一种基于张量分解的多特征融合的4D表情识别方法与流程
本发明涉及一种表情识别方法,具体涉及一种基于张量分解的多特征融合的4d表情识别方法。
背景技术:
随着人工智能和计算机技术的发展和进步,表情识别和人脸识别越来越受到人们的关注。表情识别和人脸识别在生活的中应用也逐渐变的广泛。当前的人脸表情识别方法有很多种,例如:利用深度神经网络提取2d图片的特征或者是视频的特征,进而进行分类。也有利用3d人脸数据表情分类的。实际上,基于2d的人脸表情识别易受光照、场景的影响。基于3d的表情识别能够克服光照和姿态的影响,但是3d的表情识别来说,由于不同的人对表情的表达方式和程度有所不同,使得即使是相同的表情,不同的个体也千差万别。因此对于表情识别这个问题来说,人的身份信息相当于是一个干扰。
技术实现要素:
本发明的目的在于提供一种基于张量分解的多特征融合的4d表情识别方法。
为实现上述目的,本发明采用如下的技术方案:
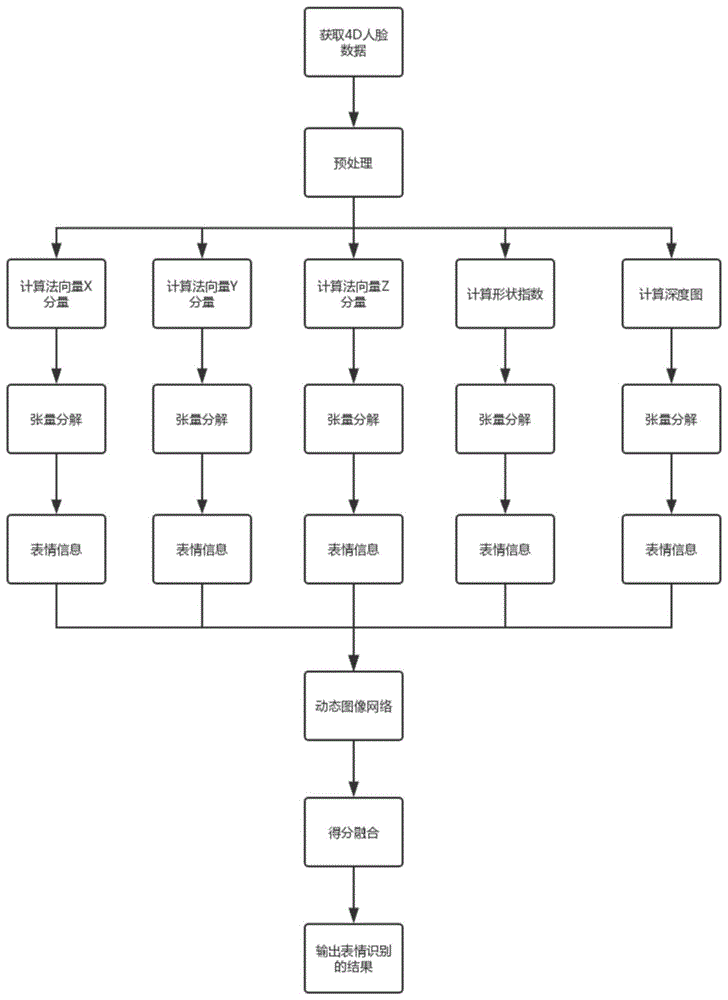
一种基于张量分解的多特征融合的4d表情识别方法,包括以下步骤:
(1)获取人脸4d表情数据;
(2)对人脸4d表情数据进行预处理后计算得到4d人脸数据的法向量三个分量、形状指数和深度图;
(3)对4d人脸数据的法向量三个分量、形状指数和深度图分别进行张量分解,提取出动态的人脸表情信息;
(4)利用动态图像网络对动态的人脸表情信息做分类,对分类的结果进行得分融合,得到最终的分类结果。
本发明进一步的改进在于,步骤(1)中,4d人脸表情数据s={f1,f2,…fl},其中fi表示3d人脸表情数据,i=1…l,l表示4d人脸的帧数。
本发明进一步的改进在于,步骤(2)中,对人脸4d表情数据进行预处理的具体过程为:对人脸4d表情数据进行去噪处理。
本发明进一步的改进在于,步骤(2)中,计算4d人脸数据的法向量三个分量的具体过程如下:
1)首先计算单个的3d人脸的法向量;具体过程如下:对于一个3d人脸数据,首先选取人脸上的一点pj的邻近的5个点,形成一个邻域δ={pi(xi,yi,zi)|i=1,2,…k},k取5,需要拟合的平面为:
ax+by+cz+d=0
满足a2+b2+c2=1;
通过最小二乘法以及拉格朗日乘子法,求解平面拟合问题,得到人脸上的一点pj的法向量,对3d人脸上所有的点进行估计,得到3d人脸的法向量;
2)将3d人脸的法向量分别投影到yz、xz、xy平面,得到一张3d人脸的法向量的x分量图,y分量图和z分量图;
3)最后将4d人脸数据中的每一个3d人脸,进行步骤1)和步骤2),得到相应的法向量分量图,再将4d人脸数据的所有3d人脸计算的相应的法向量x分量图叠在一起,得到4d人脸的法向量x分量图;将4d人脸数据的所有3d人脸计算的相应的法向量y分量图叠在一起,得到4d人脸的法向量y分量图;将4d人脸数据的所有3d人脸计算的相应的法向量z分量图叠在一起,得到4d人脸的法向量z分量图。
本发明进一步的改进在于,求解平面拟合问题的具体过程如下:协方差矩阵∑的最小特征值对应的归一化向量
协方差矩阵∑的形式如下
其中,
本发明进一步的改进在于,计算形状指数图的具体过程如下:
首先计算3d人脸的形状指数图:
对于人脸的某一个点,假设该点及其周围的区域为一个离散的含参曲面
