一种基于多深度图像特征融合的人体姿态估计方法与流程
本发明属于人体姿态估计领域,尤其是一种基于多深度图像特征融合的人体姿态估计方法。
背景技术:
随着3d视觉以及人工智能技术的不断发展,3d视觉传感器的使用范围越来越宽广,尤其是在人体姿态估计领域发挥了越来越重要的作用。基于3d视觉的人体姿态估计技术已被应用到行为识别、行为预测、人机交互、视频监控、虚拟现实等领域,例如,用于受伤人员的康复训练,用于运动员的体育训练分析,用于3d动画影视的人物形象制作等。
目前,基于3d视觉的人体姿态估计技术较为成熟,其可利用深度图像信息对前景和背景进行快速的分割,并基于随机森林的方法识别出人体的各关节点,即可计算输出3d的人体姿态信息。然而,影响人体姿态估计的因素众多,如视觉遮挡、人体部件误识别、运动突变、环境动态变化等,都会造成较大的量测信息偏差,因此依靠单个3d视觉传感器很难捕捉到完整可靠的人体姿态信息。为了增强人体姿态估计系统对视觉遮挡、环境变化等不利因素的鲁棒性,一种有效的方法是融合来自多个3d视觉传感器的人体姿态信息以获取完整且可靠的人体姿态估计信息。然而在现有的3d视觉人体姿态估计中,还没有技术能够鲁棒、有效地融合多个3d视觉传感器的信息解决复杂场景下的人体姿态估计问题。
技术实现要素:
为了克服单3d视觉传感器对遮挡、运动突变、动态场景变化等鲁棒性差的缺点,本发明提供一种基于多深度图像特征融合的人体姿态估计方法,即采用分布式融合方法融合多个3d视觉传感器信息以获取人体姿态的估计,有效地提高了人体姿态估计的精确度和鲁棒性。
本发明解决其技术问题所采用的技术方案是:
一种基于多深度图像特征融合的人体姿态估计方法,所述方法包括以下步骤:
步骤1)确定世界坐标系以及各相机坐标系与世界坐标系之间的旋转平移关系,建立人体各关节点运动学模型以及各传感器的量测模型,确定人体各关节点的过程噪声协方差qi,k、各传感器量测噪声协方差
步骤2)根据人体各关节点的运动学模型,计算k时刻各传感器中人体各关节点的状态预测值
步骤3)从3d视觉传感器读取深度图像,并基于深度随机森林方法识别计算出人体各关节点的位置
步骤4)计算k时刻各传感器下人体各关节点的卡尔曼滤波增益
步骤5)将各传感器下的人体各关节点状态估计值
步骤6)采用分布式融合方法融合各传感器下的人体各关节点状态估计值
重复执行步骤2)-6)完成对人体各关节点的姿态估计,得出融合多深度图像特征的人体姿态估计。
进一步,在所述步骤1)中,所述的i表示人体各关节点的序号,i=1,...,25,人体各关节点包括头关节、胸椎关节、肩关节、肘关节、腕关节等需要估计的人体关节点,所述的l表示视觉传感器的序号,l=1,2,...n,其中,n≥2表示传感器的数量。所述的k为离散时间序列。
所述步骤1)中,所述的人体关节点状态为各关节点在各相机坐标系下x,y和z轴上的位置。
