并行处理设备的制作方法
以下描述涉及并行处理设备。
背景技术:
根据传统技术的大多数并行处理设备以多个处理器处理多个线程的方式进行操作。这种并行处理设备不适用于并行执行非常长的顺序计算。
作为并行执行顺序计算的并行处理设备的传统技术,韩国专利no.10-0835173(名称:在数字信号处理中进行乘法累加运算的装置和方法(apparatusandmethodformultiply-and-accumulateoperationsindigitalsignalprocessing))公开了一种技术。所公开的传统技术适用于过滤和执行快速傅立叶变换(fft)等,但是具有不适用于连续执行可由中央处理单元(cpu)执行的各种计算的方面。
技术实现要素:
技术问题
以下描述旨在提供一种并行处理设备,该并行处理设备能够并行且连续地执行由中央处理单元(cpu)执行的各种顺序计算。
技术方案
在一个总体方面,提供了一种能够进行连续并行数据处理的并行处理设备,所述并行处理设备包括:计算路径网络,被配置为接收从延迟单元输出的多个延迟数据、从存储器输出的多个存储器输出数据、以及多个计算路径网络控制信号,并被配置为输出多个计算路径网络输出数据;以及延迟处理单元,被配置为输出通过延迟所述多个计算路径网络输出数据而获得的所述多个延迟数据。所述多个计算路径网络输出数据中的每个计算路径网络输出数据为通过对所述多个延迟数据和所述多个存储器输出数据执行计算而获得的值,所述值对应于所述多个计算路径网络控制信号之中与该计算路径网络输出数据相对应的计算路径网络控制信号。
有益效果
以下描述的并行处理设备可以并行且连续地执行各种顺序计算,这些计算可以由中央处理单元(cpu)执行。因此,可以提高计算处理速率和计算处理效率。
附图说明
图1示出了并行处理设备的示例。
图2示出了并行处理单元的示例。
图3示出了部分加法单元的操作的示例。
图4示出了并行处理单元的操作的示例。
具体实施方式
由于本发明可以被修改为各种形式并且包括各种实施例,所以具体实施例将在附图中说明并详细描述。然而,该描述不旨在将本发明限制于具体实施例,并且应当理解,属于本发明的技术精神和技术范围的所有改变、等同物和替换包括在本发明中。
诸如“第一”、“第二”、“a”、“b”等术语可用于描述各种元件,但是元件不受这些术语限制。这些术语仅用于将一个元件与另一个元件区分开。例如,在不脱离本发明的范围的情况下,第一元件可以命名为第二元件,并且类似地,第二元件也可以命名为第一元件。术语“和/或”包括多个相关联列出项的组合或这些相关联列出项中的任意一个。
本文中使用的单数表达包括复数表达,除非其在上下文中具有明显相反的含义。应当理解的是,诸如“包括”、“具有”等的术语旨在表示特性、数量、步骤、操作、元件、部分或它们的组合的存在,并不排除一个或多个其他特性、数量、步骤、操作、元件、部分或它们的组合的存在或添加。
在详细描述附图之前,本文中的配置单元的划分仅为根据每个配置单元的主要功能的划分。换言之,下面描述的两个或更多个配置单元可以被组合成单个配置单元,或者一个配置单元可以根据细分的功能被划分成两个或更多个单元。下面描述的每个配置单元除了负责主要功能外,可以附加地执行为其他配置单元设置的功能中的部分或全部功能,每个配置单元承担的一些主要功能也可以由其他配置单元专门承担并执行。
当执行方法或操作方法时,除非在上下文中清楚地提及特定顺序,否则所述方法的步骤可以以与所描述的顺序不同的顺序执行。换言之,步骤可以按与所描述的顺序相同的顺序执行、基本上同时地执行、或按相反的顺序执行。
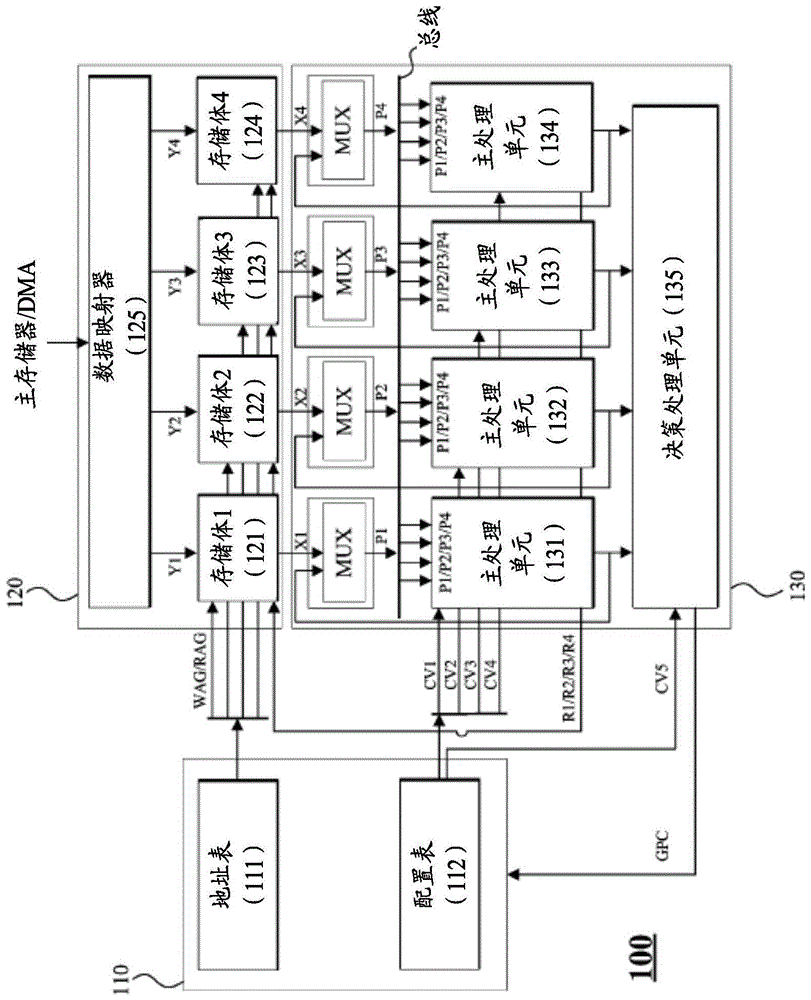
图1示出了并行处理设备100的示例。
