一种大倍率浅景深状态下人脸区域自动聚焦方法与流程
本发明涉及大倍率浅景深状态下人脸区域自动聚焦方法,应用在教育录播、视频会议用摄像机领域。
背景技术:
近年,在教育录播、视频会议等应用中,通常会使用10倍、12倍或20倍等变倍摄像机,在一个5-10米的室内场景,实时播放以人物作为主题的视频,其中最关键的点是保证人物的脸部区域要绝对清晰。在此背景下,提出以人脸区域作为自动聚焦的重点区域是一种有效解决此问题的方法。
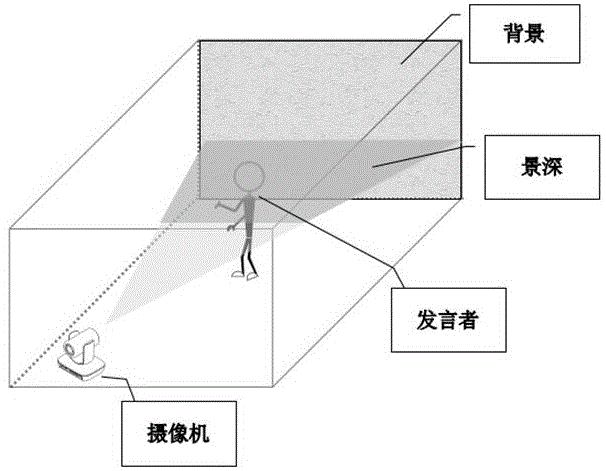
考虑到这样一种使用场景,如图1所示,在这个三维场景内,由远到近依次是背景(黑板、背景墙等)、主题(发言者)、摄像机(10倍、12倍或20倍)。对于摄像机来说,要把它拉动到适当的倍率下,让发言者占图像的三分之一至四分之一大小,同时保证发言者在图像内最清晰。影响发言者区域清晰程度的因素有四个:
(1)变倍镜头拉动到大倍率下的景深会变浅,无法同时保证背景与人物都清晰。
(2)降低噪点增大光圈的策略导致景深会变浅,无法同时保证背景与人物都清晰。
(3)背景细节过于丰富,在自动聚焦算法内被误认为是图像主题计算出了假峰值,导致背景清晰,人物模糊。
(4)人物细节过于单一,在自动聚焦算法内权重过小,在计算fv(focusvalue)时被算法忽略,导致其它物距清晰,人物模糊。
以上因素组合在一起,便很难通过传统的自动聚焦算法达到人物区域清晰的目的。
近年,神经网络技术发展突飞猛进,它们被广泛应用在ai(artificialintelligence)领域,很多人工智能领域的科学家尝试解决各类检测问题,其中包括人脸区域检测算法。它在神经网络中被设计成计算多层不同等级特征的权重达到预测图像中是否存在人脸以及定位人脸区域的算法。往往低等级特征(low-levelfeature)关注图像中一些微小的细节,例如边缘、颜色、转角、梯度、像素等,高等级特征(high-levelfeature)关注图像中目标、形状,同时考虑更加丰富的语义信息,例如五官、痣、脸型等。应用人脸检测算法辅助自动聚焦能够很好的避免上述影响发言者区域图像清晰度问题的产生,达到发言者区域最清晰的效果。
另一方面,极致优化的神经网络软件开发框架,例如服务器端:caffe、tensorflow、pytorch,嵌入式端:ncnn(arm核),nnie(npu),以及硬件存储和算力的支撑,让这些需要大量计算的复杂算法可以实时运行。然而面对设计精良小巧、成本节约的摄像机产品,往往在成像需求方面就已经消耗部分算力,再把人脸检测、区域指定算法嵌入到系统内必然造成算力吃紧,难以达到实时处理的情况。
技术实现要素:
有鉴于此,本发明的目的在于克服上述难题,而提供一种大倍率浅景深状态下人脸区域自动聚焦方法,在大倍率浅景深场景下,能够在算力不足的摄像机产品中进行人脸检测、区域优选、自动聚焦,以找到发言者区域最清晰focus电机位置。
本发明为解决上述问题所采用的技术方案是:一种大倍率浅景深状态下人脸区域自动聚焦方法,其特征在于:包括如下步骤:
步骤一、基于yolov3神经网络,训练人脸检测器dtr,步骤如下:
(1)搭建神经网络训练服务器,使用gpu对神经网络训练加速;
(2)准备训练数据:d={d1,d2,...,dn},其中d代表人脸数据集,dn代表单个人脸图片样本,n是样本个数;
(3)改进yolov3神经网络,得到改进版的yolov3神经网络m;
(4)计算yolov3神经网络m的人脸检测器权重w,设置迭代次数i,同时计算损失度l对比阈值大小,当损失度l小于阈值时训练停止,最终得到人脸检测器dtr,它是由m和w共同组成;
(5)在人脸数据集d中选取出一部分数据作为测试数据集dt,把测试数据集dt输入到人脸检测器dtr里,测试人脸检测器dtr的有效性;
步骤二、使用人脸检测器dtr计算图像中人脸区域集合:
r=dtr(dinput),
其中dinput是帧数据,r是检测出的人脸区域集合,通常集合中单个人脸框rn(rn∈r)包含5个参数xmin,xmax,ymin,ymax,score,分别是x轴最小最大坐标、y轴最小最大坐标与人脸框置信度;
