一种webshell检测方法、终端设备及存储介质与流程
本发明涉及计算机网络安全技术领域,具体地涉及一种基于命令序列及主动学习算法的webshell检测方法、终端设备及存储介质。
背景技术:
伴随着web技术的提高和锁承载信息的爆炸性增长,web从最初的简单静态内容的展示演变到提供丰富动态内容的交互式应用,从单一服务器拓展到大规模集群。今年来,csdn密码泄漏门,apachestruts2漏洞,棱镜门等一系列网络安全时间进入人们的视野,这其中绝大部分都与web网站安全息息相关。根据cncert每年发布的年度安全报告,与web网站相关的入侵行为呈逐年上升趋势。在所有的安全威胁中,尤其以网站后门为甚。
网站后门又被称为webshell,是一种基于web服务的后门程序。webshell危害巨大,如果发现网站已经被植入webshell后,则意味着攻击者已经利用漏洞掌握了服务器的控制权限。因此检测webshell对于及时掌握网络安全态势具有及其重要的意义。
尽管攻击手段变化无穷,但它们的目的往往是一致的,即窃取,破坏目标数据。而盗取,破坏目标数据的基础之一即是在web系统中安插后门代码,从而建立持久化访问以达到攻击的目的,这种后门代码,就是webshell,这是攻击者为在web服务器上执行命令而设计的一类木马程序。
常见的webshell检测方法主要有静态检测方法和动态检测方法两类,相较于动态检测方法,静态检测方法以其占用资源少,检测周期短,效率高的优点,获得了更为广泛的应用,但是传统的基于正则匹配的静态检测方法,不能有效识别混淆后的webshell脚本,也不能有效识别从未出现过的webshell脚本,新兴的使用机器学习算法的静态检测方法又有着特征普适性差的缺点。
近年来,webshell数量依然呈上升的趋势,尤其是新型webshelll,其数量始终呈逐年递增状态,这对网络空间安全造成了极大的威胁。随着技术的不断发展,机器学习能够自动发掘webshell的内在规律并不断完善自身的性能,进而实现对未知webshell的检测。因此,相比于传统的基于特征码、hash值等的检测技术,采用基于机器学习的方法对webshell进行建模和检测时具有更高的检测率,其已成为websehll检测领域的研究热点。在机器学习的训练阶段,往往需要大量的、完备的websehll样本集才能达到理想的检测效果。然而在现实网络环境中,一方面,webshell样本,特别是新型webshell样本,数量较少,难以形成完备的训练集,从而影响了webshell的检测效果;另一方面,对webshell进行分析和标注也需要大量的人力和物力,从而影响了webshelll的检测效率。因此,如何在小规模webshell样本的情况下实现较为理想的检测效果和效率,是webshell检测领域研究的重点和难点。现实情况中,在新型webshell出现之初,被标记的webshell数量较少,难以训练泛化能力较强的检测模型,若采用人工的方式对未知的webshell样本进行标记,则需要大量的人力和物力。为解决该问题,主动学习应运而生,其可以利用当前小样本训练的检测模型,主动地选择其中最有价值的样本进行标记,然后再将该样本加入到之前模型的训练集中重新训练,以不断提高检测模型的泛化能力。主动学习可以显著地减少训练所需的样本数量。
传统的机器学习webshell检测技术依赖于大量的已标记样本,然而新出现的webshell代码的标记数量往往较少,使得传统的机器学习检测方法难以取得较好的检测效果。针对该问题,研究了基于命令序列及主动学习算法的webshell检测方法,提出了基于最大距离的样本选择策略和基于最小估计风险的样本标记策略,实现了已标记样本较少情况下的webshell检测。相比于未使用主动学习的方法,该算法的总体检测效果更好,在已标记样本数量占比为10%的情况下,其比随机选择策略的主动学习的效果更好,在时间性能上比人工标记策略的主动学习效果更好。