对3d人脸的每一个顶点计算形状指数shapeindex,得到3d人脸的形状指数图;
将4d人脸的每一个3d人脸的形状指数图堆叠起来,得到4d人脸的形状指数图。
本发明进一步的改进在于,计算4d人脸的深度图的具体过程如下:
首先计算3d人脸的深度图,对于一个3d人脸fi上的一个点pj(xj,yj,zj),其对应的深度图的像素值depj的计算公式为:
其中,zmax和zmin表示人脸fi的点的z坐标的最大最小值;
然后将4d人脸的所有3d人脸的深度图堆叠起来,得到4d人脸的深度图。
本发明进一步的改进在于,步骤(3)中,4d人脸数据的深度图进行张量分解的具体过程如下:
1)建立模型;
对于4d人脸的深度图dep∈rh×w×l,其中,h表示深度图的高度,w表示深度图的宽度,l表示4d人脸的序列长度,假设表情信息为emo∈rh×w×l,身份信息为id∈rh×w×l,则建立4d人脸表情-身份信息分离模型:
f=demo
其中,λ表示权重系数,e表示噪声,demo表示对动态的表情信息的建模;
||demo||1=||dhemo||1+||dvemo||1+||dtemo||1
dhemo=vec(emo(i,j+1,k)-emo(i,j,k))
dvemo=vec(emo(i+1,j,k)-emo(i,j,k))
dtemo=vec(emo(i,j,k+1)-emo(i,j,k))(2)
dh表示水平方向的差分算子,dv表示水平方向的差分算子,dt表示时域方向的差分算子;
对静态的人物身份id的建模如下:
其中,
2)模型的求解:
对于建立的4d人脸表情-身份信息分离模型,通过迭代优化来进行求解。
本发明进一步的改进在于,通过迭代优化来进行求解的具体过程如下:
第一步:更新塔克分解的核心张量
其中,λdep为拉格朗日乘子向量,βdep为正惩罚参数,
第二步:更新噪声e;
其中,
第三步:更新动态表情信息emo;
其中,fftn和ifftn分别表示快速3d傅里叶变换和反变换,βdep和βf为正惩罚参数,λf是拉格朗日乘子向量,|·|2是元素的平方操作,d*表示的是d的伴随矩阵;
更新张量f:
其中,λ是权重系数,λf是拉格朗日乘子向量,βf为正惩罚参数,soft为一个函数,定义为:soft(a,τ):=sgn(a)·max(|a|-τ,0);
更新4d人脸表情-身份信息分离模型的拉格朗日乘子向量λf、正惩罚参数βf和βdep,:
其中,
对于第三步提取的动态表情信息emo,送入动态图像网络提取表情运动的信息,进而实现表情的分类。
本发明进一步的改进在于,动态图像网络的底层是深度神经网络,在网络全连接层之前,加入了一层rankpooling层,网络的rankpooling层的计算过程如下:
网络的更新如下:
其中,a(m)表示动态图像网络的第m层的输出,μt表示的是网络要学习的参数,v1,...,vt表示动态图像网络的输出的特征;为方便网络反向传播进行了如下的近似:
其中αt是网络要学习的参数,
与现有技术相比,本发明具有以下有益效果:
(1)利用4d人脸数据来进行表情识别和人脸识别,能够克服2d人脸识别中受光照姿态等因素的影响较大的缺点。使用4d数据,对于不同的场景和环境,在表情识别和人脸识别中都能取得稳定的效果。