步骤三、人脸区域优选:
将一张图像内较为居中且面积较大的人脸框作为自动聚焦的对象,有:
(1)设图像中心点坐标为(centerx,centery),人脸框中心点坐标为(facex,facey),即:
facex=(xmax-xmin)/2,
facey=(ymax-ymin)/2,
(2)利用欧式距离公式,分别计算每个人脸框距离图像中心点的距离disn:
(3)分别计算每个人脸框的面积:
arean=(xmax-xmin)×(ymax-ymin),
(4)根据上述disn,arean,s和人脸框置信度scoret,以及阈值来锁定一个人脸框,首先过滤小于阈值scorethd的人脸框,其次对disn进行从小到大排序,disn越小说明它代表的人脸框距离图像中心点越近,然后计算disn对应的arean,如果它小于阈值areathd,那么抛弃该disn,重新判断disn+1对应的arean+1是否小于阈值areathd,以此类推,最后锁定一个人脸框作为优选后的人脸区域;
步骤四、优选人脸区域与hisi芯片划分的m*n区域匹配,锁定感兴趣聚焦区域;
步骤五、计算感兴趣区域fv:
同时考虑两种fv,高频图像清晰度值fvhigh与低频图像清晰度值fvlow,在fvhigh与fvlow的切换通过设置阈值thdhigh和thdlow的方式来实现:
如果fvhigh大于等于thdhigh并且fvlow大于等于thdlow,那么fv=fvhigh,
如果fvhigh大于等于thdhigh并且fvlow小于thdlow,那么fv=fvhigh,
如果fvhigh小于thdhigh并且fvlow大于等于thdlow,那么fv=fvlow,
如果fvhigh小于thdhigh并且fvlow小于thdlow,那么fv=fvlow,
加权求和fv计算方法是:
其中t∈m*n,weight是对应区域的权重,fvoutput是加权求和后的值;
步骤六、自动聚焦:
初始化搜索方向dinit=far,设置focus电机行进速度为低速,采用连续多帧行进focus电机的方式找到下一阶段行进方向;利用步骤五的fvoutput逐帧改变focus电机前进速度,多次折返focus电机运动方向后确定最清晰图像对应的focus电机位置,既定焦。
本发明单个人脸图片样本一部分是开源数据,另一部分是自己采集标注的数据。
本发明改进yolov3神经网络的步骤为适当减少yolov3的卷积层数,并且降低剩余卷积层的核大小,目的是让算法运行的更快,同时考虑mobilenet卷积层的形态,把部分剩余卷积层的标准卷积调整为点卷积,进一步加速神经网络算法的计算速度。
本发明爬山算法步骤是:
(1)设定focus电机前进速度与fvoutput的大小相关,fvoutput越大速度越小,fvoutput越小速度越大,依赖的初始化搜索方向dinit=far,让focus电机前进,目的是找到下一阶段运动方向,当fvoutput达成连续2次下降时,设置下一阶段方向为near,否则为far,其中near和far分别代表focus电机的两个不同行进方向,并且near与far的行进方向相反;
(2)设置focus电机速度为快速,按照步骤(1)中确定的运动方向持续推进focus电机,直到fvoutput达成连续3次下降,其中当fvoutput首次下降时,适当降低focus电机速度,当fvoutput第二次下降时,大幅降低focus电机速度,此时可以确定focus电机已经越过了最清晰图像对应的focus电机点位。
(3)focus电机运动方向设置为步骤(2)的反向,速度为中速并且持续推进focus电机,当fvoutput开始下降时,迅速减小focus电机速度,当fvoutput达到连续2次下降后,进入下一个阶段。
(4)在前三个步骤中,已经记录了最大fvoutput与它对应的focus电机位置,调整focus电机位置到最清晰focus电机位置后,爬山算法结束。
本发明所述的gpu型号为nvidiartx2080ti。
