基于实体序列编码的知识图谱融合方法与流程
本发明涉及知识图谱应用技术领域,尤其涉及一种基于实体序列编码的知识图谱融合方法。
背景技术:
目前国内外的知名互联网企业,例如谷歌、百度、腾讯、微软都搭建了属于自己的知识库,这些知识库提供了大量的知识服务信息,例如谷歌的知识库系统knowledgevault已经入库16亿条信息,目前还在收集入录更多的信息。百度的知识图谱的应用服务在5年间增长了160倍。这些企业使用知识图谱可以提供的更多语义信息,提供更加智能化的搜索服务,为互联网用户提供了便携的服务。
这些知识图谱包含了大量常识信息,融合这些跨语言的知识库可以提供更多的知识,为互联网用户提供更智能化的信息检索帮助服务。但是知识库体系庞大,内容众多,语言不一致,如何高效融合这些知识库成为一个重点挑战问题。融合知识图谱的首要工作是找出两个只是空间可对齐的知识实体,例如将英文知识库中newyork和中文知识库中的纽约对齐为一个实体。传统的方法可以使用机器词翻译的方式,将多语言实体的词进行翻译,但是存在着一词多义的情况,例如朝阳这个词可能指的是辽宁的朝阳,也可能是北京的朝阳。使用深度学习的方法学习节点向量,标注已知的对齐实体对,训练对齐模型进行对齐,是目前研究的热点工作,这个方法根据实体的语义信息和实体之间的关系语义进行对齐操作,提高了模型的准确率,但是这类模型存在问题,标注训练语料需要耗费大量人力。
而且,由于深度学习模型在实体对齐任务中的良好表现,但是缺少训练语料的问题,如果训练语料不充分,无法学习出准确高效的对齐模型。
技术实现要素:
为解决上述技术问题,本发明提供了一种基于实体序列编码的知识图谱融合方法学习方法。
基于实体序列编码的知识图谱融合方法,包括:
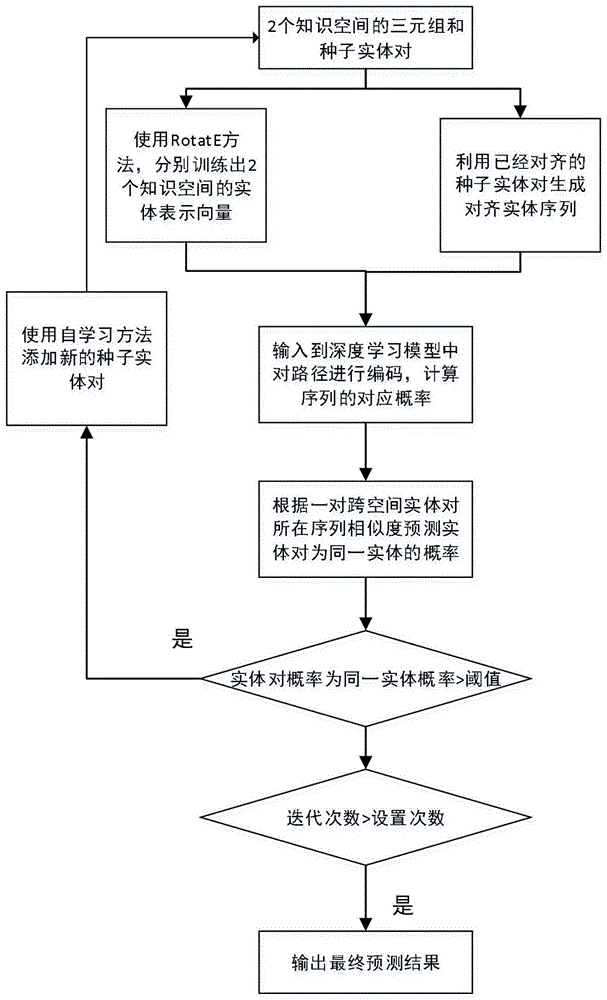
步骤一:知识图谱实体表示学习;
步骤二:选择路径编码和对齐模型;
步骤三:跨语言实体对齐模型,其中,在源语言知识图谱空间中,针对其中的一个实体,构建与其他种子实体的2跳序列,在目标语言知识图谱空间中构建可能与之对应的序列,找出概率最高的对齐序列,然后从对齐序列中找到同位置的节点,作为该节点的对齐节点;
步骤四:添加新的候选种子节点。
进一步,所述步骤一中,使用rotate模型分别学习源语言知识图谱空间和目标语言知识图谱空间中的实体表示向量和关系表示向量,所述rotate模型通过三种关系:对称、反转、构成,来训练所述实体表示向量和所述关系表示向量,得到三元组集合和种子实体对。
进一步,所述步骤二中,包括构建训练实体序列、对实体序列进行编码;对于任意一对跨语言对齐种子实体,在所述源语言知识图谱空间中选择2跳路径,所述2跳路径上的点都是对齐的种子实体,构建长度为5的节点序列,在所述目标语言知识图谱空间中构建同样长度为5的节点序列,两个空间中2跳实体序列上的点是一一对应的;训练时,对所述节点序列上的节点和关系的表示向量进行拼接和卷积操作学习出2个实体序列的表示,并设计公式计算两个实体序列是否是同一实体序列的概率。
进一步,所述计算两个实体序列是否是同一实体序列的概率的公式为:
p(vt|vs)=exp(-η||vt-θvs||2)。
进一步,所述步骤四中,待步骤三得到所述节点后,如果与旧的训练语料没有冲突,生成新的实体表示路径,作为新的训练语料训练对齐模型。
本发明一种基于实体序列编码的知识图谱融合方法,针对现有技术中深度学习模型训练语料不足的问题,提出了基于实体路径表示学习的方法,训练模型的输入是已知对齐种子实体之间的2跳路径,在对齐种子实体较少的情况下可以得到较多的路径训练数据,在较少标注训练语料下学习出对齐模型。
本发明需要的标注训练语料少,只需要标注较少训练实体对,就可以学习训练模型,降低了标注人力成本;相比于简单的机器翻译模型,本发明引入实体节点与其他节点之间的关系,模型输入是实体节点之间的2跳路径,使得输入训练模型中的语义信息更丰富,避免了传统机器翻译的一词多义的混淆问题;模型在得到新的可对齐节点后,利用自学习的方法,本发明将新的可对齐节点的路径加入训练数据中对模型进行新一轮训练,提高模型训练的准确率,因此使用更少的训练语料,得到更高的准确率。
附图说明
图1为本发明实施例的流程示意图;
图2为本发明构建训练语料的流程图;
图3为本发明的深度学习模型的流程图;
图4为本发明实施例中负采样的流程图。
具体实施方式
为了能够更加详尽地了解本发明实施例的特点与技术内容,下面结合附图对本发明实施例的实现进行详细阐述,所附附图仅供参考说明之用,并非用来限定本发明实施例。
为清楚地说明本发明的设计思想,下面结合实施例对本发明进行说明。
图1为本发明实施例一种基于实体序列编码的知识图谱融合方法的流程示意图,如图1所示,所述基于实体序列编码的知识图谱融合方法包括以下步骤:
步骤一:知识图谱实体表示学习;
步骤二:选择路径编码和对齐模型;
步骤三:跨语言实体对齐模型,其中,在源语言知识图谱空间中,针对其中的一个实体,构建与其他种子实体的2跳序列,在目标语言知识图谱空间中构建可能与之对应的序列,找出概率最高的对齐序列,然后从对齐序列中找到同位置的节点,作为该节点的对齐节点;
步骤四:添加新的候选种子节点。
上述示例中,本发明的知识库的表示为g=(e,r,s),其中e={e1,e2…,en}是知识库的实体集合,其中包含|e|种不同实体;r={r1,r2,…,r|r|}是知识库中的关系集合,包含|r|种不同关系,而s∈e×r×e则表示知识库中的三元组集合,一般表示为(h,r,t),其中h和t表示头实体和尾实体,而r表示h和t之间的关系。
我们使用rotate模型来训练实体与关系向量,rotate主要利用3种主要的关系:对称,反转,构成
对称:对于
r(x,y)→r(y,x)
反转:对于
r2(x,y)→r1(x,y)
构成:对于
r2(x,y)+r3(y,z)→r1(x,z)
rotate首先将头实体h和尾实体t映射到一个高维空间rk,之后在rk上定义关系r将头实体h逐元素旋转到尾实体t,具体公式为:
t=h°r,where|ri|=1,
这里°表示为哈达玛积,并且需要对每个ri∈ck进行模长约束,如公式中,将模长约束为1.
