一种基于卷积神经网络的多尺度轻量化道路路面检测方法与流程
本发明属于图像识别领域,涉及一种基于卷积神经网络的多尺度轻量化道路路面检测模型。本发明应用于路面检测的智能化,以制定出合理且高效的养护管理决策。
背景技术:
近些年,我国公路总里程增速明显放缓,这标志着我国公路行业从大建设周期迈向大养护时代,而路面破损检测是其中的重点。随着近些年人工智能技术的兴起,在某些图像分类领域中,一些基于卷积神经网络的分类准确度已经达到甚至超越人类的识别精度。
目前,考虑实际路面破损图像受曝光度和阴影等因素影响的cracktree网络,能够对水泥路面破损图像进行自动化的裂缝识别。其对于非连续的裂缝有很强的识别能力,但是没有考虑到实际裂缝的宽度问题。
一种cnn-cdm卷积神经网络结构,可以对沥青路面破损图像进行识别分类,能够自动化的对每张输入图像进行有无裂缝的判断输出。但是该方法会出现将坑槽误认为裂缝的错误。
经典的深度卷积神经网络alexnet、vgg等路面检测技术,其神经网络连接模式过于冗余而低效,模型复杂,参数量大,运行速度慢,计算需求高。
在实际应用中,基于不同检测车所采集的路面站点图像往往具有不同的尺寸,和由于外部环境变化导致的光影变化大等问题。故,本文提出一种能够解决以上问题的,能够根据图像尺度变化自适应结构调整的轻量化卷积神经网络mobilecrack。
技术实现要素:
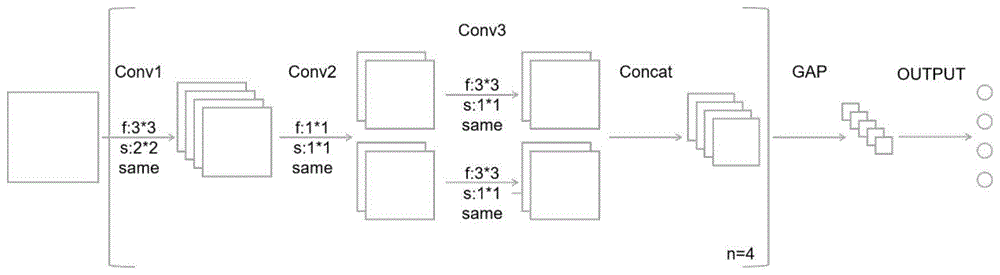
一种基于卷积神经网络的多尺度轻量化道路路面检测模型,具体内容如下:本发明基于vgg和xception的设计思路,设计了一种全新的cnn结构,mobilecrack,适用于路面裂缝的识别。主要结构为堆叠的coremodule和全局平均池化层,如图1所示。
本发明公开了一种基于卷积神经网络的多尺度轻量化道路路面检测方法,第一步图像采集,使用人工方法对原始破损路面进行采集,采集格式为统一像素三通道灰度图像。
第二步批量裁剪,为了使路面图像数据集满足深度学习要求,将所得路面原始图片数据集进行裁剪,使路面图片尺寸缩小至一定规模,既能够不破坏路面裂缝等分类特征,又尽可能的降低图像尺寸过大带来的难以训练问题。首先,通过双线性插值进行横向缩放至较小的统一像素。然后,对其进行连续剪裁,每张路面图像剪裁得到50张更小像素的子图像。
第三步人工标定,在本发明中,路面图像数据集的规模和分类特征的一致性会对网络预测精度造成很大影响。因此使用人工标定法,用labelimg对上一步得到的路面图片集进行标定,共分为background、crack、sealedcrack、roadmark四类。
第四步数据增强,由于深度学习时,训练集的数量越多越有利于学习,因此,将本发明的路面图片集的每一张图片进行适当的处理步骤来扩大图片集。具体方法为镜像和旋转。镜像,将每一张分割的路面图像经过镜像对称,扩大一倍路面图集,最后经过不同角度的旋转,再次扩大数倍路面图集。
第五步数据集制作,把路面图片集按照训练集、验证集和测试集比例为10:1:1进行划分。
第六步基于卷积神经网络模型建立,建立一种新型的cnn构架——mobilecrack。
主要结构coremodule为1个尺寸3*3,步长2的标准卷积层,后接一层1*1卷积。将输出的路面特征图按通道分为两部分,进行卷积核尺寸为3*3,步长1的标准卷积,即分组卷积。concatlayer将两组输出在通道维度上进行合并,此为coremodule的输出。所有的卷积层的填充方式均采用same模式。同时,在每个卷积层和激活函数间,添加bn层,保证层间数据的稳定性,同时加速训练效率。在单个coremodule中,通道数不发生改变,即,cs=cp=2*cg=cc。其中,cs,cp,cc为标准卷积层、1*1卷积层,和concat层输出的通道数,cg为分组卷积层中每个group的输出通道数。
