用于监督式学习的分布式标记的制作方法
交叉引用
本申请要求2019年8月29日提交的美国专利申请16/566066号和2018年9月28日提交的美国临时专利申请62/738990号的优先权,这两个专利申请据此以引用方式并入本文。
本公开整体涉及经由私有化数据进行机器学习的领域。更具体地讲,本公开涉及实现一个或多个机制以使得能够实现机器学习模型的监督式训练的私有化分布式标记的系统。
背景技术:
机器学习是人工智能的应用,其使得复杂的系统能够在没有被明确编程的情况下从经验中自动学习和改进。机器学习模型的准确性和有效性可部分地取决于用于训练那些模型的数据。例如,可以使用经标记的数据集训练机器学习分类器,其中分类器要学习识别的数据的样本与为样本标识分类的一个或多个标签一起被提供给分类器。一般来讲,更大的训练数据集导致更准确的分类器。然而,当前用于准备训练数据集的技术可能是繁杂、耗时且昂贵的,尤其是涉及手动标记数据以生成训练数据集的技术。
技术实现要素:
本文所述的实施方案提供了一种技术用于众包机器学习模型的训练数据的标记,同时保持众包参与方提供的数据的隐私。客户端设备可用于生成要在训练数据集中使用的数据的单元的所提议的标签。在将数据传输给服务器时,使用一个或多个隐私机制来保护用户数据。
一个实施方案提供一种数据处理系统,该数据处理系统包括用于存储指令的存储器设备和用于执行存储在存储器设备上的指令的一个或多个处理器。该指令使得该数据处理系统执行操作,该操作包括:向一组多个移动电子设备发送未标记的一组数据,该组多个移动电子设备用于生成用于该未标记的一组数据的一组所提议的标签,其中移动电子设备中的每一者包括第一机器学习模型的变体;从该组多个移动电子设备接收用于该未标记的一组数据的一组所提议的标签,该组所提议的标签被编码以掩蔽该组所提议的标签中每个所提议的标签的各个贡献者;处理该组所提议的标签以确定用于该未标记的一组数据的最频繁提议的标签;将该未标记的一组数据和最频繁提议的标签添加到第一训练集;以及使用该第一训练集训练第二机器学习模型,该第二机器学习模型位于服务器设备上。
一个实施方案提供了一种存储指令的非暂态机器可读介质,该指令用于使得一个或多个处理器执行操作,该操作包括:向一组多个移动电子设备发送未标记的一组数据,该组多个移动电子设备用于生成用于该未标记的一组数据的一组所提议的标签,其中该移动电子设备中的每一者包括第一机器学习模型;从该组多个移动电子设备接收用于该未标记的一组数据的一组所提议的标签,该组所提议的标签被编码以掩蔽对组所提议的标签的各个贡献者;处理该组所提议的标签以确定用于该未标记的一组数据的最频繁提议的标签的估计;将该未标记的一组数据和对应的最频繁提议的标签添加到第一训练集;以及使用该第一训练集训练第二机器学习模型,该第二机器学习模型位于服务器设备上。
一个实施方案提供了移动电子设备上的一种数据处理系统,该数据处理系统包括用于存储指令的存储器设备和用于执行存储在存储器设备上的指令的一个或多个处理器。该指令使得该一个或多个处理器选择移动电子设备上的一组数据;基于所选择的数据生成训练集;使用该训练集训练第一机器学习模型;从服务器接收未标记的一组数据;为该未标记的一组数据的元素生成所提议的标签;以及将一个或多个所提议的标签的私有化版本传输给服务器。
一个实施方案提供了一种存储指令的非暂态机器可读介质,该指令用于使得一个或多个处理器执行操作,该操作包括:选择移动电子设备上的一组数据;基于所选择的数据生成训练集;使用该训练集训练第一机器学习模型,该第一机器学习模型在移动电子设备上训练;从服务器接收未标记的一组数据;为该未标记的一组数据的元素生成所提议的标签;以及将所提议的标签的私有化版本传输给服务器。
通过附图以及通过以下具体实施方式,本实施方案的其他特征将显而易见。
附图说明
本公开的实施方案以举例的方式而不是以限制的方式在各个附图的图示中进行说明,在附图中类似的附图标号是指类似的元件。
图1示出了根据本文所述实施方案的用于使能机器学习模型的训练数据的众包标记的系统。
图2示出了根据一个实施方案的用于从多个客户端设备接收私有化众包标签的系统。
图3a是根据一个实施方案的用于为服务器提供的未标记数据生成隐私化所提议的标签的系统的框图。
图3b是根据一个实施方案的系统的数据流的图示。
图4a是根据一个实施方案的用于经由未标记数据的众包标记来提高机器学习模型的准确性的方法的流程图。
图5a至图5c示出了可在本文所述的经由差分隐私实现私有化的实施方案中使用的示例性私有化数据编码。
图6a至图6b是根据本文所述实施方案的用于对要传输给服务器的所提议的标签进行编码和差分隐私化的示例性过程。
图7a至图7d是根据实施方案的客户端算法和服务器算法的多比特直方图和计数均值草图模型的框图。
图8示出了根据实施方案的可以以私有化方式标记的数据。
图9a示出了根据一个实施方案的可以以私有化方式学习的设备活动序列。
图9b示出了可用于训练客户端设备上的预测器模型的示例性设备活动。
图10示出了根据本文所述实施方案的客户端设备上的计算架构,该计算架构可用于使能使用机器学习算法的设备上的半监督式训练和推断。
图11是根据实施方案的移动设备架构的框图。
图12是示出可以结合本公开的实施方案中的一个或多个使用的示例性计算系统的框图。
具体实施方式
本文将参考下文讨论的细节来描述各种实施方案和方面。附图将例示各种实施方案。以下说明书和附图为例示性的,并且不应被理解为限制性的。描述了许多具体细节,以提供对各个实施方案的全面理解。然而,在某些实例中,熟知的或常规的细节并未被描述,以便提供对实施方案的简明论述。
在本说明书中提到的“一个实施方案”或“实施方案”或“一些实施方案”是指结合该实施方案所述的特定特征、结构或特性可被包括在至少一个实施方案中。在本说明书中的各个位置出现短语“实施方案”不一定都是指同一个实施方案。需注意,本文描述的流程图或操作可以存在变化,而不脱离本文所述的实施方案。例如,可以并行地、同时地或以与所示顺序不同的顺序执行操作。
许多监督式学习技术的具体实施中的关键障碍是要求在训练服务器上具有经标记的数据。对经标记的数据问题的现有解决方案包括将训练数据集中化并用一个或多个标签手动注释数据。在训练数据为用户数据的情况下,将此类数据保持在服务器上可能具有失去用户隐私的风险。另外,手动标记训练数据可能成本过高。
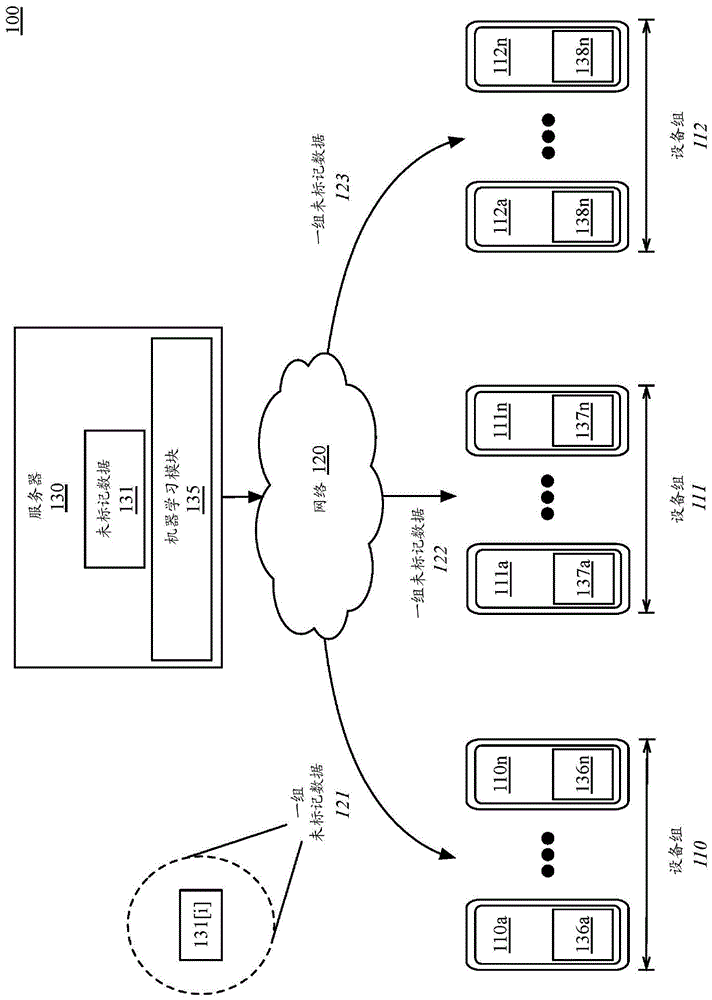
图1示出了根据本文所述实施方案的用于使能机器学习模型的训练数据的众包标记的系统100。如图1所示,在一个实施方案中,服务器130可通过网络120与一组客户端设备110a-110n、111a-111n、112a-112n连接。服务器130可以是任何类型的服务器,包括单个服务器或服务器群集。服务器130也可以是或包括基于云的服务器、应用服务器、后端服务器、虚拟服务器或它们的组合。网络120可以是任何合适类型的有线或无线网络,诸如局域网(lan)、广域网(wan)或其组合。客户端设备中的每一者可包括任何类型的计算设备,诸如台式计算机、平板电脑、智能电话、电视机顶盒或其他计算设备。例如,客户端设备可以是
在一个实施方案中,服务器130存储机器学习模块135,该机器学习模块可包括使用神经网络(诸如但不限于深度学习神经网络)实现的机器学习模型。例如,机器学习模块135可包括卷积神经网络(cnn)或递归神经网络(rnn),包括rnn的长短期记忆(lstm)变体。可使用其他类型的机器学习模型和/或神经网络。机器学习模块135可包括未经训练或使用通用数据预先训练的基本低准确度学习模型的具体实施。服务器130也可存储一组未标记数据131。在一个实施方案中,未标记数据131是将被标记并用于提高机器学习模块135的准确度的一大组数据。
未标记数据131包括若干类型的数据,包括机器学习模块135可被配置为进行分类的数据的类型。然而,系统100不限于与任何特定类型的数据一起使用,并且可基于要学习或分类的数据的类型来配置。例如,系统100可用于图像数据,但不限于任何特定类型的数据。例如,图像数据可用于基于图像的分类模型,诸如图像分类器,其可被配置用于对象检测或面部识别。系统100也可被配置为训练预测系统。字符和字词的序列可用于训练预测性键盘的预测模型。例如,可以训练机器学习模块135,使得对于给定的一组输入字符,可以预测下一个字符或字词。应用的序列可用于训练应用预测器。例如,对于用户访问或使用的给定序列的应用,可以训练机器学习模块135预测用户可能访问的下一个或多个应用,并且在用户界面的用户容易快捷访问的区域中呈现那些应用的图标。在一个实施方案中,地图绘制应用可使用机器学习模块135的变体来基于用户的最近位置或目的地的重置来预测用户的导航目的地。在一个实施方案中,设备和应用活动的组合可用于训练机器学习模块135预测即将到来的用户利用设备的活动。例如,当移动设备在工作日早晨连接到汽车的蓝牙音频或其他车载信息娱乐设备时,机器学习模块135可用于预测用户正准备通勤到工作目的地。在一个实施方案中,与虚拟助理快捷方式相关联的数据也可用于训练机器学习模型135。虚拟助理快捷方式可用于跨设备的多个应用使一个或多个任务自动化。