在现有的研究中,基于支持向量机的主动学习方法,即将最靠近svm分类面的样本作为不确定样本,对其进行人工标记并加入原训练集,然后重新训练分类模型。还有在svm的基础上引入了一种直推式支持向量机的方法,其利用待分类样本的内部信息来提高学习器的局部分类性能。实验结果表明,在少标注样本少于400的情况下,tsvm比svm约高出4%~6%的性能。另一种主动学习方法是基于委员会投票选择的主动学习技术,其通过训练多个分类器,将投票不一致的样本进行标记并重新加入训练集,能够使用很少的样本达到理想的检测精度。相比于svm,该方法的速度更快。但是上述方式在选择未标注的样本后,都采用人工标注的方式对样本进行标记,时间开销较高,不利于快速形成检测。通过计算样本的相似性,再结合最小化估计风险的主动学习来选择样本,省去了人工标注的环节,直接将相似度较高的样本加入原来的训练集,在小规模webshell样本的情况下降低了错误率。但是,该方法的局限性较大,需要构建数据依赖网络并找到重要资源对象,不具有通用性。
技术实现要素:
本发明旨在提供一种基于命令序列及主动学习算法的webshell检测方法,以解决上述问题。为此,本发明采用的具体技术方案如下:
根据本发明的一方面,提供了一种基于命令序列及主动学习算法的webshell检测方法,该方法包括以下步骤:
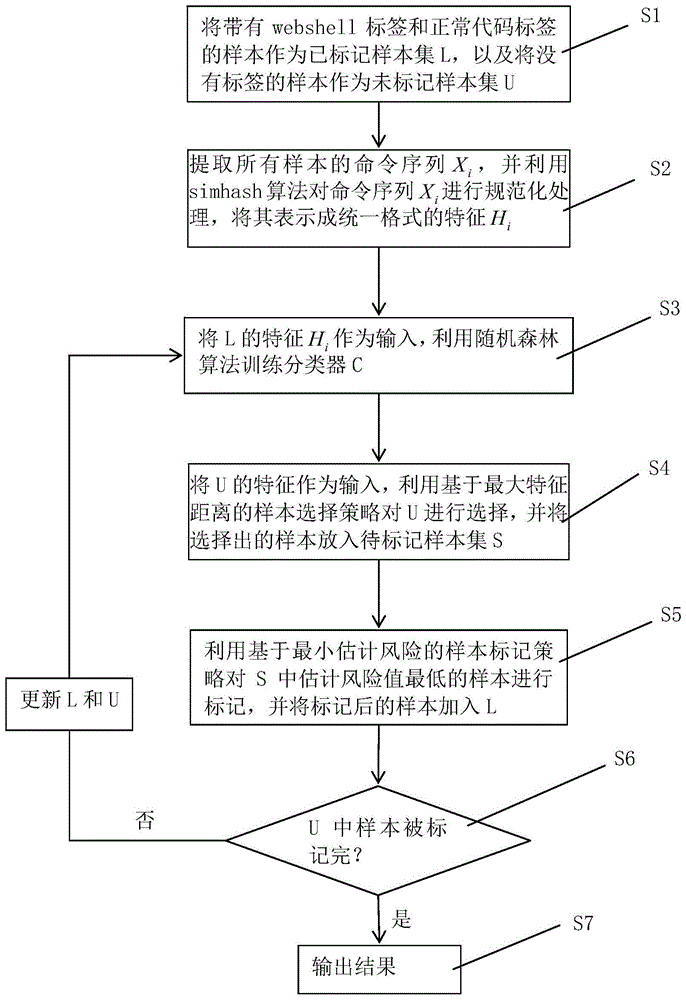
s1.将带有webshell标签和正常代码标签的样本作为已标记样本集l,以及将没有标签的样本作为未标记样本集u;
s2.提取所有样本的特征,即命令序列xi,i(i∈l∪u)表示第i个样本,并利用simhash算法对命令序列xi进行规范化处理,将其表示成统一格式的特征hi;
s3.将l的特征hi作为输入,利用随机森林算法训练分类器c;
s4.将u的特征hi作为输入,利用基于最大特征距离的样本选择策略对u进行选择,并将选择出的样本放入待标记样本集s;
s5.利用基于最小估计风险的样本标记策略对s中估计风险值最低的样本进行标记,并将标记后的样本加入l;
s6.更新l和u,并重新对c进行训练,直到u中所有样本被标记完毕;
s7.输出检测结果。
进一步地,s2中的利用simhash算法对命令序列进行规范化处理的具体过程为:首先对命令序列xi进行分词处理,将其分成多个api函数,其中xi={opi1,opi2,...opin},n为api函数的数量,opin为调用api函数的命令,并根据导致系统出现安全问题的概率来确定每个api函数的权重,概率越高,权重越大;然后对每个命令都做b位的hash计算和加权,若hash值的第k位为1,则权重wk为正,否则为负;最后将加权后的权重累加和进行归一化处理,得到最终的simhash值hi。
进一步地,b=6。
进一步地,s4中的最大特征距离为海明距离。
进一步地,s4的具体过程为:首先对未标记样本集u的特征hi进行两两计算,得到两个样本之间的海明距离,并将其保存在数组中;其次计算数组元素的最大值,并返回最大海明距离指向的样本;最后选择具有最大值的两个样本加入待标记样本集s中。
进一步地,s5的具体过程为:首先将选择出的待标记样本集s中的样本与已标记样本集l中的样本进行相似性度量;然后利用分类器c对s中的样本进行预测;最后根据相似性度量的结果和预测的结果计算样本的估计风险值,并输出估计风险值最小的样本及其标记。
进一步地,相似性度量的计算过程如下:
设来自s和l的样本特征分别为hs={y1y2...yb},hl={z1z2...zb},
定义相似性度量公式为:
其中,yr,zr分别表示两个样本的特征hs,hl所对应的比特数值,hs表示s中第s个样本的特征,hl表示l中第l个样本的特征;若s与l中被标记为webshell的样本l进行相似性度量,则用sim(hs,hl+)表示;若s与被标记为正常代码的样本l进行相似性度量,则用sim(hs,hl-)表示;hl+表示l中webshell类样本的第l个样本的特征,hl-表示l中正常代码类样本的第l个样本的特征。
进一步地,样本的估计风险值的计算公式如下:
其中,
进一步地,已标记样本集l的样本数量占所有样本数量的比例为10%左右。
进一步地,webshell包括基于asp、php、aspx、jsp语言的webshell。
根据本发明的另一方面,还提供了一种终端设备,可包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其中,所述处理器执行所述计算机程序时实现如上所述的方法的步骤。
根据本发明的又一方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其中,所述计算机程序被处理器执行时实现如上所述的方法的步骤。
