一种铁路货车制动梁梁体折断故障图像识别方法与流程
本发明涉及货运列车检测技术领域,具体为一种铁路货车制动梁梁体折断故障图像识别方法。
背景技术:
制动梁是铁路车辆基础制动装置的最重要部分,车辆制动时,制动力通过制动梁传到闸瓦,使车辆停止前进。制动梁梁体折断故障将直接影响行车安全,一旦发现故障,需及时拦停检修处理。传统的制动梁工位,采用人工检查图像的方式进行故障检测。由于检车人员在工作过程中极易出现疲劳、遗漏等情况,造成漏检、错检的出现,影响行车安全。而采用图像处理和深度学习的方法进行制动梁折断故障自动识别,人工只需对报警结果进行确认,可有效节约人力成本,并提高检测准确率。
技术实现要素:
本发明的目的是:针对现有技术中采用人工检查图像的方式进行故障检测。由于检车人员在工作过程中极易出现疲劳、遗漏,造成检测效率低的问题,提出一种铁路货车制动梁梁体折断故障图像识别方法。
本发明为了解决上述技术问题采取的技术方案是:一种铁路货车制动梁梁体折断故障图像识别方法,包括以下步骤:
步骤一:获取途径货车的高清线阵图像,并建立样本数据集;
步骤二:对样本数据集进行数据扩增;
步骤三:对数据集中的图像进行标记;
步骤四:将原始图像和标记数据生成数据集,用于模型训练;
步骤五:从图像中裁剪出待识别部件区域;
步骤六:对制动梁梁体部分进行定位,确定识别范围,并利用u-net网络对图像进行分割;
步骤七:综合先验知识对u-net网络分割结果进行过滤与图像处理后,对图像进行裁剪和拼接;
步骤八:将裁剪和拼接后的图像输入ssd-fpn网络模型中进行训练,并得到输出结果,根据该输出结果判断是否有折断故障。
进一步的,所述数据扩增包括:图像的旋转、平移、缩放、水平翻转、垂直翻转、对比度、光照调节和增加噪声。
进一步的,所述对数据集中的图像进行标记的标记结果为原始图像对应的类别的掩码图像以及故障图像对应的折断故障区域的标记。
进一步的,所述u-net网络包括:编码单元、解码单元和编码解码单元,所述编码单元采用3个下采样的编码单元,所述解码单元包含3个上采样的解码单元;
第一编码单元包含64个3×3大小的卷积核进行卷积并池化,并与第三解码单元融合;
第二编码单元包含64个3×3大小的卷积核进行卷积并池化,并与第二解码单元融合;
第三编码单元包含128个3×3大小的卷积核进行卷积并池化,并与第一解码单元融合;
编码解码单元包含256个3×3大小的卷积核进行卷积;
第一解码单元包含编码解码单元2*2上采样后和第三编码单元融合,然后进行128个3×3大小的卷积核进行卷积;
第二解码单元包含第一解码单元2*2上采样后和第二编码单元融合,然后进行64个3×3大小的卷积核进行卷积;
第三解码单元包含第二解码单元2*2上采样后和第一编码单元融合,然后进行32个3×3大小的卷积核进行卷积;
最后1×1大小的卷积核进行卷积,输出分割结果。
进一步的,所述ssd_fpn网络模型的训练过程为:
s1:提取resnet_fpn特征,拼接高层的语义特征以及底层的空间特征,生成特征map;
s2:多层特征图生成anchor;
s3:将多层特征图预测anchor,同groundtruthbox相匹配,根据匹配结果确定loss;
s4:loss反向传播,更新权重,继续下一轮训练。
进一步的,所述s3中匹配的策略为:对所有的groundtruthbox选择与它iou最大的anchor进行匹配;对所有的anchor,选择任何与其iou大于0.5的groundtruthbox进行匹配。
进一步的,所述loss包括分类损失和回归位置损失,
所述分类损失的确定公式如下:
所述回归位置损失的确定公式如下:
x=labels-predictions
总损失为:
total_loss=localization_loss+w×classification_loss。
进一步的,所述步骤八的具体步骤为:首先根据类别置信度确定其类别,并过滤掉属于背景的预测框,然后根据置信度阈值,过滤掉阈值较低的预测框,对于留下的预测框进行解码,根据先验框得到其真实的位置参数,解码之后,根据置信度进行降序排列,然后仅保留top-k个预测框,最后进行非极大性抑制算法,过滤掉那些重叠度较大的预测框,得到网络输出的预测结果,综合预测框位置和制动梁梁体定位的二值图像,以及预测框的置信度,判断是否有折断故障,并上传识别结果。