(2)充分利用了4d人脸数据的信息,对于序列人脸数据计算了人脸的法向量的三个分量、形状指数和深度图,充分利用了人脸的3d几何信息,对不同的人来说,人脸的特征更具有代表性和判别性,人脸识别和表情识别的准确率也更高。
(3)利用张量分解的方法,将4d人脸数据分解得到动态的表情信息和静态的人脸身份信息。将动态表情信息用于表情识别,除去了人物身份的干扰,使得表情识别的结果更加稳健、准确。
附图说明
图1是本发明的具体流程图。
图2是本发明的4d人脸的法向量三个分量、形状指数和深度图。
图3是本发明的4d人脸的法向量三个分量、形状指数和深度图经过张量分解提取的动态表情信息图。
图4是本发明的本发明的利用动态图像网络对形状指数中提取的动态表情信息进行表情识别的网络结构图。
图5是本发明的本发明的利用动态图像网络对多特征融合表情识别网络结构图。
具体实施方式
下面通过实施例对本发明进行详细说明。
参见图1,本发明包括以下步骤:
(1)获取人脸4d表情数据;
(2)对数据进行预处理,计算出4d人脸数据的法向量三个分量,以及形状指数和深度图,这五个特征深刻反映了各个时刻人脸的几何形状特性;
(3)对4d人脸数据的法向量三个分量,以及形状指数和深度图分别进行张量分解,提取出动态的人脸表情信息和静态身份信息;
(4)利用动态图像网络对动态的人脸表情信息做分类,对分类的结果进行得分融合,得到最终的分类结果。
具体的,参见图1,本发明包括以下步骤:
步骤101:
获取人脸4d表情数据,其中4d表情数据,是指一系列的3d人脸数据视频序列。先用的一些相机如intelrealsensesr300等,能够捕捉到人脸的深度信息,可以借助结构光模型,很容易得到3d人脸表情数据,连续采集3d人脸表情数据即可得到4d人脸数据。
假设4d人脸表情数据为s={f1,f2,…fl},其中fi(i=1…l)表示3d人脸表情数据,l表示4d人脸的帧数。
步骤102:
对4d数据进行预处理,由相机得到的4d人脸数据常常含有噪声和空洞等,需要对4d人脸进行预处理,并进一步计算4d人脸对应的法向量分量、形状指数和深度图。具体来说,
步骤2.1:需要对4d人脸进行去噪处理,一般可以通过双边滤波来实现,对4d人脸数据进行填洞处理,可借助模板脸补洞的方法实现,这些都是对于3d、4d数据的一般处理方法。
步骤103:
计算4d人脸数据的法向量三个分量,以及形状指数和深度图。这一步是从4d人脸中提取出相应的几何特征。如图2所示,给出了从公开的4d表情公开数据库bu4d计算法向量三个分量,以及形状指数和深度图的例子。该例子,共选取了5帧人脸,图像自上而下分别为:深度图,法向量x分量图、法向量y分量图、法向量z分量图、形状指数图。图像从左往右显示了不同时间,同一人脸的同一个表情情况。具体来说,计算4d人脸的法向量三个分量,以及形状指数和深度图包含以下3个步骤。
(1)计算4d人脸的法向量分量:
1)首先计算单个的3d人脸的法向量,对于一个3d人脸数据,例如点云,估计某一个点处的法向量是通过某一个点及其周围若干个点来平面拟合的方法得到的,一般来说,是利用一点和其最近邻的5个点来拟合平面得到。例如:人脸上的一点pj的法向量,首先选取pj的邻近的5个点,形成一个邻域δ={pi(xi,yi,zi)|i=1,2,…k},这里k取5需要拟合的平面为:
ax+by+cz+d=0
满足a2+b2+c2=1;
通过最小二乘法以及拉格朗日乘子法,求解上述平面拟合问题,最终得到人脸上的一点pj的法向量,具体求解上述平面拟合问题的具体过程为:协方差矩阵∑的最小特征值对应的归一化向量
协方差矩阵∑的形式如下:
其中
对3d人脸上所有的点进行估计,得到3d人脸的法向量;
2)接下来,计算法向量的三个分量,具体来说,得到了某一个3d人脸的法向量之后,将法向量分别投影到yz、xz、xy平面,依次得到了一张3d人脸的法向量的x分量图,y分量图和z分量图。
3)最后将4d人脸数据中的每一个3d人脸,进行步骤1)和步骤2),得到相应的法向量分量图,再将4d人脸数据的所有3d人脸计算的相应的法向量x分量图叠在一起,得到4d人脸的法向量x分量图,将4d人脸数据的所有3d人脸计算的相应的法向量y分量图叠在一起,得到4d人脸的法向量y分量图,将4d人脸数据的所有3d人脸计算的相应的法向量z分量图叠在一起,得到4d人脸的法向量z分量图。实际上得到的4d法向量分量图就是一个法向量分量的视频。
(2)计算4d人脸的形状指数图,4d人脸的形状指数衡量的是人脸两个曲面的两个主曲率的归一化的结果过,可以看作是一种二阶微分的性质,具体来说,计算4d人脸的形状指数图的步骤如下:首先计算3d人脸的形状指数图:
对于人脸的某一个点,假设该点及其周围的区域为一个离散的含参曲面
便得到了该顶点处的形状指数。对3d人脸的每一个顶点计算形状指数shapeindex,得到3d人脸的形状指数图;
将4d人脸的每一个3d人脸的形状指数图堆叠起来,得到4d人脸的形状指数图。
(3)计算4d人脸的深度图,深度图的每一个像素的灰度值体现了人脸的每一点,到相机的距离,反应人脸的几何形状。计算4d人脸的深度图步骤如下:
首先计算3d人脸的深度图,对于一个3d人脸fi上的一个点pj(xj,yj,zj)来说,其对应的深度图的像素值depj的计算公式为:
其中zmax和zmin表示人脸fi的点的z坐标的最大最小值。
然后将4d人脸的所有3d人脸的深度图堆叠起来,就得到4d人脸的深度图。
步骤104:
对步骤103所得的法向量分量、形状指数和深度图分别进行张量分解,得到静态的人物身份信息和动态的表情变化信息。具体来说,以深度图为例,法向量的分量以及形状指数的张量分解的流程类似可得。
(1)建立模型,对于4d人脸的深度图dep∈rh×w×l,其中h表示深度图的高度,w表示深度图的宽度,l表示4d人脸的序列长度。考虑到对于一个3d人脸序列来说,动态的部分是表情,静态的部分是身份信息,表情和身份可以认为是分布独立的,可将二者分开。假设表情信息为emo∈rh×w×l,身份信息为id∈rh×w×l,那么可以建立以下4d人脸表情-身份信息分离模型:
f=demo
其中,λ表示权重系数,衡量了f和e之间的比重,e表示噪声,demo表示对动态的表情信息的建模:
||demo||1=||dhemo||1+||dvemo||1+||dtemo||1
dhemo=vec(emo(i,j+1,k)-emo(i,j,k))
dvemo=vec(emo(i+1,j,k)-emo(i,j,k))
dtemo=vec(emo(i,j,k+1)-emo(i,j,k))(2)