本发明采用上述技术方案,具有的有益效果是:本发明方法选择性地对样本进行标记且不依赖于人工,进一步提高了主动学习的效率,能够在webshell样本数量较少的情况下不断增量训练,逐渐提高模型的泛化能力,从而达到较为理想的检测效果,为新型webshell的检测提供了支持。
附图说明
为进一步说明各实施例,本发明提供有附图。这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理。配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点。图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
图1是本发明的基于命令序列及主动学习算法的webshell检测方法的流程图;
图2是simhash算法的处理过程的示意图;
图3是基于最大特征距离的样本选择策略流程图;
图4是基于最小估计风险的样本标记策略的流程图。
具体实施方式
现结合附图和具体实施方式对本发明进一步说明。
如图1所示,根据本发明的一方面,提供了一种基于命令序列及主动学习算法的webshell检测方法,该方法包括以下步骤:
s1.将带有webshell标签和正常代码标签的样本作为已标记样本集l,以及将没有标签的样本作为未标记样本集u。
s2.提取所有样本的特征,即命令序列xi,并利用simhash算法对命令序列xi进行规范化处理,将其表示成统一格式的特征hi。具体包括以下过程:
s21.样本命令序列提取:
命令序列是websehll实现其恶意行为并与系统交互所必须的操作码,虽然命令序列本身是没有恶意性的,但是websehll通过某些命令学列的组合,可使其所表示的行为构成恶意性,而这些行为在正常文件中是不常见的,如执行“一句话”命令、文件上传操作、文件下载操作和提权操作等。因此,本发明对webshell的命令序列xi={opi1,opi2,...opin}进行提取,其中i(i∈l∪u)表示第i个样本,n为api函数的数量,opin为调用api函数的命令。对应网页脚本来说,提取样本命令系列就是对网页脚本提取opcode操作码序列。下面以php脚本为例,实现opcode的提取过程。由php脚本的生命周期可知,每一个php脚本并不会直接被命令执行引擎zend执行,而必须要经过文本扫描,语法解析等步骤,去除无用的注释信息,生成opcode序列,zend引擎的真正执行的是opcode序列;所以,与php脚本相比,php脚本的opcode序列在保留php操作指令结构的前提下,消除了注释信息对下一阶段生成的词袋的影响,确保生成的词袋是与php脚本的操作意图是相关的,也起到了防止攻击者通过注释信息对代码变形,干扰分类模型分类的效果;而且,不同的php脚本会生成不同的opcode序列,相同类别的php脚本生成的opcode序列却具有一定程度的相似性。
利用php-vld插件,生成php命令序列即opcode,以一个常见的“一句话”木马为例:
其他语言(例如,asp、aspx或jsp等)的命令序列提取类似,可通过相关工具生成也可通过词法及语法解析生成。
s22.命令序列规划化处理:
由于命令序列的长度不一,将其直接作为特征会增加后续建模的计算复杂度,从而影响检测的效果,因此本文采用simhash算法对该序列进行处理,将每个特征都表示成相同位数的二进制形式。图2示出了simhash算法的处理过程:
s221:对webshell命令序列xi={opi1,opi2,...opin}进行分词处理,将其分为多个api函数,并确定每个函数的权重。
每个函数的权重的设定根据该函数导致系统出现安全问题的概率高低进行设定,概率越高权重越大。权重与概率对应关系可以事先定义。例如,权重可以设置为1-10,其中1表示该函数不会导致系统出现安全问题,而10表示该函数肯定会导致系统出现安全问题。
s222:对每个函数均进行哈希(hash)运算,得到对应的哈希值。
哈希值为二进制数01组成的b位数值的签名,比如b=6,“api1”的哈希值hash(api1)为100101,“api2”的哈希值hash(api2)为“101011”。通过哈希运算可以将字符串转变成一系列数字。
s223:对每个函数的哈希值进行按位加权运算。
该实施例中还进一步设定:若哈希值中某位的值为1,则该位的权重wk设为正,否则设为负。