并行处理设备100包括地址和配置值生成单元110、存储器120和并行处理单元130。尽管在图1中未示出,并行处理设备还可以包括直接存储器访问(dma)、主存储器以及输入和输出设备。
地址和配置值生成单元110可以将读地址组rag和写地址组wag传送到存储器120。读地址组rag包括多个读地址,写地址组wag包括多个写地址。地址和配置值生成单元110可以包括用于存储多个读地址组rag和/或多个写地址组wag的地址表111。
地址和配置值生成单元110将配置值组cvg传送到并行处理单元130。配置值组cvg包括多个主处理配置值cv1、cv2、cv3和cv4以及决策处理配置值cv5。地址和配置值生成单元110可以包括用于存储多个配置值组cvg的配置值表112。
地址和配置值生成单元110可以输出存储在与从决策处理单元135传送的信息相对应的位置中的读地址组rag、写地址组wag和配置值组cvg。可替代地,地址和配置值生成单元110可以根据从单独的控制单元传送的信息来输出读地址组rag、写地址组wag和配置值组cvg。
地址和配置值生成单元110输出存储在与从决策处理单元135传送的程序计数器gpc相对应的位置中的读地址组rag、写地址组wag和配置值组cvg。
存储器120包括例如四个存储体(memorybank)121、122、123和124。第一存储体121至第四存储体124中的每个存储体可以为例如双端口随机存取存储器(ram)。存储器120输出与读地址组rag相对应的读数据组x1至x4。同样,存储器120根据写地址组wag存储写数据组y1至y4。
存储器120还可以包括数据映射器125。数据映射器125可以接收从dma传送的数据、从并行处理单元130传送的多个数据r1、r2、r3和r4,并通过将接收的数据按照将存储所述接收的数据的存储体121至124的位置进行排列,来获得写数据组y1至y4。数据映射器125可以将写数据组y1至y4分别输出到存储体121至124。同样,数据映射器125可以将要存储在主存储器中的数据从存储器120传送到dma。
并行处理单元130包括例如四个主处理单元131、132、133和134以及决策处理单元135。主处理单元131至134可以对读数据组x1至x4执行特定的计算。主处理单元131至134执行与输入的主处理配置值cv1至cv4相对应的操作。决策处理单元135接收主处理单元131至134的输出,并为下一操作做出决策。决策处理单元135执行与决策处理配置值cv5相对应的操作。并行处理单元130输出最终计算出的多个数据r1、r2、r3、r4和gpc。
图2示出了并行处理单元200的示例。并行处理单元200为与图1的并行处理单元130相对应的元件。并行处理单元200为包括四个主处理单元210、220、230和240的元件的示例。
多个主处理单元中的每个主处理单元可以包括输入单元、部分加法单元和延迟单元。主处理单元210包括输入单元211、部分加法单元212和延迟单元213。主处理单元220包括输入单元221、部分加法单元222和延迟单元223。主处理单元230包括输入单元231、部分加法单元232和延迟单元233。主处理单元240包括输入单元241、部分加法单元242和延迟单元243。
输入单元211、221、231和241可以分别从各存储体接收数据。而且,部分加法单元212、222、232和242的输出可以被反馈到输入单元211、221、231和241。因此,输入单元211、221、231和241可以包括用于选择多个输入数据中的任何一个输入数据的多路复用器mux。
