痴呆症预测装置、预测模型生成装置及痴呆症预测用程序的制作方法
1.本发明涉及痴呆症预测装置、预测模型生成装置以及痴呆症预测用程序,尤其涉及预测患者的痴呆症的病情程度(包括患者罹患痴呆症的可能性)的技术、以及生成该预测中使用的预测模型的技术。
背景技术:
2.痴呆症随着人口的老龄化而不断增加,不仅成为医疗问题,而且成为大的社会问题。在治疗痴呆症时,痴呆症的早期发现及病情程度的评价非常重要。目前,在痴呆症的筛查或病情程度的评价中,日常临床上广泛使用简易精神状态检查(mini mental state examination:mmse)。mmse是由观察定向力、记忆力、注意力(计算力)、语言能力、构成力(图形能力)等的11个项目30分满分的问题构成的认知功能检查。在30分中,27分以下为疑似轻度认知障碍(mild cognitive impairment:mci),23分以下为疑似痴呆症,等等。
3.目前,已知有一种按mmse的评价项目进行评价来判定罹患痴呆症的可能性,并根据该判定结果进行护理支援的系统(例如参照专利文献1)。在专利文献1所记载的系统中,通过mmse调查被护理者的身体或精神健康状态,并根据该调查结果来评价被护理者的健康状态。而且,根据被护理者的健康状态的评价制成语音或影像并分发给护理者,护理者根据分发到的语音或影像来护理被护理者。然后,重新调查被护理者的身体或精神健康状态,重新评价被护理者的健康状态。关于调查,记载了从记忆障碍、定向力、adl(日常生活活动能力)、身体机能这四个项目的观点进行。
4.专利文献1:日本专利特开2002-251467号公报
技术实现要素:
5.mmse作为再现性高的测试而广为人知。然而,当对同一名患者进行多次测试时,患者会通过其练习效果而记住问题的内容,从而无法测出准确的得分。因此,存在难以频繁地测定痴呆症的病情程度这一问题。上述专利文献1所记载的系统完全未考虑到上述mmse不宜反复使用这一问题。
6.本发明是为了解决上述问题而完成的,其目的在于,即使在反复测定痴呆症的病情程度的情况下,也能够得到排除了患者的练习效果的测定结果。
7.为了解决上述问题,在本发明的痴呆症预测装置中,将分别表示痴呆症的病情程度已知的多名患者进行的自由对话的内容的多个文本作为学习用数据输入,对该输入的多个文本进行语素分析而提取多个分解元素,并将多个文本分别按照规定的规则在q个维度上向量化,从而计算出由q个轴分量构成的多个文本向量,并且,将多个分解元素分别按照规定的规则在q个维度上向量化,从而计算出由q个轴分量构成的多个元素向量,进而,通过分别取得多个文本向量与多个元素向量的内积,从而计算出反映多个文本与多个分解元素之间的关联度的关联度指标值。然后,生成用于根据针对一个文本由多个关联度指标值构成的文本指标值组预测痴呆症的病情程度的预测模型。在针对作为预测对象的患者预测痴
呆症的病情程度时,将表示作为预测对象的患者进行的自由对话的内容的文本作为预测用数据输入,并将通过对该输入的预测用数据执行元素提取、文本向量计算、元素向量计算以及指标值计算的各处理而得到的关联度指标值应用于预测模型,从而预测作为预测对象的患者的痴呆症的病情程度。
8.(发明效果)
9.根据如上所述构成的本发明,由于是通过分析患者所进行的自由对话来预测痴呆症的病情程度,因而不需要进行简易精神状态检查(mmse)。因此,即使在反复测定痴呆症的病情程度的情况下,也能够得到排除了患者的练习效果的测定结果(预测结果)。尤其是,若患者已罹患痴呆症,则会在自由对话中发现痴呆症特有的对话特征,由于是在反映上述对话特征的状态下计算出关联度指标值,并使用该关联度指标值生成预测模型,因此,能够从患者进行的自由对话预测痴呆症的病情程度。
附图说明
10.图1是表示第一实施方式涉及的痴呆症预测装置的功能构成例的框图。
11.图2是第一实施方式涉及的文本指标值组的说明图。
12.图3是表示第一实施方式涉及的痴呆症预测装置的动作例的流程图。
13.图4是表示第二实施方式涉及的痴呆症预测装置的功能构成例的框图。
14.图5是例示第二实施方式涉及的词类提取部的处理内容的图。
15.图6是表示第二实施方式涉及的词类提取部所提取的词类的例子的图。
16.图7是表示第三实施方式涉及的痴呆症预测装置的功能构成例的框图。
17.图8是例示第三实施方式涉及的预测模型生成部的处理内容的图。
18.图9是表示第四实施方式涉及的痴呆症预测装置的功能构成例的框图。
19.图10是表示第四实施方式涉及的痴呆症预测装置的功能构成例的框图。
20.图11是表示第五实施方式涉及的痴呆症预测装置的功能构成例的框图。
21.图12是表示痴呆症预测装置的变形例的框图。
22.(符号说明)
23.10、10e:学习用数据输入部
24.11a:单词提取部(元素提取部)
25.11b:词类提取部(元素提取部)
26.12a~12e:向量计算部
27.121:文本向量计算部(元素向量计算部)
28.122:单词向量计算部(元素向量计算部)
29.123:词类向量计算部(元素向量计算部)
30.13a~13c:指标值计算部
31.14a~14e:预测模型生成部
32.15:降维部
33.20:预测用数据输入部
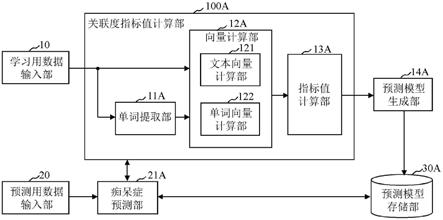
34.21a~21e:痴呆症预测部
35.30a~30e:预测模型存储部
36.100a~100e:关联度指标值计算部
具体实施方式
37.(第一实施方式)
38.以下,根据附图对本发明的第一实施方式进行说明。图1是表示第一实施方式涉及的痴呆症预测装置的功能构成例的框图。第一实施方式涉及的痴呆症预测装置的功能构成包括:学习用数据输入部10、单词提取部11a、向量计算部12a、指标值计算部13a、预测模型生成部14a、预测用数据输入部20以及痴呆症预测部21a。向量计算部12a的更为具体的功能构成包括文本向量计算部121和单词向量计算部122。另外,本实施方式的痴呆症预测装置作为存储介质而具备预测模型存储部30a。此外,以下为了便于说明,将由单词提取部11a、向量计算部12a以及指标值计算部13a构成的部分称为关联度指标值计算部100a。
39.关联度指标值计算部100a是输入与文本相关的文本数据,计算并输出反映文本与其中所包含的单词之间的关联度的关联度指标值的部分。另外,本实施方式的痴呆症预测装置由关联度指标值计算部100a对表示患者进行的自由对话的内容的文本进行分析,利用由此计算出的关联度指标值,并根据患者的自由对话的内容预测患者的痴呆症的病情程度。此外,通过学习用数据输入部10、关联度指标值计算部100a以及预测模型生成部14a构成本发明的预测模型生成装置。
40.本说明书中的“文本”一般是指包含两个以上的由句号分开的一个句子(sentence)的文本。尤其是在本说明书中,将医生与患者之间进行的一系列自由对话(连续对话)中患者多次说话的发言内容(相当于多个句子)综合作为一个文本(text)进行处理。即,针对一个患者的一次自由对话(一系列对话),定义包含多个句子的一个文本。
