一种构建数据类目体系的方法和系统与流程
本发明涉及数据分类技术,更具体而言,涉及一种构建数据类目体系的方法和系统。
背景技术:
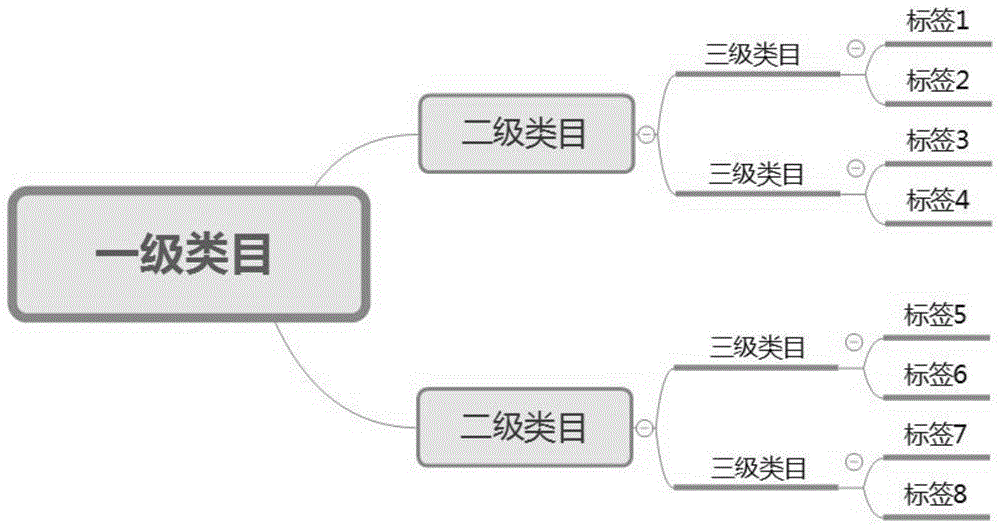
:越来越多的企业拥有或者控制越来越多的以物理或电子方式记录的数据。为了能更好地分析、利用这些数据,通常需要构建数据类目体系。数据类目体系越完整(即丰度越高),企业对数据的使用就越高效。当前一般通过对数据进行人工整理和分类来构建数据类目体系,缺少自动构建数据类目体系的技术方案。技术实现要素:本发明提供了一种构建数据类目体系的方法,其包括获取新类目;将所述新类目和所述数据类目体系中的现有类目向量化;通过比较向量化的所述新类目与向量化的所述现有类目之间的相似度来确定所述新类目在所述数据类目体系中的位置。在一种实施方案中,所述获取操作包括从数据资产中读取数据;和对所述数据进行分词以生成所述新类目。在一种实施方案中,所述数据是表名或字段名。在一种实施方案中,所述确定操作包括确定所述新类目在所述数据类目体系中的最佳类目层级;并且其中,与其他类目层级相比,所述新类目与所述最佳类目层级的相似度最高。在一种实施方案中,所述新类目与所述最佳类目层级中的全部现有类目的相似度的平均值和标准差的乘积不低于其他类目层级。在一种实施方案中,当所述数据是表名时,所述新类目在除最低类目层级之外的类目层级中;并且当所述数据是字段名时,所述新类目在最低类目层级中。在一种实施方案中,所述确定操作包括确定所述新类目在所述数据类目体系中的最佳类目序列;并且其中,与其他类目序列相比,所述新类目与所述最佳类目序列的相似度最高。在一种实施方案中,所述新类目与所述最佳类目序列中的全部现有类目的相似度的乘积不低于其他类目序列。在一种实施方案中,当所述新类目的类目层级已经确定时,所述新类目与所述最佳类目序列的相似度是所述新类目与所述类目序列中的部分现有类目的相似度的乘积;并且其中,所述部分现有类目的类目层级比所述新类目的类目层级高。在一种实施方案中,该方法还包括以二维数组表示所述新类目的所述位置。本发明还提供了一种构建数据类目体系的系统,其包括用于获取新类目的装置;用于将所述新类目和所述数据类目体系中的现有类目向量化的装置;和用于通过比较向量化的所述新类目与向量化的所述现有类目之间的相似度来确定所述新类目在所述数据类目体系中的位置的装置。本发明还提供了一种计算机可读介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上面描述的方法。本发明能够自动构建数据类目体系。使用本发明的方法构建的数据类目体系具有较高的完整度。附图说明图1是根据本发明的实施例的数据类目体系的示意图。图2是根据本发明的实施例的构建数据类目体系的方法的流程图。图3a和3b是根据本发明的实施例的确定新类目在数据类目体系中的类目层级的示意图。图4a和4b是根据本发明的实施例的确定新类目在数据类目体系中的类目序列的示意图。具体实施方式现在将参照若干示例性实施例来说明本发明的内容。应当理解,说明这些实施例仅是为了使得本领域普通技术人员能够更好地理解并且因此实现本发明的内容,而不是暗示对本发明的范围进行任何限制。如本文中所使用的,术语“包括”及其变体应当解读为意味着“包括但不限于”的开放式术语。术语“基于”应当解读为“至少部分地基于”。术语“一个实施例”和“一种实施例”应当解读为“至少一个实施例”。术语“另一个实施例”应当解读为“至少一个其他实施例”。在本发明的实施例中,“数据类目体系”指的是包含一个或多个领域中数据的类目的集合。在本发明的实施例中,“类目”指的是描述特定领域中数据的内容的关键词。例如,营销领域的数据类目体系可以包含如下类目:人、消费者、人口学属性、性别、年龄等。在计算机系统的实施层面,类目表现为关键词的字符串(以中文或其他文字的形式)。在本发明的实施例中,数据类目体系中的类目可以被划分在不同的层级中。在本发明的实施例中,每个类目层级可以包含多个类目。在本发明的实施例中,数据类目体系可以包含一个或多个(例如,两个以上)类目层级。