一种多处理器神经网络处理设备的制作方法
本发明涉及一种用于多处理器神经网络处理设备的自测试系统。
背景技术:
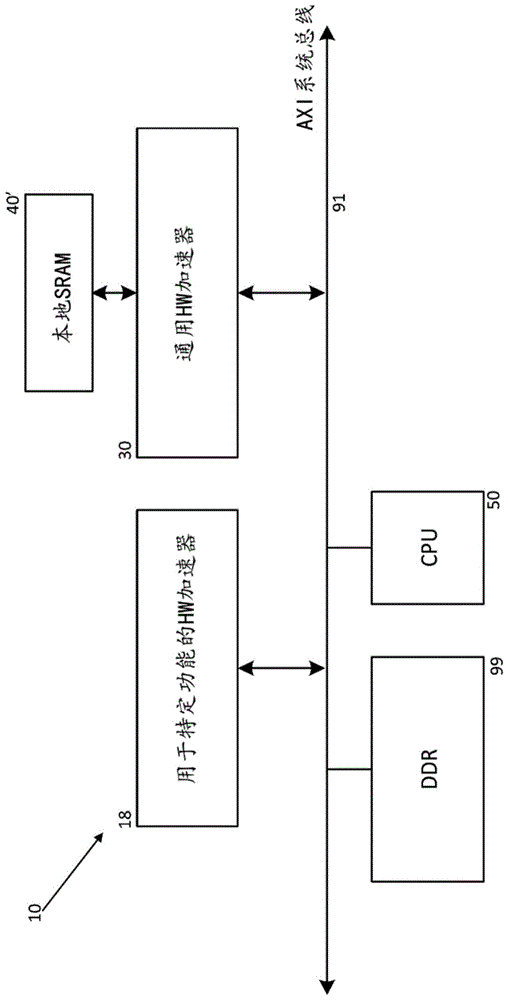
图1示意性地示出了用于在车辆中使用的驱动器监测系统(dms)的典型系统架构。
此类系统10可包含主机cpu50,可能是双/四核处理器和系统存储器99,例如单通道或多通道lpddr4存储器模块,诸如格拉茨技术大学(technischeuniversitatgraz),信息技术研究所,burimaliu于2012年5月的工学硕士论文“designandimplementationofaself-testconceptforanindustrialmulti-coremicrocontroller”中公开的。
此类系统可还包括用于加速处理的协同处理模块18、30,并且这些可包括:通用硬件加速器30,诸如可编程神经网络引擎或各种数字信号处理(dsp)核心,例如,如在pct申请pct/ep2018/071046(ref:fn-618-pct)和shibahara等人于2017年1月在《ieeejournalofsolid-statecircuits》第52卷第1期上的文章“a16nmfinfetheterogeneousnona-coresocsupportingiso26262asilbstandard”中分别公开的;或专用于特定功能加速的硬件引擎18,例如,诸如pct专利申请wo2017/108222(ref:fn-470-pct)中所公开的面部检测,或诸如美国专利no.9,280,810(ref:fn-384-cip)中公开的图像失真校正,其公开内容通过引用并入本文。
核心处理器50以及通用处理器30和专用处理器18直接从存储器99或者经由系统总线91从车辆周围布置的各种传感器接收信息,以便例如通过驾驶员显示器(未示出)控制或提供有关车辆的信息。
在结合到车辆中之前,汽车系统通常必须遵守安全标准,诸如iso26262中定义的汽车安全完整性等级(asil)a、b、c或d。asil–a是汽车行业中使用的最低安全级别,而asil–d是最高安全级别。
用于确保处理加速器提供asil-d安全性的第一种很少使用的机制是冗余的。这里,多个处理加速器将各自执行相同的功能,最后将比较每个处理加速器的结果,并且将任何差异发送给主机。
这当然提供了高的安全覆盖范围,但相对于非冗余实现,它需要倍数的硅区域和功耗。
另一种广泛使用的机制是软件内建自测试(bist)。在这种情况下,主机cpu可在处理加速器通电时或在固定的时间段调度任务。该任务包括对处理加速器硬件的一些软件测试,以确保处理加速器中没有故障。测试软件应当以提供尽可能多的验证覆盖范围的方式开发。软件bist可相对地易于实施,并且可随时进行调整或重写。但是,它通常提供相对低的覆盖范围(通常仅在asil–a中使用),并且可影响正常功能的性能。
另一方面,硬件bist涉及使处理加速器能够自我测试并且确定结果好坏的电路。这可提供高的覆盖范围,但当然涉及附加硅区域,理论上极限接近如上所述的冗余。
技术实现要素:
根据本发明,提供了根据权利要求1所述的多处理器神经网络处理设备。
本发明的实施方案基于多处理器神经网络处理设备内的一个神经网络处理引擎,该神经网络处理引擎以其他方式自由地获取另一处理引擎的配置(程序)并且在有限的时间段内运行相同的配置。将来自每个引擎的结果进行比较,并且如果它们不相等,则可容易地识别一个或其他引擎中的故障。
在冗余模式下运行之后,引擎可返回到其自己的指定任务。
附图说明
现在将参考附图以举例的方式来描述本发明的实施方案,在附图中:
图1示出了驾驶员监测系统(dms)的典型架构;
图2示出了根据本发明的实施方案可操作的多处理器神经网络处理设备;