所述步骤3)中,所述的残差
所述步骤3)中,所述的读取到的人体各关节点位置信息,利用随机森林方法实现人体部件识别的基础上,计算得出人体各关节点的位置信息。
所述步骤5)中,所述的上标l*表示世界坐标系下传感器l的估计结果,所述的读取到的人体各关节点位置信息,利用随机森林方法实现人体部件识别的基础上,计算得出人体各关节点的位置信息。
所述步骤6)中,所述的上标f表示融合估计结果。
本发明的有益效果主要表现在:提供一种基于多深度图像特征融合的人体姿态估计方法,针对单个3d视觉传感器在捕捉人体姿态时存在的遮挡、环境变化等缺陷,采用分布式融合方法融合多个3d视觉传感器信息以获取人体姿态的估计,减少了复杂环境下对人体姿态估计的不利影响,有效地提高了人体姿态估计的精确性和鲁棒性。
附图说明
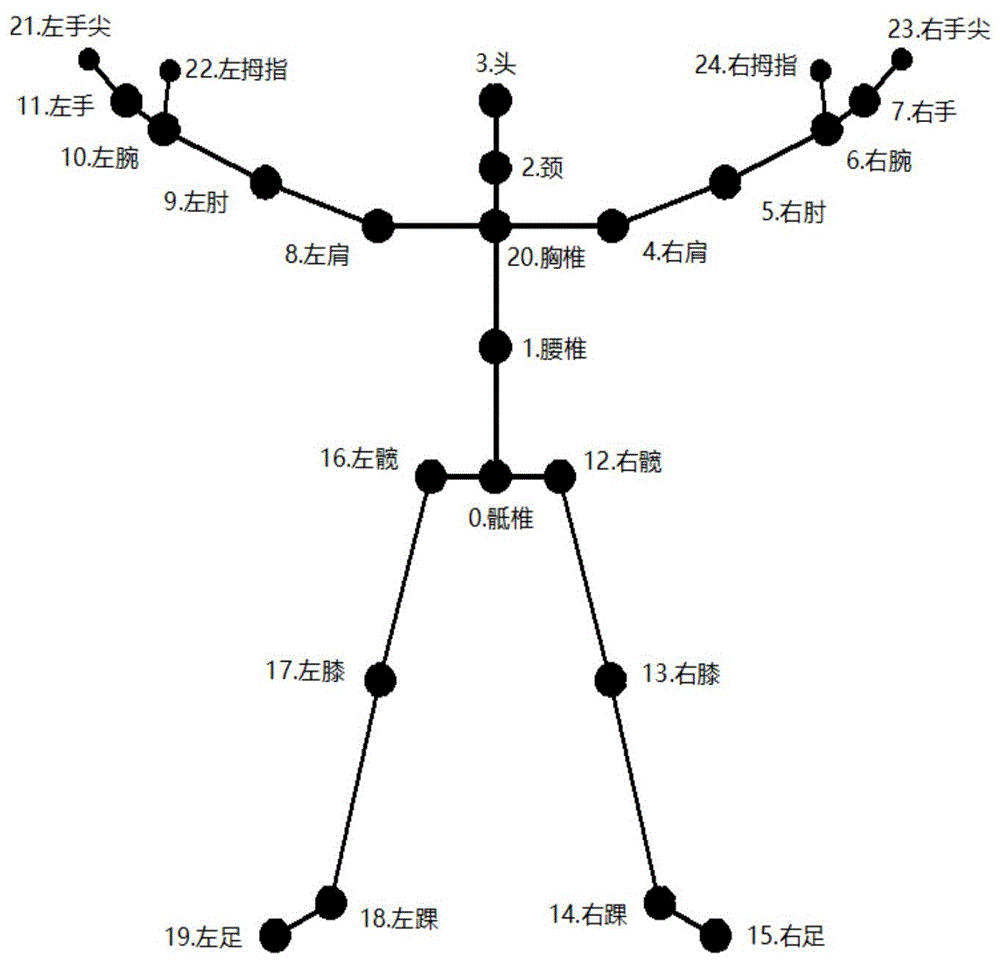
图1是用于描述深度图像下的人体各关节点示意图。
图2是基于多深度图像特征融合的人体姿态估计流程图。
具体实施方式
下面结合附图对本发明做进一步描述。
参照图1和图2,一种基于多深度图像特征融合的人体姿态估计方法,所述方法包括以下步骤:
步骤1)确定世界坐标系以及各相机坐标系与世界坐标系之间的旋转平移关系,建立人体各关节点运动学模型以及各传感器的量测模型,确定人体各关节点的过程噪声协方差qi,k、各传感器量测噪声协方差
步骤2)根据人体各关节点的运动学模型,计算k时刻各传感器中人体各关节点的状态预测值
步骤3)从3d视觉传感器读取深度图像,并基于深度随机森林方法识别计算出人体各关节点的位置
步骤4)计算k时刻各传感器下人体各关节点的卡尔曼滤波增益
步骤5)将各传感器下的人体各关节点状态估计值
步骤6)采用分布式融合方法融合各传感器下的人体各关节点状态估计值
重复执行步骤2)-6)完成对人体各关节点的姿态估计,得出融合多深度图像特征的人体姿态估计。
如图1所示,将人体姿态估计问题分解成对人体各关节点的位置估计问题,其包括了头关节、胸椎关节、肩关节、肘关节、腕关节等25个人体关节点。基于多深度图像特征融合的人体姿态估计流程图如图2所示。首先,对各传感器的相机坐标系与世界坐标系进行标定,确定各相机坐标系与世界坐标系之间的旋转平移关系。建立人体各关节点的运动学模型以及各传感器的量测模型:
xi,k=xi,k-1+wi,k(1)
其中,k=1,2,…为离散时间序列,
其次,计算各传感器下人体各关节点的状态预测值
根据人体各关节点的运动学模型以及上一时刻的状态估计值
计算各传感器下人体各关节点的卡尔曼滤波增益
计算在世界坐标系中各传感器下人体各关节点状态估计值
其中,
采用分布式融合方法融合各传感器下人体各关节点的状态估计值
重复执行公式3)-13),完成对人体所有关节点的状态估计,从而得到基于多深度图像特征融合的人体姿态估计。
- 还没有人留言评论。精彩留言会获得点赞!