推断器生成装置、监视装置、推断器生成方法以及推断器生成程序与流程
1.本发明涉及推断器生成装置、监视装置、推断器生成方法以及推断器生成程序。
背景技术:
2.近年来,为了防止因为打瞌睡、身体状况突变等引起汽车交通事故,正在开发监视驾驶员的状态的技术。另外,针对实现汽车的自动驾驶的动向在不断加速。自动驾驶是指通过系统来控制汽车的操纵,但是,有时必须由驾驶员取代系统进行驾驶,因此,即使在自动驾驶中,也需要监视驾驶员是否处于能够进行驾驶操作的状态。在该自动驾驶期间有必要监视驾驶员的状态这一情况在联合国欧洲经济委员会(un
‑
ece)的政府间会议(wp29)中也得到确认。从这一点出发,也不断推进监视驾驶员的状态的技术开发。
3.作为推断驾驶员的状态的技术,例如在专利文献1中,提出了通过利用相机获取拍摄有乘客脸部的脸部图像数据,并对获取到的脸部图像数据进行解析,从而推断乘客的状态(例如困倦等)的装置。具体而言,专利文献1中提出的装置利用由神经网络等构成的学习完毕模型,根据从脸部图像数据提取的脸部的特征点来推断乘客的状态。由此,该装置能够根据脸部图像数据推断乘客的状态。
4.专利文献1:日本特开2007
‑
257043号公报
技术实现要素:
5.本申请发明者们发现,在如专利文献1等的现有方法中,存在如下的问题。即,若利用机器学习,则能够构建根据脸部图像数据推断对象者的状态的推断器。然而,在如专利文献1那样由人来设计所提取的脸部的特征点的情况下,从该特征点导出的特征量中未必始终表现出对象者的状态。因此,为了解决这样的问题,考虑以从脸部图像数据直接推断对象者的状态的方式训练神经网络等的学习模型。根据该方法,学习模型在学习过程中自动设计从脸部图像导出的特征量。因此,被训练的学习模型能够根据脸部图像数据适当地推断对象者的状态。但是,已知存在多个从训练数据(输入数据)导出正解数据的模型的局部性的最优解,神经网络等的学习模型的参数在机器学习的过程中趋向任一局部解。因此,在机器学习的过程中,学习模型的参数有可能趋向根据脸部图像数据推断对象者的状态的精度比较低的局部解。
6.因此,本申请的发明人们发现,在现有的方法中,存在可能无法构建能够根据脸部图像数据高精度地推断对象者的状态的推断器(已学习完毕的学习模型)这一问题。此外,该问题不仅在如上所述推断驾驶员的状态的场景下产生,而且在推断生产线上的作业者的状态的场景等,根据通过观测对象者的活动而得到的观测数据来推断该对象者的状态的所有场景下都有可能产生。
7.本发明的一方面是鉴于上述实际情况而提出的,其目的在于,提供用于生成能够更高精度地推断对象者的状态的推断器的技术。
8.本发明为了解决上述问题而采用以下的构成。
9.即,本发明的一方面涉及的推断器生成装置具备学习数据获取部和学习处理部。学习数据获取部被构成为获取多件第一学习数据集并获取多件第二学习数据集,所述多件第一学习数据集分别由拍到驾驶车辆的受试者的脸部的第一脸部图像数据和表示驾驶所述车辆时的所述受试者的状态的第一状态信息数据的组合构成,所述多件第二学习数据集分别由拍到所述受试者的脸部的第二脸部图像数据和通过利用传感器测定所述受试者的生理学参数而得到的第一生理学数据的组合构成。学习处理部被构成为通过实施第一推断器的机器学习而构建第一推断器,并通过实施第二推断器的机器学习而构建第二推断器,所述第一推断器由编码器和推断部构成,且所述编码器和所述推断部以所述编码器的输出被输入至所述推断部的方式相互连接,所述第一推断器被训练为:当将构成各件所述第一学习数据集的所述第一脸部图像数据输入所述编码器时,从所述推断部输出与所述第一状态信息数据表示的所述受试者的状态对应的输出值,所述第一状态数据信息与输入的所述第一脸部图像数据建立关联;第二推断器由所述第一推断器的所述编码器和解码器构成,且所述编码器和所述解码器以所述编码器的输出被输入至所述解码器的方式相互连接,所述第二推断器被训练为:当将构成各件所述第二学习数据集的所述第二脸部图像数据输入所述编码器时,从所述解码器输出再现了与输入的所述第二脸部图像数据建立关联的所述第一生理学数据的输出数据。
10.根据该结构,第一推断器和第二推断器构成为具有共用的编码器。并且,第一推断器通过利用了多件第一学习数据集的机器学习,被训练为从第一脸部图像数据导出第一状态信息数据。另一方面,第二推断器通过利用了多件第二学习数据集的机器学习,被训练为从第二脸部图像数据导出第一生理学数据。因此,通过两者的机器学习,将共用的编码器的输出(特征量)设计成能够导出第一状态信息数据和第一生理学数据。
11.在此,与状态信息数据相比,生理学数据可包含与人的状态相关的高阶信息。因此,通过将共用的编码器训练为不仅能够导出第一状态信息数据,还能够导出可包含更高阶信息的第一生理学数据,能够使共用的编码器的参数趋向导出第一状态信息数据(即,推断对象者的状态)的精度更高的局部解。因此,根据该结构,能够生成可更高精度地推断对象者的状态的推断器(第一推断器)。
12.此外,第一脸部图像数据与第二脸部图像数据既可以通用,也可以互不相同。状态信息数据只要是能够表示对象者的某种状态的数据,便无特别限定,可以根据实施方式适当地选择。生理学数据通过利用一个或多个传感器测定与状态信息数据所表示的对象者的状态相关的生理学参数而得到。生理学数据既可以是从一个或多个传感器得到的原始数据,也可以是应用了某种信息处理的经加工数据。优选生理学数据以包含相比状态信息数据更高阶的与人的状态相关的信息的方式进行选择。生理学参数例如可以是脑活动(脑波、脑血流量等)、眼球运动(瞳孔直径、视线方向等)、肌肉电位、心电位、血压、脉搏、心跳、体温、皮肤电反应(galvanic skin reflex:gsr)或者它们的组合。传感器例如可以是脑电图仪、脑磁图仪、核磁共振成像装置、相机、眼电位传感器、眼球运动测量仪、肌电图仪、心电图仪、血压计、脉搏计、心率计、体温计、皮肤电反应仪或者它们的组合。相机除了rgb图像等的普通相机以外,还可以包括构成为能够获取深度图像的深度相机(距离相机、立体相机等)、构成为能够获取热成像图像的热成像相机(红外线相机等)等。眼球运动测量仪构成为测量
瞳孔直径的变化、视线方向等的眼球运动。眼球运动测量仪的测量对象的眼球运动既可以是随意运动,也可以是不随意运动。该眼球运动测量仪例如可以是瞳孔直径测量装置、视线测量装置等。瞳孔直径测量装置构成为测量对象者的瞳孔直径(的时间变化)。视线测量装置构成为测量对象者的视线方向(的时间变化)。各学习数据集也可以称为学习样本。各脸部图像数据也可以称为训练数据或输入数据。第一状态信息数据和第一生理学数据分别也可以称为正解数据或教师数据。各推断器由能够进行机器学习的学习模型构成。各推断器也可以称为学习器。
13.在上述一方面涉及的推断器生成装置中,构成各件所述第一学习数据集的所述第一脸部图像数据和所述第一状态信息数据可以在实际环境中收集,构成各件所述第二学习数据集的所述第二脸部图像数据和所述第一生理学数据可以在虚拟环境中收集。
14.实际环境是实际运用训练出的推断器(第一推断器)的环境或者与其同等的环境。实际环境例如是车辆内的空间、模仿车辆的结构物内的空间。另一发面,虚拟环境例如是实验室等非实际环境的环境。在虚拟环境中,相比于实际环境,能够使用更高性能的传感器收集表示人的状态的更高阶的信息。然而,在实际环境中,可能产生难以运用这样的高性能的传感器、或者即使能够运用也会使成本过高等问题。
15.例如,设想作为生理学数据而获取脑血流量的测定数据,以便作为对象者的状态而推断表示对象者的困倦程度的困倦度。在这样的情况下,作为用于收集生理学数据的传感器,使用构成为利用功能性核磁共振成像法(functional magnetic resonance imaging,fmri)拍摄与脑活动相关联的血流的磁共振成像装置。根据该磁共振成像装置,能够获取可更高精度地推断对象者的状态(困倦度)的生理学数据。然而,该磁共振成像装置非常大。因此,在实际环境(例如车内)中难以运用该磁共振成像装置。
16.因此,在该结构中,在实际环境中收集第一推断器的机器学习中使用的各第一学习数据集,而在虚拟环境中收集第二推断器的机器学习中使用的各第二学习数据集。由此,能够收集可包含表示受试者的状态的更高阶信息的第一生理学数据,通过利用该第一生理学数据的机器学习,能够使共用的编码器的参数趋向从能够在实际环境中容易地获取到的脸部图像数据导出对象者的状态的精度更高的局部解。因此,根据该结构,能够生成可以根据在实际环境下能够容易地获取到的数据更高精度地推断对象者的状态的推断器,由此,能够降低在实际环境下运用推断器所耗费的成本。
17.在上述一方面涉及的推断器生成装置中,所述生理学参数可以由脑活动、肌肉电位、心电位、眼球运动(尤其是瞳孔直径)或者它们的组合构成。根据该结构,能够获取包括表示受试者的状态的更高阶信息的第一生理学数据,由此,能够使共用的编码器的参数趋向导出第一状态信息数据的精度更高的局部解。因此,根据该结构,能够生成可更高精度地推断对象者的状态的推断器。此外,在这些生理学数据的测定中,例如可以使用脑电图仪(electroencephalograph:eeg)、脑磁图仪(magnetoencephalography:meg)、构成为通过功能性核磁共振成像法拍摄与脑活动相关的血流的核磁共振成像装置、肌电图仪、心电图仪、眼电位传感器、眼球运动测量仪(尤其是瞳孔直径测量装置)等。
18.在上述一方面涉及的推断器生成装置中,所述第一状态信息数据可以作为所述受试者的状态而包含表示所述受试者的困倦程度的困倦度、表示所述受试者的疲劳程度的疲劳度、表示所述受试者对于驾驶的余裕程度的余裕度、或者它们的组合。根据该结构,能够
生成可更高精度地推断困倦度、疲劳度、余裕度或者它们的组合的推断器。
19.在上述一方面涉及的推断器生成装置中,所述学习数据获取部可以构成为还获取多件第三学习数据集,所述多件第三学习数据集分别由拍到所述受试者的脸部的第三脸部图像数据和与所述第一生理学数据不同的所述受试者的第二生理学数据的组合构成;所述学习处理部可以构成为:通过与所述第一推断器和所述第二推断器的机器学习一同实施第三推断器的机器学习,从而进一步构建第三推断器,所述第三推断器由所述第一推断器的所述编码器和与所述第二推断器的所述解码器不同的其他解码器构成,且所述编码器和所述其他解码器以所述编码器的输出被输入至所述其他解码器的方式相互连接,所述第三推断器被训练为:当将构成各件所述第三学习数据集的所述第三脸部图像数据输入所述编码器时,从所述其他解码器输出再现了与输入的所述第三脸部图像数据建立关联的所述第二生理学数据的输出数据。根据该结构,在第三推断器的机器学习的过程中,共用的编码器的输出被设计成能够进一步导出第二生理学数据。由此,能够生成可更高精度地推断对象者的状态的推断器。此外,第三推断器的机器学习中利用的第二生理学数据也可以通过测定与第一生理学数据相同的生理学参数而得到。另外,也可以设置多个第三推断器。
20.在上述一方面涉及的推断器生成装置中,所述学习数据获取部可以构成为还获取多件第四学习数据集,所述多件第四学习数据集分别由所述受试者的第三生理学数据与表示所述受试者的状态的第二状态信息数据的组合构成。而且,所述学习处理部可以构成为:通过与所述第一推断器和所述第二推断器的机器学习一同实施第四推断器的机器学习,从而构建第四推断器,所述第四推断器由与所述第一推断器的所述编码器不同的其他编码器和所述第一推断器的所述推断部构成,且所述其他编码器与所述推断部以所述其他编码器的输出被输入至所述推断部的方式相互连接,所述第四推断器被训练为:当将构成各件所述第四学习数据集的所述第三生理学数据输入所述其他编码器时,从所述推断部输出与所述第二状态信息数据所表示的所述受试者的状态相对应的输出值,所述第二状态信息数据与输入的所述第三生理学数据建立关联,并且,在所述机器学习的过程中,将所述第一推断器和所述第四推断器训练为:当所述第一状态信息数据与所述第二状态信息数据一致时,使通过将与所述第一状态信息数据建立关联的所述第一脸部图像数据输入所述编码器而从所述编码器得到的输出值、与通过将与所述第二状态信息数据建立关联的所述第三生理学数据输入所述其他编码器而从所述其他编码器得到的输出值之间的误差小于阈值。
21.在该结构中,第四推断器被训练为从生理学数据导出对象者的状态。与从脸部图像数据相比,从生理学数据有望能够更高精度地推断对象者的状态。因此,与从脸部图像数据推断对象者的状态的推断器相比,该第四推断器有望能够更高精度地推断对象者的状态。因此,在该结构中,将该第四推断器中的其他编码器的输出用作用于更高精度地推断对象者的状态的第一推断器中的编码器的输出的样本。即,在机器学习的过程中,将第一推断器和第四推断器训练为:使编码器的输出与其他编码器的输出之间的误差小于阈值。由此,能够使第一推断器中的编码器的参数趋向推断对象者的状态的精度更高的局部解。因此,根据该结构,能够生成可更高精度地推断对象者的状态的推断器。
22.另外,本发明的一方面涉及的监视装置具备:数据获取部,获取拍到驾驶车辆的对象者的脸部的脸部图像数据;推断处理部,通过将获取到的所述脸部图像数据输入由上述任一方式涉及的推断器生成装置构建的所述第一推断器的所述编码器,从而从所述第一推