部分加法单元212、222、232和242可以对多个输入数据执行加法运算。部分加法单元212、222、232和242中的每个可以接收从输入单元211、221、231和241输出的所有数据。例如,输入单元211、221、231和241的输出可以连接到集线总线,在该集线总线中,如图2所示,信号之间不发生冲突,因此输入单元的输出可以根据配置值被选择性地传送到部分加法单元212、222、232和242。地址和配置值生成单元110将配置值组cvg传送到并行处理单元130。配置值指示配置值组cvg中的多个主处理配置值cv1、cv2、cv3和cv4。
输入单元211、221、231和241以及部分加法单元212、222、232和242用于将输入数据或计算结果传送到设定路径。部分加法单元212、222、232和242为执行特定计算并且还传送数据的元件。这样的结构可以被称为计算路径网络。在图2中,由a表示的结构为计算路径网络。
延迟单元213、223、233和243将部分加法单元212、222、232和242的输出数据延迟一个周期,并在下一周期将所述延迟的输出数据输入到输入单元211、221、231和241中。延迟单元213、223、233和243使用信号延迟器d延迟与当前时间点相对应的数据,并且在下一周期中将所述延迟的数据传送到输入单元211、221、231和241。换言之,延迟单元420根据时钟,延迟和传送数据。
延迟单元213、223、233和243可以包括用于存储与当前周期相对应的信息的存储器(寄存器)。延迟单元213、223、233和243可以将部分加法单元212、222、232和242的输出值存储在寄存器中,并在下一周期将存储在寄存器中的输出值传送到输入单元211、221、231和241。
此外,使用延迟单元213、223、233和243将多个所需的数据提供给输入单元211、221、231和241,从而以(软件设计者的)编程代码表示的计算处理可以被使用主处理单元210、220、230和240的尽可能多的计算资源并行执行。该处理需要每个周期中的连续并行数据处理功能,以提高并行数据处理计算的效率。部分加法单元的部分加法功能和数据路径配置功能(用于下一周期计算的数据重排功能)一起使用,从而可以进行连续并行数据处理。换言之,利用提供用于一起执行数据重排功能和数据计算功能的结构的部分加法单元,可以配置能够进行连续并行数据处理的并行处理设备,以提高并行数据处理计算的效率。
在图2中,所有延迟单元213、223、233和243由b表示。在并行处理单元200中,与所有延迟单元213、223、233和243相对应的结构被称为延迟处理单元。
决策处理单元接收主处理单元210至240的输出并做出决策。基于主处理单元210至240在当前周期中生成的信息或标记,决策处理单元可以对在下一周期中生成的信息进行决策或控制。假设当前周期为t1,下一周期为t2,则决策处理单元基于主处理单元210至240在t1中生成的信息来执行特定计算或进行决策。决策处理单元可以基于主处理单元210至240的输出结果来确定数据处理是否已经完成。当数据处理还没有完成时,决策处理单元可以将信息传送到地址和配置值生成单元110,使得主处理单元210至240可以执行正在进行的计算或者已经准备好在t2中执行的计算处理。延迟单元213、223、233和243的处理结果可以根据需要存储在存储体中。
图3示出了部分加法单元的操作的示例。图3示出了其中有四个主处理单元的情况的示例。图3的所有主处理单元可以被认为具有4端口路径。在图3中,由p1至p4表示的点对应于输入单元的输出。并且,多个计算单元或部分加法单元212、222、232和242输出计算结果,每个所述结果被传送到点r1、r2、r3和r4。
