面向流式数据的分布式自动处理方法及系统与流程
本发明属于数据处理技术领域,具体涉及一种面向流式数据的分布式自动处理方法及系统。
背景技术:
流式数据是指由若干不同的数据源持续生成的数据,随着传感器网络、航空航天、气象测控等应用领域的迅速扩展、iot用例的高速增长、以及传统领域对用户行为数据的持续深入挖掘,流式数据正从大量异构的数据源高速地流入数据存储。
传统的数据处理大致经历了以下几个阶段:
1.数据库阶段,主要是oltp(联机事务处理)的需求。这一阶段数据来源大部分是传统的结构化数据,数据量也并不大,简单的db就能满足需求,场景上强调高并发,单条数据简单提取和展示(增删查改)。
2.数据仓库阶段,olap(联机分析处理)成为主要需求。这一场景对并发的要求不高,但需要打通不同的异构数据库,如结构化数据和以日志形式沉淀的半结构化/非结构化的行为数据,并且能够进行批量的数据处理,也就是通常说的低并发,大批量(批处理)、面向分析(query+计算,用于制作报表)。针对分析需求,就诞生了数据仓库(dw,datawarehouse),以解决大量数据的存储和计算需求。数据库也在这一阶段从传统的单点集中式架构转向分布式。
3.数据平台阶段,原来的技术架构越来越不能支持海量技术处理。数据量呈指数级增长,随着iot(物联网)的发展,带动了视图声(视频、图像、声音)数据的增长,未来90%的数据可能都来自于视图声的非结构化数据,这些数据需要视觉计算技术、图像解析的引擎+视频解析的引擎+音频解析的引擎来转换成结构化数据。5g技术的发展,可能会进一步放大视图声数据的重要性。
上层的业务场景依托底层提供的数据服务基础能力,一方面希望用到数据服务基本的增删查改仓储能力,另一方面希望数据能为业务赋能,通过数据来改善业务,以至于拓宽业务场景的边界。同时,越来越多传统的业务场景也希望转变到数据驱动的轨道上,由此,日益增长的数据存储和仍然稀缺的数据应用就成为了企业的主要矛盾之一。
同时,由于企事业部门之间的系统分散开发或者些单位系统重建或引进系统开发项目,以及数据本身的异构不同源性质,导致很多单位内部之间的信息不能共享,产生数据与信息孤岛;或者没有统一的数据规范和标准,造成数据整合的不便。数据还仅仅停留在散乱的资源阶段,离数据“变现”,形成数据资产的理想阶段,还相距甚远。企业内部为各团队的重复建设付出了无谓的技术成本,并难以对前台跨团队/跨数据仓库的业务需求提供敏捷快速的支撑。
在数据开发中,核心数据模型的变化是相对缓慢的,同时,对数据进行维护的工作量也非常大;但业务创新的速度、对数据提出的需求的变化,是非常快速的。
传统的数据处理面临以下的三类问题:
效率问题:为什么应用开发增加一个报表,就要十几天时间?为什么不能实时获得用户推荐清单?当业务人员对数据产生一点疑问的时候,需要花费很长的时间,结果发现是数据源的数据变了,最终影响上线时间;
协作问题:当业务应用开发的时候,虽然和别的项目需求大致差不多,但因为是别的项目组维护的,所以数据还是要自己再开发一遍;
能力问题:数据的处理和维护是一个相对独立的技术,需要相当专业的人来完成,但是很多时候,我们有一大把的应用开发人员,而数据开发人员很少。
在数据存储的选型上,传统集中式/单一性的数据库架构已经无法支撑现代的海量数据处理和存储,存储和计算成本高,传统的纵向扩展能力面临单机性能的瓶颈,单点故障的风险大。
