一种基于图像识别的pdf表格结构识别方法与流程
本发明涉及图像识别技术,尤其涉及一种基于图像识别的pdf表格结构识别方法。
背景技术:
在大数据和人工智能的应用场景下,要对大量的信息进行搜集、处理、分析,对数据进行结构化,发现数据中的规律来指导生产。信息的存在方式是多样的、非结构化的,大量的信息存在于表格中,而表格可能存在于pdf、网页、图像中。针对pdf中的表格,目前存在的表格解析方法大致有通过读取pdf的xml信息来解析表格(如xpdf工具)、将pdf转为xml、html、word等其他格式再解析(如pdf-docx工具)、将pdf转为图像再进行结构识别,前两种由于pdf文件本身的信息损失,都不能准确地进行解析,第三种方法主要依赖于图像识别算法,目前现存的方法对复杂表格也不能够准确识别。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种基于图像识别的pdf表格结构识别方法,能够得到表格的单元格排列信息,如第i行第j列的具体内容,以及复杂表格的跨列(colspan)、跨行(rowspan)信息。
本发明的目的是通过以下技术方案来实现的:一种基于图像识别的pdf表格结构识别方法,该方法包括以下步骤:
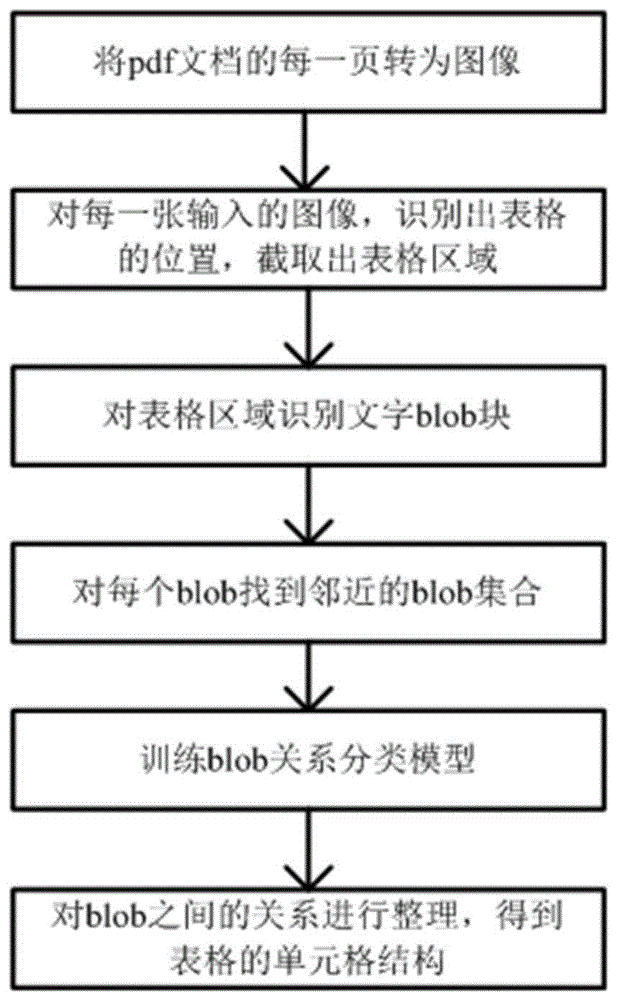
(1)将pdf文档的每一页转为图像;
(2)对每一张输入的图像,识别出表格的位置,截取出表格区域;
(3)对表格区域识别文字blob块;
(4)对每个blob找到邻近的blob集合:对表格区域内的blob集合按照图像y坐标进行排序,排列成多行的blob集合,每行的blob集合按照x坐标排序;排序后,对每行中的blob,找到同一行中下一个相邻的blob、下一行中与其x轴上有重合的blob作为其邻近集合;
(5)训练blob关系分类模型,包括:
训练数据:将标注数据中的每个blob与其邻近集合中的每个blob建立blob对,得到每个blob对的两种关系:是否同行、是否同列,作为groundtruth;再计算每个blob对的特征;
训练模型:建立两个分类器,分别用于分类是否同行、是否同行;
模型预测:预测blob与邻近集合中每个blob是否同行、同列;
(6)对blob之间的关系进行整理,得到表格的单元格结构:
分别计算表格的列集合和行集合;
表格的单元格:将表格行集合按照图像的y坐标排序,列集合按照图像的x坐标排序,再将每行每列进行交叉,得到表格的单元格;
整理单元格中的blob:将每个单元格中的blob按行排列,并将每一行的blob合并为一个大blob,并将大blob的横坐标扩展到表格的单元格边界,再对这一个大blob进行字符识别,得到该单元格的文字内容。
进一步地,步骤(2)中采用基于rcnn的神经网络建立表格检测器,识别出表格位置。
进一步地,步骤(3)中基于ctpn、craft、tesseract等工具识别表格区域的文字blob块。
进一步地,训练数据整理过程中,每个blob对(blobi,blobj)的特征包括:blobi和blobj的图像坐标、字符串长度、两个blob之间的欧氏距离、x轴重合率、y轴重合率,将这些值的绝对值和相对值都作为特征。
进一步地,训练模型过程中,选用svm、dnn、gnn、transformer等模型建立分类器。
进一步地,所述步骤(6)中,对于表格列的计算过程如下:
对每行中的blob,在该blob的邻近集合中找出在同一行的blob集合blob_sameline_neighbor,在blob_sameline_neighbor中找出与该blob有同列关系的blob,将该blob和与其有同列关系的blob共同形成一个分枝branch={blobi},i=0,1,..n_branch,n_branch为与该blob有同列关系的blob数量;将有共同blob的branch合并,得到这一行的branch集合branch_this={branchj},j=0,1,..n_branch_this,n_branch_this为该行的分枝数量;再与上一行得到的branch集合branch_last={branchk},k=0,1,..n_branch_last进行合并,n_branch_last为上一行的分枝数量,即将branch_this集合中有和branch_last集合中有相同blob的某一branchj和branchk合并,得到更新后的集合branch_last={branchk},k=0,1,..n_branch_last_update,如果branchj在branch_last中找不到有相同blob的分枝,则将branchj增加到branch_last集合;最终得到的branch_last集合,集合中的每个branch都是表格的一列。