断器的所述推断部获取与所述对象者的状态的推断结果对应的输出;以及输出部,输出与所述对象者的状态的推断结果相关联的信息。根据该结构,能够高精度地推断对象者的状态。
23.另外,上述各方式涉及的推断器生成装置和监视装置不仅可以应用于推断车辆驾驶员的状态的场景,也可以应用于推断驾驶员以外的对象者的状态的所有场景,例如推断生产线的作业者的状态的场景等。进而,上述各方式涉及的推断器生成装置和监视装置不仅可以应用于根据拍到对象者脸部的脸部图像数据推断该对象者的状态的场景,还可以应用于根据通过观测对象者的活动而得到的观测数据推断对象者的状态的所有场景。例如,上述各方式涉及的推断器生成装置和监视装置可以应用于根据拍到对象者的图像数据来推断该对象者的状态的场景、根据图像数据以外的其他种类的数据来推断对象者的状态的场景等。
24.例如,本发明的一方面涉及的推断器生成装置具备:学习数据获取部,被构成为获取多件第一学习数据集并获取多件第二学习数据集,所述多件第一学习数据集分别由拍到执行规定作业的受试者的第一图像数据和表示执行所述规定作业时的所述受试者的状态的状态信息数据的组合构成,所述多件第二学习数据集分别由拍到所述受试者的第二图像数据和通过利用传感器测定所述受试者的生理学参数而得到的生理学数据的组合构成;以及学习处理部,被构成为通过实施第一推断器的机器学习而构建第一推断器,并通过实施第二推断器的机器学习而构建第二推断器,所述第一推断器由编码器和推断部构成,且所述编码器和所述推断部以所述编码器的输出被输入至所述推断部的方式相互连接,所述第一推断器被训练为:当将构成各件所述第一学习数据集的所述第一图像数据输入所述编码器时,从所述推断部输出与所述状态信息数据表示的所述受试者的状态对应的输出值,所述状态数据信息与输入的所述第一图像数据建立关联;第二推断器由所述第一推断器的所述编码器和解码器构成,且所述编码器和所述解码器以所述编码器的输出被输入至所述解码器的方式相互连接,所述第二推断器被训练为:当将构成各件所述第二学习数据集的所述第二图像数据输入所述编码器时,从所述解码器输出再现了与输入的所述第二图像数据建立关联的所述生理学数据的输出数据。此外,规定作业例如可以是车辆的驾驶、生产线上的作业等。
25.例如,本发明的一方面涉及的推断器生成装置具备:学习数据获取部,被构成为获取多件第一学习数据集并获取多件第二学习数据集,所述多件第一学习数据集分别由通过利用第一传感器测定执行规定作业的受试者的活动而得到的第一观测数据和表示执行所述规定作业时的所述受试者的状态的状态信息数据的组合构成,所述多件第二学习数据集分别由通过利用所述第一传感器测定所述受试者的活动而得到的第二观测数据和通过利用与所述第一传感器不同种类的第二传感器测定所述受试者的生理学参数而得到的生理学数据的组合构成;以及学习处理部,被构成为通过实施第一推断器的机器学习而构建第一推断器,并通过实施第二推断器的机器学习而构建第二推断器,所述第一推断器由编码器和推断部构成,且所述编码器和所述推断部以所述编码器的输出被输入至所述推断部的方式相互连接,所述第一推断器被训练为:当将构成各件所述第一学习数据集的所述第一观测数据输入所述编码器时,从所述推断部输出与所述状态信息数据表示的所述受试者的状态对应的输出值,所述状态数据信息与输入的所述第一观测数据建立关联;第二推断器
由所述第一推断器的所述编码器和解码器构成,且所述编码器和所述解码器以所述编码器的输出被输入至所述解码器的方式相互连接,所述第二推断器被训练为:当将构成各件所述第二学习数据集的所述第二观测数据输入所述编码器时,从所述解码器输出再现了与输入的所述第二观测数据建立关联的所述生理学数据的输出数据。
26.第一传感器和第二传感器也可以无特别限定,可以根据实施方式适当地选择。优选第二传感器构成为具有比第一传感器更高的功能,相比于第一传感器能够获取与人的状态相关的高阶信息。另一方面,优选第一传感器比第二传感器廉价。此外,判别两种数据中包含更高阶信息的数据的方法例如可以采用如下方法。即,准备由两种数据和受试者的状态的组合构成的学习样本。通过机器学习,并使用学习样本构建训练为从一方的数据导出受试者的状态的第一学习模型、以及被训练为从另一方的数据导出受试者的状态的第二学习模型。接着,准备由两种数据和对象者的状态(正解)的组合构成的评价样本。利用已学习完毕的第一学习模型,根据评价样本的一方的数据推断对象者的状态。同样地,利用已学习完毕的第二学习模型,根据评价样本的另一方的数据推断对象者的状态。然后,对各学习模型的推断精度进行评价。作为该评价的结果,在第一学习模型的导出精度比第二学习模型高的情况下,可以判定为一方的数据包含比另一方的数据更高阶的信息。相对于此,在第二学习模型的导出精度比第一学习模型高的情况下,可以判定为另一方的数据包含比一方的数据更高阶的信息。
27.在上述一方面涉及的推断器生成装置中,构成各件所述第一学习数据集的所述第一观测数据和所述状态信息数据可以在实际环境中收集;构成各件所述第二学习数据集的所述第二观测数据和所述生理学数据可以在虚拟环境中收集。根据该结构,能够生成可以根据在实际环境下能够容易地获取到的数据更高精度地推断对象者的状态的推断器,由此,能够降低在实际环境下运用推断器所耗费的成本。
28.在上述一方面涉及的推断器生成装置中,所述第一传感器可以由相机、眼电位传感器、视线测量装置、麦克风、血压计、脉搏计、心率计、体温计、皮肤电反应仪、载荷传感器、操作设备或者它们的组合构成;所述第二传感器可以由脑电图仪、脑磁图仪、核磁共振成像装置、肌电图仪、心电图仪、瞳孔直径测量装置或者它们的组合构成。根据该结构,能够生成可以根据在实际环境下能够容易地获取到的数据更高精度地推断对象者的状态的推断器,由此,能够降低在实际环境下运用推断器所耗费的成本。此外,载荷传感器既可以构成为测量一点的载荷,也可以构成为测量载荷分布。操作设备只要是作为状态推断对象的对象者能够操作的设备便无特别限定,其种类可以根据实施方式适当地选择。在对象者驾驶车辆的案例中,操作设备例如可以是方向盘、制动器、加速器等。通过第一传感器得到的观测数据例如由图像数据、眼电位数据、视线的测量数据、音频数据、血压数据、脉搏数数据、心率数据、体温数据、皮肤电反射数据、载荷的测量数据、操作日志或它们的组合构成。操作日志表示操作设备的操作历史。
29.作为上述各方式涉及的推断器生成装置和监视装置各自的其他方式,本发明的一方面既可以是实现以上各构成的信息处理方法,也可以是程序,还可以是存储这样的程序的计算机等可读的存储介质。在此,计算机等可读的存储介质是指通过电、磁、光学、机械或化学作用存储程序等信息的介质。另外,本发明的一方面涉及的推断系统也可以由上述任一方式涉及的推断器生成装置和监视装置构成。
30.例如,本发明的一方面涉及的推断器生成方法由计算机执行如下步骤:获取多件第一学习数据集的步骤,所述多件第一学习数据集分别由拍到驾驶车辆的受试者的脸部的第一脸部图像数据和表示驾驶所述车辆时的所述受试者的状态的状态信息数据的组合构成;获取多件第二学习数据集的步骤,所述多件第二学习数据集分别由拍到所述受试者的脸部的第二脸部图像数据和通过利用传感器测定所述受试者的生理学参数而得到的生理学数据的组合构成;以及通过实施第一推断器的机器学习而构建第一推断器,并通过实施第二推断器的机器学习而构建第二推断器的步骤,其中,所述第一推断器由编码器和推断部构成,且所述编码器和所述推断部以所述编码器的输出被输入至所述推断部的方式相互连接,所述第一推断器被训练为:当将构成各件所述第一学习数据集的所述第一脸部图像数据输入所述编码器时,从所述推断部输出与所述状态信息数据表示的所述受试者的状态对应的输出值,所述状态数据信息与输入的所述第一脸部图像数据建立关联;第二推断器由所述第一推断器的所述编码器和解码器构成,且所述编码器和所述解码器以所述编码器的输出被输入至所述解码器的方式相互连接,所述第二推断器被训练为:当将构成各件所述第二学习数据集的所述第二脸部图像数据输入所述编码器时,从所述解码器输出再现了与输入的所述第二脸部图像数据建立关联的所述生理学数据的输出数据。
31.另外,例如,本发明的一方面涉及的推断器生成程序用于使计算机执行如下步骤:获取多件第一学习数据集的步骤,所述多件第一学习数据集分别由拍到驾驶车辆的受试者的脸部的第一脸部图像数据和表示驾驶所述车辆时的所述受试者的状态的状态信息数据的组合构成;获取多件第二学习数据集的步骤,所述多件第二学习数据集分别由拍到所述受试者的脸部的第二脸部图像数据和通过利用传感器测定所述受试者的生理学参数而得到的生理学数据的组合构成;以及通过实施第一推断器的机器学习而构建第一推断器,并通过实施第二推断器的机器学习而构建第二推断器的步骤,其中,所述第一推断器由编码器和推断部构成,且所述编码器和所述推断部以所述编码器的输出被输入至所述推断部的方式相互连接,所述第一推断器被训练为:当将构成各件所述第一学习数据集的所述第一脸部图像数据输入所述编码器时,从所述推断部输出与所述状态信息数据表示的所述受试者的状态对应的输出值,所述状态数据信息与输入的所述第一脸部图像数据建立关联;所述第二推断器由所述第一推断器的所述编码器和解码器构成,且所述编码器和所述解码器以所述编码器的输出被输入至所述解码器的方式相互连接,所述第二推断器被训练为:当将构成各件所述第二学习数据集的所述第二脸部图像数据输入所述编码器时,从所述解码器输出再现了与输入的所述第二脸部图像数据建立关联的所述生理学数据的输出数据。
32.根据本发明,能够生成可更高精度地推断人的状态的推断器。
附图说明
33.图1示意性地例示出本发明的应用场景的一例。
34.图2示意性地例示出实施方式涉及的推断器生成装置的硬件构成的一例。
35.图3示意性地例示出实施方式涉及的监视装置的硬件构成的一例。
36.图4a示意性地例示出实施方式涉及的推断器生成装置的软件构成的一例。
37.图4b示意性地例示出实施方式涉及的推断器的机器学习的过程的一例。
38.图5示意性地例示出实施方式涉及的监视装置的软件构成的一例。
39.图6例示出实施方式涉及的推断器生成装置的处理步骤的一例。
40.图7例示出实施方式涉及的监视装置的处理步骤的一例。
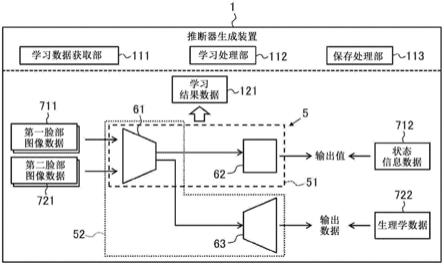
41.图8示意性地例示出变形例涉及的推断器生成装置的软件构成的一例。
42.图9示意性地例示出变形例涉及的推断器生成装置的软件构成的一例。
43.图10示意性地例示出本发明的应用场景的变形例。
44.图11示意性地例示出变形例涉及的推断器生成装置的软件构成的一例。
45.图12示意性地例示出变形例涉及的监视装置的软件构成的一例。
46.图13示意性地例示出变形例涉及的推断器生成装置的软件构成的一例。
47.图14示意性地例示出变形例涉及的监视装置的软件构成的一例。
具体实施方式
48.以下,根据附图对本发明的一方面涉及的实施方式(以下,也表述为“本实施方式”)进行说明。但是,以下说明的本实施方式在所有方面都仅为本发明的例示。当然,能够在不脱离本发明的范围的情况下进行各种改良和变形。即,在实施本发明时,也可以适当地采用符合实施方式的具体构成。需要说明的是,本实施方式中利用自然语言来说明出现的数据,但是,更为具体而言,利用计算机可识别的模拟语言、命令、参数、机器语言等来指定。
49.§
1应用例
50.首先,使用图1对本发明的应用场景的一例进行说明。图1示意性地例示出本实施方式涉及的推断系统100的应用场景的一例。在图1的例子中,设想为从脸部图像数据导出驾驶车辆的驾驶员的状态的场景。车辆的驾驶是本发明的“规定作业”的一例,脸部图像数据是本发明的“图像数据”及“观测数据”的一例。但是,本发明的应用对象也可以不限于这样的例子。本发明能够广泛应用于根据观测数据推断对象者的状态的场景中。
51.如图1所示,本实施方式涉及的推断系统100具备经由网络相互连接的推断器生成装置1和监视装置2。由此,本实施方式涉及的推断系统100被构成为:根据脸部图像数据生成用于推断对象者的状态的推断器,并通过生成的推断器推断驾驶员的状态。推断器生成装置1与监视装置2之间的网络的种类可以从例如因特网、无线通信网、移动通信网、电话网、专用网等适当地选择。
52.本实施方式涉及的推断器生成装置1是被构成为通过实施机器学习而构建用于根据脸部图像数据推断对象者的状态的推断器(第一推断器51)的计算机。具体而言,首先,本实施方式涉及的推断器生成装置1获取多件第一学习数据集71及多件第二学习数据集72。
53.各件第一学习数据集71由拍到驾驶车辆的受试者t的脸部的第一脸部图像数据711和表示驾驶车辆时的受试者t的状态的状态信息数据712的组合构成。第一脸部图像数据711例如可以在车辆内的空间(实际环境)中通过配置为能够拍摄坐在驾驶席上的受试者t的脸部的相机31得到。状态信息数据712是本发明的“第一状态信息数据”的一例。作为机器学习对象的对象者的状态例如可以是表示困倦程度的困倦度、表示疲劳程度的疲劳度、表示对于驾驶的余裕程度的余裕度、或者它们的组合。与之相应地,状态信息数据712例如可以构成为:作为受试者t的状态而包含表示受试者t的困倦程度的困倦度、表示受试者t的疲劳程度的疲劳度、表示受试者t对于驾驶的余裕程度的余裕度、或者它们的组合。
54.另一方面,各件第二学习数据集72由拍到受试者t的脸部的第二脸部图像数据721