客户端设备可被组织成可各自包含多个客户端设备的设备组(例如,设备组110、设备组111、设备组112)。每个设备组可包含n个设备,其中n可为任何设备数量。例如,设备组110可包含客户端设备110a-110n。设备组111可包含客户端设备111a-111n。设备组112可包含客户端设备112a-112n。在一个实施方案中,每个设备组可包含多达128个设备,但是每个设备组中客户端设备的数量可在不同实施方案中是不同的,并且不限于任何特定数量的设备。一般来讲,每组使用大量设备以使标记系统能够对于组内客户端的退出具有弹性,使得系统为了提供所提议的标签并不需要组内的所有设备。每个设备组中设备的数量对于每个组可以是相同的,也可以在各个组中是不同的。在一个实施方案中,在所提议的标签中的特定一者被选择之前,服务器130可以要求每个组内阈值数量的设备发送所提议的标签。
在一个实施方案中,每个客户端设备(客户端设备110a-110n、客户端设备111a-111n、客户端设备112a-112n)可包括本地机器学习模块。例如,设备组110的客户端设备110a-110n可各自包含对应的本地机器学习模块136a-136n。设备组111的客户端设备111a-111n可各自包含对应的本地机器学习模块137a-137n。设备组112的客户端设备112a-112n可各自包含对应的本地机器学习模块138a-138n。在各种实施方案中,本地机器学习模块可以在工厂调配期间被加载在每个客户端设备上,或者可以在客户端设备的系统映像被更新时被加载或更新。在一个实施方案中,每个本地机器学习模块最初可以是服务器的机器学习模块135的变体。然而,本地机器学习模块可包括与服务器所使用的学习模型不同类型的学习模型。在一个实施方案中,每个客户端设备上的本地机器学习模块136a-136n、137a-137n、138a-138n可包括lstm网络,而服务器130上的机器学习模块135可为cnn。通过对存储在客户端设备上的本地数据进行训练,可为每个客户端设备个性化客户端设备上的本地机器学习模型。
在一个实施方案中,基于将训练其相应机器学习模型的数据的类型来对设备分组。例如,本地机器学习模块136a-136n可以对存储在客户端设备110a-110n上的文本数据进行训练,而机器学习模块137a-137n可以对存储在客户端设备111a-111n上的图像数据进行训练。本地机器学习模块138a-138n可针对与客户端设备112a-112n相关联的应用或设备活动数据进行训练。在一个实施方案中,服务器130和客户端设备可在要用于训练的可用数据的类型上同步,并且可以相应地对设备进行分组。
服务器可向每个设备组内的每个客户端设备提供一组未标记数据(例如,一组未标记数据121、一组未标记数据122、一组未标记数据123)。这些组未标记数据可各自包括未标记数据的一个或多个单元131[i],客户端设备可基于每个客户端设备上的个性化机器学习模块136a-136n、137a-137n、138a-138n来为其生成所提议的标签。在一个实施方案中,传输到设备组中设备的这组未标记数据包括未标记数据的相同的一个或多个单元,其中每个设备组接收未标记数据的不同单元。例如,提供给设备组110中每个客户端设备110a-110n的这组未标记数据121可包括未标记数据的第一单元。提供给设备组111中每个客户端设备111a-111n的这组未标记数据122可包括未标记数据的第二单元。提供给设备组112中每个客户端设备112a-112n的未标记数据123可包括未标记数据的第三单元。
图2示出了根据一个实施方案的用于从多个客户端设备接收私有化众包标签的系统200。在一个实施方案中,系统200包括一组客户端设备210a-210c(统称210),其可以是上述任何客户端设备(例如,客户端设备110a-110n、111a-111n、112a-112n)。使用上述技术,客户端设备210可以各自生成各自可以经由网络120传输给服务器130的经私有化的所提议标签212a-212c(来自客户端设备210a的经私有化的所提议标签212a、来自客户端设备210b的经私有化的所提议标签212b、来自客户端设备210c的经私有化的所提议标签212c)。在一个实施方案中,经私有化的所提议标签212a-212c作为元组被发送,该元组包括所提议的标签和所提议的标签所对应的一组未标记数据的元素。在一个实施方案中,所传输的元组包括所提议的标签和该组未标记数据的相关联元素的标识符。在一个实施方案中,可根据传输设备可用的隐私预算,从客户端设备210中的一者或多者传输所提议的标签和相关联元素的多个元组。
例示的客户端设备210可在相同的设备组或不同的设备组中。例如,客户端设备210a可表示图1中设备组110的客户端设备110a,而客户端设备210b可表示图1中设备组111的客户端设备111a。在客户端设备210在不同设备组中的情况下,经私有化的所提议标签212a-212c可各自与服务器130所提供的未标记数据的不同的一个或多个单元对应。例如,客户端设备210a可接收至少未标记数据的第一单元,该第一单元可不同于客户端设备210b所接收的未标记数据的第二单元。在客户端设备210在相同设备组中的情况下,经私有化的所提议标签212a-212c可与服务器所提供的未标记数据的相同的一个或多个单元(例如,图1所示的一组未标记数据121中的未标记数据131[i])对应。虽然所提议的标签用于数据的相同单元,但客户端设备210所提议的标签可以不同,因为标签是基于每个客户端设备上个性化的机器学习模型而提议的,其中个性化的机器学习模型是基于存储在每个客户端设备210a-210c中的本地数据而个性化的。
在通过网络120传输给服务器130之前,在客户端设备210上生成的所提议的标签被私有化以生成经私有化的所提议的标签212a-212c。执行隐私化以掩蔽众包数据集中任何所提议的标签的贡献者的身份,并且可使用一种或多种数据隐私化算法或技术来执行。本文所述的一些实施方案将差分隐私编码应用于所提议的标签,而其他实施方案可实现同态加密、安全多方计算或其他私有化技术。
服务器130维护所提议的标签聚合数据230的数据存储,其是从客户端设备210接收的经私有化的所提议标签212a-212c的聚合。所提议的标签聚合数据230的格式可基于应用于所提议标签的隐私化技术而变化。在一个实施方案中,使用多比特直方图差分隐私技术来对所提议的标签私有化,并且所提议标签聚合数据230是包含所提议标签频率估计的直方图。服务器可以处理所提议标签聚合数据230以确定未标记数据131的每个单元的最频繁提议标签,并对每个单元进行标记,生成一组众包标记数据231。然后,众包标记数据231可用于训练和增强机器学习模型。
图3a是根据一个实施方案的用于为服务器提供的未标记数据生成隐私化所提议标签的系统300的框图。系统300包括客户端设备,该客户端设备可以是客户端设备110a-110n、111a-111n、112a-112n或客户端设备210中的任一者。客户端设备310包括用于执行监督式学习的机器学习模块361,其具有已经使用客户端设备310上的客户端数据332训练的学习模型。然后,经训练的机器学习模块361可用于为从服务器130接收的未标记数据131的一个或多个元素生成所提议的标签333。在一个实施方案中,客户端设备310可具有隐私引擎353,该隐私引擎包括隐私守护进程356和隐私框架或应用编程接口(api)355。隐私引擎353可使用各种工具诸如散列函数(包括密码散列函数)来对客户端设备310所生成的所提议的标签333进行私有化。在一个实施方案中,隐私引擎353可使用多种私有化技术中的一种或多种(包括但不限于差分隐私算法)来对所提议的标签333进行私有化。然后,可经由网络120向服务器130传输经私有化的所提议的标签333。
服务器130可包括接收模块351和频率估计模块341用于确定标签频率估计331,该标签频率估计可存储在各种数据结构中,例如在多比特直方图算法中的阵列。接收模块351可异步接收来自大量客户端设备的众包私有化标签。在一个实施方案中,接收模块351可从所接收的数据中移除潜在标识符。潜在标识符可包括ip地址、元数据、会话标识符或可标识客户端设备310的其他数据。频率估计模块341也可利用操作诸如但不限于计数均值草图或多比特直方图操作来处理所接收的经私有化的所提议标签。标签频率估计331可由标记和训练模块330分析,该标记和训练模块可通过对未标记数据的每个单元应用例如为未标记服务器数据的单元接收的最高频率标签来确定未标记服务器数据的标签,但也可使用其他确定标签的方法。标记和训练模块330可使用所确定的标签来将现有的服务器侧机器学习模块135训练成经改进的服务器侧机器学习模块346。在一个实施方案中,客户端设备310和服务器130可进行迭代过程,以提高机器学习模块所实现的机器学习模型的准确性。在一个实施方案中,如果客户端设备310上的机器学习模块361与经改进的机器学习模块346兼容,则可以经由部署模块352将经改进的机器学习模块346部署到客户端设备310。另选地,客户端设备310使用的机器学习模型的版本可以在服务器130上增强或更新,并且经由部署模块352部署到客户端设备310,例如,如果机器学习模块361实现与服务器130上的经改进的机器学习模块346不同类型的模型的话。在一个实施方案中,部署模块352也可用于将未标记数据131从服务器130发布到客户端设备310。
