基于相关学习的图传播的弱监督细粒度图像分类算法的制作方法
本发明属于计算机视觉技术领域,以提高细粒度图像分类准确性和效率为出发点,提出基于相关学习的图传播的弱监督细粒度图像分类算法。
背景技术:
作为一个新兴的研究主题,弱监督细粒度图像分类(wfgic)专注于判别性细微差异,其仅使用图像级标签来区分子类别的对象。由于同一子类别中的图像之间的差异细微,拥有几乎相同的整体几何形状和外观,因此区分细粒度图像仍然是一项艰巨的任务。
在wfgic中,学习如何从细粒度图像中定位判别性部分起着关键作用。最近的工作可以分为两组。第一组是基于启发式方案来定位判别性部分。启发式方案的局限性在于,它们很难保证所选区域具有足够的判别性。第二类是通过学习机制进行的端到端本地化分类方法。但是,所有先前的工作都试图独立地定位判别性区域/patch,而忽略了区域的局部空间上下文以及区域之间的相关性。
利用局部空间上下文可以提高区域的判别能力,而且挖掘区域之间的相关性比单个区域更具判别性。这启发将区域的局部空间上下文和区域之间的相关性纳入判别性patch选择中。为此,提出了一个交叉图传播(cgp)子网络,以学习区域之间的相关性。具体而言,cgp以交叉方式迭代计算区域之间的相关性,然后通过对其他区域进行相关权重加权来增强每个区域。通过这种方式,每个区域的特征都是对全局图像级上下文进行编码,即整个图像中聚合区域和其他区域之间的所有相关性,以及局部空间上下文,即该区域越靠近聚合区域,交叉图传播期间的聚合频率越高。在cgp中通过学习各区域之间的相关性,可以指导网络隐式发现对wfgic更有效的判别性区域组。图l显示了的动机,当独立考虑每个区域时,可以看到得分图(图l(b))突出显示了头部区域,而得分图(图l(d))在交错图传播的多次迭代之后加强了最具判别性的区域,这有助于对判别性区域组(头部和尾部区域)进行精确定位。
判别性特征表示对于wfgic起到了另一个关键作用。最近,一些端到端网络通过编码卷积特征向量为高阶信息来增强特征表示的判别能力。这些方法之所以有效,是因为它们对对象平移和姿势变化具有不变性,这得益于特征的无序聚合方式。这些特征编码方法的局限性在于它们忽略了局部判别特征对wfgic的重要性。因此,某些方法结合了局部判别特征,以通过合并选定的区域特征向量来提高特征判别能力。但是,值得注意的是,所有先前的工作都忽略了判别性区域特征向量之间的内部语义相关性。此外,还有一些噪声上下文,例如图1(c)(e)中的选择判别性区域内的背景区域。这样的背景信息或是含有很少判别性的信息可能对wfgic有害,因为所有子类别都具有相似的背景信息(例如,鸟类通常栖息在树上或在天空中飞翔)。基于以上直观但重要的观察和分析,提出了一个相关特征增强(cfs)子网络,以探索区域特征向量之间的内部语义相关性,以获得更好的判别能力。的做法是通过用选择区域的特征向量来构造图,然后在cfs中联合学习特征向量节点之间的相互依赖性,来指导判别信息的传播。图l(g)和(f)是有无cfs学习的特征向量。
技术实现要素:
本发明提出了一个基于相关学习的图传播的弱监督细粒度图像分类算法,以充分挖掘和利用wfgic的相关性的判别潜力。在cub-200-2011和cars-196数据集上的实验结果表明,提出的模型是有效的,并且达到了最佳水平。
本发明的技术方案如下:
一种基于相关学习的图传播的弱监督细粒度图像分类算法,包括四个方面:
(1)交叉图传播(cgp)