本发明的有益效果是:
1、利用图像自动识别的方式代替人工检测,提高检测效率、准确率。
2、将深度学习算法应用到制动梁梁体折断故障自动识别中,提高整体算法的稳定性及精度。
3、对u-net模型进行优化,缩短预测时间,提高分割速度。
4、将ssd的特征提取器由vgg16更改为resnet50与fpn的组合,通过多尺度的目标检测,将整体特征与局部特征相融合,提高单阶段目标检测算法ssd在小尺度目标检测方面精度。
5、传统的fpn每层特征金字塔只有一个尺度的特征表达,各层特征相互独立,没有关联。通过拼接高层的语义特征以及底层的空间特征,使每个预测层含有丰富的多尺度特征,更利于小目标的检测。
附图说明
图1为本发明故障识别流程图。
图2为本发明改进的u-net网络结构图。
图3为本发明fpn多层次特征融合示意图。
具体实施方式
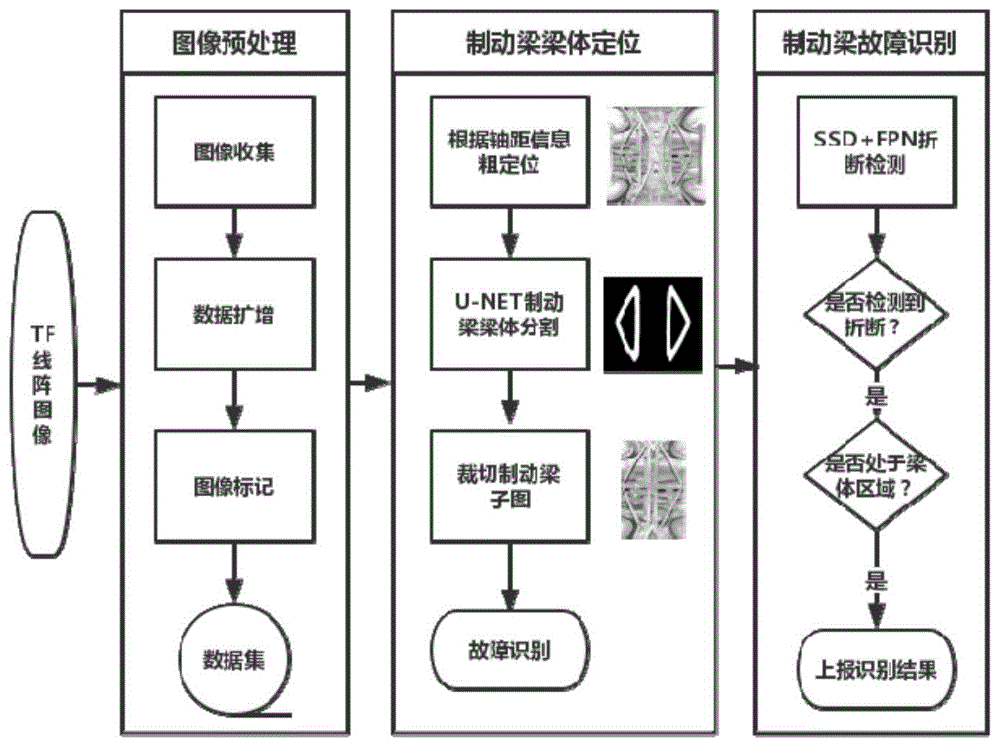
具体实施方式一:参照图1至图3具体说明本实施方式,本实施方式所述的一种铁路货车制动梁梁体折断故障图像识别方法,包括以下步骤:
步骤一:获取途径货车的高清线阵图像,并建立样本数据集;
步骤二:对样本数据集进行数据扩增;
步骤三:对数据集中的图像进行标记;
步骤四:将原始图像和标记数据生成数据集,用于模型训练;
步骤五:从图像中裁剪出待识别部件区域;
步骤六:对制动梁梁体部分进行定位,确定识别范围,并利用u-net网络对图像进行分割;
步骤七:综合先验知识对u-net网络分割结果进行过滤与图像处理后,对图像进行裁剪和拼接;
步骤八:将裁剪和拼接后的图像输入ssd_fpn网络模型中进行训练,并得到输出结果,根据该输出结果判断是否有折断故障。
1、图像预处理
(1)图像收集
通过在货车轨道周围搭建高清设备,获取途径货车的高清线阵图像。由于货车部件可能受到雨水、泥渍、油渍、黑漆等自然条件或者人为条件的影响。不同转向架类型的制动梁有所差异,不同站点拍摄的图像也可能存在差异。因此,制动梁图像之间千差万别。所以,在收集制动梁图像数据的过程中,要保证多样性,尽量将各种条件下的制动梁图像全部收集。
(2)数据扩增
样本数据集的建立虽然包括各种条件下的图像,但为获得更多的训练样本,增加模型的鲁棒性,仍需要对样本数据集进行数据扩增。扩增形式包括图像的旋转、平移、缩放、水平翻转、垂直翻转、对比度、光照调节、增加噪声等操作,每种操作都是在随机条件下进行的,这样可以最大程度的保证样本的多样性和适用性。
(3)图像标记
根据不同模型的需求,对数据集中的图像进行标记。制动梁梁体定位所采用的分割模型的标记结果为原始图像对应的类别(背景-0/制动梁梁体区域-1)的掩码图像。折断故障识别所采用的目标检测模型,通过标记得到包含折断位置的矩形框的xml文件。
(4)数据集生成
将原始图像和标记数据生成数据集,用于模型训练。
2、制动梁梁体定位
(1)利用硬件的轴距信息和部件的位置等先验知识,从整列车的大图中裁剪出待识别部件区域。
(2)因为制动梁梁体较大,在底部图像上占比较大,因此需要先在底部图像上对制动梁梁体部分进行定位,确定识别范围。本发明采用u-net网络对图像进行分割,得到0为背景,1为制动梁梁体的二值图像。
u-net网络能够结合图像的全局与局部细节方面的特征,进行综合的考虑。前几层的卷积结果,会在同高度解码器上的进行信息融合。这样图像的图像高分辨率的细节信息就不会随着网络深度加深而丢失,能帮助最终我们的图像提供精细分割;而经过一次一次卷积池化后,在u-net的最下层,包含整幅图像的全局信息(故障的总体位置、分布等),因此在医疗图像领域应用十分广泛。
区别于高分辨率复杂的医疗图像,货车制动梁图像的分辨率要相对低些,无需提取超高分辨率特征来进行故障识别。因此在不影响分割结果的前提下,对u-net网络结构进行了优化:减少网络深度,缩减卷积核的数目,进而减少参数数量,提高模型的预测速度。
如图2所示,具体如下:
①64个3×3大小的卷积核进行卷积并池化;