图3a示出了在4端口路径中执行部分加法功能的示例。部分加法单元212、222、232和242根据主处理配置值cv1、cv2、cv3和cv4中的配置值将由输入单元输出的结果选择性地相加。作为示例,描述了部分加法单元212。部分加法单元212可以接收p1、p2、p3和p4。部分加法单元212总共包括三个加法器。与图3不同,部分加法单元可以具有另一计算结构。部分加法单元212可以将p1、p2,p3和p4以各种组合相加。
对于连续并行处理,部分加法单元212、222、232和242通过延迟单元在下一周期根据配置值、将作为输入数据的选择性部分相加值的输出输入到指定输入单元,所述输入数据是在用于并行处理的编程代码的编译过程中得到的。该处理可以被认为是部分加法单元212、222、232和242以特定顺序对输入数据进行重排的处理。
部分加法单元212、222、232和242执行以下功能:根据部分加法配置值来选择输入单元211、221、231和241的一个或多个输出,并将所选择的一个或多个输出相加。如上所述,从地址和配置值生成单元110接收所述部分加法配置值。作为示例,根据部分加法配置值,第一部分加法单元212、第二部分加法单元222、第三部分加法单元232和第四部分加法单元242可以分别输出p0(第一输入单元211)的输出、p1(第二输入单元221)的输出、p2(第三输入单元231)的输出和p3(第四输入单元241)的输出。作为示例,根据部分加法配置值,第一部分加法单元212、第二部分加法单元222、第三部分加法单元232和第四部分加法单元242可以分别输出p4(第四输入单元241)的输出、p1(第一输入单元211)的输出、p2(第二输入单元221)的输出和p3(第三输入单元231)的输出。作为另一示例,第一部分加法单元212、第二部分加法单元222、第三部分加法单元232和第四部分加法单元242可以分别输出第二输入单元221、第三输入单元231和第四输入单元241的输出之和,第一输入单元211、第三输入单元231和第四输入单元241的输出之和,第一输入单元211、第二输入单元221和第四输入单元241的输出之和,以及第一输入单元211、第二输入单元221和第三输入单元231的输出之和。作为另一示例,根据部分加法配置值,第一部分加法单元212、第二部分加法单元222、第三部分加法单元232和第四部分加法单元242可以分别输出通过将第一输入单元211的输出减去第二输入单元221的输出而获得的值、通过将第二输入单元221的输出减去第三输入单元231的输出而获得的值、通过将第三输入单元231的输出减去第四输入单元241的输出而获得的值、以及通过将第四输入单元241的输出减去第一输入单元211的输出而获得的值。
为此,部分加法单元212、222、232和242可以通过连接到输入单元211、221、231和241的输出的总线来接收输入单元的输出。
图3b示出了4端口路径中的数据传输路径的可能示例。部分加法单元212、222、232和242可以将输入单元p1至p4的输出值的选择性相加结果存储在寄存器中。部分加法单元212、222、232和242可以对输入数据的各种组合执行计算。因此,由部分加法单元212、222、232和242输出的结果通过指定计算或处理可以带来诸如将输入数据p1、p2、p3和p4传送到部分加法单元212、222、232和242的寄存器或其他寄存器的效果。如图3b所示,这产生了就好像部分加法单元212、222、232和242将计算结果传送到各种路径一样的效果。
作为并行处理的示例,下面基于图3所示的结构详细描述示例1。示例1用c语言表示。
<示例1>
假设示例1是顺序执行的,可能需要10个周期来执行一次“do{…}while(cur<10)”。