和利用一个或多个传感器测定受试者t的生理学参数而得到的生理学数据722的组合构成。例如,第二脸部图像数据721可以在实验室等的虚拟环境中通过配置为能够拍摄受试者t的脸部的相机32得到。另外,生理学数据722是本发明的“第一生理学数据”的一例。生理学数据722例如可以通过利用脑电图仪33测定脑波而得到。脑波是本发明的“生理学参数”的一例,脑电图仪33是本发明的“传感器”的一例。各相机(31、32)的种类并无特别限定,可以根据实施方式适当地选择。各相机(31、32)除了例如数码相机、摄像机等普通的相机以外,也可以使用构成为能够获取深度图像的深度相机(距离相机、立体相机等)、构成为能够获取热成像图像的热成像相机(红外线相机等)等。
55.接着,本实施方式涉及的推断器生成装置1利用所获取到的多件第一学习数据集71和多件第二学习数据集72实施学习网络5的机器学习。本实施方式涉及的学习网络5具备第一推断器51和第二推断器52。第一推断器51由编码器61和推断部62构成。编码器61和推断部62以编码器61的输出被输入至推断部62的方式相互连接。第二推断器52由第一推断器51的编码器61和解码器63构成。即,在本实施方式中,第一推断器51和第二推断器52具有共用的编码器61。编码器61及解码器63以编码器61的输出被输入至解码器63的方式相互连接。
56.本实施方式涉及的推断器生成装置1利用多件第一学习数据集71实施第一推断器51的机器学习。由此,推断器生成装置1构建第一推断器51,该第一推断器51被训练为:当将构成各件第一学习数据集71的第一脸部图像数据711输入编码器61时,从推断部62输出与状态信息数据712所表示的受试者t的状态相对应的输出值,该状态信息数据712与输入的第一脸部图像数据711建立关联。另外,本实施方式涉及的推断器生成装置1利用多个第二学习数据集72实施第二推断器52的机器学习。由此,推断器生成装置1构建第二推断器52,该第二推断器52被训练为:当将构成各件第二学习数据集72的第二脸部图像数据721输入编码器61时,从解码器63输出将与输入的第二脸部图像数据721建立关联的生理学数据722再现的输出数据。通过上述机器学习,生成用于根据脸部图像数据推断对象者的状态的推断器(第一推断器51)。
57.另一方面,本实施方式涉及的监视装置2是构成为利用由推断器生成装置1生成的已学习完毕的推断器(第一推断器51),根据脸部图像数据推断驾驶车辆的驾驶员d的状态的计算机。具体而言,监视装置2首先获取拍到驾驶车辆的驾驶员d的脸部的脸部图像数据。驾驶员d是本发明的“对象者”的一例。脸部图像数据例如可以通过配置为能够拍摄坐在驾驶席上的驾驶员d的脸部的相机41得到。
58.接着,本实施方式涉及的监视装置2通过将所获取到的脸部图像数据输入由推断器生成装置1构建的第一推断器51的编码器61,从而从第一推断器51的推断部62获取与驾驶员d的状态的推断结果对应的输出。由此,监视装置2推断驾驶员d的状态。然后,监视装置2输出与驾驶员d的状态的推断结果建立关联的信息。
59.如上所述,在本实施方式中,第一推断器51和第二推断器52构成为具有共用的编码器61。第一推断器51通过利用多件第一学习数据集71进行机器学习而被训练,以根据脸部图像数据推断对象者的状态。另一方面,第二推断器52通过利用多件第二学习数据集72进行机器学习而被训练,以根据脸部图像数据再现对象者的生理学现象。因此,通过两个推断器(51、52)的机器学习,共用的编码器61的输出(特征量)被设计成能够从脸部图像数据
导出对象者的状态及生理学现象。
60.在此,与状态信息数据712相比,生理学数据722可包含与人的状态相关的高阶信息。例如,当通过脑电图仪33得到生理学数据722时,生理学数据722包含与人的脑活动相关的信息。相对于此,由状态信息数据712表示的人的状态是困倦度、疲劳度、余裕度、或者它们的组合。当利用关于人的脑活动的信息时,能够导出困倦度、疲劳度以及余裕度,并且也能够导出其他的人的状态。因此,与状态信息数据712相比,生理学数据722包含与人的状态相关的高阶信息。
61.因此,通过将共用的编码器61训练为不仅能够导出状态信息数据712,还能够导出可包含更高阶信息的生理学数据722,能够使共用的编码器61的参数趋向导出状态信息数据712(即,推断对象者的状态)的精度更高的局部解。因此,根据本实施方式涉及的推断器生成装置1,能够生成可更高精度地推断对象者的状态的推断器(第一推断器51)。
62.此外,当第一学习数据集71和第二学习数据集72的件数充分时,共用的编码器61被适当地训练,以输出能够导出人的状态及生理学现象两者的特征量。因此,当第一学习数据集71和第二学习数据集72中的任一方的件数少时,能够通过另一方来补偿机器学习中利用的学习样本的件数。因此,根据本实施方式,能够生成可更高精度地推断对象者的状态的推断器,而且不会导致收集学习样本的成本大幅增大。本实施方式涉及的监视装置2通过利用这样的第一推断器51,能够高精度地推断驾驶员d的状态。
63.此外,在图1的例子中,推断器生成装置1和监视装置2为分开独立的计算机。然而,推断系统100的构成也可以不限定于这样的例子。推断器生成装置1和监视装置2也可以由一体的计算机构成。另外,推断器生成装置1和监视装置2也可以分别由多台计算机构成。进而,推断器生成装置1和监视装置2也可以不与网络连接。该情况下,也可以经由非易失性存储器等的存储介质来进行推断器生成装置1与监视装置2之间的数据交换。
64.§
2构成例
65.[硬件构成]
[0066]
<推断器生成装置>
[0067]
接着,使用图2对本实施方式涉及的推断器生成装置1的硬件构成的一例进行说明。图2示意性地例示出本实施方式涉及的推断器生成装置1的硬件构成的一例。
[0068]
如图2所示,本实施方式涉及的推断器生成装置1是与控制部11、存储部12、通信接口13、输入装置14、输出装置15以及驱动器16电连接的计算机。需要说明的是,在图2中,将通信接口记载为“通信i/f”。
[0069]
控制部11构成为包含作为硬件处理器的cpu(central processing unit:中央处理器)、ram(random access memory:随机存取存储器)、rom(read only memory:只读存储器)等,并根据程序和各种数据执行信息处理。存储部12是存储器的一例,例如由硬盘驱动器、固态驱动器等构成。在本实施方式中,存储部12存储推断器生成程序81、多件第一学习数据集71、多件第二学习数据集72、学习结果数据121等的各种信息。
[0070]
推断器生成程序81是用于使推断器生成装置1执行后述的机器学习的信息处理(图6),构建用于根据脸部图像数据推断对象者的状态的已学习完毕的推断器(第一推断器51)的程序。推断器生成程序81包含该信息处理的一系列的命令。多件第一学习数据集71以及多件第二学习数据集72在该机器学习中使用。学习结果数据121是用于进行通过机器学
习构建的已学习完毕的推断器(第一推断器51)的设定的数据。学习结果数据121作为推断器生成程序81的执行结果而生成。之后详细进行叙述。
[0071]
通信接口13例如为有线lan(local area network:局域网)模块、无线lan模块等,且是用于经由网络进行有线或无线通信的接口。推断器生成装置1通过利用该通信接口13,能够经由网络与其他的信息处理装置(例如监视装置2)进行数据通信。
[0072]
输入装置14例如是鼠标、键盘等用于进行输入的装置。另外,输出装置15例如是显示器、扬声器等用于进行输出的装置。操作者能够利用输入装置14和输出装置15来操作推断器生成装置1。
[0073]
驱动器16例如是cd驱动器、dvd驱动器等,且是用于读取存储介质91中存储的程序的驱动装置。驱动器16的种类可以根据存储介质91的种类适当地选择。上述推断器生成程序81、多件第一学习数据集71以及多件第二学习数据集72的至少任意一个也可以存储于该存储介质91中。
[0074]
存储介质91是以计算机及其他装置、机械等能够读取所记录的程序等信息的方式,通过电、磁、光学、机械或化学作用存储该程序等信息的介质。推断器生成装置1也可以从该存储介质91获取上述推断器生成程序81、多件第一学习数据集71以及多件第二学习数据集72中的至少任意一个。
[0075]
在此,在图2中,作为存储介质91的一例,例示了cd、dvd等的盘式存储介质。但是,存储介质91的种类并不限定于盘式,也可以是盘式以外的类型。作为盘式以外的存储介质,例如可以举出闪存等的半导体存储器。
[0076]
此外,关于推断器生成装置1的具体的硬件构成,能够根据实施方式适当地省略、替换以及追加构成要素。例如,控制部11也可以包含多个硬件处理器。硬件处理器可以由微处理器、fpga(field
‑
programmable gate array:现场可编程门阵列)、dsp(digital signal processor:数字信号处理器)等构成。存储部12也可以由控制部11所包含的ram及rom构成。也可以省略通信接口13、输入装置14、输出装置15以及驱动器16中的至少任意一个。推断器生成装置1也可以还具备用于与各相机(31、32)以及脑电图仪33连接的外部接口。该外部接口可以与监视装置2的后述外部接口24同样地构成。推断器生成装置1也可以由多台计算机构成。该情况下,各计算机的硬件构成既可以一致,也可以不一致。另外,推断器生成装置1除了被设计为所提供的服务专用的信息处理装置之外,也可以是通用的服务器装置、pc(personal computer:个人计算机)等。
[0077]
<监视装置>
[0078]
接着,使用图3对本实施方式涉及的监视装置2的硬件构成的一例进行说明。图3示意性地例示出本实施方式涉及的监视装置2的硬件构成的一例。
[0079]
如图3所示,本实施方式涉及的监视装置2是与控制部21、存储部22、通信接口23、外部接口24、输入装置25、输出装置26以及驱动器27电连接的计算机。此外,在图3中,通信接口和外部接口分别记载为“通信i/f”和“外部i/f”。
[0080]
监视装置2的控制部21~通信接口23以及输入装置25~驱动器27可以分别与上述推断器生成装置1的控制部11~驱动器16同样地构成。即,控制部21构成为包括作为硬件处理器的cpu、ram、rom等,并根据程序及数据来执行各种信息处理。存储部22例如由硬盘驱动器、固态驱动器等构成。存储部22存储监视程序82、学习结果数据121等的各种信息。
[0081]
监视程序82是用于使监视装置2执行利用已学习完毕的第一推断器51来监视驾驶员d的状态的后述信息处理(图7)的程序。监视程序82包含该信息处理的一系列的命令。学习结果数据121在该信息处理时用于设定已学习完毕的第一推断器51。之后详细进行叙述。
[0082]
通信接口23例如是有线lan模块、无线lan模块等,且是用于经由网络进行有线或无线通信的接口。监视装置2通过利用该通信接口23,能够经由网络与其他的信息处理装置(例如推断器生成装置1)进行数据通信。
[0083]
外部接口24例如是usb(universal serial bus:通用串行总线)端口、专用端口等,且是用于与外部装置连接的接口。外部接口24的种类及数量可以根据所连接的外部装置的种类及数量适当地选择。在本实施方式中,监视装置2经由外部接口24与相机41连接。
[0084]
相机41用于通过拍摄驾驶员d的脸部来获取脸部图像数据。相机41的种类和配置位置并无特别限定,可以根据实施方式适当地决定。相机41例如可以使用与上述各相机(31、32)相同种类的相机。另外,相机41例如可以配置在驾驶席的前方上方,至少以驾驶员d的上半身为拍摄范围。此外,当相机41具备通信接口时,监视装置2也可以经由通信接口23与相机41连接,而不是外部接口24。
[0085]
输入装置25例如是鼠标、键盘等用于进行输入的装置。另外,输出装置26例如是显示器、扬声器等用于进行输出的装置。驾驶员d等的操作者能够利用输入装置25和输出装置26来操作监视装置2。
[0086]
驱动器27例如是cd驱动器、dvd驱动器等,且是用于读取存储介质92中存储的程序的驱动装置。上述监视程序82及学习结果数据121中的至少任意一个也可以存储于存储介质92中。另外,监视装置2也可以从存储介质92获取上述监视程序82和学习结果数据121中的至少任意一个。
[0087]
此外,关于监视装置2的具体的硬件构成,与上述推断器生成装置1同样,可以根据实施方式适当地省略、替换以及追加构成要素。例如,控制部21也可以包含多个硬件处理器。硬件处理器可以由微处理器、fpga、dsp等构成。存储部22也可以由控制部21所包含的ram及rom构成。也可以省略通信接口23、外部接口24、输入装置25、输出装置26以及驱动器27中的至少任意一个。监视装置2也可以由多台计算机构成。该情况下,各计算机的硬件构成既可以一致,也可以不一致。另外,监视装置2除了设计为所提供的服务专用的信息处理装置以外,也可以使用通用的服务器装置、通用的台式pc、笔记本pc、平板pc、包括智能手机的便携电话等。
[0088]
[软件构成]
[0089]