所述按位加权运算为将二进制的哈希值中的每一位均与权重进行相乘,如“api1”的哈希值进行按位加权运算的结果为:w(api1)=100101*4=4-4-44-44,“api2”的哈希值进行按位加权运算的结果为:w(api2)=101011*5=5-55-555。
s224:将该webshell命令序列xi的所有函数的按位加权运算结果进行按位累加。
如“api1”的“4-4-44-44”和“api2”的“5-55-555”进行累加,得到“4+5-4+-5-4+54+-5-4+54+5”,即为“9-91-11”。
s25:将该webshell命令序列xi的按位累加结果进行归一化处理(降维),得到simhash值hi,该simhash值hi即为api调用序列的特征。
所述归一化处理为:将大于0的位置1,否则置0。如上述步骤s24计算的结果“9-91-11”经过归一化处理后的结果为“101011”,该结果为该调用序列xi的simhash签名。
s3.将l的特征hi作为输入,利用随机森林算法训练分类器c。随机森林算法训练分类器c的过程是公知的,这里不再进行进一步描述。
s4.将u的特征hi作为输入,利用基于最大特征距离的样本选择策略对u进行选择,并将选择出的样本放入待标记样本集s。
基于最大特征距离的样本选择策略的目的是从大量未标记样本中选择具有标记价值的样本,这一方面能够减少后续标记的工作量,提高整个主动学习算法的检测速度;另一方面能够提高标记的准确率,降低无用样本带来的干扰。在主动学习初期,已标记的样本较少,训练的分类器泛化性能较低,难以对特征相近的样本进行预测,选择特征差异较大的样本能够降低预测难度。而同一类样本的特征存在相似性,相似性越低的样本,其特征之间的差异越大。为此,本发明提出了一种基于最大特征距离的样本选择策略,将特征间的海明距离(hammingdistance)作为样本差异性的衡量标准,其目的是从未标记样本集u中选择出待标记的样本集s,以为后续的样本标记提供支持。由于特征的数据为二进制形式,因此使用海明距离能够更好地反映各特征在位数上的差异。海明距离是两个b位长码字,例如z={z1z2...zb}和y={y1y2...yb}之间对应位的不同比特总数,其公式如下:
其中,yr∈{0,1},zr∈{0,1},dham(y,z)表示y和z在相同位置上不同比特数的总数,总数越多相似度越低。如对于两个命令序列的特征h1=10010111和h2=1010100,其中不同的位数共有3位,因此dham(h1,h2)=3。
本发明假设webshell样本由于其恶意性会大量调用敏感函数,使得其命令序列较为相似,利用该策略进行选择的过程如图3所示。首先对未标记样本集u的特征hi进行两两计算,得到两个样本之间的海明距离,并将其保存在数组中;其次计算数组元素的最大值,并返回最大距离特征指向的样本;最后选择具有最大值的两个样本加入待标记样本集s中。基于最大特征距离的样本选择策略的算法描述下所示:
基于最大特征距离(海明距离)的样本选择策略
输入:未标记样本集u,共u个样本;
输出:待标记样本集s;
step1设i=1,j=i+1,i,j∈u;
step2计算第i个和第j个未标记样本的海明距离dham(i,j),并将
计算结果保留在集合d中;
step3ifj<=uj=j+1andgotostep2;
elsegotostep4;
step4ifi<=u-1i=i+1andgotostep2
elsegotostep5;
step5计算max{d},选择符合条件的两个样本加入待标记样本集
s中。
s5.利用基于最小估计风险的样本标记策略对s中估计风险值最低的样本进行标记,并将标记后的样本加入l。
基于最小估计风险的样本标记策略的目的是通过分析样本自身的信息和规律,利用机器自动对样本进行标记,以进一步提升算法的检测速度。其基本思路是:首先将选择出的待标记样本集s中的样本与已标记样本集l中的样本进行相似性度量;然后利用初始分类器c对s中的样本进行预测;最后根据相似性度量的结果和预测的结果计算样本的估计风险值,并输出估计风险值最小的样本及其标记。在传统的主动学习过程中,从未标记样本集u中选择出待标记样本后通常都是采用人工交互的方式进行标记,会消耗大量的人力和物力,还存在标记速度过慢的缺点,难以快速进行检测。因此,本文结合相似性度量,利用最小估计风险的方法对样本自动进行标记,该策略的流程如图4所示。