dh表示水平方向的差分算子,dv表示水平方向的差分算子,dt表示时域方向的差分算子。
公式(2)刻画了人脸表情的动态变换信息。对静态的人物身份id的建模如下
公式(3)其实是对4d人脸的身份信息的塔克分解,
(2)模型的求解,对于公式(1)建立的4d人脸表情-身份信息分离模型,需要通过迭代优化来进行求解。对于这种多变量的优化问题,通常使用交替方向乘子法(admm)来进行迭代优化。首先对参数进行初始化,具体的迭代更新的步骤如下:
第一步:更新塔克分解的核心张量
其中,λdep是拉格朗日乘子向量,βdep为正惩罚参数,
第二步:更新噪声e:
其中
第三步:更新动态表情信息emo;
其中,fftn和ifftn分别表示快速3d傅里叶变换和反变换,βdep和βf为正惩罚参数,λf是拉格朗日乘子向量,|·|2是元素的平方操作,d*表示的是d的伴随矩阵,dh,dv,dt分别表示竖直、水平和时域方向的差分算子,f定义为:f=demo;
其中,d*表示的是d的伴随矩阵。
更新张量f:
其中,λ是权重系数,λf是拉格朗日乘子向量,βf为正惩罚参数,soft为一个函数,其定义为:soft(a,τ):=sgn(a)·max(|a|-τ,0)
更新4d人脸表情-身份信息分离模型的拉格朗日乘子向量λf,λf和正惩罚参数βf和βdep,:
其中,
如图3所示,显示了4d人脸的法向量三个分量,以及形状指数和深度图经过张量分解之后提取的动态表情图。图像自上而下表示深度图、图像自上而下分别为:深度图,法向量x分量图、法向量y分量图、法向量z分量图、形状指数图,从左往右显示了不同时间,同一人脸的同一个表情经过张量分解提取的动态表情信息图。
步骤105:
对于步骤三提取的动态表情信息emo,可以送入动态图像网络提取表情运动的信息,进而可以实现表情的分类。一般的表情可以分为六类:开心,生气,悲伤,惊讶,厌恶,害怕。动态图像网络是一种提取运动图像的网络。网络的底层是一般的深度神经网络如:vggnet16网络,在网络全连接层之前,加入了一层rankpooling层。其中rankpooling层的作用是将一个视屏序列特征,变成一张图。这一张图片蕴含了个视频序列里每一帧的动态特征。如图4所示,为动态图像网络的网络结构图,网络的rankpooling层的其计算流程如下:
网络的更新如下:
其中,a(m)表示动态图像网络的第m层的输出,μt表示的是网络要学习的参数,v1,...,vt表示动态图像网络的输出的特征。为方便网络反向传播进行了如下的近似:
其中αt是网络要学习的参数,
步骤106:
将步骤4得到的不同的特征数据的结果,进行得分融合,最终得到模型的表情识别的结果,并输出表情识别的结果。图5示出了,运用动态图像网络对法向量分量、形状指数和深度图中提取的动态表情信息进行多特征融合表情识别网络结构图。
本发明是基于张量分解的4d人脸数据的几何特征图像,如:法向量三个分量、形状指数和深度图。将4d人脸数据的几何特征图像的动态表情信息和静态人物身份信息分开,分别利用提取的4d人脸数据的动态表情信息进行表情识别,并对不同的几何特征图的表情识别结果进行得分融合,得到最终的表情识别的结果,这样既减少了人物身份信息的干扰,又运用了多个4d人脸几何特征,使得最终表情识别的结果更加稳健、有效。
- 还没有人留言评论。精彩留言会获得点赞!