41.图1所示的各功能块可以由硬件、dsp(digital signal processor:数字信号处理器)、软件中的任一种构成。例如,在由软件构成的情况下,上述各功能块实际上具备计算机的cpu、ram、rom等而构成,并通过运行存储于ram或rom、硬盘或者半导体存储器等记录介质中的程序而实现。
42.学习用数据输入部10将m个文本作为学习用数据输入,该m个文本分别表示痴呆症的病情程度已知的m名(m是2以上的任意整数)患者进行的自由对话的内容。例如,学习用数据输入部10将已通过预先训练过的医生赋予了mmse得分的患者与医生之间进行的自由对话的语音转换成文字数据,并将该文字数据中包含的患者的说话部分的文本作为学习用数据输入。该情况下,针对患者而言已知的痴呆症的病情程度是指mmse得分的值。学习用数据输入部10将分别从m名患者的自由对话中取得的m个文本作为多个学习用数据输入。
43.患者与医生之间的自由对话例如以5~10分钟左右的问诊形式进行。即,以医生向患者提出问题,患者回答该问题的形式反复进行对话。然后,利用麦克风输入此时的对话进行录音,并使用人工转录或自动语音识别技术,将一系列对话(自由对话)的语音转换成文字数据。仅提取该文字数据中患者的说话部分作为学习用数据。此外,也可以在将自由对话的语音转换成文字数据时,仅将患者的说话部分转换成文字数据。
44.单词提取部11a是权利要求中的“元素提取部”的一例,其对通过学习用数据输入部10作为学习用数据输入的m个文本进行分析,从该m个文本中提取n个(n是2以上的任意整数)单词(相当于权利要求中的分解元素)。作为文本的分析方法,例如可以使用公知的语素
分析。在此,单词提取部11a既可以提取通过语素分析分割的所有词类的语素作为单词,也可以仅提取特定词类的语素作为单词。
45.此外,有时m个文本中包含多个相同的单词。该情况下,单词提取部11a并非提取多个相同的单词,而是仅提取一个。即,单词提取部11a所提取的n个单词是指n种单词。其中,所提取的n个单词分别附带有表示其在文本中的出现频率的信息。在此,单词提取部11a也可以计测从m个文本提取出同一单词的频率,并按出现频率由高到低提取n个(n种)单词、或者提取出现频率为阈值以上的n个(n种)单词。
46.罹患痴呆症的患者有时会出现多次重复已说过的话这样的倾向。另外,罹患痴呆症的患者有时也会出现难以自主说话,且针对医生的问题连续说出同样的话语这样的重复对话(鹦鹉学舌)的倾向。因此,通过单词提取部11a从包含上述痴呆症特有的对话特征的自由对话的文本中提取n个单词。
47.向量计算部12a根据m个文本和n个单词计算出m个文本向量和n个单词向量。在此,文本向量计算部121通过将作为单词提取部11a的分析对象的m个文本分别按照规定的规则在q个(q为2以上的任意整数)维度上向量化,从而计算出由q个轴分量构成的m个文本向量。另外,单词向量计算部122通过将单词提取部11a提取出的n个单词分别按照规定的规则在q个维度上向量化,从而计算出由q个轴分量构成的n个单词向量。
48.在本实施方式中,作为一例,如以下那样计算文本向量和单词向量。现在,考虑由m个文本和n个单词构成的集合s=<d∈d,w∈w>。在此,对于各文本d
i
(i=1、2、
……
、m)和各单词w
j
(j=1、2、
……
、n)分别关联文本向量d
i
→
和单词向量w
j
→
(以下,设定符号
“→”
是指向量)。然后,针对任意的单词w
j
和任意的文本d
i
计算出下式(1)所示的概率p(w
j
|d
i
)。
49.【数式1】
[0050][0051]
此外,该概率p(w
j
|d
i
)例如是能够依照论文
“‘
distributed representations of sentences and documents’by quoc le and tomas mikolov,google inc,proceedings of the 31
st international conference on machine learning held in bejing,china on 22-24 june 2014”中公开的概率p而算出的值,其中,该论文中记载了通过段向量对文本、文档进行评价的内容。在该论文中,例如当存在“the”、“cat”、“sat”这三个单词时,预测第四个单词为“on”,并披露了该预测概率p的计算式。该论文中记载的概率p(wt|wt-k、
……
、wt+k)是根据多个单词wt-k、
……
、wt+k预测出另一个单词wt时的正确概率。
[0052]
相对于此,本实施方式中使用的式(1)所示的概率p(w
j
|d
i
)表示从m个文本中的一个文本d
i
预测出n个单词中的一个单词w
j
的正确概率。从一个文本d
i
预测出一个单词w
j
具体是指:当出现某一个文本d
i
时,预测其中包含单词w
j
的可能性。
[0053]
在式(1)中,使用以e为底数、以单词向量w
→
与文本向量d
→
的内积值为指数的指数函数值。然后,计算出根据作为预测对象的文本d
i
和单词w
j
的组合计算出的指数函数值与根据文本d
i
和n个单词w
k
(k=1、2、
……
、n)的各组合计算出的n个指数函数值的合计值的比率,作为从一个文本d
i
预测出一个单词w
j
的正确概率。
[0054]
这里,单词向量w
j
→
与文本向量d
i
→
的内积值也可以说是将单词向量w
j
→
投影至文本向量d
i
→
的方向时的标量值、即单词向量w
j
→
所具有的文本向量d
i
→
的方向上的分量
值。可以认为这是表示单词w
j
对文本d
i
的贡献程度。因此,使用利用上述内积算出的指数函数值求出针对一个单词w
j
算出的指数函数值与针对n个单词w
k
(k=1、2、
……
、n)算出的指数函数值的合计的比率,相当于求出从一个文本d
i
预测出n个单词中的一个单词w
j
的正确概率。
[0055]
此外,由于式(1)中d
i
和w
j
是对称的,因此,也可以计算出从n个单词中的一个单词w
j
预测出m个文本中的一个文本d
i
的概率p(d
i
|w
j
)。从一个单词w
j
预测出一个文本d
i
是指:在出现某一个单词w
j
时预测出该单词w
j
包含在文本d
i
中的可能性。该情况下,文本向量d
i
→
与单词向量w
j
→
的内积值也可以说是将文本向量d
i
→
投影至单词向量w
j
→
的方向时的标量值、即文本向量d
i
→
所具有的单词向量w
j
→
的方向上的分量值。可以认为这是表示文本d
i
对单词w
j
的贡献程度。
[0056]
此外,此处示出了使用以单词向量w
→
与文本向量d
→
的内积值为指数的指数函数值的计算例,但并非必须使用指数函数值。只要是利用了单词向量w
→
与文本向量d
→
的内积值的计算式即可,例如,也可以利用内积值本身(其中,包含进行用于使内积值始终为正值的规定运算(例如内积值+1)的情况)的比率求出概率。
[0057]
接着,向量计算部12a如下式(2)所示计算出使值l最大化这样的文本向量d
i
→
和单词向量w
j
→
,其中,该值l是将通过上述式(1)算出的概率p(w
j
|d
i