在步骤s4的海明距离计算的基础上设计相似性度量的标准,对s中每个样本的特征与l中每个样本的特征进行度量,其思想是:特征越相似的两个样本,其属于同一类样本的可能性就越大。通过与不同类样本进行相似性度量,可初步确定待选择样本属于某一类的概率。相似性度量的计算过程如下:
设来自s和l的样本特征分别为hs={y1y2...yb},hl={z1z2...zb},
定义相似性度量公式为:
其中,yr,zr分别表示两个样本的特征hs,hl所对应的比特数值,hs表示s中第s个样本的特征,hl表示l中第l个样本的特征;若s与l中被标记为webshell的样本l进行相似性度量,则用sim(hs,hl+)表示;若s与被标记为正常代码的样本l进行相似性度量,则用sim(hs,hl-)表示;hl+表示l中webshell类样本的第l个样本的特征,hl-表示l中正常代码类样本的第l个样本的特征。
估计风险计算的基本思想是:对某样本的分类器c的预测结果与相似性度量结果进行综合评估,估计风险越低说明该样本标签被标记正确的概率就越大。其主要过程如下:首先设分类器c的预测结果为c(h)(c(h)∈{0,1}),预测的标签为h()(h∈{webshell,正常文件})。为进一步确定样本的标记情况,在相似性度量的基础上,对c的预测结果与相似性度量的结果进行风险值的估计,将估计风险值最小的样本及其标记输出。这里包括对中webshell类和正常代码类的风险估计,其计算公式如下:
其中,
s6.更新l和u,并重新对c进行训练,直到u中所有样本被标记完毕;
s7.输出检测结果。
此外,本发明还提供了一种终端设备,可包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其中,所述处理器执行所述计算机程序时实现上述方法实施例中的步骤,例如图1所示的步骤s1-s7等方法步骤,或者所述处理器执行所述计算机程序时实现上述装置实施例中各模块/单元的功能。
示例性地,所述计算机程序可以被分割成一个或多个模块/单元,所述一个或者多个模块/单元被存储在所述存储器中,并由所述处理器执行,以完成本发明。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序在所述终端设备中的执行过程。。
终端设备可以是桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备。终端设备可包括但不仅限于,处理器、存储器。例如其还可以包括输入输出设备、网络接入设备、总线等。
处理器可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现成可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,所述处理器是所述终端设备的控制中心,利用各种接口和线路连接整个终端设备的各个部分。
所述存储器可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现所述终端设备的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其中,所述计算机程序被处理器执行时实现如上所述的方法的步骤,例如图1所示的步骤s1-s7等方法步骤。
计算机程序的各个模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
本发明针对webshell出现之初,用于分析检测的样本数量较少的现实情况,设计了基于最大距离的样本选择策略和最小估计风险的样本标记策略,在l/(l+u)较小的情况下,采用该算法比采用随机选择策略的主动学习算法的检测效果更优。在时间性能上,采用该算法比采用人工标记策略的主动学习算法更具优势。同时,与不采用主动学习的机器学习算法相比,该算法具有更好的检测效果,而且在少量样本集和l/(l+u)较小(例如,10%左右)的情况下,该检测方法的优势更加明显。可见,本发明提出的检测方法具有一定的实用价值,能够为当前新型webshell的检测提供有效的技术支持。
尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!