因此,针对上述技术问题,有必要提供一种面向流式数据的分布式自动处理方法及系统。
技术实现要素:
本发明的目的在于提供一种面向流式数据的分布式自动处理方法及系统。
为了实现上述目的,本发明一实施例提供的技术方案如下:
一种面向流式数据的分布式自动处理方法,所述方法包括:
获取若干异构数据源中的流式数据;
将流式数据分发并存储至数据平台中的数据库中;
基于不同的应用场景,提供标准化的数据视图给不同的业务。
一实施例中,所述流式数据包括结构化数据、非结构化数据、半结构化数据中的一种或多种。
一实施例中,所述结构化数据包括日常业务中crm/erp单条的结构化数据;非结构化数据包括以日志形式积累的用户行为的非结构化文本数据及带空域信息的雷达图片的非结构化图像数据;半结构化数据包括以日志形式积累的用户行为的半结构化文本数据。
一实施例中,所述数据平台中的数据库包括分布式存储的mysqlcluster数据库、newsql型tidb数据库、neo4j图形数据库、hbase数据库、mongodb数据库、ossstorage数据库、elasticsearch搜索和分析引擎数据库中的一种或多种。
一实施例中,获取若干异构数据源中的流式数据后还包括:
数据清洗,对流式数据的缺失进行预处理。
一实施例中,所述方法还包括:
通过建立数据分发器组件,建立数据源和数据平台的数据通信。
一实施例中,数据源和数据平台的数据通信为基于消息队列的订阅和广播机制的数据通信。
本发明一实施例提供的技术方案如下:
一种面向流式数据的分布式自动处理系统,所述系统包括数据源、数据平台及应用层,其中:
所述数据源包括若干异构数据源,用于存储提供流式数据;
所述数据平台包括若干分布式存储数据库,用于聚合和治理流式数据,并基于不同的应用场景,提供标准化的数据视图给不同的业务。
一实施例中,所述流式数据包括结构化数据、非结构化数据、半结构化数据中的一种或多种;结构化数据包括日常业务中crm/erp单条的结构化数据;非结构化数据包括以日志形式积累的用户行为的非结构化文本数据及带空域信息的雷达图片的非结构化图像数据;半结构化数据包括以日志形式积累的用户行为的半结构化文本数据。
一实施例中,所述数据平台中的数据库包括分布式存储的mysqlcluster数据库、newsql型tidb数据库、neo4j图形数据库、hbase数据库、mongodb数据库、ossstorage数据库、elasticsearch搜索和分析引擎数据库中的一种或多种。
与现有技术相比,本发明具有以下优点:
能够支撑现代企业对数据的进一步开发和利用,使数据对业务产生更大的价值,打通不同团队间的数据并且以统一的标准进行建设,以达到技术降本、应用提效、业务赋能的目标;
通过聚合和治理跨域的异构数据源,将数据抽象封装成服务,提供给前端以业务价值的逻辑概念,以弥补数据开发和应用开发之间由于开发速度不匹配,出现的响应力跟不上的问题。
具有水平易扩展性,可利用一般的x86硬件组成分布式集群数据库,扩充计算和存储能力。且扩展过程对上层应用透明无感知,同时通过合理的部署架构,可提供可用区级别的灾备能力。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