在coremodule的堆叠时,后一个coremodule的第一层标准卷积核数量取决于前一层最后concat层的输出通道个数,是其2倍。mobilecrack中的所有卷积计算,均通过coremodule中的3类卷积层完成。降采样工作,均由coremodule中的标准卷积层完成,由于普通池化层(poolinglayer)对于数据空间尺寸的缩小速度过快,故不使用池化层。由于全连接层(fullyconnectedlayer)会将图像的空间特征破坏,且其全连接特性导致参数量巨大,故mobilecrack不采用全连接层。用全局平均池化层代替,其不仅能够大幅度减少参数数量,同时能够使网络具有多尺度的输入特性。全局平均池化,是将每张路面图片特征图均值池化为一个点数据,其输出的向量尺寸只与输入向量的通道数有关。mobilecrack的结构参数如表1所示:
表1mobilecrack各层的结构和参数
mobilecrack的损失函数采用交叉熵函数(categoricalcrossentropy)。优化器采用adam,β_1=0.9,β_2=0.999,ε=10-8。在训练时,mini-batch尺寸设置为128,学习率设置为0.001,decay设置为,将学习率每10个epoch下调一个数量级。
第七步训练与测试,将处理好的路面数据训练集输入到搭建的神经网络中进行训练,稍后进行测试,并且做准确度、灵敏度分析。
附图说明
图1mobilecrack结构图。图中:f为卷积核尺寸,s为卷积核移动步长,same为一种填充模式,n为堆叠的coremodule个数。
图2批量剪裁示意图。
图3图像集中4种分类图片:(a)路面背景(b)路面背景(c)未修补裂缝(d)已修补裂缝。
图4图像增强,(a)图像垂直翻转,(b)(c)(d)图像旋转90°,180°,270°。
图5固定n值下不同输入尺寸对应的mobilecrack(a)训练集损失(b)训练集准确度(c)验证集损失(d)验证集准确度。
图6固定输入尺寸下不同n值对应的mobilecrack(a)训练集损失(b)训练集精确度(c)验证集损失(d)验证集精确度。
图7固定输出特征图尺寸下不同n值对应的mobilecrack(a)训练集损失(b)训练集准确度(c)验证集损失(d)验证集准确度。
图8不同参数下mobilecrack的表现图。
图9不进行正则化的mobilecrack计算结果。
图10不同keep-prob下(a)训练集损失(b)训练集准确度(c)验证集损失(d)验证集准确度。
图11不同dropoutkeep-prob值对应的mobilecrack表现。
图12不同cnn与mobilecrack的表现对比图。
具体实施方式
本发明所采用的原始路面破损图像数据集共有6,380张4,096*2,000像素的三通道灰度图像。为使数据集满足深度学习要求,对原始图像做如下数据预处理步骤:
(1)批量剪裁
批量剪裁的目的是将4,096*2,000像素的原始图片进行剪裁,使图片尺寸缩小至一定规模,既不破坏路面裂缝等分类特征,又尽可能的降低图像尺寸过大带来的难以训练问题。本文针对每张4,096*2,000像素的原始图像:
首先,通过双线性插值进行横向缩放至4,000*2,000像素。
然后,对其进行连续剪裁,每张4,000*2,000像素的图像剪裁得到50张400*400像素的子图像,如图2所示。
(2)人工标记
人工标记的目的在于对数据集进行分类,以进行监督学习。在监督学习中,数据集的规模和分类特征的一致性会对网络预测精度造成很大影响。所以在此步骤中,本发明对每张400*400像素的子图片进行分类和筛选,共得到1,308张路面背景图像,519张未修补裂缝图像,412张已修补裂缝图像和406张路面标线图像,如表2所示。图3展示了4种分类的典型图片。
表2数据集构成
(3)数据增强(dataaugmentation)
数据增强的目的在于将数据集的规模扩大,丰富数据及图像的多样性。本发明通过两种手段进行数据增强,镜像和旋转。
首先,将每张图片进行垂直镜像,如图4(a)所示。
然后,对三张图像分别进行旋转90°,180°和270°变换,如图4(b)(c)(d)所示。故图像集经过图像增强后,相当于将原图像集的规模增至8倍。所以,得到最终的数据集构成为路面背景10,464张,未修补裂缝4,152张,已修补裂缝3,296张和路面标线3,248张,如表2所示。
(4)数据集制作