进一步地,所述步骤(6)中,对于表格行的计算过程如下:
对每列中的blob,在该blob的邻近集合中找出在同一列的blob集合blob_sameline_neighbor,在blob_sameline_neighbor中找出与该blob有同行关系的blob,将该blob和与其有同行关系的blob共同形成一个分枝branch={blobi},i=0,1,..n_branch,n_branch为与该blob有同行关系的blob数量;并将有共同blob的branch合并,得到这一列的branch集合branch_this={branchj},j=0,1,..n_branch_this,n_branch_this为该列的分枝数量;再与上一列得到的branch集合branch_last={branchk},k=0,1,..n_branch_last进行合并,n_branch_last为上一列的分枝数量,即将branch_this集合中有和branch_last集合中有相同blob的某一branchj和branchk合并,得到更新后的集合branch_last={branchk},k=0,1,..n_branch_last_update,如果branchj在branch_last中找不到有相同blob的分枝,则将branchj增加到branch_last集合;最终得到的branch_last集合,集合中的每个branch都是表格的一行。
本发明的有益效果是:本发明去掉了图像特征,并增加了与邻接块的边的特征,用blob领域缩小了表格中文本块的搜索范围,大大加快了收敛速度和识别的准确率。对文字blob的检测和后处理消除了字符遗漏的问题。
附图说明
图1为本发明基于图像识别的pdf表格结构识别方法的流程图;
图2为表格的文本blob示意图;
图3为表格结构识别结果示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
如图1所示,本发明提供的一种基于图像识别的pdf表格结构识别方法,该方法将其他格式的文档转为图像,对每一张输入的图像,识别出表格的位置,截取出表格区域,对表格区域识别文字blob块,对每个blob找到邻近的blob,对blob与每一个邻近blob之间的关系进行预测(是否同一行、是否同一列),最后通过这些关系得到表格的结构。具体实现步骤如下:
1.将pdf文档的每一页转为图像。
2.对每一张输入的图像,识别出表格的位置,截取出表格区域。
在本申请实施例中,可以采用基于rcnn的神经网络建立表格检测器,识别出表格位置。
3.对表格区域识别文字blob块,如图2所示,图中每个黑色矩形框为一个文本blob。
在本申请实施例中,可以基于ctpn、craft、tesseract等工具进行识别。
4.对每个blob找到邻近的blob集合,包括:
对表格区域内的blob集合按照图像y坐标进行排序,排列成多行(textline)的blob集合,每行的blob集合按照x坐标排序;排序后,对每行中的blob,找到同一行中下一个相邻的blob、下一行中与其x轴上有重合的blob作为其邻近集合。
5.训练blob关系分类模型。
训练数据:将标注数据中的每个blob与其邻近集合中的每个blob建立blob对,得到每个blob对的2种关系:是否同行、是否同列,作为groundtruth;再计算每个blob对(blobi,blobj)的特征:blobi和blobj的图像坐标、字符串长度、两个blob之间的欧氏距离、x轴重合率、y轴重合率,将这些值的绝对值和相对值都作为特征。
训练模型:选用svm、dnn、gnn、transformer等模型建立分类器,建立两个分类器,用于分类是否同行、是否同行。
模型预测:与训练数据整理过程一样,得到每个blob的邻近blob集合,预测blob与邻近集合中每个blob得到它们是否同行、同列。