cgp模块的图传播过程包括两个阶段:第一阶段是cgp学习每两个区域之间的相关权重系数(即相邻矩阵计算)。在第二阶段,该模型通过交叉加权求和运算组合其相邻区域的信息,以寻找真正的判别性区域(即图更新)。具体来说,通过计算整个图像中每两个区域之间的相关性,将全局图像级上下文集成到cgp中,并通过迭代的交叉聚合操作对局部空间上下文信息进行编码。
给定输入特征图mo∈rc×h×w,其中w,h,c分别是特征图的宽,高和通道数,将它输入到cgp模块f:ms=f(mo),(1)
其中f由节点表示,相邻矩阵计算和图更新组成。ms∈rc×h×w是输出特征图。节点表示:节点表示是通过简单的卷积运算f来生成的:
mg=f(wt·mo+bt),(2)
其中wt∈rc×1×1×c和bt分别是学习的权重参数和卷积层的偏差向量。mg∈rc×h×w表示节点特征图。具体来说,将1×1卷积核视为小区域检测器。在mg的固定空间位置上的通道的每个vt∈rc×1×1向量代表图像对应位置上的一个小区域。使用生成的小区域作为节点表示。值得注意,wt是随机初始化的,并且初始的三个节点特征图是通过三种不同的f计算获得的:
相邻矩阵计算:在特征图
让以相邻矩阵中两个位置的一个关联为例。
其中
其中rijk是第i行,第j列和第k个通道的相关权重系数。
在向前传播的过程中,区域越有判别性,它们之间的相关性就越大。在反向传播中,针对节点向量的每个blob实施导数。当分类的概率值较低时,惩罚将会被反向传播以降低两个节点的相关权重,并且将同时更新通过节点表示生成操作计算出的节点向量。
图更新:将由节点表示生成阶段生成的
其中
与resnet类似,采用残差学习:
ms=α·mu+mo(6)
其中,α是自适应权重参数,它逐渐学习为判别性相关特征分配更多权重。它的范围是[0,1],并初始化为接近0。这样,ms会汇总相关特征和原始输入特征以挑选出更多判别性patch。然后,将ms作为新输入输入到cgp的下一个迭代中。在多次图传播之后,每个节点可以以不同频率聚合所有区域,从而间接学习全局相关性,并且该区域越靠近聚合区域,则在图传播过程中聚合频率越高,这反映了局部空间上下文信息。
(2)判别性patch的采样
在这项工作中,根据目标检测中特征金字塔网络(fpn)的启发,从三个不同尺度的特征图生成默认patch。该设计可以使网络负责不同大小的判别性区域。
在获得聚合了相关特征和原始输入特征的残差特征图ms后,将其馈入判别式响应层。具体来说,引入一个1×1×n卷积层和一个sigmoid函数σ来学习判别概率图s∈rn×h×w,这表明了判别性区域对最终分类的影响。n是特征图中给定位置的默认patch数。
此后,将相应地为每个默认patchpijk分配判别概率值。公式表示如下:
pijk=[tx,ty,tw,th,sijk],(7)
其中(tx,ty,tw,th)是每个patch的默认坐标,sijk表示第i行,第j列和第k个通道的判别概率值。最终,网络根据概率值选择前m个patch,其中m为超参数。
(3)相关性特征加强(cfs)
当前大多数工作都忽略了判别性区域特征向量之间的内部语义相关性。此外,在选择的判别性区域中存在一些具有较少的判别性或是存在上下文噪声。提出了一个cfs子网络来探索区域特征向量之间的内部语义相关性,以获得更好的判别能力。cfs的详细信息如下:
节点表示和相邻矩阵计算:要构造图以挖掘所选patch之间的相关性,从m个所选patch中提取具有d维特征向量的m个节点作为图卷积网络(gcn)的输入。在检测到m个节点之后,计算相关系数的相邻矩阵,该矩阵反映了节点之间的相关强度。因此,可以如下计算相邻矩阵的每个元素:
ri,j=ci,j·<ni,nj>(8)
其中ri,j表示每两个节点(ni,nj)之间的相关系数,ci,j是加权矩阵c∈rm×m中的相关权重系数,可以学习ci,j通过反向传播来调整相关系数ri,j。然后,对相邻矩阵的每一行执行归一化,以确保连接到一个节点的所有边的总和等于1。相邻矩阵a∈rm×m的归一化通过softmax函数实现,如下所示:
最终构造的相关图计算了所选patch之间的关系强度。
图形更新:在获得相邻矩阵之后,将具有m个节点的特征表示n∈rm×d和相应的相邻矩阵a∈rm×m都作为输入,并将节点特征更新为n′∈rm×d′。正式地,gcn的这一层过程可以表示为:
n′=f(n,a)=h(anw),(10)
其中w∈rd×d′是学习的权重参数,h是非线性函数(在实验中使用整流线性单位函数(relu))。多次传播后,所选patch中的判别信息可以进行更广泛的交互以获得更好的判别能力。
(4)损失函数
提出了一个端到端模型,该模型将cgp和cfs合并到一个统一的框架中。cgp和cfs在多任务损失l的监督下一起训练,l由基本的细粒度分类损失组成。提出了一个端到端模型,该模型将cgp和cfs合并到一个统一的框架中。cgp和cfs在多任务损失
其中λ1,λ2,λ3是平衡这些损失的超参数。经过多次实验验证,设置参数λ1=λ2=λ3=1。
让用x代表原始图像,并分别用p={p1,p2,...,pn}和p′={p′1,p′2,...,p′n}代表有无cfs模块选择的判别性patch。c是置信度函数,它反映了分类为正确类别的概率,而s={s1,s2,...,sn}表示判别概率分数。然后,引导损失,等级损失和特征增强损失定义如下:
在这里,引导损失指导网络选择最具判别性的区域,等级损失则使所选择patch的判别性分数和最终分类概率值保持一致。这两个损失函数直接调整cgp的参数,并间接影响cfs。特征增强损失可以保证使用cfs的选择区域特征的预测概率大于无cfs的选择特征的预测概率,并且网络可以调整相关权重矩阵c和gcn权重参数w来影响所选patch之间的信息传播。
本发明是第一个基于图传播来探索和利用区域相关性,以隐式发现判别性区域组并提高其对wfgic的特征判别能力的方法。所采用的基于端到端图传播的关联学习(gcl)模型,将交叉图传播(cgp)子网络和相关特征增强(cfs)子网络整合到一个统一的框架中进行有效联合地学习判别性特征。在caltech-ucsdbirds-200-2011(cub-200-2011)和stanfordcars数据集上评估提出的模型。本发明的方法在分类精度(例如,cub-200-2011上的88.3%vs87.0%(chen等))和效率(例如cub-200-2011上的56fpsvs30fps(lin,roychowdhury和maji))上均达到了最佳性能。
附图说明
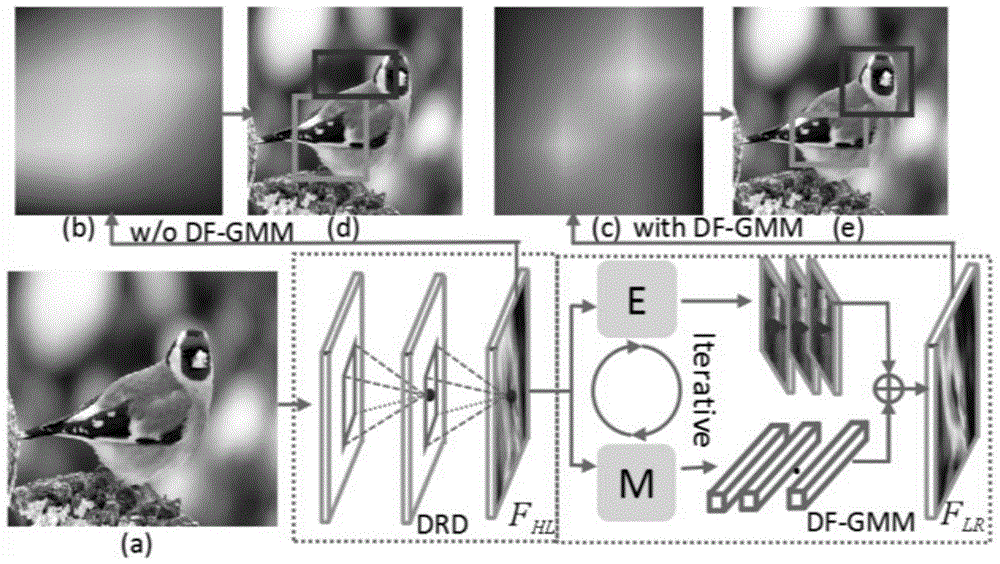
图1:判别性特征导向的高斯混合模型(df-gmm)的动机。其中drd表示区域扩散的问题;fhl表示高层语义特征图;flr表示低秩特征图;(a)是原始图像;(b)(c)是用来指导网络对判别性区域进行采样的判别响应图;(e)(d)是分别在有无使用df-gmm学习的情况下的定位结果。我们可以看到,减少drd之后,(c)比(b)更加紧凑和稀疏,并且(e)中的结果区域比(d)中的更加准确和具有判别性。