可以使用图3的单周期并行处理计算功能,在每个周期中连续执行具有类似于示例1的属性的顺序处理代码中的do-while循环。根据图1的地址和配置值生成单元的表(项目)中的值,在下一周期中将r1、r2、r3和r4的计算结果值分别输入到p1、p2、p3和p4。
现代处理器具有多阶段指令管线(multistageinstructionpipeline)。管线中的每个阶段对应于一个处理器,该处理器执行用于执行同一阶段中的不同动作的指令。n阶段管线在完成的不同阶段可以具有多达n条不同的指令。典型的管线处理器具有五个阶段(取指令、解码、执行、存储器访问和回写)。奔腾4处理器具有31阶段管线。在管线进行中,某些处理器可以发出具有指令级并行性的一条或多条指令。这些处理器被称为超标量处理器。只要指令之间没有数据依赖性,就可以将它们分组在一起。
通常,所有指令都能以组为单位无需重排地被并行执行且结果不发生变化的情况称为指令级并行性。从1980年代中期到1990年代中期,指令级并行性主导了计算机体系结构。但是,指令级并行性不能显著克服连续并行数据处理的问题,因此,现在它的使用受到限制。
循环的依赖性取决于前一周期的一个或多个结果。以下循环的数据依赖性阻碍了并行化的进展。例如,在<示例1>中
<示例1>
通常认为该循环不能并行化。这是因为在每个循环中进行循环时,cur依赖于p1、p2、p3和p4。由于每个周期取决于先前的结果,因此该循环无法并行化。
然而,当利用采用图3的路径网络的单周期并行处理设备执行示例1时,可以避免由于并行处理而引起的数据依赖性,并且可以在每个周期中连续执行do-while循环。示例1的单周期并行处理过程可以表示如下。
<示例1的单周期并行处理过程>
通过多个计算器(路径网络)输入数据与多个计算器(路径网络)输出数据之间的同时映射(连接),可以避免由于执行程序代码而引起的数据依赖性。避免数据依赖性使得最大化可以同时并行处理的数据处理量成为可能。多个计算器不限于路径网络。当在概念上满足以下条件时,通过多个计算器输入数据与多个计算器输出数据之间的同时映射(连接),可以避免由于执行程序代码而引起的数据依赖性。
首先,根据以下一致的并行数据处理规则设计的并行处理设备被称为单周期并行处理设备。
假设单周期并行处理设备为多个计算(和数据)处理器,每个计算(和数据)处理器接收至少一个数据。
单周期并行处理设备
(i)排列要处理的数据并在处理之前存储排列的数据。
(ii)在一个周期中计算所存储的数据,然后将结果重排以在下一周期中使用。
(iii)当具有可以在当前一个周期中使用前一周期的重排结果的结构时,可以执行连续并行数据处理。
在这种情况下,单周期并行处理设备可以执行连续并行数据处理,但是除非避免了由于执行代码而引起的数据依赖性,否则难以提高连续并行数据处理的效率。
为了提高并行数据处理的效率,可以通过多个计算器输入数据与多个计算器输出数据之间的同时映射(连接)来避免由于执行代码而引起的数据依赖性。这是因为当[输入数据组]和[由输入数据组的组合组成的输出数据组]同时连接在计算器的可用计算资源中时,可以通过输入数据组与输出数据组之间的连接(映射)而不管数据处理顺序如何,来简单编写预期程序代码。例如,作为过程描述语言的c语言和作为硬件描述语言的verilog具有不同的代码描述方法,但是可以使用两种语言编写预期程序。因此,当在verilog中设计等效于c程序代码的并行处理例程和相应的并行处理编译器时,可以通过多个输入数据与多个输出数据之间的同时映射(连接)来避免由于执行代码而引起的数据依赖性,并且预期程序可被编写。
图4示出了并行处理单元200的操作的示例。
如上所述,存储体从主存储器等接收数据。多个存储体(存储体1、存储体2、存储体3和存储体4)存储排列的数据。存储器映射器可以排列和传送要存储在存储体中的数据。