为满足监督学习的需要,将经过数据增强后的数据集共计21,160张图像,按照训练集、验证集和测试集比例为10:1:1进行划分。但是考虑到无损路面和其他三种分类的图像数量差距过大,为保证在学习时每种分类的训练集数据数量相近,每种分类筛选2,500张作为训练集。得到训练集10,000张,验证集图像1,000张和测试集图像1,000张,如表2所示。
对于mobilecrack的多尺度输入特性,为降低网络模型的计算量,同时能够保证裂缝识别的精度衰减程度较低,对输入图像的尺寸做灵敏度分析。即,不同尺度的相同图像输入,对网络识别精度的影响。同时,最重要的一个超参数n,即coremodule的堆叠数量。其与多尺度的输入向量和输出的特征图尺寸挂钩:
其中sizeinput为第一个coremodule的输入特征图的尺寸,sizeoutput为第n个coremodule的输出特征图的尺寸。
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野(receptivefield)。感受野中的每一个像素值并不是同等重要。一个像素点越接近感受野中心,对输出特征的计算所起作用越大。这意味着某一个特征不仅仅是受限在输入图片中某个特定的区域(感受野),并且呈指数级聚焦在区域的中心。感受野计算公式:
r1=1(2)
r2=f2(3)
式中,rk是第k层神经元的感受野,fk第k层的卷积核尺寸,而si是相应的第i层的卷积步长。.
首先,固定n的大小,即保证mobilecrack的高层神经元的感受野的一致性。以原始图像400*400,调节size_input为50,100,200。相应的,通过双线性插值调节数据集中图像的尺寸。图5展示了对应的mobilecrack在训练过程中的损失和准确度。分别对应的识别精度如表3所示。可以看出,随着sizeinput的减小,准确度会逐渐降低,但是计算所需要耗费的时间会呈指数级下降。在图像输入尺寸为50*50时,每张图片的检测只需要2毫秒。
表3固定n值下不同输入尺寸对应的mobilecrack表现
注:运行时间为mobilecrack对单张图像进行预测所需要的时间
然后,固定sizeinput=100,调整n为3,4,5。由于coremodule的特性,当n>=6,其coremodule组的sizeoutput将<=2*2,其信息量过小,无法保留充分的空间特征。故,只设置n为3,4,5。图6展示了对应的mobilecrack在训练过程中的损失和准确度。其结果如表4所示。三种形态的mobilecrack的运行时间基本相当,除去n=3时mobilecrack的准确度精度较低,网络足够深后(n>=4),其表现基本在同等水平下。故,在网络的结构复杂性和图像sizeinput两者间,存在一个结构复杂度的阈值,当其超过阈值时,决定模型表现的是输入图像自身所携带的信息的复杂度;反之,则由结构复杂度决定。
表4固定输入尺寸下不同n值对应的mobilecrack表现
表5显示了每层神经元感受野的大小。与表4相比,输入大小为100的预测精度相对较高,因为对于n=4,mobilecrack最高层神经元的感受野为91*91,如表5所示,最接近sizeinput=100的感受野。其几乎覆盖了输入图像的所有像素,同时保证了不存在冗余计算。
将sizeoutput固定不变,如表6所示,调节sizeinput为50,100,200,即固定全局平均池化层的参数,都是将尺寸为7*7的特征图全局平均池化为单个信息点。不同的是全局平均池化层的维度有所变化,输入尺寸较大的图像所蕴含的特征较复杂,需要更多的特征图进行特征提取。图7展示了对应的mobilecrack在训练过程中的损失和准确度。mobilecrack的准确度随着sizeinput的增加而提升,但是运行时间也会成倍增加。
表5各层神经元的感受野大小
表6固定输出尺寸下不同输入尺寸对应的mobilecrack表现
