融合时间衰减因子的LFM训练样本构建方法与流程
本发明涉及互联网大数据处理技术领域,具体涉及一种融合时间衰减因子的lfm训练样本构建方法。
背景技术:
融合时间衰减因子的lfm方法(fc-lfm)是一种基于机器学习的隐语义模型,每个用户的用户特征矩阵p和物品特征矩阵q都是对训练样本进行学习来产生,因此,训练样本库的构建方法就显得尤为重要。传统的lfm对用户u的训练样本的构建方法是将用户u评价过的物品作为正样本,其评价值设为1,再从训练集中随机抽取一定数量的用户u没有评价过的物品,组成负样本,其评价值设为0。将正、负样本组成用户u的训练样本。
由于负样本是表示用户不感兴趣的物品,而用户没有评价过的物品中,也许有些物品是因为不够流行,导致用户并不知道该物品,而不一定是用户不喜欢的类型。完全随机的抽取用户没有评价过的物品作为负样本,因没有考虑到用户不知道该物品而没有评价的原因,会导致推荐准确率下降。但是,如果负样本采集过于集中于流行度高的物品,又会导致训练样本库的多样性损失,同样会降低推荐准确率,因此,需要通过实验找到样本流行度与多样性相互影响的平衡点,作为样本组成的依据。
技术实现要素:
本发明提供一种综合考虑物品流行度和样本多样性对推荐性能的影响、融合时间衰减因子的lfm训练样本构建方法。
为了达到上述目的,本发明通过以下技术方案来实现:
融合时间衰减因子的lfm训练样本构建方法,包括如下步骤:
s1)从训练样本中获得用户u评价过的物品,数量为sp,作为正样本;
s2)计算整个训练集中的物品的流行度:
其中,ui表示对物品i做出过评价的用户,tr表示训练集,fit表示物品i在t时刻的时间衰减因子;
其中,tnow是当前时间,
s3)采用辛普森多样性指数(simpsonindex)来评估样本库的数据多样性,公式为:
其中,s表示整个样本集,pi表示抽取的样本落在i区间的概率;
s4)对流行度从高到低的顺序进行排序,分别用流行度前10%、20%、30%、....、100%作为样本库,并从中随机抽取负样本构建学习样本库,保持参数α=0.1,正则化参数λ=0.01不变,训练集迭代次数epochs=10,分类数k=30,正负样本比为1:10,给出不同样本库组成时的算法推荐准确度和召回率,并制表比对;
准确率描述推荐列表中包含多少比例的物品是用户确实看过的,其计算公式为:
召回率是描述测试集t中用户看过的物品有多少比例出现在推荐列表中,其计算公式为:
其中,t表示测试集,r(u)表示依据推荐算法对用户u推荐的物品列表,t(u)表示用户u在测试集t中真实评价过的物品;
s5)从用户u没有评价过的样本中,根据公式
s6)将正、负样本组成样本集,作为用户u的训练样本库。
本发明与现有技术相比,具有以下优点:
本发明融合时间衰减因子的lfm训练样本构建方法,综合考虑物品流行度和样本多样性对推荐性能的影响并融合时间衰减因子,通过实验给出不同样本库组成时的算法推荐准确度和召回率,分析得出最优流行度占比,从而得到最优的负样本,获得较好的fc-lfm算法训练效果。
附图说明
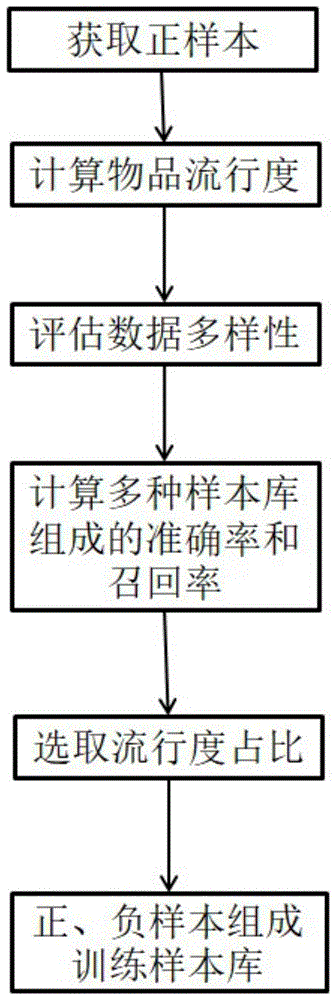
图1是本发明的流程示意图。
图2是本发明实施例中最流行电影占比对算法推荐性能的影响图。
图3是本发明实施例中样本库数据多样性对算法推荐性能的影响图。
具体实施方式
下面结合附图,对本发明的实施例作进一步详细的描述。