图3b是根据一个实施方案的系统300的数据流的图示。来自服务器130的未标记数据131可被传输给客户端设备310以供客户端设备上的机器学习模块361处理。在一个实施方案中,未标记数据131可经由部署模块352发布给各个客户端设备。客户端设备310上的机器学习模块361可基于客户端设备310上的数据存储装置329内的客户端数据332经由训练模块370进行训练。客户端数据332可包括各种类型的客户端数据,诸如文本消息数据、图像数据、应用活动数据、设备活动数据和/或应用活动和设备活动数据的组合。
已由训练模块370训练的机器学习模块361可为未标记数据131的至少一个单元生成至少一个所提议的标签333。在一个实施方案中,为未标记数据131的多个单元生成所提议的标签。尽管可以生成多个所提议的标签,但是可以基于为客户端设备310配置的隐私预算来限制传输给服务器130的经私有化的所提议标签的数量。在一个实施方案中,移动电子设备维护隐私预算,该隐私预算限制在给定时间段内可传输给服务器的经私有化数据的量。在这样的实施方案中,一旦已向服务器传输了一定量的经私有化数据,移动电子设备将在一段时间内避免发送任何其他经私有化数据。
隐私引擎353可利用多种私有化技术中的一种或多种来私有化所提议的标签,所述多种私有化技术包括但不限于差分隐私技术、同态加密或安全多方计算。对于每种私有化技术,服务器130将包括对应的逻辑以处理经私有化的数据。利用所选择的私有化技术,隐私引擎353生成至少一个经私有化的所提议的标签334,其被编码以掩蔽所提议标签333与客户端设备310之间的关系。
经私有化的所提议的标签334可以从客户端设备310传输给服务器130。在一个实施方案中,经私有化的所提议的标签334是元组,其包含经私有化的所提议的标签与跟所提议的标签对应的未标记数据的单元的标识符的配对。在一个实施方案中,元组可直接包括未标记数据的单元,而不是未标记数据的单元的标识符。是包括未标记数据的单元还是单元的标识符可根据要标记的未标记数据的各个单元的大小而变化。例如,图像数据的标识符可与所提议的标签一起传输,而字符序列的所提议的标签可直接包括在元组内。
在一个实施方案中,服务器130经由接收模块351接收经私有化的所提议的标签334。接收模块351可从客户端设备310的各个实例向频率估计模块341提供各个经私有化标签。频率估计模块341可确定标签频率估计331以估计未标记数据131的给定单元的最频繁提议的标签。标记和训练模块330可包括标记模型330a用于标记未标记数据的每个单元,例如以该单元的最高频率提议标签来标记,从而生成一组标记数据362。然后,标记和训练模块330的训练模块330b可将数据的经标记单元添加到训练数据集363。训练数据集363可被训练模块330b用于训练机器学习模块135以提高机器学习模型的准确度,从而得到经改进的机器学习模型346。
图4a是根据一个实施方案的用于经由未标记数据的众包标记来提高机器学习模型的准确性的方法400的流程图。方法400可在服务器设备诸如本文所述的服务器设备130中实现。
在一个实施方案中,方法400包括服务器执行操作401,操作401包括向一组多个移动电子设备发送一组未标记数据。该组多个移动电子设备各自被配置用于为该组未标记数据中的元素生成所提议的标签。每个移动电子设备可以包括机器学习模型。机器学习模型可以是多种机器学习模型中的一者,包括但不限于多类别分类模型或回归模型。机器学习模型可利用多种技术来实现,包括卷积神经网络或递归神经网络。
方法400还包括操作402,其中服务器从该组多个移动电子设备接收一组所提议的标签。这组所提议的标签被编码以掩蔽对这组所提议标签的各个贡献者。客户端设备可以利用多种隐私保护技术中的一者或多者对所提议的标签进行编码,包括差分隐私编码、同态加密、安全多方计算或其他私有化技术。在一个实施方案中,客户端和服务器侧差分隐私算法被应用于所提议的标签,诸如计数均值草图算法或多比特直方图算法。
方法400还包括操作403,其中服务器处理该组所提议的标签以确定未标记数据集中每个元素的最频繁提议标签的估计。该处理可包括应用服务器侧计数均值草图或多比特直方图算法来生成草图或直方图,根据该草图或直方图可估计所提议的标签的频率。从频率数据,可以为每个元素确定每个标签的提议频率的估计。该组未标记数据中每个元素的最频繁提议的标签可用于生成该组未标记数据中元素的标签。然后,方法400可执行操作404以将未标记数据的每个元素和该元素的对应的最频繁提议的标签添加到训练数据集。方法400还包括操作405,其中服务器利用训练数据集训练机器学习模型以生成经改进的机器学习模型。
图4b是根据一个实施方案的客户端设备上生成经私有化的所提议的标签的方法410的流程图。方法410可在客户端设备诸如如本文所述的客户端设备310中实现。在一个实施方案中,并且如下所述,客户端设备是移动电子设备。然而,在一些实施方案中可使用其他类型的客户端设备,诸如台式或膝上型计算设备。
在一个实施方案中,方法410包括操作411用于选择移动电子设备上的一组客户端数据。多种不同类型的客户端数据可用于生成训练数据集。例如,设备上的图像可用于训练图像分类器,或者文本数据可用于训练字词或字符预测模型。在一个实施方案中,用户所键入的字词序列可用于训练预测性文本模型,该预测性文本模型可用于在键盘应用内建议字词。可以基于为移动电子设备配置的隐私设置来确定或限制所选择的数据的特定类型。例如,移动电子设备的用户可以选择加入或选择退出使用某些类型的数据用于众包标记。在一个实施方案中,分析移动电子设备上各种类型的客户端数据,并且从元素数量足以生成可行训练数据集的客户端数据类型中选择该组客户端数据。在这种情况下,足够的元素数量是超过与机器学习模型相关联的使得模型能够被训练到指定的最小准确度水平的数学阈值的元素数量。
方法410还包括用于基于所选择的这组客户端数据生成训练集的操作412。生成训练集可包括将客户端数据与和该客户端数据相关联的标签相关联。在一个实施方案中,标签可以由用户分配给客户端数据的元素,或者可以是利用客户端设备可用的其他分类逻辑自动分配的标签。在一个实施方案中,与图像相关联的标签可以是具有广泛适用性的一般标签,诸如对象标签(例如,人、树、房屋、苹果、橙、猫、狗等)。在一个实施方案中,存储在移动电子设备上的序列数据可以被划分以用于顺序学习。例如,文本序列“你在哪里”可被分成特征(“在哪里”)和标签(“你”)。另选地,特征(“你在哪儿”)可具有标签(“?”)。另外,根据移动电子设备上的客户端数据,特征(“哪里”)可被标记(“你?”)或(“它?”)。在一个实施方案中,存储在移动电子设备上的应用或设备活动序列可以被划分为特征和标签。例如,可以分析包括连接到电源、连接到蓝牙设备、离开或到达特定位置或启动特定应用的一系列规律设备活动,以确定在移动电子设备上或与移动电子设备一起执行的一组规律活动。在特定序列中定期进行的活动可被归类为具有标签的序列特征,所述标签使得能够预测序列中的下一活动。例如,包括在某个时间段期间连接到某个蓝牙音频设备的活动特征可被标记为可能要启动的下一应用的应用预测(“地图”)。如果地图应用通常在该序列期间被启动,则导航目的地预测(“工作”)可被应用作为序列特征的标签。
方法410还包括用于利用训练集训练移动电子设备上的机器学习模型的操作413。例如,当设备空闲并连接到电源时,可以直接在移动电子设备上执行训练。训练集内的具体特征和标签可因设备而异。因此,移动电子设备上的机器学习模型将变得对每个设备个性化。训练数据集和经训练的模型不能在不泄漏可能对于移动电子设备的用户是隐私的数据的情况下从移动电子设备传输给服务器。相反,服务器可向各个移动电子设备发送未标记数据。因此,方法410还包括用于从服务器接收一组未标记数据的操作414。该组未标记数据可包括一种或多种不同类型的数据,包括但不限于图像数据、文本序列数据和/或设备活动数据。移动电子设备可以执行操作415用于为该组未标记数据中的一个或多个元素生成所提议的标签。所生成的所提议的标签的数量可以变化,并且在一个实施方案中部分地基于与移动电子设备相关联的隐私预算而受到限制。