低类目层级中的类目从属于一个或多个高类目层级的类目。例如,低类目层级中的类目“性别”从属于不同高类目层级中的类目“人”、“消费者”和“人口学属性”。在本发明的实施例中,最低类目层级又称为标签层级,并且最低类目层级中的类目又称为标签。图1示出了根据本发明的实施例的数据类目体系,其表现为树状结构。在该树状结构中,最低类目层级表述为标签层级。在本发明的实施例中,“类目序列”指的是由具有从属关系的各个类目层级中的一个类目排列组成的序列,其是从最高层级类目到最低层级类目的有顺序的排列。例如,在图3a所示的数据类目体系中,类目序列可以是“a-b1-c2-d2”或“a-b2-c3-d5”。前述“性别”类目的例子中也形成序列“人-消费者-人口学属性-性别”。如本领域中公知的,“相似度”指的是两个词语各自生成的向量之间的距离。例如,词语a的向量为[a1,a2],词语b的向量为[b1,b2],则它们之间的相似度相似度越高,则两个词语的词义越接近。在本发明的实施例中,s为1表示相似度最高,s为0表示相似度最低。在本发明的实施例中,可以使用其他相似度计算公式。图2示出了根据本发明的实施例的构建数据类目体系的方法,其包括确定新类目在数据类目体系中的位置和将新类目添加到数据类目体系的上述位置中。在本发明的实施例中,该方法包括获取新类目;将新类目和数据类目体系中的现有类目向量化;通过比较向量化的新类目与向量化的现有类目之间的相似度来确定新类目在数据类目体系中的位置。在本发明的实施例中,“新类目”指的是待添加到数据类目体系中的位置未确定的类目。在本发明的实施例中,“现有类目”指的是数据类目体系中已经存在的位置确定的类目。在本发明的实施例中,新类目可以源自从数据资产中获取的数据,包括但不限于表名和字段名。在本发明的实施例中,数据资产指的是存储在数据库中的表。在本发明的实施例中,可以将数据资产(比如mysql数据库中的表)中的表名和/或字段名同步到待进行后续操作的数据库中。在本发明的实施例中,同步操作可以是复制、移动等操作。在本发明的实施例中,可以通过例如分词工具(比如可从https://github.com/fxsjy/jieba获得的jieba分词工具)等对表名和/或字段名进行分词处理以生成新类目。在本发明的实施例中,字段名分词处理后获得的是标签。在本发明的实施例中,表名分词处理后获得的是除标签以外的类目。在本发明的实施例中,可以通过例如词语向量化工具(比如word2vec,可从https://github.com/dav/word2vec获得)等进行类目的向量化。在本发明的实施例中,通过比较向量化的类目之间的相似度,能够确定新类目在数据类目体系中的位置。在本发明的实施例中,新类目在数据类目体系中的位置指的是新类目在数据类目体系中所处的类目层级和类目序列。在本发明的实施例中,新类目所处的类目层级的确定依据的是待确定类目层级的新类目与数据类目体系中现有类目层级之间的相似度。在本发明的实施例中,首先计算待确定类目层级的新类目与每个类目层级中的所有类目的相似度的平均值和标准差,然后将平均值和标准差乘积最大的那个类目层级作为新类目所属的类目层级(最佳类目层级)。如果有多个类目层级所得乘积最大且相同,可以随机选择其中之一作为最佳类目层级。在本发明的实施例中,通过平均值来衡量新类目与现有类目层级的相似度,通过标准差来对上述相似度作修正。在本发明的实施例中,可以使用其他方法计算新类目和各个类目层级之间的相似度。图3a和3b示出了根据本发明的实施例的在数据类目体系中添加新类目的方法。图3a示出了需要确定新类目x应当属于哪个类目层级。参见图3b,首先计算新类目x与每个现有类目a、b1-b2、c1-c4和d1-d6之间的相似度si,j(i代表类目层级的序号,j代表类目层级中包含的类目的序号),然后计算出新类目x与每个类目层级中的所有类目的相似度的“平均值和标准差的乘积”,并且将最高乘积对应的类目层级作为新类目x所属的类目层级。例如,如果计算出s31、s32、s33、s34的平均值和标准差的乘积最高,则可以确定新类目x属于第3类目层级。