本发明采用的数据集是美国minnesota大学grouplensresearch实验室提供的movielens(100k)(https://grouplens.org/datasets/movielens/100k/),该数据集包括943名用户对1682部电影的10万条评分记录,数据稀疏度达到93.7%。每条记录包括用户对该电影的评分(1-5分)及评分时间(精确到秒)。本发明将该数据集按照9:1的比例随机抽取数据形成训练集和测试集,用于算法的训练及测试使用。
具体地,融合时间衰减因子的lfm训练样本构建方法,包括如下步骤:
s1)从训练样本中获得用户u评价过的电影,数量为sp,作为正样本;
s2)为了评估电影的受欢迎程度,本发明采用流行度(popularuty)指标来评估,流行度表示所有用户中评价过该物品的用户的比例,流行度越高,表示评价过该物品的用户越多,由于时间因素对流行度的影响,早期流行的物品近期不一定流行,因此,本文对流行度引入时间衰减因子,计算整个训练集中的电影的流行度:
其中,ui表示对电影i做出过评价的用户,tr表示训练集,fit表示电影i在t时刻的时间衰减因子;
其中,tnow是当前时间,
s3)为了评估样本库的数据多样性对算法学习性能的影响,采用辛普森多样性指数(simpsonindex)来评估样本库的数据多样性,其表示随机取样的两个个体属于不同种类数据的概率,其值越大表示样本越分散,值越小表示越集中,公式为:
其中,s表示整个样本集,pi表示抽取的样本落在i区间的概率;
s4)对流行度从高到低的顺序进行排序,分别用流行度前10%、20%、30%、....、100%作为样本库,并从中随机抽取负样本构建学习样本库,保持参数α=0.1,正则化参数λ=0.01不变,训练集迭代次数epochs=10,分类数k=30,正负样本比为1:10,给出不同样本库组成时的算法推荐准确度和召回率,并制表1比对;
准确率和召回率可以反映推荐算法的有效性,其中准确率描述推荐列表中包含多少比例的电影是用户确实看过的(针对测试集t),其计算公式为:
召回率是描述测试集t中用户看过的电影有多少比例出现在推荐列表中,其计算公式为:
其中,t表示测试集,r(u)表示依据推荐算法对用户u推荐的电影列表,t(u)表示用户u在测试集t中真实评价过的电影;
表1不同样本库的算法预测误差
s5)为了评估样本库中的样本按照流行度排序覆盖整个样本库的程度,本文采用样本库的流行度占比(pratio)来表示,流行度占比越小,表示样本库中的样本越集中在流行度最高的一些样本上,如流行度占比为20%,则表示将训练样本集中的流行度最高的20%的样本组成样本库,其公式为
从用户u没有评价过的样本中,根据式(6)选择流行度占比为rbest的样本作为负样本;
s6)将正、负样本组成样本集,作为用户u的训练样本库。
图1和图2展示了电影流行度及样本多样性对算法推荐准确度和召回率的影响趋势图。从表1和图1、图2可以看出,在样本多样性指数小于0.875时,随着样本多样性的提高,算法推荐准确度和召回率逐渐增大,此时样本多样性对算法带来的好处大于样本库中不流行电影增加带来的坏处;随着不流行电影的不断加入,样本多样性虽然进一步提高,但算法推荐准确度和召回率反而减小,可见此后,不流行电影对算法预测误差的影响已经大于样本多样性带来的好处。因此,在后续实验中,样本库由训练集流行度前80%的电影组成(流行度占比=80%)。
以上所述仅是本发明优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!