在一个实施方案中,未标记的这组数据与所选择的这组用户数据是相同的类型。在此类实施方案中,移动电子设备可以传送用于训练本地机器学习模型的数据的类型。在一个实施方案中,多种类型的未标记数据被发送给移动电子设备。数据类型可与未标记数据的各个元素相关联,并且移动电子设备可以为已经训练本地模型的数据的类型生成标签。在一个实施方案中,密码或其他算法可用于使移动电子设备和服务器能够在将用于训练设备上的机器学习模型的数据的类型上达成一致。例如,可以基于使用移动电子设备的设备标识符作为输入的函数来确定要使用的数据的类型。另选地,可以使用与用户的云服务账户相关联的标识符的散列,或者移动电子设备和服务器已知的函数和输入的任何其他组合。
方法410还包括操作416,其中移动电子设备可将一个或多个所提议标签的经私有化版本传输给服务器。在一个实施方案中,操作416包括将一个或多个元组传输给服务器,其中每个元组包括经私有化的所提议的标签以及该组未标记数据中元素的至少标识符。在一个实施方案中,该组未标记数据中的每个元素具有服务器已知的相关联标识符。服务器可使用在元组内提供的标识符来将经私有化的所提议的标签与为之提议标签的元素相关联。在一个实施方案中,在传输和/或隐私预算允许的情况下,元组包括未标记数据的实际单元以及用于该数据单元的经私有化的所提议的标签。是未标记数据的单元还是未标记数据的单元的标识符可基于配置、隐私/传输预算或被标记的数据的类型而变化。
在一些实施方案中,移动电子设备可以为未标记数据的多个元素生成标签。在此类实施方案中,操作416包括传输多个元组。移动电子设备也可被配置为向服务器发送仅一个标签或标签的仅一部分。本文所述的实施方案是带宽高效的,因为客户端设备仅传输少量数据。例如,在其中使用计数均值草图算法的一个实施方案中,仅传输256位数据来向服务器提议标签。
可利用本文所述的多种隐私保护编码中的一种或多种来创建所提议的标签的经私有化版本,诸如但不限于差分隐私编码或其他隐私保护技术,诸如同态加密或安全多方计算。
服务器可以从多个移动电子设备接收经私有化的所提议标签,并利用上述方法400聚合数据和处理数据。从聚合数据,服务器可以估计发送给移动电子设备的未标记数据的元素的最频繁应用标签,并生成训练数据集以增强基于服务器的机器学习模型。在一些实施方案中,方法400和方法410可以迭代地进行,其中利用多个客户端设备所提供的标签来增强基于服务器的机器学习模型,并且在一段时间之后,可以更新移动电子设备上的机器学习模型。然后,客户端设备上的更新后的机器学习模型可用于向服务器提议新标签。
经由差分隐私的所提议的标签私有化。
在一些实施方案中,将一种或多种差分隐私技术应用于众包的所提议标签以掩蔽所提议标签的贡献者的身份。作为一般概述,本地差分隐私在共享用户数据之前将随机性引入到客户端用户数据。不是具有集中式数据源d={d1,...,dn},每个数据条目di而是属于单独的客户端i。给定与客户端i的交互的抄本ti,如果要将数据元素替换为null,则对手可能不可能将ti与已生成的抄本区分开。不可区分的程度(例如,隐私程度)由ε参数化,其是表示隐私保证强度与所发布结果的准确性之间的权衡的隐私参数。通常,ε被认为是小的常数。在一些实施方案中,该ε值可以基于要私有化的数据的类型而变化,其中越敏感的数据被私有化到越高程度(越小的ε)。以下是对本地差异隐私的正式定义。
设n为客户端-服务器系统中的客户端数量,设γ为从任何单个客户端-服务器交互生成的所有可能的抄本的集合,并且设ti为在与客户端i交互时由差分隐私算法a生成的抄本。设di∈s为客户端i的数据元素。如果对于所有子集
这里,di=null指的是删除客户端i的数据元素的情况。换句话讲,具有数据集的n-1个数据点的对手不能可靠地测试第n个数据点是否是特定值。因此,无法以使得能够确定任何特定用户的数据的方式查询差分私有化的数据集。
在一个实施方案中,可在客户端设备和服务器上实现经私有化的多比特直方图模型,其中当标签的全域超过阈值时,可选地转变为计数均值草图私有化技术。多比特直方图模型可将p个比特发送给服务器,其中p对应于与潜在所提议标签相对应的数据值的全域的大小。服务器可执行求和操作以确定用户数据值的频率。多比特直方图模型可提供
图5a至图5c示出了可在本文所述的经由差分隐私实现私有化的实施方案中使用的示例性私有化数据编码。图5a示出了客户端设备上的所提议的标签编码500。图5b示出了服务器上的所提议的标签直方图510。图5c示出了服务器上的所提议的标签频率草图520。
如图5a所示,在一个实施方案中,在客户端设备上创建所提议的标签编码500,其中所提议标签值502被编码成所提议标签矢量503。所提议的标签矢量503是独热编码,其中设置与跟客户端设备所生成的所提议的标签相关联的值对应的比特。在所示的所提议的标签编码500中,标签501的全域是可以为由服务器提供给客户端设备的未标记数据单元提议的可能标签的集合。标签501的全域中值的数量与将由众包标记数据训练的机器学习模型相关。例如,对于将被训练推断选自p个分类的全域的分类的分类器,全域大小p可用于标签的全域。然而,此类关系不是对于所有实施方案都是必需的,并且标签的全域的大小不固定到任何特定大小。应当注意,本文出于方便和数学目的描述了矢量,但是可以实现任何合适的数据结构,诸如位串、对象等。
如图5b所示,在一个实施方案中,服务器可将经私有化的所提议的标签聚合成所提议的标签直方图510。对于未标记数据的每个单元,服务器可以聚合所提议标签512,并为所提议标签512中的每一者对提议数量511计数。所选择的标签513将是具有最大提议数量511的所提议的标签。
如图5c所示,在一个实施方案中,服务器可生成所提议的标签频率草图520用于与计数均值草图差分隐私算法一起使用。服务器可累积来自多个不同客户端设备的经私有化的所提议标签。每个客户端设备可传输所提议的标签的经私有化编码以及在对所提议的标签私有化时所使用的随机变体的索引值(或对索引值的标引)。随机变体是要隐私化的所提议的标签上的随机选择的变化。变体可对应于服务器已知的一组k个值(或k个索引值)。累积的所提议的标签可由服务器处理以生成所提议的标签频率草图520。频率表可由这组可能的变体索引值k索引。然后利用私有化矢量更新对应于随机选择的变体的索引值的频率表的行。下文进一步描述多比特直方图和计数均值草图方法的更详细的操作。
图6a至图6b是根据本文所述实施方案的用于对要传输给服务器的所提议的标签进行编码和差分隐私化的示例性过程600、610、620。在本文所述的实施方案中,参与众包用于服务器提供的数据的单元的标签的每个客户端设备可以为该数据单元生成所提议的标签,并且在将标签传输给服务器之前将标签私有化。所提议的标签可以是潜在提议标签的全域内的标签,其中特定标签值与客户端设备所选择的所提议标签相关联。
在一个实施方案中,如图6a的示例性过程600所示,特定值601与客户端设备所选择的所提议的标签相关联。该系统可以矢量602的形式对标签值601进行编码,其中矢量的每个位置对应于所提议的标签。标签值601可对应于矢量或比特位置603。例如,例示的所提议的标签值z对应于位置603,而潜在的所提议的标签值a和b对应于矢量602内的不同位置。矢量602可通过更新位置603处的值(例如,将该比特设置为1)来编码。为了考虑0或null值的任何潜在偏差,系统可以使用经初始化的矢量605。在一个实施方案中,经初始化的矢量605可以是矢量v←{-cε}m。应当注意,这些值用作数学项,但可利用比特来编码(例如,0=+cε,1=-cε,)。因此,矢量602可以使用经初始化的矢量605来创建编码606,其中位置603处的值(或比特)被改变(或更新)。例如,可翻转位置603处的值的符号,使得值为cε(或+cε)并且所有其他值保持为-cε,如图所示(或反之亦然)。
然后,客户端设备可以通过以概率cp609(其可以是预先确定的概率)改变值中的至少一些来创建经私有化的编码608。在一个实施方案中,系统可通过翻转值的符号(例如,(-)到(+),或反之亦然)来改变值。在一个实施方案中,概率cp609等于
因此,现在将标签值601表示为经私有化编码608,其单独地保持生成所提议的标签的用户的隐私。这个经私有化编码608可被存储在客户端设备上,并且随后被传输给服务器130。服务器130可累积来自各个客户端设备的经私有化编码(例如,矢量)。累积的编码然后可被服务器处理以用于频率估计。在一个实施方案中,服务器可执行求和操作以确定用户数据的值的总和。在一个实施方案中,求和操作包括对客户端设备所接收的矢量执行求和操作。
在一个实施方案中,如图6b的示例性过程610所示,是根据本公开的实施方案的对要传输给服务器的用户数据的编码进行差分隐私化的示例性处理流程。客户端设备可以选择所提议的标签611用于传输给服务器。所提议的标签611可以任何合适的格式被表示为项612,其中该项是所提议的标签的表示。在一个实施方案中,可使用散列函数将项612转换为数值。如图所示,在一个实施方案中使用了sha256散列函数。然而,也可使用任何其他散列函数。例如,可以使用sha或其他算法的变体,诸如具有各种位大小的sha1、sha2、sha3、md5、blake2等。因此,考虑到对于客户端和服务器两者都是已知的,任何散列函数都可在具体实施中使用。在一个实施方案中,也可使用块密码或客户端和服务器已知的另一密码函数。