②64个3×3大小的卷积核进行卷积并池化;
③128个3×3大小的卷积核进行卷积并池化;
④256个3×3大小的卷积核进行卷积;
⑤上卷积④同③融合,128个3×3大小的卷积核进行卷积;
⑥上卷积⑤同②融合,64个3×3大小的卷积核进行卷积;
⑦上卷积⑥同①融合,32个3×3大小的卷积核进行卷积;
⑧1×1大小的卷积核进行卷积,输出分割结果;
(3)综合先验知识(如制动梁梁体为两个对称三角形),对u-net分割结果进行过滤与图像处理后,分别计算两个三角形的外接矩形,以此对图像进行裁剪和拼接,用于下一步的故障检测。
3、制动梁折断检测
(1)结合fpn的网络结构
制动梁图像的特点是图像大,折断故障目标较小。而单阶段的ssd的模型,虽然速度满足实时要求,但存在小目标检测准确率不高的问题。为此,本发明提出一种基于ssd模型的多尺度故障识别的方法。该方法采用resnet50与fpn的组合的金字塔结构作为特征提取器,使对小物体比较敏感的底层特征可以直接影响到目标检测器,进而提高小目标的检测准确性;同时在不同卷积层之间,增加信息的流动性,进而提升基础网络的特征描述能力。可根据故障区域占输入图像的大小,设置合理的多尺度检测层数,在保证识别精度的基础上减少网络宽度,提高速度。如图3所示。
(2)损失函数定义
损失函数由两部分加权组成:分类损失和回归位置损失。本发明采用sigmoidfocalloss来计算分类损失,huberloss来计算回归位置损失。具体如下:
分类损失:
focalloss将重点聚焦于难训练的样本,对于简单的,易于分类的样本,降低相应的loss权重,而对于较为难训练的样本,增加对应的loss权重。简单有效的解决了单阶段目标检测前景和背景类别不均衡的问题。计算公式如下:
pt=labels*sigmoid(predictions)+(1-labels)*(1-sigmoid(predictions))
classification_loss=focal_loss(pt)=-αt(1-pt)γlog(pt)
回归位置损失:
对于分类结果中的正样本,还需计算回归位置损失。huberloss是一个用于回归问题的带参损失函数,降低了对离群点的惩罚程度,所以能增强平方误差损失函数对离群点的鲁棒性。计算公式如下:
x=labels-predictions
总损失:
总损失是①和②加权的结果。因为故障检测问题更注重于对故障检测的正确性,所以应适当提高分类损失占总损失的权重。
total_loss=localization_loss+w×classification_loss
(3)训练过程
a:提取resnet_fpn特征,生成特征map
b:多层特征图生成anchor(defaultbox)
c:将多层特征图预测anchor,同groundtruthbox相匹配,根据匹配结果,按上述公式计算loss。匹配策略如下:
对所有的groundtruthbox选择与它iou最大的anchor(defaultbox)进行匹配;对所有的anchor,选择任何与其iou大于0.5的groundtruthbox进行匹配。
d:loss反向传播,更新权重,继续下一轮训练。
4、制动梁梁体折断故障判别
对于输入的制动梁底部图像,计算特征图,对于每个可能预测框,首先根据类别置信度确定其类别(置信度最大者),并过滤掉属于背景的预测框。然后根据置信度阈值,过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数。解码之后,根据置信度进行降序排列,然后仅保留top-k(如100)个预测框。最后进行非极大性抑制(nms)算法,过滤掉那些重叠度较大的预测框,得到网络输出的预测结果,
综合预测框位置和制动梁梁体定位的二值图像,以及预测框的置信度,判断是否有折断故障,并上传识别结果。
需要注意的是,具体实施方式仅仅是对本发明技术方案的解释和说明,不能以此限定权利保护范围。凡根据本发明权利要求书和说明书所做的仅仅是局部改变的,仍应落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!