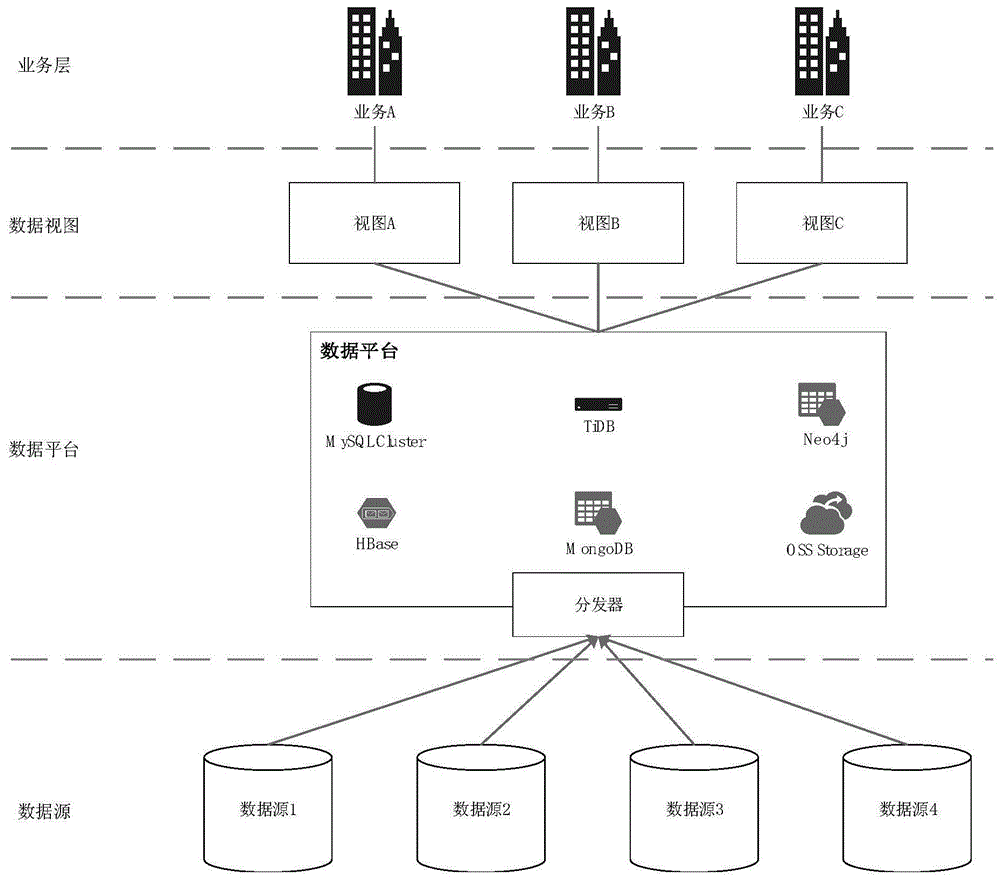
图1为本发明一具体实施例中面向流式数据的分布式自动处理系统的模块示意图;
图2为本发明一具体实施例中面向流式数据的分布式自动处理方法的流程示意图。
具体实施方式
以下将结合附图所示的各实施方式对本发明进行详细描述。但该等实施方式并不限制本发明,本领域的普通技术人员根据该等实施方式所做出的结构、方法、或功能上的变换均包含在本发明的保护范围内。
本发明公开了一种面向流式数据的分布式自动处理方法,包括:
获取若干异构数据源中的流式数据;
将流式数据分发并存储至数据平台中的数据库中;
基于不同的应用场景,提供标准化的数据视图给不同的业务。
本发明还公开了一种面向流式数据的分布式自动处理系统,包括数据源、数据平台及应用层,其中:
数据源包括若干异构数据源,用于存储提供流式数据;
数据平台包括若干分布式存储数据库,用于聚合和治理流式数据,并基于不同的应用场景,提供标准化的数据视图给不同的业务。
以下结合具体实施例对本发明作进一步说明。
参图1所示,本实施例中面向流式数据的分布式自动处理系统,包括数据源、数据平台及应用层,其中:
数据源包括若干异构数据源,用于存储提供流式数据;
数据平台包括若干分布式存储数据库,用于聚合和治理流式数据,并基于不同的应用场景,提供标准化的数据视图给不同的业务。
参图2所示,本实施例中面向流式数据的分布式自动处理方法,包括:
获取若干异构数据源中的流式数据;
将流式数据分发并存储至数据平台中的数据库中;
基于不同的应用场景,提供标准化的数据视图给不同的业务。
本实施例中的预设应用场景以民航系统的空域流量管制平台为例进行说明,在这个应用场景下,存在大量异构的不同数据源持续流入数据存储。数据类型除结构化的关系型数据外,还包括如带空域信息的雷达图片等非结构化数据,且现存的数据量极大。本实施例提供的数据平台为空域流量规划的业务数据提供海量存储能力,为多种异构数据源提供治理和聚合能力,保证底层计算和存储能力的易扩展性,对上层业务做到透明和无感知,并为上层承载的的多种应用场景提供标准化的的数据视图和接入标准。
本实施例中数据平台内存储的流式数据来源于多种异构的数据源,典型的包括日常业务中crm(客户关系管理)/erp(企业资源计划)单条的结构化数据积累,以日志形式积累的用户行为的非结构化/半结构化文本数据,以及如带空域信息的雷达图片等非结构化图像数据。在数据来源和数据本身的不同性质之外,数据到达的频率也是各不相同。
为此,数据平台流程的第一步就是对到达的流式数据进行预处理。
在数据清洗阶段,对流式数据的缺失进行处理。在数据集成阶段,将同构不同源的流式数据集成到统一的结构进行处理。并为用户提供对数据进行部分数据变换的能力。
数据平台流程的第二步,数据平台通过建立数据分发器组件,打通异构的数据源和数据平台内异构的数据存储。
在数据之间建立从数据源到本数据平台之间的一致性以及随着时间推移数据的持续协调,为用户提供简单标准化的接入方式,而由平台的组件来提供数据同步过程中所需要考虑的诸如自动容灾、错误恢复等能力。优选地,数据平台通过引入kafka等具有持久化能力的消息队列,解决数据同步速率与数据到达频率不匹配等问题,通过消息队列的订阅和广播等机制同时保证了数据同步端的水平扩展能力,并提供健全的错误恢复能力。
