海量文本数据快速聚类方法与流程
本发明涉及文本聚类领域,尤其涉及海量文本数据快速聚类方法。
背景技术:
文本聚类是依据同文档的相似度较大,不同文档相似度较小的特点,来进行同类文档的聚合,目前聚类方法多集中在提高聚类准确率上,对聚类效率而言,处理千、万级别数量的文本数据所需时间比较长,且一般聚类算法的准确率也不能满足如此巨量文本数据的聚类需求,由于采用不同的聚类算法对聚类准确率和聚类时间的影响并不相同,因此,在对某种聚类算法的聚类评估上,可以从聚类准确率和聚类时间作为观察点,以对聚类效果进行有效判断,从而为不同聚类需求进行高效的聚类算法选择;目前在千、万级别数量的文本数据聚类处理和聚类效果的评估上是比较缺乏的。
技术实现要素:
本发明的目的在于,针对上述问题,提出海量文本数据快速聚类方法,适用于在计算机设备中执行,外部接口输入的命令行参数和指定目录下读取的文本信息经预处理后通过内部接口调用预设的结构体完成对指定目录下的文本数据聚类,输出指定目录下的excel文件或图形界面聚类结果,并对聚类效果进行评估。
进一步的,所述命令行参数包括聚类算法、词向量编码方式、文本距离度量方式以及评估方式;
所述聚类算法包括k均值、单遍聚类、层次聚类和密度聚类;
所述词向量编码方式包括simhash编码、word2vector向量和bert向量;
所述文本距离度量方式包括欧式距离、汉明距离、夹角余弦距离和k-l散度;
所述评估方式包括内部评估和外部评估。
进一步的,所述聚类方法包括以下步骤:
文本数据读取:从指定目录的文本文件中读取文本信息;
文本信息预处理:通过词向量编码方式完成词嵌入得到词向量;
文本数据聚类处理:结合至少一种聚类算法、内部或外部聚类算法评估体系对预处理后的词向量进行聚类和效果评估;
聚类结果输出:以excel格式或图形界面输出聚类结果。
进一步的,所述simhash编码基于文本距离度量方式对聚类文本相似性进行判断;所述word2vector向量由词向量叠加后求平均得到句向量,句向量叠加后求平均得到文档向量;所述bert向量在word2vector向量的基础上通过docker容器级别的web服务层,以http形式提供web服务,以满足多个任务请求服务的同时高效进行。
进一步的,在所述词向量编码方式中,所有词向量均采用200维的浮点数向量。
进一步的,所述文本信息预处理步骤包括如下子步骤:
s1:对中文文档进行分词,对英文文档进行token处理;
s2:去除停用词;
s3:计算去除停用词后的文档simhash编码;
s4:采用word2vector向量方式进行词嵌入,计算去除停用词后的文档向量;
s5:采用bert向量方式进行词嵌入得到词向量。
进一步的,所述词向量用于文本信息预处理阶段的词嵌入表示。
进一步的,所述结构体包括map结构体和list结构体,所述list结构体保存聚类的中间结果,所述map结构体保存聚类结果。
海量文本数据快速聚类系统,包括数据提取模块、聚类运行模块以及聚类结果输出模块;所述聚类运行模块包括预处理模块、聚类算法执行模块以及聚类效果评估模块。
进一步的,所述数据提取模块从指定目录的文本文件中读取文本信息并发送给预处理模块;
所述预处理模块接收外部接口输入的命令行参数和数据提取模块发送的文本信息后执行文本信息预处理步骤,将命令行参数和预处理后的词向量发送给聚类算法执行模块;
所述聚类算法执行模块通过内部接口调用预设的结构体完成对指定目录下的文本数据聚类;所述聚类效果评估模块通过内部或外部聚类算法评估体系对聚类效果进行评估;
所述聚类结果输出模块输出指定目录下的excel文件或图形界面聚类结果;当使用内部评估体系时,输出对聚类效果的内部评估指标值。
本发明的有益效果:本方法能够对给定的文本文件数据集合进行聚类操作,通过不少于4种的常规聚类算法,不少于3种的文本距离度量方式以及2种不同的聚类结果评估方式,实现对于万级别数量的文本文件数据聚类时间小于或等于10分钟,对于千级别数量的文本文件数据聚类时间小于或等于1分钟的聚类效率;同时通过内部或外部聚类算法评估体系实现对聚类算法的准确率和聚类效率做出评判,实现最优聚类算法策略。
附图说明
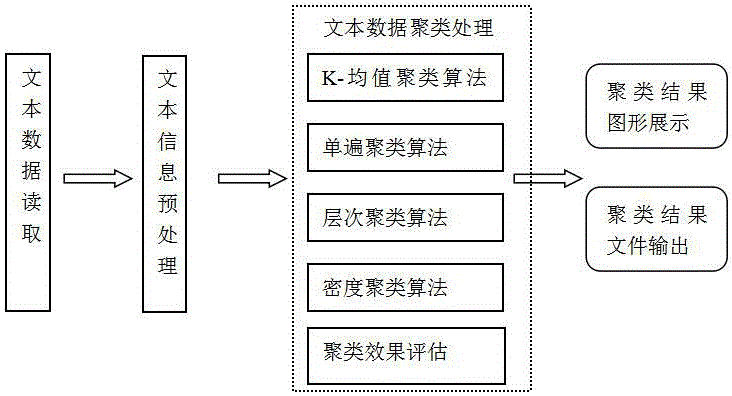
图1是本发明方法流程图;
图2是本发明聚类算法执行控制图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图说明本发明的具体实施方式。