)针对所有集合s合计后的值。即,文本向量计算部121和单词向量计算部122针对m个文本和n个单词的全部组合计算出通过上述式(1)算出的概率p(w
j
|d
i
),并将它们的合计值作为目标变量l,计算出使该目标变量l最大化的文本向量d
i
→
和单词向量w
j
→
。
[0058]
【数式2】
[0059][0060]
使针对m个文本和n个单词的所有组合算出的概率p(w
j
|d
i
)的合计值l最大化是指:使从某一个文本d
i
(i=1、2、
……
、m)预测出某一个单词w
j
(j=1、2、
……
、n)的正确概率最大化。即,可以说向量计算部12a计算出该正确概率最大化这样的文本向量d
i
→
和单词向量w
j
→
。
[0061]
在此,在本实施方式中,如上所述,向量计算部12a通过将m个文本d
i
分别在q个维度上向量化而算出由q个轴分量构成的m个文本向量d
i
→
,并通过将n个单词分别在q个维度上向量化而算出由q个轴分量构成的n个单词向量w
j
→
。这相当于使q个轴方向可变,算出上述目标变量l最大化这样的文本向量d
i
→
和单词向量w
j
→
。
[0062]
指标值计算部13a通过分别取得向量计算部12a计算出的m个文本向量d
i
→
与n个单词向量w
j
→
的内积,从而算出反映m个文本d
i
和n个单词w
j
之间的关联度的m
×
n个关联度指标值。在本实施方式中,指标值计算部13a如下式(3)所示取得文本矩阵d与单词矩阵w之积,从而算出将m
×
n个关联度指标值作为各元素的指标值矩阵dw,其中,文本矩阵d将m个文本向量d
i
→
的各q个轴分量(d
11
~d
mq
)作为各元素,单词矩阵w将n个单词向量w
j
→
的各q个轴分量(w
11
~w
nq
)作为各元素。在此,w
t
是单词矩阵的转置矩阵。
[0063]
【数式3】
[0064][0065]
可以说这样计算出的指标值矩阵dw的各元素dw
ij
(i=1、2、
……
、m,j=1、2、
……
、n)表示哪个单词对哪个文本的贡献程度如何。例如,第一行第二列的元素dw
12
是表示单词w2对文本d1的贡献程度如何的值。由此,指标值矩阵dw的各行可以用作评价文本的相似度的行,各列可以用作评价单词的相似度的列。
[0066]
预测模型生成部14a使用指标值计算部13a计算出的m
×
n个关联度指标值生成预测模型,其中,该预测模型用于根据针对一个文本d
i
由n个关联度指标值dw
ij
(j=1、2、
……
、n)构成的文本指标值组预测痴呆症的病情程度。此处预测的痴呆症的病情程度是指mmse的得分的值。即,预测模型生成部14a生成针对根据mmse的得分已知(例如x分)的患者的自由对话算出的文本指标值组预测为尽可能接近于x分的得分这样的预测模型。然后,预测模型生成部14a将生成的预测模型存储至预测模型存储部30a中。
[0067]
图2是用于说明文本指标值组的图。如图2所示,在例如第一个文本d1的情况下,文本指标值组相当于指标值矩阵dw的第一行中包含的n个关联度指标值dw
11
~dw
1n
。同样地,在第二个文本d2的情况下,相当于指标值矩阵dw的第二行中包含的n个关联度指标值dw
21
~dw
2n
。以下,与第m个文本d
m
相关的文本指标值组(n个关联度指标值dw
m1
~dw
mn
)均是同样的。
[0068]
预测模型生成部14a使用指标值计算部13a计算出的m
×
n个关联度指标值dw
11
~dw
mn
,针对各文本d
i
(i=1、2、
……
、m)的文本指标值组分别计算出与痴呆症的病情程度关联的特征量,并根据该计算出的特征量生成用于从一个文本指标值组预测痴呆症的病情程度的预测模型。在此,预测模型生成部14a生成的预测模型是将文本d
i
的文本指标值组作为输入、将mmse的得分作为解而输出的学习模型。
[0069]
例如,预测模型生成部14a生成的预测模型的形态可以是回归模型(以线性回归、逻辑回归、支持向量机等为基础的学习模型)、树模型(以决策树、回归树、随机森林、梯度提升树等为基础的学习模型)、神经网络模型(以感知器、卷积神经网络、递归型神经网络、残差网络、rbf网络、随机性神经网络、脉冲神经网络、复数神经网络等为基础的学习模型)、贝叶斯模型(以贝叶斯推断等为基础的学习模型)、聚类模型(以k近邻法、层次聚类、非层次聚类、主题模型等为基础的学习模型)等中的任意一个。此外,这里所列举的分类模型仅为一例,并不限定于此。
[0070]
预测模型生成部14a在生成预测模型时算出的特征量只要通过规定的算法算出即可。换言之,预测模型生成部14a中计算特征量的计算方法可以任意地设计。例如,预测模型生成部14a对于各文本d
i
的文本指标值组分别以使通过加权计算得到的值接近于表示痴呆
症的病情程度的已知值(mmse的得分)的方式进行规定的加权计算,并使用针对文本指标值组的加权值作为特征量,生成用于从文本d
i
的文本指标值组预测痴呆症的病情程度(mmse的得分)的预测模型。
[0071]
即,针对由指标值矩阵dw的第一行中包含的n个关联度指标值dw
11
~dw
1n
构成的第一个文本d1的文本指标值组,以使a
11
·
dw
11
+a
12
·
dw
12
+
……
+a
1n
·
dw
1n
≈mmse的已知得分的方式算出加权值{a
11
、a
12
、
……
、a
1n
}作为特征量。另外,针对由指标值矩阵dw的第二行中包含的n个关联度指标值dw
21
~dw
2n
构成的第二个文本d2的文本指标值组,以使a
21
·
dw
21
+a
22
·
dw
22
+
……
+a
2n
·
dw
2n
≈mmse的已知得分的方式算出加权值{a
21
、a
22
、
……
、a
2n
}作为特征量。以下同样地,针对第m个文本d
m
的文本指标值组,以使a
m1
·
dw
m1
+a
m2
·
dw
m2
+
……
+a
mn
·
dw
m
n≈mmse的已知得分的方式算出加权值{a
m1
、a
m2
、
……
、a
mn
}作为特征量。然后,生成上述特征量分别与mmse的已知得分相关联这样的预测模型。
[0072]
此外,此处说明了将m组加权值{a
11
、a
12
、
……
、a
1n
}、
……
、{a
m1
、a
m2
、
……
、a
mn
}分别用作特征量的例子,但并不限定于此。例如,也可以提取出一个或多个加权值、或者使用了该多个加权值的规定的运算值等作为特征量,其中,该一个或多个加权值具有从与m名患者相关的m个学习用数据得到的m个文本指标值组中的、从mmse得分相同的患者的学习用数据得到的文本指标值组彼此共通的特征。
[0073]
预测用数据输入部20将分别表示作为预测对象的m
′
名(m
′
是1以上的任意整数)患者进行的自由对话的内容的m
′
个文本作为预测用数据输入。即,预测用数据输入部20将mmse得分未知的患者与医生之间进行的自由对话的语音转换成文字数据,并将该文字数据中包含的患者的讲话部分的文本作为预测用数据输入。从预测对象的患者与医生的自由对话取得m
′
个文本的方法,与从学习对象的患者与医生的自由对话取得m个文本的上述方法是同样的。
[0074]