在一个实施方案中,客户端设备上的计算逻辑可使用所创建的散列值的一部分连同项612的变体614来解决在由服务器执行频率计数时的潜在散列冲突,这提高了计算效率,同时保持可证实的隐私级别。变体614可对应于服务器已知的一组k个值(或k个索引值)。在一个实施方案中,为了创建变体614,系统可以将索引值616的表示附加到项612。如该示例中所示,对应于索引值的整数(例如,“1,”)可以被附加到项612以创建变体(例如,“1,apple”或“apple1”等)。然后,系统可以随机选择变体619(例如,随机索引值r处的变体)。因此,系统可通过使用项612的变体614(例如,随机变体619)来生成随机散列函数617。变体的使用使得能够创建k个散列函数的族。这个散列函数族是服务器已知的,并且系统可使用随机选择的散列函数617来创建散列值613。在一个实施方案中,为了减少计算,系统可以仅创建随机选择的变体619的散列值613。另选地,系统可创建完整的一组散列值(例如,k个散列值),或直到随机选择的变体r的散列值。应当指出的是,整数序列被示出为索引值的示例,但考虑到对于客户端和服务器两者都是已知的,也可使用其他形式的表示(例如,各种数量的字符值)或函数(例如,另一散列函数)作为索引值。
一旦生成了散列值613,系统就可以选择散列值613的一部分618。在该示例中,可以选择16位部分,但是基于差分隐私算法的期望准确度水平或计算成本也可以设想其他大小(例如,8、16、32、64等位数)。例如,增加位数(或m)就增加计算(和传输)成本,但可获得准确度的改善。例如,使用16位提供216-1(例如,约65k)个潜在唯一值(或m个值范围)。类似地,增加变体k的值就增加计算成本(例如,计算草图的成本),但继而增加估计的准确性。在一个实施方案中,系统可将该值编码成矢量,如图6a所示,其中矢量的每个位置可对应于所创建的散列值613的潜在数值。
例如,图6b的处理流程620示出所创建的散列值613作为十进制数可对应于矢量/比特位置625。因此,矢量626可通过更新位置625处的值(例如,将该比特设置为1)来编码。为了考虑0或null值的任何潜在偏差,系统可以使用经初始化的矢量627。在一个实施方案中,经初始化的矢量627可以是矢量v←{-cε}m。应当注意,这些值用作数学项,但可利用比特来编码(例如,0=+cε,1=-cε,)。因此,矢量626可以使用经初始化的矢量627来创建编码628,其中位置625处的值(或比特)被改变(或更新)。例如,可翻转位置625处的值的符号,使得值为cε(或+cε)并且所有其他值保持为-cε,如图所示(或反之亦然)。
然后,系统可以通过以概率cp633改变值中的至少一些来创建经私有化的编码632,其中
图7a至图7d是根据实施方案的客户端算法和服务器算法的多比特直方图和计数均值草图模型的框图。图7a示出了如本文所述的多比特直方图模型的客户端侧过程700的算法表示。图7b示出了如本文所述的多比特直方图模型的服务器侧过程710的算法表示。图7c示出了如本文所述的计数均值草图模型的客户端侧过程720的算法表示。图7d示出了如本文所述的计数均值草图模型的服务器侧过程730的算法表示。客户端侧过程700和服务器侧过程710可使用多比特直方图模型来使得能够实现众包数据的隐私,同时保持数据的实用性。客户端侧过程700可以初始化矢量v←{-cε}m在用户要传输d∈[p]的情况下,客户端侧过程700可以被应用以翻转v[h(d)]的符号,其中h是随机散列函数。为了确保差分隐私,客户端侧过程700可以概率
如图7a所示,客户端侧过程700可以接收包括隐私参数ε、全域大小p和数据元素d∈s的输入,如框701处所示。在框702处,客户端侧过程700可以设置常数
如图7b所示,服务器侧过程710聚合客户端侧矢量,并且在给定包括隐私参数ε、全域大小p和要估计其频率的数据元素s∈s的输入的情况下,可以基于从众包客户端设备接收的聚合数据返回所估计的频率。如框711处所示,服务器侧过程710(例如,aserver)在给定隐私参数ε和全域大小p的情况下可获得n个矢量v1,···,vn对应于数据集d={d1,···,dn},使得vi←aclient(ε,p,di)。在框712处,服务器侧过程710可初始化计数器fs(例如,fs←0)。服务器侧过程710对于每个元组vi,i∈[n]可以设置fs=fs+vi[s],如框713处所示。在框714处,服务器侧过程710可返回fs,其是聚合数据集中用户数据的值的频率。
客户端侧过程700和服务器侧过程710提供隐私和实用性。客户端侧过程700和服务器侧过程710是联合本地差分隐私的。客户端侧过程700是ε本地差分隐私的,并且服务器侧过程710仅访问经私有化的数据。对于任意输出v∈{-cε,cε}p,无论用户是否在场,观察输出的概率都是类似的。例如,就不在场的用户而言,可考虑
类似地,
服务器侧过程710也具有用于频率估计的实用性保证。隐私和实用性对于差分隐私算法通常是折衷的。为了差分隐私算法实现最大隐私,算法的输出可能不是实际数据的有用近似。为了算法实现最大实用性,输出可能不足够隐私。本文所述的多比特直方图模型实现ε本地差分隐私,同时渐近地实现最佳实用性。
计数均值草图算法的总体概念类似于多比特直方图的总体概念,不同的是要传输的数据在全域大小p变得非常大时被压缩。服务器可使用维度kxm的草图矩阵m来聚合经私有化的数据。
如图7c所示,客户端侧过程720可以接收包括数据元素d∈s、隐私参数ε、全域大小p以及各自映射[p]到[m]的一组k个散列函数h={h1,h2,…hk}的输入,可以从[k]选择随机索引j以确定散列函数hj,如框721处所示。客户端侧过程720然后可以设置常数
如框723处所示,客户端侧过程720可使用随机选择的散列函数hj来设置v[hj(d)]←cε。在框724处,客户端侧过程720可以采样矢量b∈{-1,+1}m,其中每个bj是独立的且相同分布的,并且以概率
如图7d所示,服务器侧过程730可以聚合来自客户端侧过程720的客户端侧矢量。服务器侧过程730可以接收包括一组n个矢量和索引{(v1,j1),...,(vn,jn)}、隐私参数ε和各自映射[p]到[m]的一组k个散列函数h={h1,h2,...hk}的输入,如框731处所示。服务器侧过程730然后可初始化矩阵m←0,其中m具有k行和m列,使得m∈{0}k×m,如框732处所示。如框733处所示,对于每个元组(vi,ji),i∈[n],服务器侧过程730可将vi添加到m的ji行,使得m[ji][:]←m[ji][:]+vi。在框734处,服务器侧过程730可返回草图矩阵m。给定草图矩阵m,可能通过对计数去偏差并对m中的对应散列条目求平均来估计条目d∈s的计数。
虽然上文描述了经由多比特直方图和/或计数均值草图差分隐私技术的所提议的标签私有化的具体示例,但是实施方案不限于用于实现众包标签的私有化的任何具体差分隐私算法。实施方案可被配置为使用任何本地差分隐私算法,该算法使得能够对来自多个源的聚合频率数据进行经私有化的估计,同时掩蔽数据的每个单独元素到数据集的贡献者。另外,隐私技术不明确限于差分隐私算法的用户。如本文所述,可以应用同态加密技术,使得从客户端设备接收的加密值可以在服务器上求和,而不向服务器揭示经私有化的数据。例如,客户端设备可以采用同态加密算法来加密所提议的标签并将所提议的标签发送给服务器。服务器然后可以执行同态加和操作以对经加密的所提议的标签求和,而不需要知道未加密的所提议的标签。在一个实施方案中,也可以应用安全多方计算技术,使得客户端设备和服务器可以联合计算所提议标签的聚合值,而不将用户数据直接暴露给服务器。
图8示出了根据实施方案的可以以私有化方式标记的数据。图3a的机器学习模块361包括可利用客户端设备310上的各种不同类型的数据进行训练的机器学习模型。
在一个实施方案中,文本数据可用于生成训练数据来训练客户端设备上的机器学习模型,以执行文本序列标记802。可通过将客户端设备上的文本序列划分为特征和标签并对特征和标签训练本地机器学习模型来执行训练以生成用于顺序文本数据的标签。例如,“你在哪里”可被分成特征(“在哪里”)和标签(“你”)。“我很好”可被分为特征(“我”)和标签(“很好”)。该数据可用于在每个客户端设备上的机器学习模块内训练机器学习模型,从而得到基于设备上的本地数据针对每个设备个性化的机器学习模型。然后可针对从服务器发送给客户端设备的未标记数据生成所提议的标签。