因此,对于每个三元组(h,r,t),rotate的距离为:
dr(h,t)=||h°r-t||
通过网络训练使得dr(h,t)最小,此时的三元组(h,r,t)向量为训练所得的实体与关系的特征向量。
根据已经标注的对齐种子实体,构建一对可对齐对齐序列,输入到深度学习模型中,得出2条路径编码向量表示。
针对一对的种子节点实体<es,e’s>,如果在源语言知识图谱空间中存在一个实体之间序列路径{es,r1,ec,r2,ee},其中r1和r2是关系,ec和ee是源语言知识图谱空间中的实体。在目标语言知识图谱空间中存在一个对应的实体之间序列{e's,r’1,e'c,r’2,e'e},其中ec和e'c是对齐的种子节点,其中ee和e'e是对齐的种子节点。那么这对实体序列就是本发明模型的训练语料。
如图2所示,图2为构建训练语料的流程图。
得到实体序列后,需要对实体序列{es,r1,ec,r2,ee}进行编码,编码采用卷积方式,将实体和关系的表示向量拼接起来,输入到卷积网络中,再输入到全连接层中得到序列的编码表示。序列编码表示的深度学习模型如图3所示,图3为本实施例的深度学习模型的流程图。
对于一对跨语言空间实体序列是否是同一个序列的概率计算公式
p(vt|vs)=exp(-η||vt-θvs||2)
其中η和θ都是模型中的参数。
如果是1的话,代表是同一个序列,0代表是不同的序列。
训练时,引入负采样操作,加快模型训练和提高模型准确率。
负采样的过程如图4所示。
在训练出对齐模型后,使用对齐模型找出新的对齐实体对。对于源语言知识图谱空间中的一个实体es,要找到目标语言知识图谱空间中的节点的步骤如下:
构建与其他种子实体的2跳序列集合,对于集合中每个序列{e1,r1,e2,r2,e3},其中es是{e1,e2,e3}集合中任意一个实体。
如果在目标语言知识图谱空间中存在序列{e'1,r’1,e'2,r’2,e'3},要求源语言知识图谱空间序列除了es,剩下的2个实体都是跟目标语言知识图谱空间序列中的同一位置的实体是一一对齐的,目标语言知识图谱空间序列剩下的实体e’s作为es可能对齐的实体。那么可以根据5.3训练出的深度模型计算2个序列为同一个实体序列的概率作为<es,e’s>实体对是同一个实体的概率。
根据es所在多个实体序列计算出e’s候选集合,选出计算p(<es,e’s>)概率最大的实体作为对齐实体。
训练模型,使用模型预测新的对齐实体,利用自学习方法,添加新的对齐种子实体对。
如果该对种子实体对的概率大于阈值且与原有的种子实体对集没有发生冲突,那么原有的种子实体对集合加入该对新的实体对,添加新的训练标注数据,对模型进行新一轮训练。
如果添加的过程中,预测新实体对和现有的训练数据产生冲突,在当前训练数据中存在一个种子实体对<es,e’s>,当前预测出新的实体对<es,e”s>,如果<es,e’s>是最原始的标注数据,那么舍弃新的预测实体对。否则就计算p(<es,e's>)和p(<es,e”s>),选择概率值大的种子实体对。对模型进行新一轮训练。
自学习迭代次数超过设定的次数上限,在本实施例中自学习迭代次数上限为50,停止迭代,训练对齐模型输出最终的跨语言实体对齐结果。
本发明一种基于实体序列编码的知识图谱融合方法,针对现有技术中深度学习模型训练语料不足的问题,提出了基于实体路径表示学习的方法,训练模型的输入是已知对齐种子实体之间的2跳路径,在对齐种子实体较少的情况下可以得到较多的路径训练数据,在较少标注训练语料下学习出对齐模型。
本发明需要的标注训练语料少,只需要标注较少训练实体对,就可以学习训练模型,降低了标注人力成本;相比于简单的机器翻译模型,本发明引入实体节点与其他节点之间的关系,模型输入是实体节点之间的2跳路径,使得输入训练模型中的语义信息更丰富,避免了传统机器翻译的一词多义的混淆问题;模型在得到新的可对齐节点后,利用自学习的方法,本发明将新的可对齐节点的路径加入训练数据中对模型进行新一轮训练,提高模型训练的准确率,因此使用更少的训练语料,得到更高的准确率。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!