图3示出了在独立模式下操作的可编程卷积神经网络(pcnn)引擎;并且
图4示出了在冗余模式下操作的pcnn引擎。
具体实施方式
现在参考图2,示出了在以上引用的pct申请pct/ep2018/071046(ref:fn-618-pct)中所公开类型的神经网络处理设备。
该设备包括主机cpu50,该主机cpu50包括一组处理器,这些处理器可各自通过公共内部高级高性能总线(ahb)独立地控制多个可编程卷积神经网络(pcnn)集群92,其中中断请求(irq)接口用于从pcnn集群92发信号回至主机cpu50,通常用于指示处理完成,使得主机cpu50可协调pcnn集群92的配置和操作。
每个pcnn集群92包括其自己的cpu200,该cpu200与主机cpu50通信,并且在这种情况下,与pct申请wo2017/129325(ref:fn-481-pct)中所公开类型的4个独立的可编程cnn30-a…30-d通信,该pct申请的公开内容以引用方式并入本文。需注意,在pcnn集群92内,各个cnn30不必相同,并且例如,一个或多个单个cnn可具有与其他cnn不同的特性。因此,例如,一个cnn可以允许在卷积中组合比其他cnn数量更多的信道,并且在相应地配置pcnn时将采用该信息。在该实施方案中,每个单个cnn30-a…30-d以及跨系统总线91访问系统存储器99或102可使用共享存储器40',通过该共享存储器,信息可与其他集群92共享。因此,主机cpu50与集群cpu200和存储器控制器210结合,安排将初始图像信息以及网络配置信息从存储器99或102传输到共享存储器40'。为了促进这种传输,每个主机cpu50可结合一些高速缓存存储器52。
具有一个或多个串行外围接口(spi)的外部接口块95a使主机处理器50能够连接到车辆网络(未示出)以及实际上更宽的网络环境内的其他处理器。可通过spi或通过也在块95a内提供的通用输入/输出(gpio)接口(可能是并行接口)来提供此类主机处理器50与外部处理器之间的通信。
在该实施方案中,外部接口块95a还提供与各种图像传感器的直接连接,这些图像传感器包括:常规相机(vis传感器)、nir敏感相机和用于从车辆环境获取图像的热成像相机。
在该实施方案中,专用图像信号处理器(isp)核心95b包括一对管线isp0、isp1。核心95b内的局部色调映射(ltm)部件可对所接收的图像执行基本的预处理,包括例如:对图像进行重新采样;从由图像采集装置获取的连续图像的组合生成hdr(高动态范围)图像;为获取的图像生成直方图信息–有关产生梯度直方图的信息请参见pct申请no.pct/ep2017/062188(ref:fn-398-pct2);以及/或者产生可能在图像处理期间由pcnn集群92使用的任何其他图像特征映射,例如,整体图像映射-有关此类映射的详细信息,请参见pct申请wo2017/032468(ref:fn-469-pct)。然后,可以将处理后的图像/特征映射写入共享存储器40',在共享存储器40'中,它们可以立即或最终可用于pcnn集群92的后续处理,以及或者另选地,将接收到的预处理后的图像信息提供给另一失真校正核心95c用于进一步处理,或将预处理后的图像信息写入存储器99或102,以供外部处理器访问。
失真校正核心95c包括诸如在美国专利no.9,280,810(ref:fn-384-cip)中描述的功能,用于平整失真的图像,例如通过宽视场(wfov)相机(诸如舱内相机)获取的图像。如美国专利no.9,280,810(ref:fn-384-cip)中所述,核心95c可通过逐块读取临时存储在核心95b内的图像信息进行操作,或者另选地,可在扫描由核心95b提供的光栅图像信息时执行失真校正同样,核心95c包括ltm部件,使得如果需要,可还对失真校正后的图像执行有关核心95b所描述的处理。