在一个实施方案中,可以标记活动序列804,诸如但不限于应用启动序列、应用活动序列、设备活动序列或应用和设备活动的组合。设备所识别的应用或设备活动序列可用于以与文本序列标记类似的方式训练客户端设备中的机器学习模型。例如,可以分析包括连接到电源、连接到蓝牙设备、离开或到达特定位置或启动特定应用的一系列规律设备活动,以确定在移动电子设备上或与移动电子设备一起执行的一组规律活动。在特定序列中定期进行的活动可被归类为具有标签的序列特征,所述标签使得能够预测序列中的下一活动。
在一个实施方案中,客户端设备上的标记图像806也可用于训练客户端设备上的机器学习模型。例如,已以某种方式标记的与客户端设备存储或相关联的图像或照片可用于训练客户端设备上的机器学习模型。在一个实施方案中,相关标签是与图像相关联的一般描述(例如,花、日落等)。在一个实施方案中,标签可由用户应用到图像,或通过由图像或照片管理程序提供的自动图像标记或添加文字说明逻辑而自动应用到图像。
图9a示出了根据一个实施方案的可以以私有化方式学习的设备活动序列。例示了用户设备904,其中用户设备904可以是本文所述的任何形式的用户设备的变体,包括例如本文所述的客户端设备310。用户设备904可包括机器学习模块,诸如客户端设备310的机器学习模块361。用户设备904可代表用户执行多种功能,包括由在用户设备904上运行的一个或多个应用执行的功能。在一个实施方案中,应用活动数据906可被用户设备904存储,其记录应用启动或应用内活动的至少子集。可为应用活动数据906内的应用和活动分配数值。与用户设备904所执行的应用和活动相关联的数值可被编码为可用于训练用户设备904上的机器学习模块的机器学习模型的数据序列。经训练的机器学习模型可用于训练服务器所提供的未标记序列。
在一个实施方案中,服务评论应用901的启动可被检测并存储在应用活动数据906中。在一个实施方案中,用户设备904可将应用内活动的至少子集存储在应用活动数据906内。例如,服务评论应用901可任选地向应用活动数据906给予应用内活动和/或在服务评论应用901内执行的搜索。在一个实施方案中,用户设备904可检测在用户设备904上执行的应用内活动的子集。作为上述活动的示例,用户可启动服务评论应用901,服务评论应用提供对服务或商品提供方(例如,餐厅、零售店、修理店等)的用户评论。用户设备904可响应于接收到图形界面请求或虚拟助理请求而启动服务评论应用901。用户可例如经由用户设备904的图形界面或语音界面来执行对服务或商品提供方的搜索。然后,用户设备904可以显示一个或多个提供方的评论。然后,用户可启动用户设备上的地图应用903,例如,以使得用户能够确定一个或多个服务或商品提供方的位置。然后,用户可在用户设备904上启动顺风车应用905。顺风车应用905可与地图应用903分开或相关联。另选地,用户可指示用户设备904启用逐向导航913,逐向导航可以是地图应用903的特征或者是由单独的地图或导航应用提供的特征。
在一个实施方案中,每个应用启动和/或应用活动可被编码为应用活动数据906内的数字序列。数字序列可被分为特征部分和标签部分。特征部分和签条部分可用于训练机器学习模型。然后,经训练的机器学习模型可以提议用于服务器所提供的未标记序列的标签。所提议的标签可由客户端设备上的隐私引擎利用本文所述的隐私保护编码技术来选择和私有化。然后,可将经私有化的标签传输给服务器。实施方案不限于所示的具体示例。可学习的附加应用活动序列包括在线应用或媒体商店(例如,应用商店)内的购买序列或应用内的应用内购买序列。
图9b示出了可用于训练客户端设备上的预测器模型的设备活动920。如图9b所示,多种设备活动920可以被采样并用于训练应用和/或设备活动的预测模型。可以从用户的多个设备采集事件数据928,并将其组合为聚合的用户数据。事件数据928可从各种用户设备采集,包括可穿戴电子设备、移动设备诸如智能电话和平板计算设备、膝上型计算设备和台式计算设备。事件数据928包括但不限于用户动作数据922、上下文数据924和设备状态数据926。
用户动作数据922包括例如设备运动数据、应用内动作和重点关注应用数据。运动数据可包括设备的原始加速度计数据以及经处理的加速度计数据,该经处理的加速度计数据指示诸如用户行走的步数、行进的距离、运动数据、行走的楼梯段数、站立与静坐量度等信息。应用程序内的操作包括在应用程序内执行的活动,诸如在在线应用商店或媒体商店中进行的购买、在应用程序内进行的应用内购买、由web浏览器访问的网站、由相机应用程序拍摄的照片以及给定应用程序内的其他用户操作。重点关注应用数据包括关于哪些应用程序是活动的以及用户使用那些应用程序的持续时间的信息。
上下文数据924包括与其他事件数据928相关联的上下文信息,该其他事件数据诸如用户动作922或设备状态926。例如,对于每个用户动作922,可以采集上下文数据924以提供关于那些动作的附加信息。例如,如果用户定期跑步以进行锻炼,则用户的活动设备可在跑步期间将这些跑步的时间和位置记录为上下文数据924。在跑步期间,还可记录接近度信息,诸如活动设备与其他用户的设备或与用户的地理兴趣点的接近度。
事件数据928还可包括设备状态926,诸如wi-fi设备状态,包括信号强度分析和对设备的可用接入点。设备状态926还可包括电池信息,包括当前和历史电池能量水平、充电状态以及专用于特定活动或应用的电池使用百分比。
事件数据928和其他类型的设备活动920的各种元素可被转换为事件序列930并被划分为特征和元素数据。在一个实施方案中,特征数据可包括用户动作、上下文和相关联的设备状态。标签可以是将基于动作、上下文和状态的组合做出的预测。特征和元素数据可以是添加的训练数据,该训练数据用于训练客户端设备上的机器学习模型。然后,机器学习模型可以为未标记的服务器数据生成所提议的标签,其然后可被用于训练服务器设备上的预测模型。
图10示出了根据本文所述实施方案的客户端设备上的计算架构1000,该计算架构可用于使能利用机器学习算法的设备上的监督式训练和推断。在一个实施方案中,计算架构1000包括客户端标记框架1002,该客户端标记框架可被配置为利用客户端设备上的处理系统1020。客户端标记框架1002包括视觉/图像框架1004、语言处理框架1006和一个或多个其他框架1008,每个框架可以引用由核心机器学习框架1010提供的基元。核心机器学习框架1010可访问经由cpu加速层1012、神经网络处理器加速层1013和gpu加速层1014提供的资源。cpu加速层1012、神经网络处理器加速层1013和gpu加速层1014各自促进对本文所述的各种客户端设备上的处理系统1020的访问。处理系统包括应用处理器1022、神经网络处理器1023和图形处理器1024,它们中的每一者可用于加速核心机器学习框架1010和经由经核心机器学习框架提供的基元进行操作的各种更高层级框架的操作。应用处理器1022和图形处理器1024包括可用于执行核心机器学习框架1010的通用处理和图形特定处理的硬件。神经网络处理器1023包括专门调谐以加速人工神经网络的处理操作的硬件。神经网络处理器1023可提高执行神经网络操作的速度,但对于使得能够实现客户端标记框架1002的操作不是必需的。可利用应用处理器1022和/或图形处理器1024执行标记操作。
在一个实施方案中,计算架构1000的各种框架和硬件资源可用于经由机器学习模型的推断操作、以及用于机器学习模型的训练操作。例如,客户端设备可以使用计算架构1000来经由如本文所述的机器学习模型(诸如但不限于cnn、rnn或lstm模型)执行监督式学习。客户端设备然后可以使用经训练的机器学习模型来推断用于服务器所提供的未标记数据的单元的所提议标签。
附加的示例性计算设备
图11是根据实施方案的用于移动或嵌入式设备的设备架构1100的框图。设备架构1100包括存储器接口1102、包括一个或多个数据处理器、图像处理器和/或图形处理单元的处理系统1104以及外围设备接口1106。各种部件可通过一条或多条通信总线或信号线耦接。各种部件可以是单独的逻辑部件或设备或可以集成在一个或多个集成电路,诸如片上系统集成电路。
存储器接口1102可以耦接至存储器1150,其可以包括高速随机存取存储器诸如静态随机存取存储器(sram)或动态随机存取存储器(dram)和/或非易失性存储器,诸如但不限于闪存存储器(例如,nand闪存、nor闪存,等等)。
传感器、设备和子系统可耦接到外围设备接口1106以促进多个功能。例如,运动传感器1110、光传感器1112和接近传感器1114可耦接到外围设备接口1106以促进移动设备功能。还可存在一个或多个生物特征传感器1115,诸如用于指纹识别的指纹扫描器或用于面部识别的图像传感器。其他传感器1116也可连接至外围设备接口1106,诸如定位系统(例如,gps接收器)、温度传感器、或其他感测设备以促进相关的功能。可利用相机子系统1120和光学传感器1122(如电荷耦合器件(ccd)或互补金属氧化物半导体(cmos)光学传感器)来促进相机功能,诸如拍摄照片和视频剪辑。