接着,使用图4a对本实施方式涉及的推断器生成装置1的软件构成的一例进行说明。图4a示意性地例示出本实施方式涉及的推断器生成装置1的软件构成的一例。
[0090]
推断器生成装置1的控制部11将存储在存储部12中的推断器生成程序81加载至ram中。然后,控制部11通过由cpu对加载至ram中的程序81进行解释和执行,从而对各构成要素进行控制。由此,如图4a所示,本实施方式涉及的推断器生成装置1作为以软件模块的形式具备学习数据获取部111、学习处理部112以及保存处理部113的计算机进行动作。即,在本实施方式中,推断器生成装置1的各软件模块通过控制部11(cpu)实现。
[0091]
学习数据获取部111获取分别由拍到驾驶车辆的受试者t的脸部的第一脸部图像数据711和表示驾驶车辆时的受试者t的状态的状态信息数据712的组合构成的多件第一学
习数据集71。第一脸部图像数据711例如可以在车辆内的空间(实际环境)中通过配置为能够拍摄坐在驾驶席上的受试者t的脸部的相机31得到。状态信息数据712例如可以构成为:作为受试者t的状态而包含表示受试者t的困倦程度的困倦度、表示受试者t的疲劳程度的疲劳度、表示受试者t对于驾驶的余裕程度的余裕度、或者它们的组合。
[0092]
另外,学习数据获取部111获取多件第二学习数据集72,该多件第二学习数据集72分别由拍到受试者t的脸部的第二脸部图像数据721和利用一个或多个传感器测定受试者t的生理学参数而得到的生理学数据722的组合构成。例如,第二脸部图像数据721可以在实验室等的虚拟环境中通过配置为能够拍摄受试者t的脸部的相机32得到。另外,生理学数据722例如可以通过利用脑电图仪33测定脑波而得到。
[0093]
学习处理部112利用多件第一学习数据集71和多件第二学习数据集72实施学习网络5的机器学习。具体而言,学习处理部112通过利用多件第一学习数据集71实施第一推断器51的机器学习,从而构建被训练成根据脸部图像数据推断对象者的状态的第一推断器51。与此同时,学习处理部112通过利用多件第二学习数据集72实施第二推断器52的机器学习,从而构建被训练成根据脸部图像数据再现生理学数据的第二推断器52。保存处理部113将与所构建的已学习完毕的第一推断器51相关的信息作为学习结果数据121保存至存储部12。
[0094]
此外,“推断”例如可以是通过分组(分类、识别)导出离散值(类)、以及通过回归导出连续值中的任意一个。状态信息数据712的形式可以根据表示受试者t的状态的形态适当地选择。如上所述,状态信息数据712可以构成为:作为受试者t的状态而包含受试者t的困倦度、疲劳度、余裕度或者它们的组合。在以连续值表现困倦度、疲劳度以及余裕度的情况下,状态信息数据712可以由连续值的数值数据构成。另外,在以离散值表现困倦度、疲劳度以及余裕度的情况下,状态信息数据712可以由离散值(例如表示类)的数值数据构成。
[0095]
(学习网络)
[0096]
接着,进一步使用图4b对学习网络5的构成的一例进行说明。如图4a和图4b所示,本实施方式涉及的学习网络5具备编码器61、推断部62以及解码器63。编码器61构成为从脸部图像数据导出特征量。推断部62构成为根据特征量导出对象者的状态。解码器63构成为从特征量再现生理学数据。编码器61和推断部62以编码器61的输出被输入至推断部62的方式相互连接。第一推断器51由编码器61和推断部62构成。另一方面,编码器61和解码器63以编码器61的输出被输入至解码器63的方式相互连接。第二推断器52由编码器61和解码器63构成。编码器61、推断部62以及解码器63的构成只要使用能够进行机器学习的学习模型,便无特别限定,可以根据实施方式适当地选择。
[0097]
如图4b所示,在本实施方式中,编码器61由所谓的深度学习中使用的多层结构的神经网络构成,具备输入层611、中间层(隐藏层)612以及输出层613。推断部62具备全连接层621。解码器63与编码器61同样由多层结构的神经网络构成,具备输入层631、中间层(隐藏层)632以及输出层633。
[0098]
此外,在图4b的例子中,构成编码器61的神经网络具有一层中间层612。但是,编码器61的构成也可以不限定于这样的例子。中间层612的数量也可以不限于一层,编码器61也可以具备两层以上的中间层612。关于解码器63也是同样的。中间层632的数量也可以不限于一层,解码器63也可以具备两层以上的中间层632。同样地,推断部62的构成也可以不限
定于这样的例子。推断部62也可以由多层结构的神经网络构成。
[0099]
各层(611~613、621、631~633)具备一个或多个神经元(节点)。各层(611~613、621、631~633)的神经元的数量可以根据实施方式适当地设定。例如,输入层611的神经元的数量可以根据所输入的脸部图像数据的像素数来设定。全连接层621的神经元的数量可以根据作为推断对象的对象者的状态的种类数、状态的表现方法等来设定。输出层633的神经元的数量可以根据再现生理学数据的形式来设定。
[0100]
相邻层的神经元彼此适当地连接,各连接设定有权重(连接权)。在图4b的例子中,各神经元与相邻层的全部的神经元连接。然而,神经元的连接也可以不限定于这样的例子,也可以根据实施方式适当地设定。
[0101]
各神经元中设定有阈值,基本来说,根据各输入与各权重之积的和是否超过阈值来决定各神经元的输出。各层611~613所包含的各神经元间的连接的权重以及各神经元的阈值是运算处理中利用的编码器61的参数的一例。全连接层621所包含的各神经元间的连接的权重以及各神经元的阈值是推断部62的参数的一例。各层631~633所包含的各神经元间的连接的权重以及各神经元的阈值是解码器63的参数的一例。
[0102]
在第一推断器51的机器学习中,学习处理部112针对各第一学习数据集71,将第一脸部图像数据711输入编码器61的输入层611,利用编码器61及推断部62的参数执行第一推断器51的运算处理。作为该运算处理的结果,学习处理部112从推断部62的全连接层621获取与从第一脸部图像数据711推断对象者(该情况下为受试者t)的状态的结果对应的输出值。接着,学习处理部112计算获取到的输出值和与状态信息数据712对应的值之间的误差。然后,学习处理部112对第一推断器51(编码器61及推断部62)的参数的值进行调节,以使计算出的误差之和变小。学习处理部112反复调节第一推断器51的参数的值,直到从全连接层621得到的输出值和与状态信息数据712对应的值的误差之和变为阈值以下为止。由此,学习处理部112能够构建如下所述被训练的第一推断器51,即:当将构成各件第一学习数据集71的第一脸部图像数据711输入编码器61时,从推断部62输出与状态信息数据712所表示的受试者t的状态相对应的输出值,该状态信息数据712与输入的第一脸部图像数据711建立关联。
[0103]
同样地,在第二推断器52的机器学习中,学习处理部112针对各第二学习数据集72,将第二脸部图像数据721输入编码器61的输入层611,利用编码器61及解码器63的参数执行第二推断器52的运算处理。作为该运算处理的结果,学习处理部112从解码器63的输出层633获取与从第二脸部图像数据721再现对象者(该情况下为受试者t)的生理学数据的结果对应的输出数据。接着,学习处理部112计算获取到的输出数据与生理学数据722的误差。然后,学习处理部112对第二推断器52(编码器61及解码器63)的参数的值进行调节,以使计算出的误差之和变小。学习处理部112反复调节第二推断器52的参数的值,直到从输出层633得到的输出数据与生理学数据722的误差之和变为阈值以下为止。由此,学习处理部112能够构建如下所述被训练的第二推断器52,即:当将构成各件第二学习数据集72的第二脸部图像数据721输入编码器61时,从解码器63输出再现了与输入的第二脸部图像数据721建立关联的生理学数据722的输出数据。
[0104]
在这些机器学习结束之后,保存处理部113生成表示构建的已学习完毕的第一推断器51的构成(例如,神经网络的层数、各层中的神经元的个数、神经元彼此的连接关系、各
神经元的传递函数)以及运算参数(例如,各神经元间的连接的权重、各神经元的阈值)的学习结果数据121。然后,保存处理部113将生成的学习结果数据121保存至存储部12中。
[0105]
<监视装置>
[0106]
接着,使用图5对本实施方式涉及的监视装置2的软件构成的一例进行说明。图5示意性地例示出本实施方式涉及的监视装置2的软件构成的一例。
[0107]
监视装置2的控制部21将存储在存储部22中的监视程序82加载至ram中。然后,控制部21通过cpu对加载至ram中的监视程序82进行解释和执行,从而对各构成要素进行控制。由此,如图5所示,本实施方式涉及的监视装置2作为以软件模块的形式具备数据获取部211、推断处理部212以及输出部213的计算机进行动作。即,在本实施方式中,监视装置2的各软件模块也与上述推断器生成装置1同样地通过控制部21(cpu)实现。
[0108]
数据获取部211获取拍到驾驶车辆的驾驶员d的脸部的脸部图像数据221。例如,数据获取部211通过利用相机41拍摄驾驶员d的脸部来获取脸部图像数据221。推断处理部212通过保持学习结果数据121而包括已学习完毕的第一推断器51。推断处理部212参照学习结果数据121进行已学习完毕的第一推断器51的设定。然后,推断处理部212通过将所获取到的脸部图像数据221输入已学习完毕的第一推断器51的编码器61,从第一推断器51的推断部62获取与驾驶员d的状态的推断结果对应的输出。输出部213输出与驾驶员d的状态的推断结果建立关联的信息。
[0109]
<其他>
[0110]
关于推断器生成装置1及监视装置2的各软件模块,在后述的动作例中详细进行说明。此外,在本实施方式中,对推断器生成装置1和监视装置2的各软件模块均通过通用的cpu实现的例子进行说明。但是,以上的软件模块的一部分或全部也可以通过一个或多个专用的处理器实现。另外,关于推断器生成装置1和监视装置2各自的软件构成,也可以根据实施方式适当地省略、替换以及追加软件模块。
[0111]
§
3动作例
[0112]
[推断器生成装置]
[0113]
接着,使用图6对推断器生成装置1的动作例进行说明。图6是表示本实施方式涉及的推断器生成装置1的处理步骤的一例的流程图。以下说明的处理步骤是本发明的“推断器生成方法”的一例。但是,以下说明的处理步骤仅为一例,各处理也可以在可能的范围内进行变更。另外,对于以下说明的处理步骤,可以根据实施方式适当地省略、替换以及追加步骤。
[0114]
(步骤s101)
[0115]
在步骤s101中,控制部11作为学习数据获取部111进行动作,获取分别由第一脸部图像数据711和状态信息数据712的组合构成的多件第一学习数据集71。另外,控制部11获取分别由第二脸部图像数据721和生理学数据722的组合构成的多件第二学习数据集72。
[0116]
多件第一学习数据集71的获取方法没有特别限定,可以根据实施方式适当地选择。例如,可以准备搭载有相机31的车辆或者模仿车辆的结构物及受试者t,并利用相机31在各种条件下拍摄驾驶车辆的受试者t,从而获取拍到受试者t的脸部的第一脸部图像数据711。所准备的车辆或者模仿车辆的结构物及受试者t的数量可以根据实施方式适当地决定。然后,通过对得到的第一脸部图像数据711组合表示受试者t的状态的状态信息数据
712,从而能够生成各第一学习数据集71。
[0117]
第一脸部图像数据711的数据形式可以根据实施方式适当地选择。状态信息数据712只要是表示受试者t的某种状态的数据即可,也可以不特别限定。状态信息数据712例如可以构成为:作为受试者t的状态而包含受试者t的困倦度、疲劳度、余裕度或者它们的组合。另外,作为第一学习数据集71而相互对应的第一脸部图像数据711和状态信息数据712并不一定必须在时间上一致。例如,状态信息数据712既可以构成为表示与为了得到第一脸部图像数据711而拍摄受试者t的脸部的时刻(以下称为“拍摄时刻”)一致的时刻的受试者t的状态,也可以构成为表示与第一脸部图像数据711的拍摄时刻错开的时刻(例如,未来的时刻)的受试者t的状态。但是,为了保证能够从第一脸部图像数据711导出受试者t的状态,优选第一脸部图像数据711的摄影时刻与状态信息数据712所表示的受试者t的状态的时刻具有关联性。
[0118]
同样地,多件第二学习数据集72的获取方法也无特别限定,可以根据实施方式适当地选择。例如,准备相机32、脑电图仪33以及受试者t,利用相机32在各种条件下拍摄受试者t,并利用脑电图仪33测量受试者t的脑波。所准备的相机32、脑电图仪33以及受试者t的数量可以根据实施方式适当地决定。参与获取第一学习数据集71的受试者与参与获取第二学习数据集72的受试者既可以一致,也可以不一致。通过将由此得到的第二脸部图像数据721和生理学数据722组合,从而能够生成各第二学习数据集72。
[0119]