本发明高频图像清晰度值fvhigh与低频图像清晰度值fvlow是通过hisi芯片封装好的滤波器计算获得。
本发明初始搜索方向dinit为随机定义的方向。
本发明步骤三的步骤(4)中,如果第一次迭代并未选择任何人脸框,那么适应的减小areathd,重新运行步骤(4)。
本发明与现有技术相比,具有以下优点和效果:1、在传统的自动聚焦算法基础上融合了人脸检测算法,做到能够在大倍率浅景深状态下检测出人脸区域,并且聚焦到此区域,可以快速准确的达到发言者区域自动聚焦的目的,同时考虑画面震荡小、聚焦速度快、准确性高、稳定性强等技术特点;2、做到了在算力不足的嵌入式端实时地进行人脸检测、区域优选、自动聚焦;3、空间时间复杂度小,占用内存量低,搜索时间短;4、鲁棒性好,可靠性高,可扩展性强,可维护性高,很好的解决了在大倍率浅景深状态下自动聚焦算法无法聚焦到发言者区域这一难题;5、在实际场景中使用有良好的聚焦效果表现,聚焦速度快,聚焦震荡不明显,发言者区域始终保持最清晰可见。
附图说明
图1为现有技术中提及的一种使用场景的模拟场景图。
图2为本发明爬山算法示例图。
具体实施方式
下面结合附图并通过实施例对本发明作进一步的详细说明,以下实施例是对本发明的解释而本发明并不局限于以下实施例。
本发明包括如下步骤:
步骤一、基于yolov3神经网络,训练人脸检测器,步骤如下:
(1)搭建神经网络训练服务器,使用gpu(nvidiartx2080ti)对神经网络训练加速。
(2)准备训练数据:d={d1,d2,...,dn},其中d代表人脸数据集,dn代表单个人脸图片样本,n是样本个数,在我们的训练中n约等于40万,其中一部分来自开源的人脸数据库,另一部分是自己标注的人脸数据。
(3)改进yolov3神经网络,适当减少yolov3的卷积层数,并且降低剩余卷积层的核大小,目的是让算法运行的更快,同时考虑mobilenet卷积层的形态,把部分剩余卷积层的标准卷积调整为点卷积,进一步加速神经网络算法的计算速度,最后得到改进版的yolov3神经网络m。
(4)计算yolov3神经网络m的人脸检测器权重w,设置迭代次数i,同时计算损失度l对比阈值大小,当损失度l小于阈值时训练停止,最终得到人脸检测器dtr,它是由m和w共同组成。
(5)在人脸数据集d中选取出一部分数据作为测试数据集dt,把测试数据集dt输入到人脸检测器dtr里,测试人脸检测器dtr的有效性,其中dt与d不重叠。
步骤二、使用人脸检测器dtr计算图像中人脸区域集合:
r=dtr(dinput)
其中dinput是帧数据,r是检测出的人脸区域集合,通常集合中单个人脸框rn(rn∈r)包含5个参数xmin,xmax,ymin,ymax,score,分别是x轴最小最大坐标、y轴最小最大坐标与人脸框置信度。
步骤三、人脸区域优选:
往往一张图像内可能存在多个人脸框,但总是会有一个较为居中且面积较大,那么考虑此人脸框作为自动聚焦的对象。有:
(1)假设图像中心点坐标为(centerx,centery),人脸框中心点坐标为(facex,facey),即:
facex=(xmax-xmin)/2
facey=(ymax-ymin)/2
(2)利用欧式距离公式,分别计算每个人脸框距离图像中心点的距离disn:
(3)分别计算每个人脸框的面积:
arean=(xmax-xmin)×(ymax-ymin)
(4)根据上述disn,arean,s和人脸框置信度scoret,以及阈值来锁定一个人脸框,首先过滤小于阈值scorethd的人脸框,这个阈值通常设置的较高,用来过滤掉置信度不高的人脸框,其次对disn进行从小到大排序,disn越小说明它代表的人脸框距离图像中心点越近,然后计算disn对应的arean,如果它小于阈值areathd,那么抛弃该disn,重新判断disn+1对应的arean+1是否小于阈值areathd,以此类推,最后锁定一个人脸框作为优选后的人脸区域,如果第一次迭代并未选择任何人脸框,那么系统会自适应的减小areathd,重新运行(4),这种做法是为了选择一个距离图像中心较近同时面积较大的人脸框,因为它通常被视为图像的主体。