作为预测对象的患者可以是初诊患者,也可以是被诊断为疑似患有痴呆症的复诊患者。在将初诊患者作为预测对象的情况下,不用对患者实施mmse,仅在患者与医生之间通过问诊进行自由对话,便可如下所述预测该患者是否疑似患有痴呆症、或者患有痴呆症时的病情程度。另一方面,在将复诊患者作为预测对象的情况下,也不用对该患者实施mmse,仅在患者与医生之间通过问诊进行自由对话便可预测痴呆症的病情程度。由此,能够不受患者针对mmse的练习效果影响地判断症状是改善还是恶化。
[0075]
痴呆症预测部21a通过将针对预测用数据输入部20输入的预测用数据执行单词提取部11a、文本向量计算部121、单词向量计算部122以及指标值计算部13a的处理而得到的关联度指标值应用于预测模型生成部14a生成的预测模型(存储在预测模型存储部30a中的预测模型),从而预测作为预测对象的m
′
名患者的痴呆症的病情程度。
[0076]
例如,在通过预测用数据输入部20输入了从mmse得分未知的m
′
名患者的自由对话中取得的m
′
个文本作为预测用数据的情况下,通过根据痴呆症预测部21a的指示对该m
′
个文本执行关联度指标值计算部100a的处理,从而得到m
′
个文本指标值组。痴呆症预测部21通过将关联度指标值计算部100a算出的m
′
个文本指标值组作为输入数据提供给预测模型,从而分别预测m
′
名患者的痴呆症的病情程度。
[0077]
在该预测时,单词提取部11a从通过预测用数据输入部20作为预测用数据输入的m
′
个文本中提取n个单词。单词提取部11a在预测时从m
′
个文本中提取的单词的数量与单词
提取部11a在学习时从m个文本中提取的单词的数量n相同。此外,例如有时m
′
=1,即从基于一名患者的自由对话的一个文本中提取n个单词。因此,优选预先预想到5~10分钟左右的问诊形式的自由对话中一名患者可能说出的单词的标准种类来确定n的值,以免产生从预测用数据的一个文本中提取出的n个单词与从学习用数据的m个文本中提取出的n个单词全部不重复(重复是指单词相同)的事态。
[0078]
另外,在预测时,文本向量计算部121通过将m
′
个文本分别按照规定的规则在q个维度上向量化,从而计算出由q个轴分量构成的m
′
个文本向量。单词向量计算部122通过将n个单词分别按照规定的规则在q个维度上向量化,从而计算出由q个轴分量构成的n个单词向量。指标值计算部13a通过分别取得m
′
个文本向量与n个单词向量的内积,从而计算出反映m
′
个文本与n个单词之间的关联度的m
′×
n个关联度指标值。痴呆症预测部21a通过将指标值计算部13a计算出的m
′
个关联度指标值应用于预测模型存储部30a中存储的预测模型,从而预测作为预测对象的m
′
名患者的痴呆症的病情程度。
[0079]
此外,为了减轻预测时的运算负荷,也可以省略通过单词向量计算部122计算单词向量,而预先存储学习时计算出的n个单词向量,并在预测时使用该n个单词向量。这样,预测时读出并利用单词向量计算部122在学习时算出的n个单词向量的处理也作为对预测用数据执行文本向量计算部122的处理的一个方式而包含在内。
[0080]
图3是表示上述那样构成的第一实施方式涉及的痴呆症预测装置的动作例的流程图。图3中的(a)示出生成预测模型的学习时的动作例,(b)示出使用生成的预测模型预测痴呆症的病情程度的预测时的动作例。
[0081]
在图3中的(a)所示的学习时,首先,学习用数据输入部10将分别表示痴呆症的病情程度(mmse得分)已知的m名患者进行的自由对话的内容的m个文本作为学习用数据输入(步骤s1)。单词提取部11a对学习用数据输入部10输入的m个文本进行分析,从该m个文本中提取n个单词(步骤s2)。
[0082]
接着,向量计算部12a根据学习用数据输入部10输入的m个文本和单词提取部11a提取出的n个单词,计算出m个文本向量d
i
→
和n个单词向量w
j
→
(步骤s3)。然后,指标值计算部13a分别取得m个文本向量d
i
→
与n个单词向量w
j
→
的内积,从而计算出反映m个文本d
i
和n个单词w
j
之间的关联度的m
×
n个关联度指标值(将m
×
n个关联度指标值作为各元素的指标值矩阵dw)(步骤s4)。
[0083]
进而,预测模型生成部14a使用如上所述由关联度指标值计算部100a从与m名患者相关的学习用数据算出的m
×
n个关联度指标值,生成用于根据针对一个文本d
i
由n个关联度指标值dw
ij
构成的文本指标值组预测痴呆症的病情程度的预测模型,并将生成的预测模型存储至预测模型存储部30a中(步骤s5)。至此,学习时的动作结束。
[0084]
在图3中的(b)所示的预测时,首先,预测用数据输入部20将分别表示作为预测对象的m
′
名患者进行的自由对话的内容的m
′
个文本作为预测用数据输入(步骤s11)。痴呆症预测部21a将预测用数据输入部20输入的预测用数据供给至关联度指标值计算部100a,并指示计算出关联度指标值。
[0085]
根据该指示,单词提取部11a对预测用数据输入部20输入的m
′
个文本进行分析,从该m
′
个文本中提取n个单词(步骤s12)。接着,向量计算部12a根据预测用数据输入部20输入的m
′
个文本和单词提取部11a提取出的n个单词,计算出m
′
个文本向量d
i
→
和n个单词向量w
j
→
(步骤s13)。
[0086]
然后,指标值计算部13a分别取得m
′
个文本向量d
i
→
与n个单词向量w
j
→
的内积,从而计算出反映m
′
个文本d
i
与n个单词w
j
之间的关联度的m
′×
n个关联度指标值(将m
′×
n个关联度指标值作为各元素的指标值矩阵dw)(步骤s14)。指标值计算部13a将计算出的m
′×
n个关联度指标值供给至痴呆症预测部21a。
[0087]
痴呆症预测部21a通过将从关联度指标值计算部100a供给的m
′×
n个关联度指标值应用于预测模型存储部30a中存储的预测模型,从而预测作为预测对象的m
′
名患者的痴呆症的病情程度(步骤s15)。由此,预测时的动作结束。
[0088]
如以上详细说明,在第一实施方式中,通过将表示痴呆症的病情程度已知的患者所进行的自由对话的内容的m个文本作为学习用数据输入,并计算从该输入的文本计算出的文本向量与从文本内包含的单词计算出的单词向量的内积,从而计算出反映文本与单词之间的关联度的关联度指标值,并使用该关联度指标值生成预测模型。另外,在针对作为预测对象的患者预测痴呆症的病情程度时,通过将表示作为预测对象的患者所进行的自由对话的内容的m
′
个文本作为预测用数据输入,并将从该输入的预测用数据同样地计算出的关联度指标值应用于预测模型,从而预测作为预测对象的患者的痴呆症的病情程度。
[0089]
根据如此构成的第一实施方式,由于是通过分析患者所进行的自由对话来预测痴呆症的病情程度,因而不需要进行简易精神状态检查(mmse)。因此,即使在反复测定痴呆症的病情程度的情况下,也能够得到排除了患者的练习效果的测定结果(预测结果)。尤其是,若患者已罹患痴呆症,则会在自由对话中发现包含重复发言的单词等的痴呆症特有的对话特征,由于是在反映上述对话特征的状态下计算出关联度指标值,并使用该关联度指标值生成预测模型,因此,能够根据患者进行的自由对话预测痴呆症的病情程度。