6.对blob之间的关系整理,得到表格的单元格结构,即表格列(哪些blob在同一列)、表格行(哪些blob在同一行)、表格单元格(哪些blob属于同一个单元格)。
对于表格列的计算:对每行(textline)中的blob,在该blob的邻近集合中找出在同一行的blob集合blob_sameline_neighbor,在blob_sameline_neighbor中找出与该blob有同列关系的blob,将该blob和与其有同列关系的blob共同形成一个分枝branch={blobi},i=0,1,..n_branch,n_branch为与该blob有同列关系的blob数量;并将有共同blob的branch合并,得到这一行的branch集合branch_this={branchj},j=0,1,..n_branch_this,n_branch_this为该行的分枝数量;再与上一行(textline)得到的branch集合branch_last={branchk},k=0,1,..n_branch_last进行合并,n_branch_last为上一行的分枝数量,即将branch_this集合中有和branch_last集合中有相同blob的某一branchj和branchk合并,得到更新后的集合branch_last={branchk},k=0,1,..n_branch_last_update,如果branchj在branch_last中找不到有相同blob的分枝,则将branchj增加到branch_last集合;最终得到的branch_last集合,集合中的每个branch都是表格的一列。
对于表格行的计算是类似的:对每列中的blob,在该blob的邻近集合中找出在同一列的blob集合blob_sameline_neighbor,在blob_sameline_neighbor中找出与该blob有同行关系的blob,将该blob和与其有同行关系的blob共同形成一个分枝branch={blobi},i=0,1,..n_branch,n_branch为与该blob有同行关系的blob数量;并将有共同blob的branch合并,得到这一列的branch集合branch_this={branchj},j=0,1,..n_branch_this,n_branch_this为该列的分枝数量;再与上一列得到的branch集合branch_last={branchk},k=0,1,..n_branch_last进行合并,n_branch_last为上一列的分枝数量,即将branch_this集合中有和branch_last集合中有相同blob的某一branchj和branchk合并,得到更新后的集合branch_last={branchk},k=0,1,..n_branch_last_update,如果branchj在branch_last中找不到有相同blob的分枝,则将branchj增加到branch_last集合;最终得到的branch_last集合,集合中的每个branch都是表格的一行。
表格的单元格:之后将表格行集合按照图像的y坐标排序,列集合按照图像的x坐标排序,再将每行每列进行交叉,得到表格的单元格,如同时存在第i行的blob集合和第j列的blob集合的blob,就构成了表格的第i行j列的单元格。
整理单元格中的blob:将每个单元格中的blob按行排列,并将每一行的blob合并为一个大的blob,并将大blob的横坐标扩展到表格的单元格边界,再对这一个大blob进行字符识别(ocr),得到该单元格的文字内容,该步骤可以消除blob检测中漏掉的字符,如”,.:-”等标点符号和其他较小的字符。字符识别可基于crnn模型,如tesseract-ocr工具。
如图3所示,将同一单元格的文本blob识别出来后,形成一个大的文本blob;左侧角标为单元格的行列位置,如”1_0”表示第1行第0列的单元格,单元格的内容为”bodyweight(kg)”。
以上所述仅是本发明的优选实施方式,虽然本发明已以较佳实施例披露如上,然而并非用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何的简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!