步骤四、优选人脸区域与hisi芯片划分的m*n区域匹配,锁定感兴趣聚焦区域:
对于200万像素图像(1920*1080)来说,考虑到实时的fv(focusvalue)计算,往往无法自由的划分区域。hisi芯片,如:3516,3559,3519a等把图像划分为m*n个固定区域,其中mmax=15,nmax=17,每个区域提供一个fv给自动聚焦算法使用。在步骤三里我们已经确定了优选人脸框,与m*n个固定区域匹配有:先以xmin,ymin找到固定区域的左上角,在以xmax,ymax找到固定区域的右下角,两个角作为矩形框的左上与右下,我们自然可以确定最终的感兴趣矩形聚焦区域。
步骤五、计算感兴趣区域fv:
本发明同时考虑两种fv,高频图像清晰度值fvhigh与低频图像清晰度值fvlow,往往图像较为清晰的时候,图像内边缘与纹理特征会更加丰富可见,fvhigh也更加具有代表性,而图像较为模糊的时候,图像内边缘变得无法分辨,纹理细节几乎没有,fvlow更具有代表性。在fvhigh与fvlow的切换通过设置阈值thdhigh和thdlow的方式来实现::
如果fvhigh大于等于thdhigh并且fvlow大于等于thdlow,那么fv=fvhigh,
如果fvhigh大于等于thdhigh并且fvlow小于thdlow,那么fv=fvhigh,
如果fvhigh小于thdhigh并且fvlow大于等于thdlow,那么fv=fvlow,
如果fvhigh小于thdhigh并且fvlow小于thdlow,那么fv=fvlow,
thdhigh和thdlow用来控制系统是使用fvhigh还是fvlow,因为根据拍摄场景的不同,高低频对图像清晰度的表达也不同,通常图像较为模糊情况下fvlow更具有代表性,图像较为清晰情况下fvhigh可以被更好的使用。
加权求和fv计算方法是:
其中t∈m*n,weight是对应区域的权重,fvoutput是加权求和后的值。其中weight通过经验获得,中心区域权重往往大于四周区域,比如当步骤四计算出的感兴趣区域为4x4区域时,
步骤六、运行自动聚焦算法:
初始化搜索方向dinit=far,设置focus电机行进速度为低速,采用连续多帧行进focus电机的方式找到下一阶段行进方向。利用步骤五的fvoutput逐帧改变focus电机前进速度,基于爬山算法如图2多次折返focus电机运动方向后确定最清晰图像对应的focus电机位置,既定焦。
爬山算法步骤是:
(1)设定focus电机前进速度与fvoutput的大小相关,fvoutput越大速度越小,fvoutput越小速度越大,依赖上述设置的初始化搜索方向dinit=far,让focus电机前进,目的是找到下一阶段运动方向,当fvoutput达成连续2次下降时,设置下一阶段方向为near否则为far,其中near和far分别代表focus电机的两个不同行进方向,并且near与far的行进方向相反。
(2)设置focus电机速度为快速,按照(1)中确定的运动方向持续推进focus电机,直到fvoutput达成连续3次下降,其中当fvoutput首次下降时,适当降低focus电机速度,当fvoutput第二次下降时,大幅降低focus电机速度,此时可以确定focus电机已经越过了最清晰图像对应的focus电机点位。
(3)focus电机运动方向设置为(2)的反向,速度为中速并且持续推进focus电机,当fvoutput开始下降时,迅速减小focus电机速度,当fvoutput达到连续2次下降后,进入下一个阶段。
在前三个阶段中,已经记录了最大fvoutput与它对应的focus电机位置,调整focus电机位置到最清晰focus电机位置后,爬山算法结束。
此外,需要说明的是,本说明书中所描述的具体实施例,其所取名称、结构可以不同,本说明书中所描述的以上内容仅仅是对本发明结构所作的举例说明。
- 还没有人留言评论。精彩留言会获得点赞!