),
根据sherman-morrison-woodbury公式,得到:
在概率pca模型中,w和d对应特征向量和样本协方差矩阵特征值的对角矩阵。将5的表达式可知,当观测噪声σ2增加时,dt的分布减少,并且我们使用dt和dw来计算p(x)。
所述步骤(9)具体包括:
运用所预测窗口中图像的数据来更新模型,具体方法如下。
如已有数据模型为一个d×n的矩阵a={i1,…,in},其中每列in代表一帧的数据。我们已经对a进行了奇异值分解,算式为a=u∑vt.算法已预测的新数据b为一个d×m的矩阵。此时我们要用一种高效的增量算法将b中的数据添加到a和b的联合特征基向量中,也就是他们的奇异值分解[ab]=u′σ′v′t中的u′.我们可以通过以下公式:
其中,
我们使一个大小为k+m的方阵
最后,特征基向量u得以更新:
同时,通过设置遗忘因子,更新新的向量并且将之前的信息的权重降低,已达到有效的学习新的信息,改变模型,适应物体光线,角度的变化。具体实现如下:
设置参数f∈[0,1],更新特征基向量后将之前的特征值与f相乘,计算
经过以上步骤,算法可以持续运行,而且有较强的鲁棒性,不易受物体外形,角度,光线的变化而影响跟踪的效果
应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施方式中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!