图2为本发明提出的基于相关学习的图传播(gcl)模型的框架图。通过交叉图传播(cgp)子网生成判别性相邻矩阵(am),并通过计分网络(sample)生成判别性得分图(scoremap)。然后,gcl根据判别性得分图从默认patch(dp)中选择更具判别性的patch。同时,将从原始图像得来的patch裁剪并调整为224×224的大小,并通过图传播相关特征增强(cfs)子网络生成判别特征。最后,将多个特征连接起来以获得wfgic的最终特征表示。
图3为本发明
图4为本发明的区域之间有无相关性的可视化结果。(a)表示原始图像。(c)(b)分别是有无相关性的特定对应通道特征图。
图5为本发明相关权重系数图的可视化结果。第一行表示原始图像。第二,第三和第四行分别表示通过第一,第二和第三次图传播后的相关权重系数图。
具体实施方式
以下结合技术方案和附图详细叙述本发明的具体实施方式。
数据集:实验评估是在下面三个基准数据集上进行的:caltech-ucsdbirds-200-2011,stanfordcars和fgvcaircraft,它们是用于细粒度图像分类的广泛使用的竞赛数据集。cub-200-2011数据集涵盖200种鸟类,并包含11788个鸟类图像,图像分为5994张图像的训练集和5794张图像的测试集。斯坦福汽车数据集包含196个类别的16,185张图像,这些图像分为8144张训练集和8041张测试集。飞机数据集包含100个类别的10000张图片,训练集和测试集大约为2:1。
实施细节:在的实验中,所有图像的大小均调整为448×448。使用全卷积网络resnet-50作为特征提取器,用“批量归一化”作为正则化器。优化器使用初始学习率为0.001的momentumsgd,学习率在每60个epoch后乘以0.1。将权重衰减率设为1e-4。此外,为了减少patch冗余,基于patch的判别性得分对patch采用非最大抑制(nms),并将nms阈值设置为0.25。
消融实验:如表1所示,进行了一些消融实验,以说明所提出模块的有效性,包括交叉图传播(cgp)和相关特征增强(cfs)。
在没有任何对象或局部标注的情况下,通过resnet-50从整个图像中提取特征并将其设置为基线(bl)。然后,引入默认patch(dp)作为本地特征,以提高分类准确性。当采用评分机制(score)时,它不仅可以保留高度判别性的patch,还可以将patch的数目减少到个位数,然后在cub-200-2011数据集的top-1分类准确性提高了1.7%。此外,通过cgp模块考虑了区域组的判别能力,消融实验结果表明,如果每个区域以相同的频率(cgp-sf)聚合所有其他区域,则其在cub上准确度为87.2%,而交叉传播可以实现更好的性能,即能达到87.7%。最后,介绍了cfs模块,以探索和利用选出的patch之间的内部相关性,并获得88.3%的最新结果。消融实验已经证明,所提出的网络确实可以学习判别性区域组,提高判别性特征值,有效地提高了准确率。
表1本发明方法的不同变种在cub-200-2011上的消融实验的识别结果
定性比较:准确度比较:因为提出的模型仅使用图像级标注,而不使用任何对象或部位标注,的比较集中在弱监督方法上。在表2和表3中,分别显示了不同方法在cub-200-2011数据集,stanfordcars-196数据集和fgvcaircraft数据集上的性能。在表2的自上而下,将不同方法分为六组,分别是(1)有监督的多阶段方法,该方法通常依赖于对象甚至部位标注来获得可用的结果。(2)弱监督多级框架,通过选择判别性区域逐渐击败了强监督方法。(3)弱监督的端到端特征编码,通过将cnn特征向量编码为高阶信息而具有良好的性能,但是依赖于较高的计算成本。(4)端到端定位分类子网络,可以在各种数据集上很好地工作,但是却忽略了判别性区域之间的相关性。(5)由于使用了额外的信息(例如语义嵌入),其他方法也取得了良好的性能。(6)的端到端gcl方法无需任何额外注释即可实现最佳效果,并且在各种数据集上均具有一致的性能。