第二脸部图像数据721的数据形式可以根据实施方式适当地选择。生理学数据722只要是利用一个或多个传感器测定能够与状态信息数据712所表示的受试者t的状态相关的生理学参数而得到的数据,则也可以不限定于上述脑波的测定数据。生理学参数例如可以是脑活动(脑波、脑血流量等)、眼球运动(瞳孔直径、视线方向等)、肌肉电位、心电位、血压、脉搏、心跳、体温、皮肤电反应或者它们的组合。传感器例如可以是脑电图仪、脑磁图仪、核磁共振成像装置、相机、眼电位传感器、眼球运动测量仪、肌电图仪、心电图仪、血压计、脉搏计、心率计、体温计、皮肤电反应仪或者它们的组合。眼球运动测量仪构成为测量例如瞳孔直径的变化、视线方向等的眼球运动。眼球运动测量仪的测量对象的眼球运动既可以是随意运动,也可以是不随意运动。该眼球运动测量仪例如可以是瞳孔直径测量装置、视线测量装置等。瞳孔直径测量装置适当地构成为测量对象者的瞳孔直径(的时间变化)。视线测量装置适当地构成为测量对象者的视线方向(的时间变化)。优选生理学数据722以包含相比状态信息数据712更高阶的与人的状态相关的信息的方式进行选择。生理学数据722既可以是从一个或多个传感器得到的原始数据,也可以是应用了某种信息处理的经加工数据。另外,与上述第一学习数据集71同样地,作为第二学习数据集72而相互对应的第二脸部图像数据721和生理学数据722也不一定必须在时间上一致。
[0120]
此外,构成各件第一学习数据集71的第一脸部图像数据711和第一状态信息数据712优选在实际环境下收集。实际环境是实际运用训练后的第一推断器51的环境(例如,运用监视装置2的环境)或者与此同等的环境。实际环境例如是车辆内的空间、模仿车辆的结构物内的空间。即,优选在搭载有相机31的车辆或模仿车辆的结构物内得到第一脸部图像数据711。
[0121]
相对于此,构成各件第二学习数据集72的第二脸部图像数据721和生理学数据722优选在虚拟环境下收集。虚拟环境例如是实验室等非实际环境的环境。优选在该虚拟环境
中以包含表示受试者t的状态的更高阶的信息的方式获取生理学数据722。该情况下,在虚拟环境下测定的生理学参数可以是脑活动、肌肉电位、心电位、眼球运动(特别是瞳孔直径)或者它们的组合。与此相应地,在虚拟环境中利用的传感器可以是脑电图仪、脑磁图仪、核磁共振成像装置、肌电图仪、心电图仪、眼电位传感器、眼球运动测量仪(特别是瞳孔直径测量装置)或者它们的组合。
[0122]
另外,在第一脸部图像数据711和第二脸部图像数据721的拍摄环境不同的情况下,受试者t的脸部以外的要素(例如,佩戴于脸部的传感器)存在较大差异,该差异有可能对通过机器学习构建的推断器的精度造成不良影响。所谓拍摄环境不同的案例,例如有如上所述在实际环境下收集第一脸部图像数据711,而在虚拟环境下收集第二脸部图像数据721的案例。因此,该情况下,优选对第一脸部图像数据711和第二脸部图像数据721适当地进行加工,以使无法区分第一脸部图像数据711和第二脸部图像数据721的脸部以外的要素。
[0123]
该加工可以利用对抗生成网络(generative adversarial network:gan)等的生成模型。对抗生成网络由生成器和判别器构成。生成器构成为根据噪声生成与学习样本(图像)对应的图像。判别器被训练成判别所提供的图像来自学习样本还是来自生成器。相对于此,生成器被训练为生成判别器的判别错误这样的图像。通过交替反复进行该判别器和生成器的学习,生成器学到生成接近于学习样本的图像的能力。
[0124]
因此,根据该对抗生成网络,能够适当地加工第一脸部图像数据711和第二脸部图像数据721。例如,构建包括第一生成器的第一对抗生成网络,该第一生成器将第一脸部图像数据711作为学习样本,生成与第一脸部图像数据711对应的图像。同样地,构建包括第二生成器的第二对抗生成网络,该第二生成器将第二脸部图像数据721作为学习样本,生成与第二脸部图像数据721对应的图像。将由第一生成器生成的图像作为加工完毕的新的第一脸部图像数据711与原来的第一脸部图像数据711进行替换,将由第二生成器生成的图像作为加工完毕的新的第二脸部图像数据721与原来的第二脸部图像数据721进行替换。由此,能够适当地对第一脸部图像数据711和第二脸部图像数据721进行加工,使得无法区分脸部以外的要素。
[0125]
但是,第一脸部图像数据711和第二脸部图像数据721的加工方法并不限定于上述例子。例如,也可以通过应用高斯滤波器、平均化滤波器、中值滤波器等公知的滤波器来对第一脸部图像数据711和第二脸部图像数据721进行加工。另外,例如也可以通过对能够通过图像处理而区分脸部以外的要素的区域施加掩码(mask),从而对第一脸部图像数据711和第二脸部图像数据721进行加工。掩码例如既可以是单色噪声,也可以是随机噪声。另外,例如也可以以不包含脸部以外的要素的方式从第一脸部图像数据711和第二脸部图像数据721分别提取出脸部区域(例如矩形的区域),并将提取出的脸部区域的图像分别替换为新的第一脸部图像数据711和第二脸部图像数据721。
[0126]
但是,获取各件第一学习数据集71和各件第二学习数据集72的环境并不限定于上述例子,可以根据实施方式适当地选择。也可以在同一环境下获取各件第一学习数据集71和各件第二学习数据集72。该情况下,第一脸部图像数据711和第二脸部图像数据721可以彼此相同。另外,可以收集分别由脸部图像数据、状态信息数据712以及生理学数据722的组合构成的多件学习数据集。各件第一学习数据集71也可以通过从该各件学习数据集提取出
脸部图像数据和状态信息数据712而得到。各件第二学习数据集72也可以通过从各件学习数据集提取出脸部图像数据和生理学数据722而得到。
[0127]
上述那样的各件第一学习数据集71和各件第二学习数据集72既可以自动生成,也可以手动生成。另外,也可以通过推断器生成装置1生成各件第一学习数据集71和各件第二学习数据集72。或者,也可以通过推断器生成装置1以外的其他计算机生成各件第一学习数据集71和各件第二学习数据集72的至少任意一个。
[0128]
在由推断器生成装置1生成各件第一学习数据集71和各件第二学习数据集72的情况下,控制部11从各相机(31、32)适当地获取第一脸部图像数据711和第二脸部图像数据721。另外,控制部11例如受理操作者经由输入装置14对受试者t的状态的指定,生成表示所指定的受试者t的状态的状态信息数据712。进而,控制部11从脑电图仪33适当地获取生理学数据722。然后,控制部11通过将第一脸部图像数据711和状态信息数据712组合而生成各件第一学习数据集71。控制部11通过将第二脸部图像数据721和生理学数据722组合而生成各件第二学习数据集72。由此,在步骤s101中,控制部11能够获取多件第一学习数据集71和多件第二学习数据集72。
[0129]
另一方面,在由其他计算机生成各件第一学习数据集71和各件第二学习数据集72的至少任意一个的情况下,生成的学习数据集从其他计算机适当地转发至推断器生成装置1。在本步骤s101中,控制部11例如也可以经由网络、存储介质91等获取由其他计算机生成的各件第一学习数据集71和各件第二学习数据集72中的至少任意一个。在其他计算机中,可以通过与上述推断器生成装置1同样的方法生成各件第一学习数据集71和各件第二学习数据集72中的至少任意一个。
[0130]
另外,所获取到的第一学习数据集71和第二学习数据集72各自的件数也可以不特别限定,可以根据实施方式适当地决定。当获取了多件第一学习数据集71以及多件第二学习数据集72时,控制部11使处理进入下一步骤s102。
[0131]
(步骤s102)
[0132]
在步骤s102中,控制部11作为学习处理部112进行动作,利用多件第一学习数据集71和多件第二学习数据集72实施学习网络5的机器学习。具体而言,控制部11通过利用多件第一学习数据集71实施第一推断器51的机器学习,从而构建被训练成根据第一脸部图像数据711推断状态信息数据712的第一推断器51。与此同时,控制部11通过利用多件第二学习数据集72实施第二推断器52的机器学习,从而构建被训练成根据第二脸部图像数据721再现生理学数据722的第二推断器52。
[0133]
详细而言,首先,控制部11准备学习网络5。所准备的学习网络5的构成、各神经元间的连接的权重的初始值、以及各神经元的阈值的初始值既可以根据模板提供,也可以通过操作者输入来提供。另外,在进行再学习的情况下,控制部11也可以根据通过进行过去的机器学习而得到的学习结果数据来准备学习网络5。
[0134]
接着,控制部11将步骤s101中获取到的各第一学习数据集71所包含的第一脸部图像数据711用作输入数据,将对应的状态信息数据712用作教师数据,执行第一推断器51的学习处理。该学习处理可以使用随机梯度下降法等。
[0135]
例如,在第一步骤中,控制部11针对各第一学习数据集71,将第一脸部图像数据711输入编码器61的输入层611,并从输入侧开始依次进行各层(611~613、621)所包含的各
神经元的点火判定。由此,控制部11从推断部62的全连接层621获取与从第一脸部图像数据711推断状态信息数据712所表示的受试者t的状态的结果对应的输出值。在第二步骤中,控制部11计算所获取到的输出值和与状态信息数据712对应的值的误差。在第三步骤中,控制部11利用误差反向传播(back propagation)法,并使用计算出的输出值的误差,计算各神经元间的连接的权重以及各神经元的阈值各自的误差。在第四步骤中,控制部11根据计算出的各误差,进行各神经元间的连接的权重以及各神经元的阈值各自的值的更新。
[0136]
控制部11针对各件第一学习数据集71,反复通过上述第一~第四步骤调节第一推断器51(编码器61及推断部62)的参数的值,直到从全连接层621得到的输出值和与状态信息数据712对应的值的误差之和变为阈值以下为止。阈值可以根据实施方式适当地设定。由此,控制部11能够构建如下所述被训练的第一推断器51,即:当将构成各件第一学习数据集71的第一脸部图像数据711输入编码器61时,从推断部62输出与状态信息数据712所表示的受试者t的状态相对应的输出值,该状态信息数据712与输入的第一脸部图像数据711建立关联。
[0137]
同样地,控制部11将步骤s101中获取到的各第二学习数据集72所包含的第二脸部图像数据721用作输入数据,将对应的生理学数据722用作教师数据,执行第二推断器52的学习处理。学习处理可以与第一推断器51相同。即,控制部11将学习处理的对象从各层(611~613、621)替换为各层(611~613、631~633),将第一脸部图像数据711替换为第二脸部图像数据721,将状态信息数据712替换为生理学数据722,执行上述第一~第四步骤的各处理。控制部11针对各件第二学习数据集72,反复通过上述第一~第四步骤调节第二推断器52(编码器61及解码器63)的参数的值,直到从解码器63的输出层633得到的输出数据与生理学数据722的误差之和变为阈值以下为止。阈值可以根据实施方式适当地设定,既可以与上述第一推断器51的机器学习中的阈值相同,也可以不同。由此,控制部11能够构建如下所述被训练的第二推断器52,即:当将构成各件第二学习数据集72的第二脸部图像数据721输入编码器61时,从解码器63输出再现了与输入的第二脸部图像数据721建立关联的生理学数据722的输出数据。
[0138]
第一推断器51的机器学习和第二推断器52的机器学习的处理顺序也可以无特别限定,可以根据实施方式适当地决定。第一推断器51的机器学习的处理既可以在第二推断器52的机器学习的处理之前执行,也可以与第二推断器52的机器学习的处理同时执行,还可以在第二推断器52的机器学习的处理之后执行。当第一推断器51和第二推断器52的机器学习完成时,控制部11使处理进入下一步骤s103。
[0139]
此外,当在上述步骤101中收集到表示与对应的第一脸部图像数据711的拍摄时刻错开的时刻的受试者t的状态的状态信息数据712时,在本步骤s102中,第一推断器51被训练成推断与脸部图像数据的拍摄时刻错开的时刻的对象者的状态。关于第二推断器52也是同样的。各第一学习数据集71中的第一脸部图像数据711与状态信息数据712之间的时间上的关系和各第二学习数据集72中的第二脸部图像数据721与生理学数据722之间的时间上的关系并不一定必须一致。
[0140]
另外,为了降低第二推断器52的学习处理的复杂性,防止由于学习数据的偏差而陷入学习处理未收敛的状态,也可以通过加工处理使用作教师数据的生理学数据722简单化。例如,也可以将生理学数据722加工成表示梯度的朝向(值在下一个采样点上升还是下
降)。另外,例如,生理学数据722可以通过按整数、对数标尺等的规定间隔使连续值离散化而得到,也可以利用聚集等方法根据数据的分布进行离散化而得到。另外,这些离散化既可以适用于所获取到的数据本身,也可以适用于上述梯度的大小。
[0141]
(步骤s103)
[0142]
在步骤s103中,控制部11作为保存处理部113进行动作,生成表示通过步骤s102的机器学习构建的第一推断器51的构成及参数的信息作为学习结果数据121。然后,控制部11将生成的学习结果数据121保存至存储部12中。由此,控制部11结束本动作例涉及的处理。
[0143]