海量文本数据快速聚类方法,适用于在计算机设备中执行,外部接口输入的命令行参数和指定目录下读取的文本信息经预处理后通过内部接口调用预设的结构体完成对指定目录下的文本数据聚类,输出指定目录下的excel文件或图形界面聚类结果,并对聚类效果进行评估。
所述命令行参数包括聚类算法、词向量编码方式、文本距离度量方式以及评估方式;聚类算法包括k均值、单遍聚类、层次聚类和密度聚类;词向量编码方式包括simhash编码、word2vector向量和bert向量;文本距离度量方式包括欧式距离、汉明距离、夹角余弦距离和k-l散度;评估方式包括内部评估和外部评估。
用户在进行文档聚类选择时,可通过外部接口输入选择的命令行参数,对于聚类算法,默认为单遍聚类;对于词向量编码方式,默认为simhash编码;对于文本距离度量方式默认为欧式距离;对于评估方式默认为内部评估。
所述simhash编码基于文本距离度量方式对聚类文本相似性进行判断;所述word2vector向量由词向量叠加后求平均得到句向量,句向量叠加后求平均得到文档向量;所述bert向量在word2vector向量的基础上通过docker容器级别的web服务层,以http形式提供web服务,以满足多个任务请求服务的同时高效进行。
如图1所示文本聚类方法包括以下步骤:
文本数据读取:从指定目录的文本文件中读取文本信息,在指定目录下读取需要进行聚类的文本数据文件;
文本信息预处理:通过词向量编码方式完成词嵌入得到词向量,主要的预处理有:
分词(如果是英文文档,则没有分词,但是需要进行token处理);
去除停用词;
采用simhash编码方式,则直接计算去除停用词后的文档simhash编码;
采用word2vector向量方式进行词嵌入,则直接计算去除停用词后的文档的向量,具体方式是文档的向量由句子向量叠加后求平均,句子向量由词向量叠加后求平均;
采用bert向量方式进行词嵌入,其基本原理和使用word2vector方式相同,但是因为bert模型规模很大,如果像使用word2vector向量进行直接调用,则无法高效的同时为多个任务请求服务,因此在这里使用docker容器技术专门为使用bert模型搭建一个容器级别的web服务,通过在docker容器级别的web服务层,以http形式提供基于restful风格的web服务;
文本数据聚类处理:结合至少一种聚类算法、内部或外部聚类算法评估体系对预处理后的词向量进行聚类和效果评估;文本聚类算法提供了不少于4种聚类算法实现,分别是基于k均值、层次、密度、单遍等算法,同时提供了2个大类的聚类算法评估体系,外部评估体系与内部评估体系;
聚类结果输出:同时提供excel格式的聚类结果输出与图形界面的聚类结果输出;此外,当使用内部评估体系时,可以输出对聚类效果的内部评估指标值。
所述词向量用于文本信息预处理阶段的词嵌入表示,所有词向量均采用200维的浮点数向量。
所述预设的结构体包括保存聚类结果的map结构体和保存聚类的中间结果的list结构体。
一种实现上述文本聚类方法的文本聚类系统,包括数据提取模块、聚类运行模块以及聚类结果输出模块;所述聚类运行模块包括预处理模块、聚类算法执行模块以及聚类效果评估模块。
所述数据提取模块从指定目录的文本文件中读取文本信息并发送给预处理模块;
所述预处理模块接收外部接口输入的命令行参数和数据提取模块发送的文本信息后执行文本信息预处理步骤,将命令行参数和预处理后的词向量发送给聚类算法执行模块;
所述聚类算法执行模块通过内部接口调用预设的结构体完成对指定目录下的文本数据聚类;所述聚类效果评估模块通过内部或外部聚类算法评估体系对聚类效果进行评估;
所述聚类结果输出模块输出指定目录下的excel文件或图形界面聚类结果;当使用内部评估体系时,输出对聚类效果的内部评估指标值。
如图2所示聚类算法执行模块执行正常时,聚类效果评估模块通过内部或外部聚类算法评估体系对聚类效果进行评估;当出现文本数据集合过大,造成内存溢出时,系统内部数据、状态全部回滚到出错前状态,并记录聚类算法执行出错情况。
所述文本聚类系统还包括日志管理模块,所述日志管理模块记录出错信息,所述出错信息包括出错时间、出错等级、出错原因以及出错地点,其中出错地点使用递归调用展示。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书界定。
- 还没有人留言评论。精彩留言会获得点赞!