还应注意,与pcnn集群92相同,核心95b和95c中的每个可以经由相应的仲裁器220和控制器93-a、97访问非易失性存储器102和存储器99,并且通过相应的sram控制器210访问易失性存储器40'。
本发明的实施方案可在诸如图2所示的系统上实现。在这种情况下,每个pcnn集群92或cnn30可在独立模式(图3)和冗余模式(图4)下操作之间进行切换。
实施方案是基于每次要处理一个或多个输入图像/映射时,集群92或cnn30被提供有输入图像或(多个)映射,以及需要由cnn执行的网络配置两者,即,网络的每层的定义以及网络的各层内要采用的权重。
通常,如图3所示,可能需要第一pcnn_092’/30’通过程序_0定义的网络并且使用权重_0处理一个或多个输入映射_0以产生一个或多个输出映射_0。需注意,输出映射_0可包括来自由程序_0定义的网络的中间层的输出映射,或者它们可包括由由程序_0定义的网络的输出节点生成的一个或多个最终分类。类似地,可能需要第二pcnn_192”/30”通过由程序_1定义的网络并且使用权重_1来处理一个或多个输入映射_1以产生一个或多个输出映射_1。(需注意,输入映射_0和输入映射_1可为相同或不同的图像/映射或者重叠的图像/映射集。)
应当理解,可能希望或有必要在不同的时间和不同的频率执行不同的网络。因此,例如,在带有一个或多个前向相机的车辆中,专用于识别相机视场内的行人的pcnn集群92或cnn30可以每秒30帧以上的速度执行,而在带有面向驾驶员相机的车辆中,用于识别驾驶员面部表情的pcnn集群92或cnn30可以每秒30帧以下的速度执行。类似地,一些网络可能比其他网络更深或更广泛,因此即使以相同的频率执行,也可能涉及不同的处理时间。
因此,应当显而易见的是,将存在在诸如图2所示的多处理器神经网络处理设备中的多个pcnn集群92或单个cnn30中的一者或多者将处于空闲状态的时间段。
本发明的实施方案是基于此类pcnn集群92或cnn30中的至少一些:独立地处于主机cpu50的控制下或经由它们各自的群集cpu200能够识别存储器99中或跨系统总线91(以及可能的ahb总线)传递的用于其他目标pcnn的程序命令和数据。
在这些情况下,如图4所示,pcnn集群92”或单个cnn30”可切换成在冗余模式下操作,其中它们使用另一目标pcnn集群92'或cnn30'的输入映射、配置信息/程序定义和权重来复制该目标pcnn集群/cnn的处理。
当在冗余模式下操作时,每个此类pcnn群集92”或cnn30”可继续执行目标pcnn的程序,直到处理完成或pcnn集群/cnn从主机cpu50接收到请求它以独立模式执行自己的网络程序的命令。
然后,可由以下任一者来比较处理的结果(在完成或中断前已经发生的情况下):冗余pcnn集群92”中的集群cpu200;冗余cnn30”;目标pcnn集群92’或cnn30’中的集群cpu200,如果目标pcnn集群92’或cnn30’知道其操作正被冗余pcnn集群/cnn遮蔽;或主机cpu50,如决策框400所指示的。
使用多个单个cnn共有的cpu200对pcnn集群92或单个cnn30进行冗余检查消除了主机cpu50识别进行测试的机会的负担,但是相比在每个单个cnn30内提供此类功能,还减少了要实现的逻辑的量。类似地,由于每个cpu200在任何情况下都为每个单个cnn30提供对系统总线91的访问权限,因此它可容易地代表它们采取行动,以识别对其他pcnn群集92或单个cnn30进行测试的机会。