[0090]
(第二实施方式)
[0091]
接着,根据附图对本发明的第二实施方式进行说明。图4是表示第二实施方式涉及的痴呆症预测装置的功能构成例的框图。在该图4中,标注了与图1所示的符号相同符号的部件具有相同的功能,故此处省略重复的说明。
[0092]
如图4所示,第二实施方式涉及的痴呆症预测装置取代关联度指标值计算部100a、预测模型生成部14a、痴呆症预测部21a以及预测模型存储部30a而具备关联度指标值计算部100b、预测模型生成部14b、痴呆症预测部21b以及预测模型存储部30b。第二实施方式涉及的关联度指标值计算部100b取代单词提取部11a、向量计算部12a以及指标值计算部13a而具备词类提取部11b、向量计算部12b以及指标值计算部13b。向量计算部12b的更为具体的功能构成取代单词向量计算部122而具备词类向量计算部123。此外,通过学习用数据输入部10、关联度指标值计算部100b以及预测模型生成部14b构成本发明的预测模型生成装置。
[0093]
第二实施方式涉及的关联度指标值计算部100b是输入与第一实施方式相同的与文本相关的文本数据,计算并输出反映文本与其中所包含的各语素的词类之间的关联度的关联度指标值。
[0094]
词类提取部11b是权利要求中的“元素提取部”的一例,对学习用数据输入部10作为学习用数据输入的m个文本进行分析,从该m个文本中提取p个(p为2以上的任意整数)词类(相当于权利要求中的分解元素)。作为文本的分析方法,例如可以使用公知的语素分析。
在此,针对通过语素分析而被分割的各语素,词类提取部11b既可以如图5中的(a)那样针对每个单一语素提取一个词类,也可以如图5中的(b)那样针对连续的多个语素提取一组词类。
[0095]
此外,本实施方式中提取的词类不仅是动词、形容词、形容动词、名词、代词、数词、连体词、副词、连词、感叹词、助动词、助词这样的大类,还如图6所示提取细分至中类、小类、细类的词类。图6示出了词类提取部11b提取出的词类的一例。此处所示的词类仅为一例,本发明并不限定于此。
[0096]
此外,在m个文本中,有时包含多个相同的词类(或者相同的词类组)。该情况下,词类提取部11b并非提取多个相同的词类(或者相同的词类组)而是仅提取一个。即,词类提取部11b所提取的p个(包含p组的概念。下同)词类是指p种词类。其中,提取出的p个词类分别附带有表示其在文本中的出现频率的信息。
[0097]
在罹患痴呆症的患者中,有时会出现想不起专有名词而多用“它(
あれ
)”、“这个(
これ
)”、“那个(
それ
)”等的指示词的倾向。另外,在罹患痴呆症的患者中,有时会出现无法说出下一句话而多用“那个
……
(
あの
)”、“嗯
……
(
うーん
)”、“唉
……
(
えー
)”等语气词的倾向。因此,根据上述痴呆症特有的对话特征,存在会在自由对话的文本中多次出现的相同词类。因此,通过词类提取部11b从包含上述痴呆症特有的对话特征的自由对话的文本中提取p个词类。
[0098]
向量计算部12b从m个文本和p个词类计算出m个文本向量和p个词类向量。在此,文本向量计算部121通过将作为词类提取部11b的分析对象的m个文本分别按照规定的规则在q个维度上进行向量化,从而计算出由q个轴分量构成的m个文本向量。另外,词类向量计算部123通过将词类提取部11b提取出的p个词类分别按照规定的规则在q个维度上进行向量化,从而计算出由q个轴分量构成的p个词类向量。
[0099]
文本向量和词类向量的计算方法与第一实施方式相同。即,在第二实施方式中,向量计算部12b考虑由m个文本和p个词类构成的集合s=<d∈d,h∈h>。在此,对各文本d
i
(i=1、2、
……
、m)和各词类h
j
(j=1、2、
……
、p)分别关联文本向量d
i
→
和词类向量h
j
→
。然后,向量计算部12b针对m个文本和p个词类的所有组合计算出与上式(1)同样算出的概率p(h
j
|d
i
),并将它们的合计值作为目标变量l,计算出使该目标变量l最大化的文本向量d
i
→
和词类向量h
j
→
。
[0100]
指标值计算部13b通过分别取得由向量计算部12b算出的m个文本向量d
i
→
与p个词类向量h
j
→
的内积,从而计算出反映m个文本d
i
和p个词类h
j
之间的关联度的m
×
p个关联度指标值。在第二实施方式中,指标值计算部13b如下式(4)所示取得文本矩阵d与词类矩阵h之积,从而算出将m
×
p个关联度指标值作为各元素的指标值矩阵dh,其中,文本矩阵d将m个文本向量d
i
→
的各q个轴分量(d
11
~d
mq
)作为各元素,词类矩阵h将p个词类向量h
j
→
的各q个轴分量(h
11
~h
pq
)作为各元素。在此,h
t
是词类矩阵的转置矩阵。
[0101]
【数式4】
[0102][0103]
预测模型生成部14b使用指标值计算部13b计算出的m
×
p个关联度指标值生成预测模型,其中,该预测模型用于根据针对一个文本d
i
由p个关联度指标值dh
ij
(j=1、2、
……
、p)构成的文本指标值组预测痴呆症的病情程度(mmse得分值)。即,预测模型生成部14b通过与第一实施方式中说明的方法相同的方法,生成针对根据mmse得分已知(例如x分)的患者的自由对话计算出的文本指标值组预测为尽可能接近于x分的得分这样的预测模型。然后,预测模型生成部14b将生成的预测模型存储至预测模型存储部30b中。
[0104]
痴呆症预测部21b通过将针对预测用数据输入部20输入的预测用数据执行词类提取部11b、文本向量计算部121、词类向量计算部123以及指标值计算部13b的处理而得到的关联度指标值应用于预测模型生成部14b生成的预测模型(存储在预测模型存储部30b中的预测模型),从而预测作为预测对象的m
′
名患者的痴呆症的病情程度。
[0105]
如以上详细说明,在第二实施方式中,通过将表示痴呆症的病情程度已知的患者所进行的自由对话的内容的m个文本作为学习用数据输入,并计算从该输入的文本计算出的文本向量与从文本内包含的语素的词类计算出的词类向量的内积,从而计算出反映文本与词类之间的关联度的关联度指标值,并使用该关联度指标值生成预测模型。另外,在针对作为预测对象的患者预测痴呆症的病情程度时,通过将表示作为预测对象的患者所进行的自由对话的内容的m
′
个文本作为预测用数据输入,并将从该输入的预测用数据同样地计算出的关联度指标值应用于预测模型,从而预测作为预测对象的患者的痴呆症的病情程度。
[0106]
在如此构成的第二实施方式中,由于是通过分析患者所进行的自由对话来预测痴呆症的病情程度,因而也不需要进行简易精神状态检查(mmse)。因此,即使在反复测定痴呆症的病情程度的情况下,也能够得到排除了患者的练习效果的测定结果(预测结果)。尤其是,若患者已罹患痴呆症,则会在自由对话中发现包含多个规定词类的语素的痴呆症特有的对话特征,由于是在反映上述对话特征的状态下计算出关联度指标值,并使用该关联度指标值生成预测模型,因而能够从患者进行的自由对话预测痴呆症的病情程度。