此外,学习结果数据121的保存目的地不限于存储部12。控制部11例如也可以将学习结果数据121存储至诸如nas(network attached storage:网络连接存储)等的数据服务器中。学习结果数据121既可以包含表示通过机器学习构建的第二推断器52(特别是解码器63)的构成及参数的信息,也可以不包含。
[0144]
另外,也可以在构建了已学习完毕的第一推断器51之后,控制部11将所生成的学习结果数据121在任意的时刻转送至监视装置2。监视装置2可以通过从推断器生成装置1接受转送而获取学习结果数据121,也可以通过访问推断器生成装置1或者数据服务器而获取学习结果数据121。学习结果数据121也可以预先嵌入监视装置2。
[0145]
进而,控制部11也可以通过定期重复上述步骤s101~s103的处理,从而定期地更新学习结果数据121。在该重复时,可以适当地执行第一学习数据集71和第二学习数据集72的变更、修正、追加、删除等。然后,控制部11也可以在每次执行学习处理时将更新后的学习结果数据121转送至监视装置2,从而定期更新监视装置2所保持的学习结果数据121。
[0146]
[监视装置]
[0147]
接着,使用图7对监视装置2的动作例进行说明。图7是表示本实施方式涉及的监视装置2的处理步骤的一例的流程图。但是,以下说明的处理步骤仅为一例,各处理也可以在可能的范围内进行变更。另外,对于以下说明的处理步骤,可以根据实施方式适当地省略、替换以及追加步骤。
[0148]
(步骤s201)
[0149]
在步骤s201中,控制部21作为数据获取部211进行动作,获取拍到驾驶车辆的驾驶员d的脸部的脸部图像数据221。在本实施方式中,监视装置2经由外部接口24与相机41连接。因此,控制部21从相机41获取脸部图像数据221。该脸部图像数据221既可以是动态图像数据,也可以是静态图像数据。当获取脸部图像数据221时,控制部21使处理进入下一步骤s202。
[0150]
但是,脸部图像数据221的获取路径并不限定于上述例子,可以根据实施方式适当地选择。例如,也可以是与监视装置2不同的其他计算机与相机41连接。该情况下,控制部21也可以通过从其他计算机接受脸部图像数据221的发送而获取脸部图像数据221。
[0151]
(步骤s202)
[0152]
在步骤s202中,控制部21作为推断处理部212进行动作,进行已学习完毕的第一推断器51的设定。接着,控制部21将获取到的脸部图像数据221输入已学习完毕的第一推断器51,执行第一推断器51的运算处理。即,控制部21将脸部图像数据221输入编码器61的输入层611,从输入侧开始依次进行各层(611~613、621)所包含的各神经元的点火判定。由此,控制部21从推断部62的全连接层621获取与驾驶员d的状态的推断结果对应的输出值。
[0153]
由此,控制部21能够利用已学习完毕的第一推断器51根据获取到的脸部图像数据221推断驾驶员d的状态。当上述机器学习中利用的状态信息数据712被构成为作为受试者t的状态而包含受试者t的困倦度、疲劳度、余裕度或者它们的组合时,控制部21能够推断驾驶员d的困倦度、疲劳度、余裕度或者它们的组合。当推断出驾驶员d的状态时,控制部21使处理进入下一步骤s203。
[0154]
(步骤s203)
[0155]
在步骤s203中,控制部21作为输出部213进行动作,输出与驾驶员d的状态的推断结果建立关联的信息。输出目的地和输出的信息的内容分别可以根据实施方式适当地决定。例如,控制部21也可以将通过步骤s202推断驾驶员d的状态的结果直接经由输出装置26输出。
[0156]
另外,例如,控制部21也可以根据驾驶员d的状态的推断结果执行某些信息处理。然后,控制部21也可以输出执行了该信息处理的结果。作为信息处理的一例,在作为驾驶员d的状态而推断困倦度和疲劳度中的至少一方的情况下,控制部21也可以判定困倦度和疲劳度中的至少一方是否超过阈值。阈值可以适当地设定。而且,当困倦度和疲劳度中的至少一方超过阈值时,控制部21也可以经由输出装置26输出促使驾驶员d在停车场等停车进行休息的警告。
[0157]
另外,作为信息处理的其他例子,当车辆构成为能够进行自动驾驶动作时,控制部21也可以根据驾驶员d的状态的推断结果控制车辆的自动驾驶的动作。作为一例,设想车辆构成为能够切换通过系统来控制车辆的行驶的自动驾驶模式和通过驾驶员d的操纵来控制车辆的行驶的手动驾驶模式。
[0158]
该情况下,当车辆以自动驾驶模式行驶,并从驾驶员d或系统受理到从自动驾驶模式切换为手动驾驶模式时,控制部21也可以判定驾驶员d的推断出的余裕度是否超过阈值。然后,当驾驶员d的余裕度超过阈值时,控制部21也可以允许从自动驾驶模式切换为手动驾驶模式。另一方面,当驾驶员d的余裕度在阈值以下时,控制部21也可以不允许从自动驾驶模式切换为手动驾驶模式而维持以自动驾驶模式行驶。
[0159]
另外,当车辆以手动驾驶模式行驶时,控制部21也可以判定困倦度和疲劳度中的至少一方是否超过阈值。而且,当困倦度和疲劳度中的至少一方超过阈值时,控制部21也可以从手动驾驶模式切换为自动驾驶模式,并向车辆的系统发送指示在停车场等安全场所停车的指令。另一方面,当困倦度和疲劳度中的至少一方未超过阈值时,控制部21也可以使车辆维持手动驾驶模式行驶。
[0160]
另外,当车辆以手动驾驶模式行驶时,控制部21也可以判定余裕度是否为阈值以下。而且,当余裕度为阈值以下时,控制部21也可以向车辆的系统发送减速的指令。另一方面,当余裕度超过阈值时,控制部21也可以使车辆维持在驾驶员d的操作下行驶。
[0161]
当信息的输出完成时,控制部21结束本动作例涉及的处理。此外,在驾驶员d位于驾驶席且车辆行驶的期间,控制部21也可以持续反复执行步骤s201~s203的一系列的处理。由此,监视装置2能够持续地监视驾驶员d的状态。
[0162]
[特征]
[0163]
如上所述,在本实施方式中,第一推断器51和第二推断器52构成为具有共用的编码器61。本实施方式涉及的推断器生成装置1通过上述步骤s102的机器学习的处理训练第
一推断器51,以从第一脸部图像数据711导出状态信息数据712,并且训练第二推断器52以从第二脸部图像数据721再现生理学数据722。因此,编码器61的输出(特征量)被设计为能够从脸部图像数据导出对象者的状态及生理学现象。与状态信息数据712相比,生理学数据722可包含与人的状态相关的高阶信息。因此,通过在步骤s102的机器学习中,以不仅能够导出状态信息数据712,还能够导出可包含更高阶的信息的生理学数据722的方式训练共用的编码器61,从而能够使共用的编码器61的参数趋向推断对象者的状态的精度更高的局部解。因此,根据本实施方式涉及的推断器生成装置1,能够生成可更高精度地推断对象者的状态的第一推断器51。
[0164]
此外,当第一学习数据集71和第二学习数据集72的件数充分时,共用的编码器61被适当地训练,以输出能够导出人的状态及生理学现象两者的特征量。因此,当第一学习数据集71和第二学习数据集72中的任一方的件数少时,能够通过另一方来补偿机器学习中利用的学习样本的件数。即,在上述步骤s101中,可以通过增加第一学习数据集71和第二学习数据集72中的任一个的件数来补充另一个的件数的不足。因此,根据本实施方式,能够生成可更高精度地推断对象者的状态的第一推断器51,而且不会导致收集学习样本的成本大幅增大。本实施方式涉及的监视装置2通过利用这样的第一推断器51,能够高精度地推断驾驶员d的状态。
[0165]
另外,在虚拟环境中,相比于实际环境,能够使用更高性能的传感器收集表示人的状态的更高阶的信息。然而,在实际环境中,可能产生难以运用这样的高性能的传感器、或者即使能够运用也会使成本过高等问题。因此,在本实施方式中,可以在实际环境下收集上述步骤s101中获取到的各件第一学习数据集71,可以在虚拟环境下收集各件第二学习数据集72。由此,能够收集可包含与受试者t的状态相关的高阶信息的生理学数据722,通过利用该生理学数据722的机器学习,能够使共用的编码器61的参数趋向从能够在实际环境中容易地获取到的脸部图像数据导出对象者的状态的精度更高的局部解。因此,根据本实施方式,能够生成可以根据在实际环境下能够容易地获取到的数据更高精度地推断对象者的状态的第一推断器51,由此,能够降低在实际环境下运用第一推断器51所耗费的成本。
[0166]
§
4变形例
[0167]
以上,详细说明了本发明的实施方式,但上述说明在所有方面均仅为本发明的例示。当然,能够在不脱离本发明的范围的情况下进行各种改良和变形。例如,能够进行如下的变更。此外,以下针对与上述实施方式相同的构成要素使用相同的附图标记,对于与上述实施方式相同的点适当地省略说明。以下的变形例能够适当地进行组合。
[0168]
<4.1>
[0169]
在上述实施方式中,编码器61和解码器63由多层结构的全连接神经网络构成,推断部62由全连接层621构成。但是,分别构成编码器61、推断部62以及解码器63的神经网络的结构和种类也可以不限定于上述例子,可以根据实施方式适当地选择。例如,编码器61和解码器63可以由具备卷积层、池化层以及全连接层的卷积神经网络构成。另外,在利用时序数据的情况下,编码器61和解码器63也可以由递归型神经网络构成。
[0170]
另外,编码器61、推断部62以及解码器63所利用的学习模型也可以不限于神经网络,可以根据实施方式适当地选择。编码器61、推断部62以及解码器63分别可以使用例如回归树、支持向量回归模型等的回归模型。另外,也可以在该回归模型上连接支持向量机、分
类树、随机森林、装袋机、提升机或者它们的组合。推断部62例如可以使用线性回归模型。推断部62和解码器63分别也可以使用例如附条件的概率场模型。
[0171]
<4.2>
[0172]
在上述实施方式中,学习结果数据121包含表示已学习完毕的神经网络的构成的信息。但是,学习结果数据121的构成也可以不限定于上述例子,只要能够用于设定已学习完毕的第一推断器51,便可以根据实施方式适当地决定。例如,在所利用的神经网络的构成在各装置中通用的情况下,学习结果数据121也可以不包含表示已学习完毕的神经网络的构成的信息。
[0173]
<4.3>
[0174]
在上述实施方式中,学习网络5由具备相互通用的编码器61的第一推断器51和第二推断器52构成。由此,上述实施方式涉及的推断器生成装置1通过第二推断器52的机器学习使共用的编码器61的参数趋向更好的局部解,从而实现提高第一推断器51的精度。但是,学习网络5的构成也可以不限定于上述例子,可以根据实施方式适当地选择。例如,也可以采用以下的两个变形例。
[0175]
(第一变形例)
[0176]
图8示意性地例示出本变形例涉及的推断器生成装置1a的软件构成的一例。推断器生成装置1a的硬件构成与上述实施方式涉及的推断器生成装置1相同。另外,如图8所示,推断器生成装置1a的软件构成也与上述实施方式涉及的推断器生成装置1相同。与上述实施方式涉及的学习网络5相比较,除了本变形例涉及的学习网络5a还具备第三推断器53这一点、学习数据获取部111构成为进一步获取多件第三学习数据集73这一点、学习处理部112构成为利用多件第三学习数据集73进一步执行第三推断器53的机器学习这一点以外,推断器生成装置1a与上述实施方式涉及的推断器生成装置1同样地动作。
[0177]
即,本变形例涉及的学习网络5a具备第一推断器51、第二推断器52以及第三推断器53。第三推断器53由与第一推断器51的编码器61及第二推断器52的解码器63不同的解码器64构成。解码器64是本发明的“其他解码器”的一例。解码器64由能够进行机器学习的学习模型构成。与解码器63同样地,该解码器64可以由神经网络构成。编码器61及解码器64以编码器61的输出被输入至解码器64的方式相互连接。
[0178]
推断器生成装置1a的控制部与上述推断器生成装置1同样地执行步骤s101的处理,获取多件第一学习数据集71和多件第二学习数据集72。除此之外,在步骤s101中,控制部还获取分别由拍到受试者t的脸部的脸部图像数据731和与生理学数据722不同的受试者t的生理学数据732的组合构成的多件第三学习数据集73。各件第三学习数据集73可以与各件第二学习数据集72同样地进行收集。
[0179]
脸部图像数据731是本发明的“第三脸部图像数据”的一例。脸部图像数据731可以与第一脸部图像数据711和第二脸部图像数据721中的至少一方相同。另外,生理学数据732是本发明的“第二生理学数据”的一例。生理学数据732既可以通过测定与生理学数据722不同的生理学参数而得到,也可以通过在不同的时刻测定与生理学数据722相同的生理学参数而得到。另外,也可以通过对测定相同的生理学参数而得到的数据应用不同的信息处理(例如,上述简单化处理),从而得到各生理学数据(722、732)。
[0180]
在步骤s102中,控制部利用多件第三学习数据集73与第一推断器51和第二推断器