输入单元211、212、213和214包括多路复用器mux。输入单元211、212、213和214使用多路复用器mux选择从存储体输入的数据和从延迟单元213、223、233和243输入的数据之一。
部分加法单元212、222、232和242可以对从输入单元211、212、213和214输出的数据执行加法运算。如上所述,部分加法单元212、222、232和242可以对输入单元211、212、213和214的输出的可能组合执行各种计算。而且,部分加法单元212、222、232和242中的每个可以将计算结果传送到延迟单元213、223、233和243中的至少一个。
部分加法单元212、222、232和242中的每个将计算结果传送到延迟单元213、223、233和243。在这种情况下,部分加法单元212、222、232和242沿着配置的路径将计算结果传送到延迟单元213、223、233和243中的每个。换言之,可以以设定顺序传送计算结果。因此,部分加法单元212、222、232和242可以按设定顺序排列计算结果,并且将排列的计算结果存储在延迟单元213、223、233和243的寄存器中。可替代地,部分加法单元212、222、232和242可以不执行加法运算,而是可以沿着配置的路径传送输入单元211、212、213和214的输出值,以将新排列的输出值存储在延迟单元213、223、233和243的寄存器中。
(i)部分加法单元212、222、232和242中的每个接收输入单元的输出中的至少一个,并对所接收的输出执行部分加法运算。(ii)部分加法单元212、222、232和242中的每个可以根据配置值执行各种计算组合中的任意一种。(iii)部分加法单元212、222、232和242中的每个将计算结果传送到延迟单元的寄存器。所有延迟单元213、223、233和243的寄存器分别为d1、d2、d3和d4。如上所述,部分加法单元212、222、232和242执行各种计算组合中的任意一种,并将输入数据无变化地传送到寄存器或将计算结果传送到寄存器。在该处理期间,部分加法单元212、222、232和242可以基于配置分别将数据存储在d1、d2、d3和d4中。换言之,部分加法单元212、222、232和242可以以特定顺序对输入数据或输入数据的计算结果进行重排,并将重排的输入数据或计算结果存储在d1、d2、d3和d4中。
同时,部分加法单元可以被称为执行加法运算的计算单元或计算器。
在图4中,由a表示包括部分加法单元212、222、232和242的计算网络。
根据当前周期中输入的配置值,包括在延迟单元213、223、233和243中的多个寄存器的输出数据可以经过(passthrough)多个输入单元和多个计算单元(部分加法单元),并且可以被重新排列(重排)在包括在延迟单元213、223、233和243中的多个寄存器的输入点。根据下一周期中新输入的配置值,所述重排的数据可以通过输入单元被再次提供给计算单元(部分加法单元)。在下一周期中,输入单元211、212、213和214可以选择性地输出从延迟单元213、223、233和243传送的数据。在图4中,由b表示包括延迟单元213、223、233和243的延迟处理单元。
因此,当在第一周期中处理的排列数据可以被用在作为下一周期的第二周期中时,并行处理单元200可以执行连续并行数据处理。
本文中所附的实施例和附图仅代表包括在本发明中的技术精神的一部分。显见的是,在上文和附图的技术精神的范围内,本领域普通技术人员能够容易地设计的修改示例和具体实施方式包括在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!