[0107]
(第三实施方式)
[0108]
接着,根据附图对本发明的第三实施方式进行说明。图7是表示第三实施方式涉及的痴呆症预测装置的功能构成例的框图。在该图7中,标注了与图4所示的符号相同符号的部件具有相同的功能,故此处省略重复的说明。第三实施方式使用第一实施方式中说明的根据文本向量和单词向量计算出的指标值矩阵dw、和第二实施方式中说明的根据文本向量和词类向量计算出的指标值矩阵dh这两者。
[0109]
如图7所示,第三实施方式涉及的痴呆症预测装置取代关联度指标值计算部100b、
预测模型生成部14b、痴呆症预测部21b以及预测模型存储部30b而具备关联度指标值计算部100c、预测模型生成部14c、痴呆症预测部21c以及预测模型存储部30c。第三实施方式涉及的关联度指标值计算部100c具备单词提取部11a和词类提取部11b,并取代向量计算部12b和指标值计算部13b而具备向量计算部12c和指标值计算部13c。向量计算部12c的更为具体的功能构成具备文本向量计算部121、单词向量计算部122以及词类向量计算部123。此外,通过学习用数据输入部10、关联度指标值计算部100c以及预测模型生成部14c构成本发明的预测模型生成装置。
[0110]
指标值计算部13c如上述式(3)所示分别取得m个文本向量d
i
→
与n个单词向量w
j
→
的内积,从而计算出反映m个文本d
i
和n个单词w
j
之间的关联度的m
×
n个关联度指标值dw
ij
(第一评价值矩阵dw)。此外,指标值计算部13c如上述式(4)所示分别取得m个文本向量d
i
→
与p个词类向量h
j
→
的内积,从而计算出反映m个文本d
i
与p个词类h
j
之间的关联度的m
×
p个关联度指标值dh
ij
(第二评价值矩阵dh)。
[0111]
预测模型生成部14c使用指标值计算部13c计算出的m
×
n个关联度指标值dw
ij
及m
×
p个关联度指标值dh
ij
生成预测模型,其中,该预测模型用于根据针对一个文本d
i
由n个关联度指标值构成的文本指标值组dw
ij
(j=1、2、
……
、n)及由p个关联度指标值构成的文本指标值组dh
ij
(j=1、2、
……
、p)预测痴呆症的病情程度(mmse的得分值)。然后,预测模型生成部14c将生成的预测模型存储至预测模型存储部30c中。
[0112]
在此,关于预测模型生成部14c如何使用两组文本指标值组dw
ij
、dh
ij
来生成预测模型,可以任意进行设计。例如,如图8中的(a)所示,可以将文本与单词之间的第一指标值矩阵dw和文本与词类之间的第二指标值矩阵dh沿横向(行方向)排列,并将属于同一行i的文本指标值组dw
ij
、dh
ij
连接,生成包含(n+p)个关联度指标值的一个文本指标值组,并生成用于根据该文本指标值组预测痴呆症的病情程度的预测模型。
[0113]
或者,如图8中的(b)所示,也可以将文本与单词之间的第一指标值矩阵dw中包含的第i行的文本指标值组dw
ij
和文本与词类之间的第二指标值矩阵dh中包含的同样第i行的文本指标值组dh
ij
沿纵向(列方向)排列,生成2
×
n维的文本指标值组矩阵,并生成用于根据该文本指标值组矩阵预测痴呆症的病情程度的预测模型。在图8的(b)的例子中,预想为n>p,针对2
×
n维的文本指标值组矩阵中的第二行的矩阵成分,将文本指标值组dh
ij
的值设定为左对齐,并将该第二行的左端起超过p个的矩阵分量的值全部设为0。
[0114]
此外,也可以通过对m
×
n维的第一指标值矩阵dw进行之后第四实施方式中所述的降维处理而生成m
×
p维的第一指标值矩阵dw
svd
,将该降维后的第一指标值矩阵dw
svd
内包含的第i行的文本指标值组dw
ij
(j=1~p)和第二指标值矩阵dh内包含的同样第i行的文本指标值组dh
ij
(j=1~p)沿纵向(列方向)排列而生成2
×
p维的文本指标值组矩阵,并生成用于根据该文本指标值组矩阵预测痴呆症的病情程度的预测模型。
[0115]
进而,作为又一例,也可以如图8中的(c)所示,将文本与单词之间的第一指标值矩阵dw中包含的第i行的文本指标值组dw
ij
作为1
×
n维的第一文本指标值组矩阵,将文本与词类之间的第二指标值矩阵dh中包含的同样第i行的文本指标值组dh
ij
作为n
×
1维的第二文本指标值组矩阵(其中,将超过p个但不足n个的不足部分的矩阵分量的值设为0),并计算出第一文本指标值组矩阵与第二文本指标值组矩阵的内积。然后,生成用于根据计算出的值预测痴呆症的病情程度的预测模型。
[0116]
该情况下,也可以对文本与单词之间的第一指标值矩阵dw进行降维而生成m
×
p维的第一指标值矩阵dw
svd
,将该降维后的第一指标值矩阵dw
svd
内包含的第i行的文本指标值组dw
ij
作为1
×
p维的第一文本指标值组矩阵,将文本与词类之间的第二指标值矩阵dh内包含的同样为第i行的文本指标值组dh
ij
作为p
×
1维的第二文本指标值组矩阵,计算出第一文本指标值组矩阵与第二文本指标值组矩阵的内积。
[0117]
痴呆症预测部21c通过将针对预测用数据输入部20输入的预测用数据执行单词提取部11a、词类提取部11b、文本向量计算部121、单词向量计算部122、词类向量计算部123以及指标值计算部13c的处理而得到的关联度指标值应用于预测模型生成部14c生成的预测模型(存储在预测模型存储部30c中的预测模型),从而预测作为预测对象的m
′
名患者的痴呆症的病情程度。
[0118]
如以上详细说明,在第三实施方式中,通过将表示痴呆症的病情程度已知的患者所进行的自由对话的内容的m个文本作为学习用数据输入,并计算出从该输入的文本计算出的文本向量与从文本内包含的单词计算出的单词向量的内积,从而计算出反映文本与单词之间的关联度的关联度指标值,并且,计算出从该输入的文本计算出的文本向量与从文本内包含的语素的词类计算出的词类向量的内积,从而计算出反映文本与词类之间的关联度的关联度指标值,并使用该两个关联度指标值生成预测模型。另外,在针对作为预测对象的患者预测痴呆症的病情程度时,通过将表示作为预测对象的患者所进行的自由对话的内容的m
′
个文本作为预测用数据输入,并将从该输入的预测用数据同样地计算出的关联度指标值应用于预测模型,从而预测作为预测对象的患者的痴呆症的病情程度。
[0119]
在如此构成的第三实施方式中,由于是通过分析患者所进行的自由对话来预测痴呆症的病情程度,因而也不需要进行简易精神状态检查(mmse)。因此,即使在反复测定痴呆症的病情程度的情况下,也能够得到排除了患者的练习效果的测定结果(预测结果)。尤其是,在第三实施方式中,由于是针对自由对话中使用的单词和词类在反映痴呆症特有的对话特征的状态下计算出关联度指标值,并使用该关联度指标值生成预测模型,因此,能够更为准确地从患者进行的自由对话预测痴呆症的病情程度。
[0120]
(第四实施方式)
[0121]