52的机器学习一同实施第三推断器53的机器学习。具体而言,控制部将各第三学习数据集73所包含的脸部图像数据731用作输入数据,将对应的生理学数据732用作教师数据,从而执行第三推断器53的学习处理。该学习处理也可以与上述第一推断器51相同。即,控制部将学习处理的对象从编码器61及推断部62替换为编码器61及解码器64,将第一脸部图像数据711替换为脸部图像数据731,将状态信息数据712替换为生理学数据732,从而执行上述第一~第四步骤的各处理。控制部针对各件第三学习数据集73,反复通过上述第一~第四步骤调节第三推断器53(编码器61及解码器64)的参数的值,直到从解码器64得到的输出数据与生理学数据732的误差之和变为阈值以下。阈值可以根据实施方式适当地设定,既可以与上述第一推断器51和第二推断器52中的任一个的机器学习中的阈值相同,也可以与第一推断器51和第二推断器52两者的机器学习中的阈值不同。由此,控制部能够构建如下所述被训练的第三推断器53,即:当将构成各件第三学习数据集73的脸部图像数据731输入编码器61时,从解码器64输出再现了与输入的脸部图像数据731建立关联的生理学数据732的输出数据。此外,与上述实施方式同样地,第一推断器51、第二推断器52以及第三推断器53各自的机器学习的处理顺序也可以无特别限定,可以根据实施方式适当地决定。
[0181]
在步骤s103中,控制部与上述实施方式同样作为保存处理部113进行动作,将表示通过步骤s102的机器学习构建的第一推断器51的构成及参数的信息作为学习结果数据121保存至存储部12中。由此,控制部结束本变形例涉及的处理。所生成的已学习完毕的第一推断器51能够与上述实施方式同样地进行利用。上述监视装置2也可以利用通过本变形例生成的第一推断器51,根据脸部图像数据221推断驾驶员d的状态。
[0182]
根据本变形例,在第三推断器53的机器学习的过程中,共用的编码器61的输出被设计成能够进一步导出生理学数据732。由此,能够生成可更高精度地推断对象者的状态的第一推断器51。
[0183]
此外,也可以设置多个第三推断器53。另外,也可以将第三推断器53逐个追加至学习网络5a中,在步骤s102中,控制部与第一推断器51和第二推断器52的机器学习一同执行追加的第三推断器53的机器学习。然后,也可以在每次机器学习完成时,计算出所生成的已学习完毕的第一推断器51的推断相对于所准备的评价用数据集的正解率。评价用数据集与第一学习数据集71同样地构成。可以将评价用数据集中包含的脸部图像数据输入已学习完毕的第一推断器51,并根据从第一推断器51输出的输出值是否和与状态信息数据对应的值一致,来计算已学习完毕的第一推断器51的推断的正解率。当该正解率降低时,控制部也可以使追加的第三推断器53与学习网络5a分离。由此,能够生成可更高精度地推断对象者的状态的第一推断器51。
[0184]
(第二变形例)
[0185]
图9示意性地例示出本变形例涉及的推断器生成装置1b的软件构成的一例。推断器生成装置1b的硬件构成与上述实施方式涉及的推断器生成装置1相同。另外,如图9所示,推断器生成装置1b的软件构成也与上述实施方式涉及的推断器生成装置1相同。与上述实施方式涉及的学习网络5相比较,除了本变形例涉及的学习网络5b还具备第四推断器54这一点、学习数据获取部111构成为进一步获取多件第四学习数据集74这一点、学习处理部112构成为利用多件第四学习数据集74进一步执行第四推断器54的机器学习这一点以外,推断器生成装置1b与上述实施方式涉及的推断器生成装置1同样地动作。
[0186]
即,本变形例涉及的学习网络5b具备第一推断器51、第二推断器52以及第四推断器54。第四推断器54由与第一推断器51的编码器61不同的编码器65和第一推断器51的推断部62构成。编码器65是本发明的“其他编码器”的一例。编码器65构成为:通过可机器学习的学习模型从生理学数据导出特征量。该编码器65可以与编码器61同样地由神经网络构成。编码器65和推断部62以编码器65的输出被输入至推断部62的方式相互连接。此外,编码器65及解码器63以编码器65的输出被输入至解码器63的方式相互连接。
[0187]
推断器生成装置1b的控制部与上述推断器生成装置1同样地执行步骤s101的处理,获取多件第一学习数据集71和多件第二学习数据集72。除此之外,步骤s101中,控制部还获取分别由受试者t的生理学数据741和表示受试者t的状态的状态信息数据742的组合构成的多件第四学习数据集74。
[0188]
生理学数据741是本发明的“第三生理学数据”的一例,状态信息数据742是本发明的“第二状态信息数据”的一例。生理学数据741和生理学数据722既可以相同,也可以互不相同。状态信息数据742和状态信息数据712既可以相同,也可以互不相同。生理学数据741可以与生理学数据722同样地收集,状态信息数据742可以与状态信息数据712同样地收集。
[0189]
在步骤s102中,控制部利用多件第四学习数据集74与第一推断器51和第二推断器52的机器学习一同实施第四推断器54的机器学习。具体而言,控制部将各第四学习数据集74所包含的生理学数据741用作输入数据,将对应的状态信息数据742用作教师数据,从而执行第四推断器54的学习处理。该学习处理基本上可以与上述实施方式相同。即,控制部将学习处理的对象从编码器61及推断部62替换为编码器65及推断部62,将第一脸部图像数据711替换为生理学数据741,将状态信息数据712替换为状态信息数据742,从而执行上述第一~第四步骤的各处理。控制部针对各件第四学习数据集74,计算出从推断部62得到的输出值和与状态信息数据742对应的值的误差,并根据计算出的各误差更新编码器65和推断部62的参数的值。
[0190]
除此之外,在第一推断器51和第四推断器54的机器学习的过程中,控制部以使编码器61的输出与编码器65的输出的误差最小化的方式对第一推断器51和第四推断器54进行训练。具体而言,当状态信息数据712和状态信息数据742—致时,控制部计算出通过将与状态信息数据712建立关联的第一脸部图像数据711输入编码器61而从编码器61得到的输出值和将与状态信息数据742建立关联的生理学数据741输入编码器65而从编码器65得到的输出值的误差。然后,控制部根据计算出的各误差更新各编码器(61、65)的参数的值。
[0191]
控制部针对各件第四学习数据集74反复调节各参数的值,直到从推断部62得到的输出值与状态信息数据712的误差之和在阈值以下,并且,导出相同的状态信息数据时从编码器61得到的输出值与从编码器65得到的输出值的误差之和变为阈值以下为止。阈值可以根据实施方式适当地设定。
[0192]
此外,控制部既可以同时执行各推断器(51、54)的机器学习,也可以在先执行了任意一方的机器学习之后执行另一方的机器学习。例如,控制部也可以在执行了第四推断器54的机器学习之后执行第一推断器51的机器学习。该情况下,在第一推断器51的机器学习中,控制部在将第四推断器54的编码器65的参数的值固定之后,以使两个编码器(61、65)的输出的误差最小化的方式更新编码器61的参数的值。
[0193]
由此,控制部可以如下所述训练第一推断器51和第四推断器54,即:当状态信息数
据712与状态信息数据742—致时,使通过将对应的第一脸部图像数据711输入编码器61而从编码器61得到的输出值与通过将对应的生理学数据741输入编码器65而从编码器65得到的输出值的误差之和小于阈值。另外,控制部能够构建如下所述被训练的第四推断器54,即:当将构成各件第四学习数据集74的生理学数据741输入编码器65时,从推断部62输出与状态信息数据742所表示的受试者t的状态相对应的输出值,该状态信息数据742与输入的生理学数据741建立关联。
[0194]
此外,当编码器65和解码器63以编码器65的输出被输入至解码器63的方式相互连接时,控制部也可以通过机器学习如下所述训练编码器65和解码器63,即:当将各第四学习数据集74的生理学数据741输入编码器65时,从解码器63输出再现了生理学数据741的输出数据。控制部能够与上述各推断器51~54的机器学习同样地执行该编码器65和解码器63的机器学习。
[0195]
在步骤s103中,控制部与上述实施方式同样作为保存处理部113进行动作,将表示通过步骤s102的机器学习构建的第一推断器51的构成及参数的信息作为学习结果数据121保存至存储部12中。由此,控制部结束本变形例涉及的处理。所生成的已学习完毕的第一推断器51能够与上述实施方式同样地进行利用。上述监视装置2也可以利用通过本变形例生成的第一推断器51,根据脸部图像数据221推断驾驶员d的状态。
[0196]
在本变形例中,第四推断器54被训练为根据生理学数据推断对象者的状态。由于生理学数据与脸部图像数据相比可包含高阶的信息,因此,与从脸部图像数据相比,从生理学数据有望能够更高精度地推断对象者的状态。因此,与第一推断器51相比,该第四推断器54有望能够更高精度地推断对象者的状态。即,在分别训练第一推断器51和第四推断器54的情况下,与第一推断器51中的编码器61的输出相比,第四推断器54中的编码器65的输出能够更准确地表示对象者的状态。
[0197]
因此,在本变形例中,控制部将第四推断器54中的编码器65的输出用作用于更高精度地推断对象者的状态的第一推断器51中的编码器61的输出的样本。即,控制部在机器学习的过程中以使编码器61的输出与编码器65的输出的误差小于阈值的方式训练各编码器(61、65)。由此,能够使第一推断器51中的编码器61的参数趋向推断对象者的状态的精度更高的局部解。因此,根据本变形例,能够生成可更高精度地推断对象者的状态的第一推断器51。
[0198]
此外,在本变形例中,第四推断器54被构成为被输入生理学数据741。但是,第四推断器54的构成并不限定于上述例子,也可以根据实施方式适当地选择。例如,第四推断器54也可以构成为被输入脸部图像数据和生理学数据的组合。该情况下,由于脸部图像数据和生理学数据两者被用作第四推断器54的输入,因此,第四推断器54具有比第一推断器51更优异的性能。另外,由于各推断器(51、54)被构成为输入相同的脸部图像数据,因此,各个编码器(61、65)的参数能够获取类似的值。利用这一点,优选推断器生成装置1b在执行了第四推断器54的机器学习之后,以使编码器61模仿编码器65的动作的方式执行第一推断器51的机器学习。
[0199]
<4.4>
[0200]
上述实施方式涉及的推断器生成装置1适用于推断车辆的驾驶员的状态的场景。但是,上述实施方式涉及的推断器生成装置1不仅可以适用于生成用于根据拍到车辆驾驶
员的脸部的脸部图像数据推断驾驶员的状态的推断器的场景,也可以广泛应用于生成用于根据拍到进行任何作业的对象者的脸部的脸部图像数据推断对象者的状态的推断器的场景。
[0201]
图10示意性地例示出应用本发明的其他场景的一例。具体而言,图10示出将上述实施方式涉及的推断器生成装置1应用于拍摄在生产现场进行作业的作业者u的脸部,并生成用于根据得到的脸部图像数据推断作业者u的状态的推断器的场景的例子。作业者u将生产线所包含的各工序的任务作为规定的作业执行。除了脸部图像数据中拍到的对象者从车辆的驾驶者替换为生产线中的作业者这一点以外,本变形例与上述实施方式相同。
[0202]
即,在步骤s101中,控制部11获取多件第一学习数据集,该多件第一学习数据集分别由拍到执行规定作业的受试者的脸部的第一脸部图像数据和表示执行规定作业时的受试者的状态的状态信息数据的组合构成。另外,控制部11获取多件第二学习数据集,该多件第二学习数据集分别由拍到受试者的脸部的第二脸部图像数据和利用一个或多个传感器测定受试者的生理学参数而得到的生理学数据的组合构成。各件第一学习数据集可以在实际环境中收集,各件第二学习数据集可以在虚拟环境中收集。在本变形例中,规定作业是生产线中的任务。但是,规定作业并不限定于上述例子,可以根据实施方式适当地选择。
[0203]
在步骤s102中,控制部11利用获取到的多件第一学习数据集实施第一推断器51的机器学习。与此同时,控制部11利用获取到的多件第二学习数据集实施第二推断器52的机器学习。由此,控制部11构建如下所述被训练的第一推断器51,即:当将各件第一学习数据集的第一脸部图像数据输入编码器61时,从推断部62输出与对应的状态信息数据所表示的受试者的状态对应的输出值。另外,控制部11构建如下所述被训练的第二推断器52,即:当将各件第二学习数据集的第二脸部图像数据输入编码器61时,从解码器63输出再现了对应的生理学数据的输出数据。机器学习的处理也可以与上述实施方式相同。
[0204]
在步骤s103中,控制部11将表示通过步骤s102的机器学习而构建的第一推断器51的构成及参数的信息作为学习结果数据121保存至存储部12中。由此,控制部11结束本动作例涉及的处理。根据本变形例涉及的推断器生成装置1,能够生成可更高精度地推断作业者的状态的第一推断器51。
[0205]
监视装置2c被构成为:利用通过本变形例涉及的推断器生成装置1构建的第一推断器51,通过相机41拍摄在生产线上与机器人装置r一起进行作业的作业者u,从而根据得到的脸部图像数据推断作业者u的状态。该监视装置2c的硬件构成和软件构成也可以与上述实施方式涉及的监视装置2相同。监视装置2c除了处理驾驶员以外的对象者的脸部图像数据这一点以外,与上述实施方式涉及的监视装置2同样地进行动作。
[0206]