如果待确定位置的类目是标签,由于其所处的类目层级已经确定为最低级,因此不需要再计算确定其所处的类目层级。如果待确定位置的类目是除标签之外的类目,由于已经规定其所处的类目层级不是最低级,因此在进行上述类目层级相似度计算时,不需要计算待确定位置的类目与最低层级的相似度。在本发明的实施例中,新类目所处的类目序列的确定依据的是待确定类目序列的新类目与数据类目体系中现有类目序列之间的相似度。在本发明的实施例中,首先计算待确定类目序列的新类目与类目序列中的所有类目的相似度的乘积,然后将乘积最大的那个类目序列作为新类目所属的类目序列(最佳类目序列)。如果有多个类目序列所得乘积最大且相同,则可以随机选择其中之一作为最佳类目序列。在本发明的实施例中,可以使用其他方法计算新类目和各个类目序列之间的相似度。在本发明的实施例中,如果待确定类目序列的新类目的类目层级已经确定,则不需要计算其与类目序列中的所有类目的相似度的乘积,而只需要计算其与类目序列中的一部分类目的相似度的乘积,所述一部分类目所处的类目层级比新类目的类目层级高。图4a和4b示出了根据本发明的实施例的确定新类目在数据类目体系中的类目序列的方法。如图4a所示的,已经通过上面图3a和3b中的方法确定了新类目dx属于第4类目层级。图4b显示了通过分别计算新类目dx和类目序列a-b1-c1、a-b1-c2、a-b2-c3和a-b2-c4之间的相似度,然后再计算相似度的乘积:s11*s21*s31、s11*s21*s32、s11*s22*s33和s11*s22*s34,取这四个乘积中值最大的那个序列,作为类目dx所属的类目序列。例如,最大值为s11*s22*s33,那么新类目dx的位置第4类目层级并且从属于a-b2-c3类目序列,即直接从属于类目c3。由于新类目dx的类目层级已经确定,因此只需要计算类目序列中比第4类目层级更高的层级中的类目的相似度。按照上述计算得到的类目层级和类目序列,将新类目添加到数据类目体系中。例如,可以把类目作为数组值存储在二维数组中,数组中的单个变量对应某一个待确定的类目。一个二维数组构成一个完整的数据类目体系。如下面的表1中显示的,其同样也构成一个二维数组a,第1、2、3列中分别是不同层级的类目,a(i,j+1)必定从属于a(i,j)。例如,a(10,2)对应的类目“资产情况”必定属于a(10,1)对应的类目“基础特征”。表11231基础特征性别属性会员性别2基础特征性别属性用户身份证性别3基础特征年龄属性会员生日4基础特征年龄属性用户身份证年龄段5基础特征姓名属性会员姓名6基础特征姓名属性收件人名个数7基础特征姓名属性收件地址个数8基础特征联系方式收件手机号码归属地9基础特征联系方式收件手机号码个数10基础特征资产情况资产等级11基础特征资产情况是否有房12基础特征资产情况是否有车13基础特征资产情况居住小区价格14基础特征车辆属性汽车数量15基础特征车辆属性车辆品牌16基础特征车辆属性车辆派系17基础特征车辆属性用户车龄18基础特征车辆属性保养频次19基础特征车辆属性是否美容20基础特征车辆属性是否改装21基础特征车辆属性改装热度22基础特征车辆属性是否爱车23基础特征车辆属性爱车热度24基础特征家庭情况是否已婚25基础特征家庭情况有无子女26基础特征家庭情况是否有宠物本发明各实施例的方法和装置可以实现为纯粹的软件模块(例如用java语言来编写的软件程序),也可以根据需要实现为纯粹的硬件模块(例如专用asic芯片或fpga芯片),还可以实现为结合了软件和硬件的模块(例如存储有固定代码的固件系统)。本发明还提供了一种计算机可读介质,其上存储有计算机可读指令,所述指令被执行时可实施本发明各实施例的方法。本领域普通技术人员可以意识到,以上所述仅为本发明的示例性实施例,并不用于限制本发明。本发明还可以包含各种修改和变化。任何在本发明的精神和范围内作的修改和变化均应包含在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1