本发明中的数据平台中的数据库包括分布式存储的mysqlcluster数据库、newsql型tidb数据库、neo4j图形数据库、hbase数据库、mongodb数据库、ossstorage数据库、elasticsearch搜索和分析引擎数据库中的一种或多种。
具体地,本实施例中数据平台内核心的数据存储包括面向传统mysql架构的mysqlcluster集群,兼容大部分mysql协议、提供htap(hybridtransactional/analyticalprocessing,混合事务/分析处理)能力、兼容大部分mysql协议的分布式newsql型数据库tidb,图数据库neo4j,分布式的搜索和分析引擎elasticsearch,分布式面向列的存储系统hbase等等。
以上数据平台内异构的数据集群涵盖多种数据类型,支撑多种数据处理方式,为上层业务提供丰富的数据视图和数据处理能力。
此外,以上所列举的平台内数据集群的在架构上的一大特点是,相比于传统单点集中式的解决方案,这些数据存储都是分布式的,可通过一般的x86服务器进行快速地对上层应用无感知的水平扩展,并通过多点冗余提供更强的容灾保证,借助合适的部署架构,平台能够提供可用区级别的容灾能力。
面对上层的不同业务,通过定义协议标准,数据平台对上层提供多样的、标准化的接入方式,以满足不同业务场景对数据的从基本的增删查改到进一步地抽取分析的需求。面对多种不同的交互模式,提供不同的抽象/数据视图给应用层。数据平台内,统一jdbc/hdfs/hbase等存储访问,统一yarn/k8s等计算资源调度引擎。最终,使数据为业务场景赋能,实现数据驱动的业务执行目标。
应当理解的是,本实施例中对流式数据和分布式存储数据库进行了举例说明,但本发明并不限于上述的流式数据和分布式存储数据库,凡是采用上述方法及系统对流式数据进行处理的技术方案均属于本发明所保护的范围。
本发明提出的面向流式数据的分布式自动处理方法及系统,通过聚合和治理跨域的异构数据源,将数据抽象封装成服务,提供给前端以业务价值的逻辑概念;实现数据的分层与水平解耦,沉淀公共的数据能力;通过数据建模实现跨域数据整合和知识沉淀,通过数据服务实现对于数据的封装和开放,快速、灵活满足上层应用的要求,通过数据开发工具满足个性化数据和应用的需要。
上技术方案可以看出,本发明具有以下有益效果:
能够支撑现代企业对数据的进一步开发和利用,使数据对业务产生更大的价值,打通不同团队间的数据并且以统一的标准进行建设,以达到技术降本、应用提效、业务赋能的目标;
通过聚合和治理跨域的异构数据源,将数据抽象封装成服务,提供给前端以业务价值的逻辑概念,以弥补数据开发和应用开发之间由于开发速度不匹配,出现的响应力跟不上的问题。
具有水平易扩展性,可利用一般的x86硬件组成分布式集群数据库,扩充计算和存储能力。且扩展过程对上层应用透明无感知,同时通过合理的部署架构,可提供可用区级别的灾备能力。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施例加以描述,但并非每个实施例仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!