可通过一个或多个无线通信子系统1124来促进通信功能,这些无线通信子系统可包括射频接收器和发射器和/或光学(例如,红外)接收器和发射器。无线通信子系统1124的具体设计与实现可取决于移动设备打算通过其操作的通信网络。例如,包括示出的设备架构1100的移动设备可包括被设计来通过gsm网络、cdma网络、lte网络、wi-fi网络、bluetooth网络或任何其他无线网络操作的无线通信子系统1124。具体地,无线通信子系统1124可提供通信机构,通过该通信机构,媒体回放应用可从远程媒体服务器检索资源或从远程日历或事件服务器检索调度事件。
可将音频子系统1126耦接到扬声器1128和麦克风1130以促进支持语音的功能,诸如语音识别、语音复制、数字记录和电话功能。在本文描述的智能媒体设备中,音频子系统1126可以是包括对虚拟环绕声的支持的高质量音频系统。
i/o子系统1140可包括触摸屏控制器1142和/或其他输入控制器1145。对于包括显示设备的计算设备,触摸屏控制器1142可耦接至触敏显示系统1146(例如,触摸屏)。触敏显示系统1146和触摸屏控制器1142可例如使用多种触摸和压力感测技术的任何一种检测接触和运动或压力,触摸和压力感测技术包括但不限于电容性、电阻性、红外和表面声波技术,以及用于确定与触敏显示系统1146接触的一个或多个点的其他接近传感器阵列或其他元件。触敏显示系统1146的显示输出可由显示控制器1143生成。在一个实施方案中,显示控制器1143可以可变的帧速率向触敏显示系统1146提供帧数据。
在一个实施方案中,包括传感器控制器1144以监测、控制、和/或处理从运动传感器1110、光传感器1112、接近传感器1114,或其他传感器1116中一者或多者接收的数据。传感器控制器1144可包括逻辑来解释传感器数据以通过分析来自传感器的传感器数据来确定多个运动事件或活动中的一者的发生。
在一个实施方案中,i/o子系统1140包括其他输入控制器1145,其可耦接到其他输入/控制设备1148,诸如一个或多个按钮、摇臂开关、拇指轮、红外线端口、usb端口和/或指针设备诸如触笔、或控制设备诸如用于扬声器1128和/或麦克风1130的音量控制的向上/向下按钮。
在一个实施方案中,耦接至存储器接口1102的存储器1150可存储操作系统1152的指令,包括便携式操作系统接口(posix)兼容和不兼容的操作系统或嵌入式操作系统。操作系统1152可包括用于处理基础系统服务以及用于执行硬件相关任务的指令。在一些具体实施中,操作系统1152可以是内核。
存储器1150还可以存储通信指令1154以促进与一个或多个附加设备、一个或多个计算机和/或一个或多个服务器的通信,例如从远程web服务器获取web资源。存储器1150还可包括用户界面指令1156,包括图形用户界面指令以有利于图形用户界面处理。
此外,存储器1150可存储促进传感器相关处理和功能的传感器处理指令1158;促进与电话相关的过程及功能的电话指令1160;促进与电子消息处理相关的过程及功能的即时消息指令1162;促进与网页浏览相关的过程及功能的网页浏览器指令1164;促进与媒体处理相关的过程和功能的媒体处理指令1166;促进基于位置的功能性的位置服务指令包括gps和/或导航指令1168和基于wi-fi的位置指令;促进与相机相关的过程和功能的相机指令1170;和/或有利于其他过程和功能,例如安全过程和功能以及与系统相关的过程和功能的其他软件指令1172。存储器1150还可以存储其他软件指令,诸如促进与web视频相关的过程和功能的web视频指令;和/或促进与网络购物相关的过程和功能的网络购物指令。在一些具体实施中,媒体处理指令1166分为音频处理指令和视频处理指令,以分别用于促进与音频处理相关的过程和功能以及与视频处理相关的过程和功能。移动设备标识符,诸如国际移动设备身份(imei)1174或类似的硬件标识符也可存储在存储器1150中。
上面所识别的指令和应用程序中的每一者可对应于用于执行上述一个或多个功能的指令集。这些指令不需要作为独立软件程序、进程或模块来实现。存储器1150可包括附加指令或更少的指令。此外,可在硬件和/或软件中,包括在一个或多个信号处理和/或专用集成电路中,执行各种功能。
图12为根据实施方案的计算系统1200的框图。示出的计算系统1200旨在表示一系列计算系统(有线或无线的),包括例如台式计算机系统、膝上型计算机系统、平板电脑系统、蜂窝电话、包括支持蜂窝的pda的个人数字助理(pda)、机顶盒、娱乐系统或其他消费电子设备、智能电器设备、或者智能媒体回放设备的一个或多个具体实施。另选的计算系统可以包括更多、更少和/或不同的部件。计算系统1200可用于提供计算设备和/或计算设备可与之连接的服务器设备。
计算系统1200包括总线1235或用于传递信息的其他通信设备,和与总线1235耦接的可处理信息的处理器1210。虽然计算系统1200被图示为具有单个处理器,但是计算系统1200可以包括多个处理器和/或协处理器。计算系统1200还可包括存储器1220,诸如耦接到总线1235的随机存取存储器(ram)或其他动态存储设备。存储器1220可存储可由处理器1210执行的信息和指令。在由处理器1210执行指令期间,存储器1220还可用于存储临时变量或其他中间信息。
计算系统1200还可包括只读存储器(rom)1230和/或耦接到总线1235的可存储用于处理器1210的信息和指令的其他数据存储设备1240。数据存储设备1240可以是或包括各种存储设备,例如闪存存储器设备、磁盘,或光盘并且可通过总线1235或通过远程外围设备接口耦接到计算系统1200。
计算系统1200还可经由总线1235耦接到显示设备1250以向用户显示信息。计算系统1200还可以包括数字字母混合输入设备1260,该设备包括数字字母键和其他键,其可以联接到总线1235以将信息和命令选择发送给处理器1210。另一种用户输入设备包括光标控制1270设备,诸如触控板、鼠标、轨迹球、或光标方向键,用于向处理器1210传递方向信息和命令选择以及在显示设备1250上控制光标移动。计算系统1200还可以经由一个或多个网络接口1280从通信地耦接的远程设备接收用户输入。
计算系统1200还可以包括一个或多个网络接口1280,以提供对诸如局域网之类的网络的访问。网络接口1280可以包括,例如具有天线1285的无线网络接口,所述天线可以表示一个或多个天线。计算系统1200可以包括多个无线网络接口,诸如wi-fi、
在一个实施方案中,网络接口1280可以例如通过符合ieee802.11标准来提供对局域网的接入,并且/或者无线网络接口可以例如通过符合蓝牙标准提供对个人区域网络的接入。其他无线网络接口和/或协议也可得到支持。除了经由无线lan标准进行通信之外或代替经由无线lan标准进行通信,网络接口1280可以使用例如时分多址(tdma)协议、全球移动通信系统(gsm)协议、码分多址(cdma)协议、长期演进(lte)协议和/或任何其他类型的无线通信协议来提供无线通信。
计算系统1200还可包括一个或多个能量源1205和一个或多个能量测量系统1245。能量源1205可包括耦接到外部电源的ac/dc适配器、一个或多个电池、一个或多个电荷存储设备、usb充电器,或其他能量源。能量测量系统包括至少一个电压或电流测量设备,其可测量计算系统1200在预先确定的时间段内消耗的能量。此外,可包括一个或多个能量测量系统测量,例如,显示设备,冷却子系统,wi-fi子系统,或其他常用的或高能量消费子系统所消耗的能量。
在一些实施方案中,本文所述的散列函数可利用系统(客户端设备或服务器)的专用硬件电路(或固件)。例如,该函数可以是硬件加速函数。此外,在一些实施方案中,系统可使用作为专用指令集的一部分的函数。例如,硬件可使用指令集,该指令集可为针对特定类型的微处理器的指令集架构的扩展。因此,在一个实施方案中,该系统可提供硬件加速机制以用于执行密码操作,从而提高使用这些指令集执行本文所述函数的速度。
此外,硬件加速引擎/功能被设想为包括硬件、固件或其组合中的任何实现,包括各种配置,这些配置可包括作为单独处理器集成到soc中的硬件/固件,或者包括为专用cpu(或核心),或者集成到电路板上的协处理器中,或者包含在扩展电路板的芯片上,等等。
应当指出的是,术语“大约”或“基本上”可在本文中使用,并且可被解释为“尽可能接近实际”、“在技术限制内”等。另外,除非另有说明,否则术语“或”的使用指示包含性的或(例如,和/或)。
如上所述,本主题技术的一个方面是采集和使用可得自各种特定和合法来源的数据以使能顺序数据的众包学习。本公开设想,在一些实例中,该所采集的数据可包括唯一地识别或可用于识别具体人员的个人信息数据。此类个人信息数据可以包括人口统计数据、基于位置的数据、在线标识符、电话号码、电子邮件地址、社交网络id、家庭地址、与用户的健康或健身级别相关的数据或记录(例如,生命体征测量、药物信息、锻炼信息)、出生日期或任何其他识别或个人信息。