表2在cub-200-2011,cars19和aircraft上的不同方法的比较
该方法优于第一组中这些强监督方法,这表明所提出的方法可以真正找到判别性的patch,而无需任何细粒度的标注。提出的方法考虑了区域之间的相关性以选择判别性区域组,然后通过选择判别性patch胜过第四组中其他方法。同时,很好地挖掘了所选判别性patch之间的内部语义相关性,来增强信息特征,而抑制那些无用特征。因此,通过加强特征表示,的工作优于第三组中其他方法,并实现了最优准确度,在cub数据集上为88.3%,汽车数据集上为94.0%,飞机数据集上为93.5%。
与ma-cnn相比,ma-cnn通过通道分组损失函数隐含地考虑patch之间的相关性,是通过反向传播的方式在部分注意力图上应用空间约束。的工作是通过迭代的交叉图传播找到最具判别性的区域组,而且以前向传播的方式将空间上下文融合到了网络中。表2中的实验结果显示,在cub,car和aircraft数据集上,gcl模型的性能优于ma-cnn。
表1中的结果显示,的模型优于大多数其他模型,但在car数据集上比dcl稍低。认为原因是car数据集的图像比cub和aircraft的图像具有更简单,更清晰的背景。具体而言,提出的gcl模型着重于增强判别性区域组的响应,从而更好地定位具有复杂背景的图像中的判别性patch。但是,在具有简单背景的图像中定位判别性patch相对容易,因此可能不会明显受益于判别性区域组的响应。另一方面,dcl模型在区域混淆机制中的混洗操作可能会引入一些视觉模式的噪声,因此图像背景的复杂性是影响dcl对判别性patch定位精度的关键因素之一。最终,dcl在car数据集上较简单的背景下在表现出更好的性能,而的gcl模型在cub和aircraft上在复杂背景下表现更好。
速度分析:以批处理大小8在titanx显卡上测量了速度。表3显示了与其他方法的比较。请注意,其他方法的参考在表2中。wsdl使用了fasterrcnn的框架,该框架可以保留大约300个候选patch。在这项工作中,利用具有秩损失的评分机制将patch数量减少到个位数,以实现实时效率。当根据判别性得分图选择2个判别性patch时,在速度和准确性上均优于其他方法。此外,当将判别性patch的数量增加到4个时,提出的模型不仅达到了最佳的分类精度,而且还保持了55fps的实时性。
表3在cub-200-2011上不同方法的效率和有效性的对比k表示每个图像选择的判别性区域的数量
定量分析:为了验证cgp的有效性,进行了消融实验,并将mo(图4(b))和mu(图4(c))进行了可视化。可视化结果表明,mo突出显示了多个连续区域,而mu在多次交叉传播之后增强了最具判别性的区域,这有助于准确地确定判别性区域组。
如图5所示,将cgp模块生成的相关权重系数图可视化,以更好地说明区域之间的相关影响。相关系数图表示某个区域和另一个在交叉位置的区域之间的相关性。可以观察到,相关系数图倾向于集中在几个固定区域(图5中的突出显示区域),并通过cgp联合学习逐渐整合更多判别区域,而且越靠近聚集的区域计算的频率越高。
- 还没有人留言评论。精彩留言会获得点赞!