即,在步骤s201中,监视装置2c的控制部从相机41获取拍到作业者u的脸部的脸部图像数据。在接下来的步骤s202中,控制部通过将得到的脸部图像数据输入已学习完毕的第一推断器51中,并执行已学习完毕的第一推断器51的运算处理,从而从第一推断器51获取与作业者u的状态的推断结果对应的输出值。在接下来的步骤s203中,控制部输出与作业者u的状态的推断结果相关的信息。
[0207]
在本变形例涉及的步骤s203中,输出的信息的内容与上述实施方式同样可以根据实施方式适当地选择。例如,设想利用第一推断器51,作为作业者u的状态而推断作业者u的困倦度、疲劳度、余裕度、或者它们的组合的情况。该情况下,控制部也可以判断困倦度和疲
劳度中的至少一方是否超过阈值。而且,当困倦度和疲劳度中的至少一方超过阈值时,控制部也可以经由输出装置输出促使中断作业进行休息的消息。控制部也可以经由网络等向作业者u自身、监督作业者u的监督者等的用户终端发送该消息。
[0208]
另外,控制部也可以将指示执行根据作业者u的状态的推断结果决定的动作的指令作为与推断结果相关的信息输出至机器人装置r。作为一例,当作业者u的推断出的疲劳度高时,监视装置2c的控制部也可以向机器人装置r输出提高机器人装置r对作业的辅助比例的指令。另一方面,当作业者u的余裕度高时,监视装置2c的控制部也可以向机器人装置r输出降低机器人装置r对作业的辅助比例的指令。由此,本变形例涉及的监视装置2c能够利用通过推断器生成装置1生成的第一推断器51,根据脸部图像数据推断作业者u的状态。另外,监视装置2c能够根据推断的结果来控制机器人装置r的动作。
[0209]
<4.5>
[0210]
在上述实施方式及变形例中,示出了将本发明适用于根据进行某种作业的对象者的脸部图像数据推断对象者的状态的场景中的例子。但是,本发明的可适用范围并不限于上述根据脸部图像数据推断对象者的状态的场景,也可以广泛应用于根据拍到对象者的图像数据推断对象者的状态的所有场景。
[0211]
图11示意性地例示出本变形例涉及的推断器生成装置1d的软件构成的一例。推断器生成装置1d的硬件构成与上述实施方式涉及的推断器生成装置1相同。另外,如图11所示,推断器生成装置1d的软件构成也与上述实施方式涉及的推断器生成装置1相同。除了第一脸部图像数据711替换为第一图像数据711d、第二脸部图像数据721替换为第二图像数据721d这一点以外,推断器生成装置1d与上述实施方式涉及的推断器生成装置1同样地进行动作。
[0212]
即,在步骤s101中,推断器生成装置1d的控制部作为学习数据获取部111进行动作,获取多件第一学习数据集,该多件第一学习数据集分别由拍到执行规定作业的受试者的第一图像数据711d和表示执行规定作业时的受试者的状态的状态信息数据712的组合构成。另外,控制部获取多件第二学习数据集,该多件第二学习数据集分别由拍到受试者的第二脸部图像数据721d和利用一个或多个传感器测定受试者的生理学参数而得到的生理学数据722的组合构成。规定作业并无特别限定,也可以根据实施方式适当地选择。规定作业例如可以是车辆的驾驶、生产线中的任务等。
[0213]
在步骤s102中,控制部作为学习处理部112进行动作,利用获取到的多件第一学习数据集实施第一推断器51的机器学习。与此同时,控制部利用获取到的多件第二学习数据集实施第二推断器52的机器学习。由此,控制部构建如下所述被训练的第一推断器51,即:当将构成各件第一学习数据集的第一图像数据711d输入编码器61时,从推断部62输出与状态信息数据712所表示的受试者的状态相对应的输出值,该状态信息数据712与输入的第一图像数据711d建立关联。另外,控制部构建如下所述被训练的第二推断器52,即:当将构成各件第二学习数据集的第二图像数据721d输入编码器61时,从解码器63输出再现了与输入的第二图像数据721d建立关联的生理学数据722的输出数据。机器学习的处理也可以与上述实施方式相同。
[0214]
在步骤s103中,控制部作为保存处理部113进行动作,将表示通过步骤s102的机器学习构建的第一推断器51的构成及参数的信息作为学习结果数据121保存至存储部12中。
由此,控制部结束本变形例涉及的处理。根据本变形例涉及的推断器生成装置1d,能够生成可更高精度地根据图像数据推断对象者的状态的第一推断器51。
[0215]
图12示意性地例示出本变形例涉及的监视装置2d的软件构成的一例。监视装置2d被构成为:利用通过本变形例涉及的推断器生成装置1d构建的第一推断器51,根据图像数据推断对象者的状态。该监视装置2d的硬件构成也可以与上述实施方式涉及的监视装置2相同。另外,如图12所示,监视装置2d的软件构成也与上述实施方式涉及的监视装置2相同。除了脸部图像数据221替换为图像数据221d这一点以外,监视装置2d与上述实施方式涉及的监视装置2同样地进行动作。
[0216]
即,在步骤s201中,监视装置2d的控制部从相机获取拍到对象者的图像数据221d。在接下来的步骤s202中,控制部通过将图像数据221d输入已学习完毕的第一推断器51,并执行已学习完毕的第一推断器51的运算处理,从而从第一推断器51获取与对象者的状态的推断结果对应的输出值。在接下来的步骤s203中,控制部输出与对象者的状态的推断结果相关的信息。输出形式可以根据实施方式适当地选择。根据本变形例涉及的监视装置2d,能够高精度地根据图像数据推断对象者的状态。
[0217]
<4.6>
[0218]
在上述实施方式及变形例中,示出了将本发明适用于根据拍到进行某种作业的对象者的图像数据推断该对象者的状态的场景中的例子。然而,本发明的适用范围并不限于上述根据图像数据推断对象者的状态的场景,也可以应用于根据通过观测对象者的活动而得到的观测数据推断对象者的状态的所有场景。
[0219]
图13示意性地例示出本变形例涉及的推断器生成装置1e的软件构成的一例。推断器生成装置1e的硬件构成与上述实施方式涉及的推断器生成装置1相同。如图13所示,推断器生成装置1e的软件构成也与上述实施方式涉及的推断器生成装置1相同。除了将第一脸部图像数据711替换为第一观测数据711e,将第二脸部图像数据721替换为第二观测数据721e这一点以外,推断器生成装置1e与上述实施方式涉及的推断器生成装置1同样地动作。
[0220]
即,在步骤s101中,推断器生成装置1e的控制部作为学习数据获取部111进行动作,获取分别由第一观测数据711e和状态信息数据712的组合构成的多件第一学习数据集,该第一观测数据711e通过利用一个或多个第一传感器31e测定执行规定作业的受试者的活动而得到,该状态信息数据712表示执行规定作业时的受试者t的状态。另外,控制部获取分别由第二观测数据721e和生理学数据722e的组合构成的多件第二学习数据集,该第二观测数据721e通过利用一个或多个第一传感器32e测定受试者t的活动而得到,生理学数据722e通过利用与第一传感器32e不同种类的一个或多个第二传感器33e测定受试者t的生理学参数而得到。
[0221]
第一传感器(31e、32e)及第二传感器33e并无特别限定,也可以根据实施方式适当地选择。第一传感器(31e、32e)及第二传感器33e既可以相同,也可以不同。优选第二传感器33e构成为具有比第一传感器(31e、32e)更高的功能,相比于第一传感器(31e、32e)能够获取与人的状态相关的高阶信息。另一方面,优选第一传感器(31e、32e)比第二传感器33e廉价。
[0222]
另外,构成各件第一学习数据集的第一观测数据711e及状态信息数据712优选在实际环境下收集。另一方面,构成各件第二学习数据集的第二观测数据721e及生理学数据
722e优选在虚拟环境下收集。与此相应地,第一传感器(31e、32e)可以由相机、眼电位传感器、视线测量装置、麦克风、血压计、脉搏计、心率计、体温计、皮肤电反应仪、载荷传感器、操作设备或它们的组合构成。载荷传感器既可以构成为测量一点的载荷,也可以构成为测量载荷分布。操作设备只要是作为状态推断对象的对象者能够操作的设备便无特别限定,其种类可以根据实施方式适当地选择。在与上述实施方式同样对象者驾驶车辆的案例中,操作设备例如可以是方向盘、制动器、加速器等。该情况下,各观测数据(711e、721e)例如由图像数据、眼电位数据、视线的测量数据、音频数据、血压数据、脉搏数数据、心率数据、体温数据、皮肤电反射数据、载荷的测量数据、操作日志或它们的组合构成。操作日志表示操作设备的操作历史。另一方面,第二传感器33e可以由脑电图仪、脑磁图仪、核磁共振成像装置、肌电图仪、心电图仪、瞳孔直径测量装置或者它们的组合构成。
[0223]
第一传感器也在实际环境中运用第一推断器51时使用。即,第一传感器被用于从执行规定作业的对象者获取观测数据。因此,优选第一传感器(31e、32e)使用在测定受试者t的活动期间不会限制受试者t的身体动作的传感器。不会限制身体动作包括像诸如相机、麦克风等这样不与受试者接触而配置的情况、以及像诸如手表型设备、眼镜型设备等这样与受试者的身体的一部分接触,但几乎不会妨碍该身体的一部分的移动的情况。另一方面,第二传感器33e只要能够收集更高阶的信息,便也可以使用会限制受试者t的身体动作的传感器。限制身体动作包括像诸如脑电图仪等这样安装在受试者t的身体的至少一部分上,从而会妨碍该身体的一部分的移动的情况、和像诸如核磁共振成像装置等这样不与受试者t的身体接触,但为了测定必须将受试者t留在与进行规定作业的场所不同的固定场所。
[0224]
在步骤s102中,控制部作为学习处理部112进行动作,利用获取到的多件第一学习数据集实施第一推断器51的机器学习。与此同时,控制部利用获取到的多件第二学习数据集实施第二推断器52的机器学习。由此,控制部构建如下所述被训练的第一推断器51,即:当将构成各件第一学习数据集的第一观测数据711e输入编码器61时,从推断部62输出与状态信息数据712所表示的受试者的状态相对应的输出值,该状态信息数据712与输入的第一观测数据711e建立关联。另外,控制部构建如下所述被训练的第二推断器52,即:当将构成各件第二学习数据集的第二观测数据721e输入编码器61时,从解码器63输出再现了与输入的第二观测数据721e建立关联的生理学数据722的输出数据。
[0225]
在步骤s103中,控制部将表示通过步骤s102的机器学习而构建的第一推断器51的构成及参数的信息作为学习结果数据121保存至存储部12中。由此,控制部结束本变形例涉及的处理。根据本变形例涉及的推断器生成装置1e,能够生成可更高精度地根据观测数据推断对象者的状态的第一推断器51。
[0226]
图14示意性地例示出本变形例涉及的监视装置2e的软件构成的一例。监视装置2e被构成为:利用通过本变形例涉及的推断器生成装置1e构建的第一推断器51,根据观测数据推断对象者的状态。该监视装置2e的硬件构成也可以与上述实施方式涉及的监视装置2相同。另外,如图14所示,监视装置2e的软件构成也与上述实施方式涉及的监视装置2相同。除了将脸部图像数据221替换为观测数据221e这一点以外,监视装置2e与上述实施方式涉及的监视装置2同样地进行动作。
[0227]
即,在步骤s201中,监视装置2e的控制部获取通过利用一个或多个第一传感器测定执行规定作业的对象者的活动而得到的观测数据221e。在接下来的步骤s202中,控制部
将观测数据221e输入已学习完毕的第一推断器51,并执行已学习完毕的第一推断器51的运算处理,从而从第一推断器51获取与对象者的状态的推断结果对应的输出值。在接下来的步骤s203中,控制部输出与对象者的状态的推断结果相关的信息。输出形式可以根据实施方式适当地选择。根据本变形例涉及的监视装置2e,能够根据观测数据高精度地推断对象者的状态。
[0228]
附图标记说明
[0229]1…
推断器生成装置、11
…
控制部、12
…
存储部、13
…
通信接口、14
…
输入装置、15
…
输出装置、16
…
驱动器、111
…
学习数据获取部、112
…
学习处理部、113
…
保存处理部、121
…
学习结果数据、81
…
推断器生成程序、91
…
存储介质、2
…
监视装置、21
…
控制部、22
…
存储部、23
…
通信接口、24
…
外部接口、25
…
输入装置、26
…
输出装置、211
…
数据获取部、212
…
推断处理部、213
…
输出部、221
…
脸部图像数据、82
…
监视程序、31
…
相机、32
…
相机、33
…
脑电图仪、41
…
相机、5
…
学习网络、51
…
第一推断器、52
…
第二推断器、53
…
第三推断器、54
…
第四推断器、61
…
编码器、62
…
推断部、63
…
解码器、64
…
(其他的)解码器、65
…
(其他的)编码器、71
…
第一学习数据集、711
…
第一脸部图像数据、712
…
(第一)状态信息数据、72
…
第二学习数据集、721
…
第二脸部图像数据、722
…
(第一)生理学数据、73
…
第三学习数据集、731
…
(第三)脸部图像数据、732
…
(第二)生理学数据、74
…
第四学习数据集、741
…
(第三)生理学数据、742
…
(第二)状态信息数据、t
…
受试者、d
…
驾驶员(对象者)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1