本公开认识到在本发明技术中使用此类个人信息数据可用于使用户受益。例如,个人信息数据可用于学习新字词、改进键盘布局、改进用于键盘的自动纠正引擎,以及使电子设备能够更好地预期用户的需求。此外,本公开还预期个人信息数据有益于用户的其他用途。例如,健康和健身数据可根据用户的偏好来使用以提供对其总体健康状况的见解,或者可用作对使用技术来追求健康目标的个体的积极反馈。
本公开设想负责收集、分析、公开、传输、存储或其他使用此类个人信息数据的实体将遵守既定的隐私政策和/或隐私实践。具体地,将期望此类实体实现和一贯地应用一般公认为满足或超过维护用户隐私的行业或政府所要求的隐私实践。关于使用个人数据的此类信息应当被突出地并能够被用户方便地访问,并应当随数据的收集和/或使用变化而被更新。用户的个人信息应被收集仅用于合法使用。另外,此类收集/共享应仅发生在接收到用户同意或在适用法律中所规定的其他合法根据之后。此外,此类实体应考虑采取任何必要步骤,保卫和保障对此类个人信息数据的访问,并确保有权访问个人信息数据的其他人遵守其隐私政策和流程。另外,这种实体可使其本身经受第三方评估以证明其遵守广泛接受的隐私政策和实践。此外,应针对被收集和/或访问的特定类型的个人信息数据调整政策和实践,并使其适用于适用法律和标准,包括可用于施加较高标准的辖区专有的具体考虑因素。例如,在美国,对某些健康数据的收集或获取可能受联邦和/或州法律的管辖,诸如健康保险流通和责任法案(hipaa);而其他国家的健康数据可能受到其他法规和政策的约束并应相应处理。
不管前述情况如何,本公开还预期用户选择性地阻止使用或访问个人信息数据的实施方案。即本公开预期可提供硬件元件和/或软件元件,以防止或阻止对此类个人信息数据的访问。例如,本技术可被配置为允许用户在注册服务期间或其后随时选择参与采集个人信息数据的“选择加入”或“选择退出”。除了提供“选择加入”和“选择退出”选项外,本公开设想提供与访问或使用个人信息相关的通知。例如,可在下载应用时向用户通知其个人信息数据将被访问,然后就在个人信息数据被应用访问之前再次提醒用户。
此外,本公开的目的是应管理和处理个人信息数据以最小化无意或未经授权访问或使用的风险。一旦不再需要数据,通过限制数据收集和删除数据可最小化风险。此外,并且当适用时,包括在某些健康相关应用程序中,数据去标识可用于保护用户的隐私。可在适当时通过移除标识符、控制所存储数据的量或特异性(例如,在城市级别而不是在地址级别收集位置数据)、控制数据如何被存储(例如,在用户间汇集数据)和/或其他方法诸如差异化隐私来促进去标识。
因此,虽然本公开广泛地覆盖了使用个人信息数据来实现一个或多个各种所公开的实施方案,但本公开还预期各种实施方案也可在无需访问此类个人信息数据的情况下被实现。即,本发明技术的各种实施方案不会由于缺少此类个人信息数据的全部或一部分而无法正常进行。例如,序列的众包可在大量用户上执行,并且基于聚合的非个人信息数据。大量的个人用户可选择不向序列学习服务器发送数据,并且仍然可检测总体趋势。
在前面的说明中,已经描述了本公开的示例性实施方案。显而易见的是,在不脱离本公开的更广泛的实质和范围的情况下,可对其进行各种修改。相应地,说明书和附图被视为是例示性意义而不是限定性意义。所提供的描述和示例中的具体细节可用于一个或多个实施方案中的任何地方。不同实施方案或示例的各种特征可与所包括的一些特征和排除的其他特征不同地组合,以适应多种不同的应用。示例可包括主题,诸如方法,用于执行该方法的行为的装置,包括指令的至少一种机器可读介质,所述指令在由机器执行时使得机器执行该方法的行为,或者根据本文所述的实施方案和示例执行装置或系统的动作。另外,本文描述的各种部件可以是用于执行本文描述的操作或功能的装置。
本文所述的实施方案提供了一种技术用于众包机器学习模型的训练数据的标记,同时保持众包参与方提供的数据的隐私。客户端设备可用于生成要在训练数据集中使用的数据的单元的所提议的标签。在将数据传输给服务器时,使用一个或多个隐私机制来保护用户数据。
一个实施方案提供一种数据处理系统,该数据处理系统包括用于存储指令的存储器设备和用于执行存储在存储器设备上的指令的一个或多个处理器。该指令使得该数据处理系统执行操作,该操作包括:向一组多个移动电子设备发送未标记的一组数据,该组多个移动电子设备用于生成用于该未标记的一组数据的一组所提议的标签,其中移动电子设备中的每一者包括第一机器学习模型的变体;从该组多个移动电子设备接收用于该未标记的一组数据的一组所提议的标签,该组所提议的标签被编码以掩蔽该组所提议的标签中每个所提议的标签的各个贡献者;处理该组所提议的标签以确定用于该未标记的一组数据的最频繁提议的标签;将该未标记的一组数据和最频繁提议的标签添加到第一训练集;以及使用该第一训练集训练第二机器学习模型,该第二机器学习模型位于服务器设备上。
一个实施方案提供了一种存储指令的非暂态机器可读介质,该指令用于使得一个或多个处理器执行操作,该操作包括:向一组多个移动电子设备发送未标记的一组数据,该组多个移动电子设备用于生成用于该未标记的一组数据的一组所提议的标签,其中该移动电子设备中的每一者包括第一机器学习模型;从该组多个移动电子设备接收用于该未标记的一组数据的一组所提议的标签,该组所提议的标签被编码以掩蔽对组所提议的标签的各个贡献者;处理该组所提议的标签以确定用于该未标记的一组数据的最频繁提议的标签的估计;将该未标记的一组数据和对应的最频繁提议的标签添加到第一训练集;以及使用该第一训练集训练第二机器学习模型,该第二机器学习模型位于服务器设备上。
一个实施方案提供了移动电子设备上的一种数据处理系统,该数据处理系统包括用于存储指令的存储器设备和用于执行存储在存储器设备上的指令的一个或多个处理器。该指令使得该一个或多个处理器选择移动电子设备上的一组数据;基于所选择的数据生成训练集;使用该训练集训练第一机器学习模型;从服务器接收未标记的一组数据;为该未标记的一组数据的元素生成所提议的标签;以及将一个或多个所提议的标签的私有化版本传输给服务器。
一个实施方案提供了一种存储指令的非暂态机器可读介质,该指令用于使得一个或多个处理器执行操作,该操作包括:选择移动电子设备上的一组数据;基于所选择的数据生成训练集;使用该训练集训练第一机器学习模型,该第一机器学习模型在移动电子设备上训练;从服务器接收未标记的一组数据;为该未标记的一组数据的元素生成所提议的标签;以及将所提议的标签的私有化版本传输给服务器。
一个实施方案提供一种数据处理系统,该数据处理系统包括用于存储指令的存储器设备和用于执行存储在存储器设备上的指令的一个或多个处理器。该指令使得该数据处理系统执行操作,该操作包括:向一组多个移动电子设备发送未标记的一组数据,该组多个移动电子设备用于生成用于该未标记的一组数据的一组所提议的标签,其中移动电子设备中的每一者包括第一机器学习模型的变体;从该组多个移动电子设备接收用于该未标记的一组数据的一组所提议的标签,该组所提议的标签被编码以掩蔽该组所提议的标签中每个所提议的标签的各个贡献者;处理该组所提议的标签以确定用于该未标记的一组数据的最频繁提议的标签;将该未标记的一组数据和最频繁提议的标签添加到第一训练集;以及使用该第一训练集训练第二机器学习模型,该第二机器学习模型位于服务器设备上。
一个实施方案提供了一种存储指令的非暂态机器可读介质,该指令用于使得一个或多个处理器执行操作,该操作包括:向一组多个移动电子设备发送未标记的一组数据,该组多个移动电子设备用于生成用于该未标记的一组数据的一组所提议的标签,其中该移动电子设备中的每一者包括第一机器学习模型;从该组多个移动电子设备接收用于该未标记的一组数据的一组所提议的标签,该组所提议的标签被编码以掩蔽对组所提议的标签的各个贡献者;处理该组所提议的标签以确定用于该未标记的一组数据的最频繁提议的标签的估计;将该未标记的一组数据和对应的最频繁提议的标签添加到第一训练集;以及使用该第一训练集训练第二机器学习模型,该第二机器学习模型位于服务器设备上。
一个实施方案提供了移动电子设备上的一种数据处理系统,该数据处理系统包括用于存储指令的存储器设备和用于执行存储在存储器设备上的指令的一个或多个处理器。该指令使得该一个或多个处理器选择移动电子设备上的一组数据;基于所选择的数据生成训练集;使用该训练集训练第一机器学习模型;从服务器接收未标记的一组数据;为该未标记的一组数据的元素生成所提议的标签;以及将一个或多个所提议的标签的私有化版本传输给服务器。
一个实施方案提供了一种存储指令的非暂态机器可读介质,该指令用于使得一个或多个处理器执行操作,该操作包括:选择移动电子设备上的一组数据;基于所选择的数据生成训练集;使用该训练集训练第一机器学习模型,该第一机器学习模型在移动电子设备上训练;从服务器接收未标记的一组数据;为该未标记的一组数据的元素生成所提议的标签;以及将所提议的标签的私有化版本传输给服务器。
通过附图以及通过上述具体实施方式,本实施方案的其他特征将显而易见。因此,在研究附图、说明书和所附权利要求时,这些实施方案的真正范围对于技能熟练的从业人员来说是显而易见的。
- 还没有人留言评论。精彩留言会获得点赞!