接着,根据附图对本发明的第四实施方式进行说明。图9是表示第四实施方式涉及的痴呆症预测装置的功能构成例的框图。在该图9中,标注了与图1所示的符号相同符号的部件具有相同的功能,故此处省略重复的说明。此外,以下作为第一实施方式的变形例而对第四实施方式进行说明,但如图10中的(a)、(b)分别所示,第四实施方式同样可以应用为第二实施方式的变形例或者第三实施方式的变形例。
[0122]
如图9所示,第四实施方式涉及的痴呆症预测装置取代关联度指标值计算部100a、预测模型生成部14a、痴呆症预测部21a以及预测模型存储部30a而具备关联度指标值计算部100d、预测模型生成部14d、痴呆症预测部21d以及预测模型存储部30d。第四实施方式涉及的关联度指标值计算部100d除了图1所示的构成之外还具备降维部15。此外,通过学习用数据输入部10、关联度指标值计算部100d以及预测模型生成部14d构成本发明的预测模型生成装置。
[0123]
降维部15通过使用指标值计算部13a计算出的m
×
n个关联度指标值进行规定的降维处理,从而计算出m
×
k个(k是满足1≤k<n的任意整数)关联度指标值。降维处理例如可
以使用作为矩阵分解的方法而公知的奇异值分解(singular value decomposition:svd)。
[0124]
即,降维部15将如上述式(3)那样算出的评价值矩阵dw分解成三个矩阵u、s、v。在此,矩阵u是m
×
k维的左奇异矩阵,各列是dw*dw
t
的特征向量(dw
t
表示评价值矩阵dw的转置矩阵)。矩阵s是k
×
k维的正方矩阵,对角矩阵分量表示评价值矩阵dw的奇异值,除此以外的值全部为0。矩阵v是k
×
n维的右奇异矩阵,各行是dw
t
*dw的特征向量。此外,压缩后的维度k既可以是预先确定的固定值,也可以指定任意的值。
[0125]
降维部15通过利用上述那样分解的三个矩阵中的右奇异矩阵v的转置矩阵v
t
转换评价值矩阵dw,从而对评价值矩阵dw进行降维。即,通过计算m
×
n维的评价值矩阵dw与n
×
k维的右奇异转置矩阵v
t
的内积,将m
×
n维的评价值矩阵dw降维为m
×
k维的评价值矩阵dw
svd
(dw
svd
=dw*v
t
)。此外,dw
svd
表示将评价值矩阵dw通过svd进行降维后的矩阵,满足dw≈u*s*v=dw
svd
*v的关系。
[0126]
这样,通过使用svd的方法对评价值矩阵dw进行降维,能够尽可能不损害评价值矩阵dw所表达的特征地对评价值矩阵dw进行低秩近似。此外,此处说明了利用右奇异矩阵v的转置矩阵v
t
转换评价值矩阵dw的例子,但在m的值与n的值一致的情况下,也可以利用左奇异矩阵u来转换评价值矩阵dw(dw
svd
=dw*u)。
[0127]
预测模型生成部14d使用经过降维部15降维后的m
×
k个关联度指标值生成预测模型,其中,该预测模型用于根据针对一个文本d
i
由k个关联度指标值dw
ij
(i=1、2、
……
、k)构成的文本指标值组预测痴呆症的病情程度。然后,预测模型生成部14d将生成的预测模型存储至预测模型存储部30d中。
[0128]
痴呆症预测部21d通过将针对预测用数据输入部20输入的预测用数据执行单词提取部11a、文本向量计算部121、单词向量计算部122、指标值计算部13a以及降维部15的处理而得到的关联度指标值应用于预测模型生成部14d生成的预测模型(存储在预测模型存储部30d中的预测模型),从而预测作为预测对象的m
′
名患者的痴呆症的病情程度。
[0129]
在上述第一实施方式中,需要预想到5~10分钟左右的问诊形式的自由对话中一名患者说出的单词的标准种类,并选择n的值。当n的值小时,作为预测对象的一名患者说出的单词与从学习用数据的文本提取出的n种单词的重复少,有可能连一个重复都没有。另外,不包含在n个中的单词(单词提取部11未提取出的单词)的信息未加入评价值矩阵dw中。因此,n的值越小,则预测的精度越差。另一方面,若选择非常大的n值,则重复为0个的可能性变少,不包含在n个内的单词也变少,但矩阵的大小变大,计算量增加。另外,出现频率低的单词也作为特征量而包含在内,容易引发过度学习。
[0130]
相对于此,根据第四实施方式,能够将m个文本中包含的多个(例如所有)单词作为n个单词提取出并生成评价值矩阵dw,并算出在反映该评价值矩阵dw所表达的特征的状态下降维的评价值矩阵dw
svd
。由此,能够在少量的计算负荷下,更加准确地通过学习生成预测模型和使用该生成的预测模型预测痴呆症的病情程度。
[0131]
此外,此处仅说明了作为降维的一例而使用svd的例子,但本发明并不限定于此。例如,也可以使用主成分分析(principal component analysis:pca)等其他的降维方法。
[0132]
另外,在图9中,说明了将第一实施方式中生成的文本与单词之间的评价值矩阵dw进行降维的例子,但是,在如图10中的(a)所示对第二实施方式中生成的文本与词类之间的评价值矩阵dh进行降维时也能够同样地进行。相对于此,在如图10中的(b)所示对第三实施
方式中生成的第一评价值矩阵dw和第二评价值矩阵dh进行降维时,能够以下述方式进行。
[0133]
例如,能够分开对第一评价值矩阵dw和第二评价值矩阵dh分别进行降维。即,将m
×
n维的第一评价值矩阵dw降维为m
×
k维的第一评价值矩阵dw
svd
,并将m
×
p维的第二评价值矩阵dh降维为m
×
k维的第二评价值矩阵dh
svd
。作为另一例,也可以如图8中的(a)所示将第一指标值矩阵dw与第二指标值矩阵dh沿横向排列生成m
×
(n+p)维的一个指标值矩阵,并将该生成的指标值矩阵降维为m
×
k维的评价值矩阵。
[0134]
(第五实施方式)
[0135]
接着,根据附图对本发明的第五实施方式进行说明。图11是表示第五实施方式涉及的痴呆症预测装置的功能构成例的框图。在该图11中,标注了与图1所示的符号相同符号的部件具有相同的功能,故此处省略重复的说明。此外,以下作为第一实施方式的变形例而对第五实施方式进行说明,但第五实施方式同样也可以应用为第二实施方式至第四实施方式的任一方式的变形例。
[0136]
如图11所示,第四实施方式涉及的痴呆症预测装置取代学习用数据输入部10、预测模型生成部14a、痴呆症预测部21a以及预测模型存储部30a而具备学习用数据输入部10e、预测模型生成部14e、痴呆症预测部21e以及预测模型存储部30e。此外,通过学习用数据输入部10e、关联度指标值计算部100a以及预测模型生成部14e构成本发明的预测模型生成装置。
[0137]
学习用数据输入部10e将分别表示痴呆症的多个评价项目各个中的痴呆症的病情程度已知的m名患者进行的自由对话的内容的m个文本作为学习用数据输入。痴呆症的多个评价项目各个中的病情程度是指mmse的五个评价项目、即定向力、记忆力、注意力(计算力)、语言能力、构成力(图形能力)各项目的得分值。
[0138]
预测模型生成部14e使用关联度指标值计算部100a计算出的m
×
n个关联度指标值生成预测模型,其中,该预测模型用于根据针对一个文本d
i
由n个关联度指标值dw
ij
(j=1、2、
……