图8显示了不同超参数的计算结果。结果表明,模型越复杂,预测精度越高,但计算速度越慢。输入图像越小,计算速度越快,但会丢失一定的精度。同时,尺寸为400*400的原始图像的预测不仅准确度较低,且计算时间很长。而对其进行缩小后,不仅由于模型结构的简化,能够大幅度减少参数量,降低存储空间需求,加速计算,对移动端部署更加亲和;同时还能有效提高计算精度。图8中的趋势线是缩小input_size的mobilecrack变体的表现拟合趋势线。例如,输入100*100的图像,mobilecrack会自动的在inputsize<=100的变体中,寻找最优模型完成预测,即准确度最高的模型。如图8所示,即input_size=100,n=4的mobilecrack。
根据图9可以看出训练和测试的损失随着迭代次数的增加而趋近于零,即在不使用其他正则化方法时,mobilecrack仍然存在一定的对训练集过拟合现象,训练及准确率与验证集准确率有较大的差距。为此,设计dropoutkeep-prob灵敏度分析实验。
将keep-prob分别设置为0,0.1,0.2,0.3,0.4,0.5。由于coremodule中标准卷积层除了负责卷积计算,还承担降采样工作;1*1卷积层中每个卷积核对于传入的特征图的感受野只有1*1,无重叠,其若添加dropout层会丢失一些独立的像素元信息;而分组卷积层的卷积核尺寸3*3,步长1*1,其每个卷积核的感受野有所重叠,故在分组卷积层添加dropout层。
图10展示了对比试验的损失和准确度曲线。实验结果如表7所示,发现dropout层不影响模型运行速度,能够小幅度提升mobilecrack的准确度,当设置keep-prob=0.1时,准确度能够提升0.1%,但是训练更难,需要增加至少20个epoch,才能使mobilecrack达到最优。而当继续提升keep-prob时,mobilecrack的精度会越来越低。故,对于轻量化的模型mobilecrack,其过拟合现象无法通过添加dropout层,进行有效正则化。其原因是,轻量化的cnn由于参数量较少,其对于复杂特征的学习能力没有更大的网络的能力强,故其会面临欠拟合状态(underfitting),而非过拟合(overfitting)。图11展示了不同dropoutkeep-prob值对应的mobilecrack表现。
表7不同dropoutkeep-prob值对应的mobilecrack表现
表8对比了mobilecrack与经典模型alexnet、vgg、轻量化模型mobilenet。mobilecrack在现有计算资源下,能够达到更高的分类精度,同时其参数量仅为alexnet的1/33,vgg16的1/58,mobilenet的近1/4。且mobilecrack的模型存储空间只需要10mb,而轻量化模型mobilenet需要37mb。图12展示了不同cnn与mobilecrack的表现对比。
表8不同cnn与mobilecrack的表现对比
注:所有的模型均采用sizeinput=100,其中由于cpu计算速度的限制,vgg16较难训练,故采用imagenet预训练的前几层权重,只对全连接层进行训练。而alexnet和mobilenet均采用参数随机初始化方式在本研究数据集上进行训练。各个模型通过keras命令keras.model.save存储为h5格式。
本方法提出轻量化cnn模型mobilecrack用于多尺度的道路路面检测任务。mobilecrack的最重要的超参数之一n,能够根据图像尺度变化调节网络结构,提升其对于多尺度图像的适应性和分类精度。且为mobilecrack的结构提供了相当的灵活度,能够自由地在准确度、运行时间和储存大小三者间进行权衡。
(1)在mobilecrack结构不变情况下,图像输入尺寸越高准确度越高,但运行时间成倍增长。性价比最高的是输入尺寸为100*100像素的路面破损图像。
(2)在固定输入尺寸为100*100像素时,改变coremodule的数量。当模型足够复杂,其准确度基本保持不变,由输入图像尺寸决定其上限;反之,准确度随模型的复杂度同向变化。
(3)在保证gap层参数不变时,图像输入尺寸为200*200表现最好,其准确度能够达到95.1%。
在输入尺寸相同情况下,轻量化的mobilecrack具有比经典cnn模型alexnet、vgg和mobilenet更加优秀的表现,更高的准确度,更少的参数量,和更低的存储空间以及计算要求。
- 还没有人留言评论。精彩留言会获得点赞!