冗余检查功能400可以多种方式实现。应当理解的是,在处理神经网络的过程中,一系列层中的每一层将产生一个或多个输出映射。通常,卷积层和汇集层产生二维输出特征映射,而完全连接的或类似的分类层产生一维特征向量。通常,随着网络处理的进行,输出映射的大小会减小,直到例如最终网络输出层可能产生相对少量的最终分类值。然而,应当理解,其他网络(例如,生成网络或执行语义分段的那些网络)实际上可以产生大的输出映射。因此,具体地讲,如果目标pcnn集群92'或cnn30'在处理期间将任何此类输出映射写回到存储器99,则可将其与由冗余pcnn群集92”'或cnn30”产生的对应映射进行比较以确定是否存在差异。对于非常大的输出映射,可以为输出映射生成哈希、crc(循环冗余校验)或签名,然后可以将这些进行比较,而不是逐像素比较。
在任何情况下,如果输出映射或从此类输出映射得出的值匹配,则可假定目标pcnn群集92'或cnn30'和冗余pcnn群集92”'或cnn30”两者都在起作用。如果不是,则可将目标或冗余pcnn集群或cnn中的至少一者标记为潜在故障。随后可将此类潜在故障的pcnn集群或cnn设置为仅在冗余模式下运行,直到有机会针对另一目标pcnn群集或cnn进行检查。如果潜在故障的pcnn群集或cnn中的一者对另一目标pcnn群集或cnn进行检查,而另一者没有,则可将该另一pcnn群集或cnn指定为故障并且永久禁用。(在未被指定为潜在故障之前,其余潜在故障的pcnn群集或cnn可能需要在冗余模式下成功运行给定次数。)
从以上描述中将会理解,多个cnn30,无论是在单个pcnn集群92内还是散布在多个pcnn集群92中,尤其适合于进行这种饲机测试,因为此类cnn不必完成用于进行故障分析的整个网络的处理。实际上,可是这样的情况,即通常来自网络的较早层的处理的较大输出映射相比来自网络的单个最终分类可提供pcnn集群或单个cnn内的功能的更广泛的测试结果。另一方面,跨系统总线91将太多此类中间层信息写回到存储器99而不是仅将这些信息保持在本地高速缓存中可能过度消耗系统资源。这样,可在仅消耗最少的系统资源和提供足够的中间层输出信息之间平衡网络程序配置,从而可在冗余pcnn群集92”或cnn30”无需必须在其否则空闲时间期间完成网络的处理的情况下执行冗余检查。
类似地,可以看出,在诸如图2所示的多处理器神经网络处理设备中,多个重复集群92和核心30的可用性使得这些集群和核心中的一些在被确定为故障或潜在故障时被关闭或不依赖,并且设备继续处理,尽管饲机测试的机会较少。这样,系统可以被编程为警告用户已经检测到故障,并且例如,限制系统功能(速度、范围或例如自主驾驶级别),直到故障被修复为止。
应当理解,在某些系统中,由每个cnn30执行的任务可被确定性地调度,并且因此,主机cpu50或群集cpu可以先验知道它们何时操作在冗余模式下,并且因此知道何时以及在何处期望目标pcnn群集或cnn的配置信息出现在系统存储器99中。其他系统可以与分配pcnn群集92和/或cnn的主机cpu50更异步地操作以按需执行任务。在任一种情况下,应当理解的是,pcnn集群92或cnn30可被配置为识别在冗余模式下操作的机会,使得另一pcnn集群92或cnn30的功能可被测试。
还应当理解,在一些实施方案中,pcnn集群92或cnn30中的全部可以被配置为饲机地测试任何其他的pcnn集群92或cnn30,而在其他实施方案中,可能存在有限数量的或甚至指定的pcnn群集92或cnn30被配置成具有切换到冗余模式的能力。当然,这样做的优点是,在任何给定的pcnn群集92或cnn30被识别为故障的情况下提供一些备用的计算能力,并且仍然允许系统以最大能力执行。
还应该注意的是,可能存在特定时间,例如,当车辆静止时,测试pcnn集群92或cnn30的功能可是有益的,以及在被处理的图像信息可能对测试的用处不大的非常暗或对比度很低的条件下可能对处理设备的需求较少或可能不需求。在任何情况下,不必连续地或以固定间隔运行测试。
- 还没有人留言评论。精彩留言会获得点赞!