、n)构成的文本指标值组预测痴呆症的各评价项目的病情程度。此处预测的痴呆症的病情程度是指mmse的五个评价项目各自的得分值。
[0139]
即,预测模型生成部14e生成如下预测模型,即:针对根据mmse的定向力、记忆力、注意力、语言能力、构成力的各得分已知(例如分别为x1分、x2分、x3分、x4分、x5分)的患者的自由对话算出的文本指标值组,在各评价项目分别预测为尽可能接近于x1分、x2分、x3分、x4分、x5分的得分。然后,预测模型生成部14e将生成的预测模型存储至预测模型存储部30e中。
[0140]
预测模型生成部14e使用指标值计算部13a计算出的m
×
n个关联度指标值dw
11
~dw
mn
,针对各文本d
i
(i=1、2、
……
、m)的文本指标值组分别按评价项目计算出与痴呆症的各评价项目的病情程度关联的特征量,并根据该计算出的特征量生成用于从一个文本指标值组预测痴呆症的各评价项目的病情程度的预测模型。在此,预测模型生成部14e生成的预测模型是将文本d
i
的文本指标值组作为输入,将mmse的各评价项目的得分作为解而输出的学习模型。
[0141]
在第五实施方式中,预测模型生成部14e生成预测模型时算出的特征量只要通过规定的算法进行计算即可。换言之,预测模型生成部14e中计算特征量的计算方法可以任意地设计。例如,预测模型生成部15e对于各文本d
i
的文本指标值组分别按评价项目以使通过
加权计算得到的值接近于表示痴呆症的各评价项目的病情程度的已知值(mmse的各评价项目的得分)的方式进行规定的加权计算,并使用针对文本指标值组的加权值作为各评价项目的特征量,生成用于根据文本d
i
的文本指标值组预测痴呆症的各评价项目的病情程度(mmse的各评价项目的得分)的预测模型。
[0142]
例如,预测模型生成部14e生成如下的预测模型,该预测模型将相对于文本d
i
的文本指标值组的n个加权值{a
i1
、a
i2
、
……
、a
in
}中的任意一个或多个加权值作为特征量而预测第一评价项目(定向力)的得分,将另外一个或多个加权值作为特征量而预测第二评价项目(记忆力)的得分,以下同样将进而另外一个或多个加权值作为特征量而预测第三评价项目~第五评价项目(注意力、语言能力、构成力)的得分。
[0143]
痴呆症预测部21e将通过对预测用数据输入部20输入的预测用数据执行单词提取部11a、文本向量计算部121、单词向量计算部122以及指标值计算部13a的处理而得到的关联度指标值应用于预测模型生成部14e生成的预测模型(存储在预测模型存储部30e中的预测模型),从而预测作为预测对象的m
′
名患者的痴呆症的各评价项目的病情程度。
[0144]
根据以上那样构成的第五实施方式,无需进行简易精神状态检查(mmse)便可预测mmse的各评价项目的得分。
[0145]
此外,此处对于按mmse的五个评价项目预测得分的例子进行了说明,但是,也可以按照将该五个评价项目进一步细分后的更多评价项目预测得分。
[0146]
在上述第一至第五实施方式中,例示了具备学习器和预测器的痴呆症预测装置,但也可以分开构成仅具备学习器的预测模型生成装置和仅具备预测器的痴呆症预测装置。仅具备学习器的预测模型生成装置的构成如上述第一至第五实施方式中所说明。另一方面,仅具备预测器的痴呆症预测装置的构成如图12所示。
[0147]
在图12中,第二元素提取部11
′
具有与单词提取部11a、词类提取部11b、或者单词提取部11a及词类提取部11b的组合中的任意一个相同的功能。第二文本向量计算部121
′
具有与文本向量计算部121相同的功能。第二元素向量计算部120
′
具有与单词向量计算部122、词类向量计算部123、或者单词向量计算部122及词类向量计算部123的组合中的任意一个相同的功能。第二指标值计算部13
′
具有与指标值计算部13a~13e的任意一个相同的功能。痴呆症预测部21
′
具有与痴呆症预测部21a~21e的任意一个相同的功能。预测模型存储部30
′
存储与预测模型存储部30a~30e的任意一个相同的预测模型。
[0148]
另外,在上述第一至第五实施方式中,对于“痴呆症的病情程度”为mmse的得分时的例子,即预测mmse的得分的例子进行了说明,但本发明并不限定于此。例如,痴呆症的病情程度也可以是以小于mmse得分的最大值且2以上的数分类的类别。例如,也可以像mmse的得分为30~27分时为非疑似痴呆症,26~22分时为疑似轻度痴呆症障碍,21分以下时为疑似痴呆症这样将痴呆症的病情程度分为三个类别,并预测患者属于哪个分类。
[0149]
该情况下,例如在第一实施方式中,预测模型生成部14a生成如下的预测模型,即:将根据与已知mmse得分为30~27分的患者的自由对话相对应的文本数据算出的文本指标值组分类为“无疑似痴呆症”的第一类别,将根据与已知mmse得分为26~22分的患者的自由对话相对应的文本数据算出的文本指标值组分类为“疑似轻度痴呆症障碍”的第二类别,将根据与已知mmse得分为21分以下的患者的自由对话相对应的文本数据算出的文本指标值组分类为“疑似痴呆症”的第三类别。
[0150]
例如,预测模型生成部14a针对各文本d
i
的文本指标值组分别算出特征量,并根据该算出的特征量的值,利用马尔科夫链蒙特卡罗法对类别分离进行优化,由此生成用于将各文本d
i
分类为多个类别的预测模型。在此,预测模型生成部14a生成的预测模型是将文本指标值组作为输入、将想要预测的多个类别中的任意一个作为解而输出的学习模型。或者,也可以是将分类为任意类别的概率作为数值而输出的学习模型。学习模型的形态是任意的。
[0151]
另外,在上述第一至第五实施方式中,对于以mmse得分作为基准而预测痴呆症的病情程度的例子进行了说明,但本发明并不限定于此。即,也可以利用以mmse得分以外的基准掌握痴呆症的病情程度的方法,例如,能够以修订版长谷川式简易智力评价量表(hasegawa
′
s dementia scale-revised:hds-r)、adas-cog(alzheimer
′
s disease assessment scale-cognitive subscale)、cdr(clinical dementia rating)、cdt(clock drawing test)、cognistat(neurobehavioral cognitive status examination)、7分钟筛选量表等为基准预测痴呆症的病情程度。
[0152]
另外,在上述第一至第五实施方式中,对于将医生与患者的问诊形式的自由对话文字数据化,并将其用于与痴呆症的病情程度相关的学习及预测中的例子进行了说明,但本发明并不限定于此。例如,也可以将患者日常生活中进行的自由对话文字数据化,并将其用于与痴呆症的病情程度相关的学习及预测中。
[0153]
此外,上述第一至第五实施方式都只不过示出了实施本发明时的具体化的一例,并不能据此对本发明的技术范围进行限定性的解释。即,本发明能够在不脱离其主旨或其主要特征的情况下以各种方式实施。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1