电子装置上用于增强实况观众体验的系统和方法与流程
本发明涉及实况视频流式传输或广播,具体来说,涉及经由电子装置在视频流式传输或传播中的实况观众体验。
背景技术:
在实况体育游戏视频流式传输或广播中,不仅播放器以及播放器流式传输/广播的游戏本身,还在视频场景中展示其它静态对象,例如座椅、体育场、广告牌/横幅。这些静态对象中的一些载送信息,但这些信息与观众/观看者无关。例如,足球比赛中围绕足球场的广告牌/横幅显示广告。在不同人口资料和不同背景技术的情况下,广告并不局限于/针对可能来自全世界的观众/观看者。例如,在实况世界杯足球比赛中,广告牌中的一个展示与英国的德勒(deloitte)(公共会计事务所)有关的广告。但是此广告与正观看实况足球比赛的一名巴西高中男生无关,因此他对其不感兴趣。而且,高中男孩可能不理解英语,结果是广告的信息/消息无法传达给目标观众/观看者(换句话说,广告浪费在非目标观众/观看者上)。需要定制广告的内容,使得将信息/消息成功地传达给目标观众/观看者。
根据已知技术,在足球比赛期间,不同国家的观众观看在足球场边缘周围的广告牌上显示的不同广告。例如,将包含在德国踢的足球比赛的视频广播给不同国家的观众。中国和澳大利亚的观众观看的广告(替代广告)与德国观众观看的广告不同。然而,基于已知技术将替代广告应用于视频存在一些限制。在一个实例中,适用于显示替代广告的广告牌具有至少一个标识符。计算系统(例如,由广播组织提供)能够基于标识符将广告牌识别为目标对象,以将替代广告显示在目标对象上。标识符被视为预定准则,以便计算系统识别广告牌。
例如,标识符是广告牌的绿色屏幕/表面。当计算系统基于绿色屏幕/表面将广告牌识别为目标对象时,替代广告被配置成显示在目标对象上。在另一实例中,标识符是红外发射器。广告牌包含将红外信号传输到摄像头的红外发射器。基于红外信号,摄像头将广告牌识别为目标对象,计算系统随后将替代广告布置为显示在广告牌上。
在没有标识符的情况下,计算系统不能够确定目标对象,结果是观众无法观看替代广告。本发明能够通过深度学习来识别目标对象,而无需遵守任何预定准则。例如,视频含有不包含预定准则的广告牌,替代广播不能够应用于广告牌。例如,在线视频共享平台处可获得98年世界杯决赛视频(录制的视频)。视频含有在足球场的边缘周围的多个广告牌。然而,广告牌都不是绿色的(预定准则),结果是在用户进行视频流式传输期间不能够将提到广告应用于那些广告牌。
本发明涉及用于增强实况观众体验的改进技术以及提供相关优点。
技术实现要素:
本文公开示例方法,示例包含:在电子装置处由电子装置接收多个实况视频帧;由至少一个受训练的深度神经网络识别多个实况视频帧中的第一实况视频帧中的一个或多个目标对象和一个或多个非目标对象;识别属于一个或多个目标对象的一组或多组像素;基于所识别的属于一个或多个目标对象的一组或多组像素,限定一个或多个目标对象的表面上的区域;在多个实况视频帧中将一个或多个预定图形图像覆盖在一个或多个目标对象的表面上的区域上;在多个实况视频帧中将一个或多个非目标对象覆盖在一个或多个预定图形图像上,以形成处理后的实况视频,其中处理后的实况视频包括覆盖在一个或多个目标对象上的一个或多个非目标对象和一个或多个预定图形图像。
在一些示例中,一个或多个目标对象包括一个或多个静态对象,并且一个或多个非目标对象包括在一个或多个静态对象前方的一个或多个对象,其中一个或多个对象遮挡一个或多个静态对象。
在一些示例中,一个或多个静态对象包括一个或多个广告牌。
在一些实施例中,计算机可读存储媒体存储一个或多个程序,并且所述一个或多个程序包含指令,所述指令在由电子装置执行时使所述电子装置执行上文和本文描述的方法中的任一个。
在一些实施例中,电子装置包含一个或多个处理器、存储器,以及一个或多个程序,其中所述一个或多个程序存储在存储器中并且被配置成由所述一个或多个处理器执行,所述一个或多个程序包含用于执行上文和本文描述的方法中的任一个的指令。
出于前述原因,需要一种可以有效地显示定制广告而不需要广告牌遵循任何预定准则的计算系统。还需要一种用于根据各种广告需求实时或近实时地定制赛事的实时广播的计算系统。
附图说明
图1描绘根据本发明的各种实施例的显示在电子装置上的实况足球比赛视频的示例的屏幕截图。
图2a和图2b描绘根据本发明的各种实施例的使用划界构件来确定目标对象的真实边界的示意图。
图3a至3d描绘根据本发明的各种实施例的基于识别为极端点的像素产生的线的示意图。
图4描绘根据本发明的各种实施例的基于第一观看者个人信息显示在电子装置上的处理后的实况足球比赛视频的示例的屏幕截图。
图5描绘根据本发明的各种实施例的基于第二观看者个人信息显示在电子装置上的处理后的实况足球比赛视频的示例的屏幕截图。
图6描绘根据本发明的各种实施例的显示在处于一个国家的电子装置上的处理后的实况足球比赛视频的示例的屏幕截图。
图7描绘示出根据本发明的各种实施例的生成处理后的实况足球比赛视频帧的过程的示例流程图。
图8描绘示出根据本发明的各种实施例的训练电子装置以识别目标对象和非目标对象的过程的示例流程图。
图9a至9b描绘根据本发明的各种实施例的基于第一观看者个人信息显示在电子装置上的处理后的实况视频的示意图。
图10a至10c描绘根据本发明的各种实施例的显示在电子装置上的处理后的实况视频的示意图。
图11描绘可以用于实施本发明的各种实施例的计算系统。
图12描绘示出根据本发明的各种实施例的在服务器处生成处理后的实况足球比赛视频帧的过程的示例流程图。
图13描绘示出根据本发明的各种实施例的在服务器处生成处理后的实况足球比赛视频帧的过程的替代示例流程图。
具体实施方式
呈现以下描述以使得所属领域的普通技术人员能够制造和使用各种实施例。特定装置、技术和应用的描述仅作为示例提供。所属领域的技术人员将易于了解对本文所描述的示例的各种修改,并且在不脱离本发明的精神和范围的情况下,本文所定义的一般原理可以应用于其它示例和应用。因此,公开的发明并不预期限于本文描述和所示的示例,而是被赋予与权利要求一致的范围。
如今,人们能够通过各种平台观看实况视频(即,例如实况体育比赛视频)。一些平台是免费的,而一些平台是按月付费或按年付费的。实况体育比赛可以是足球比赛、网球比赛、冰球比赛、篮球比赛、棒球比赛或任何体育比赛。例如,世界杯是全球最大的体育赛事,有数十亿人观看为期一个月、每四年一次的比赛。足球比赛期间是各企业单位进行产品或服务推广的宝贵时间。多个广告牌/横幅位于足球场/足球体育场周围。多个广告牌专用于显示推广各种产品/服务的广告。广告可以用不同语言载送信息。
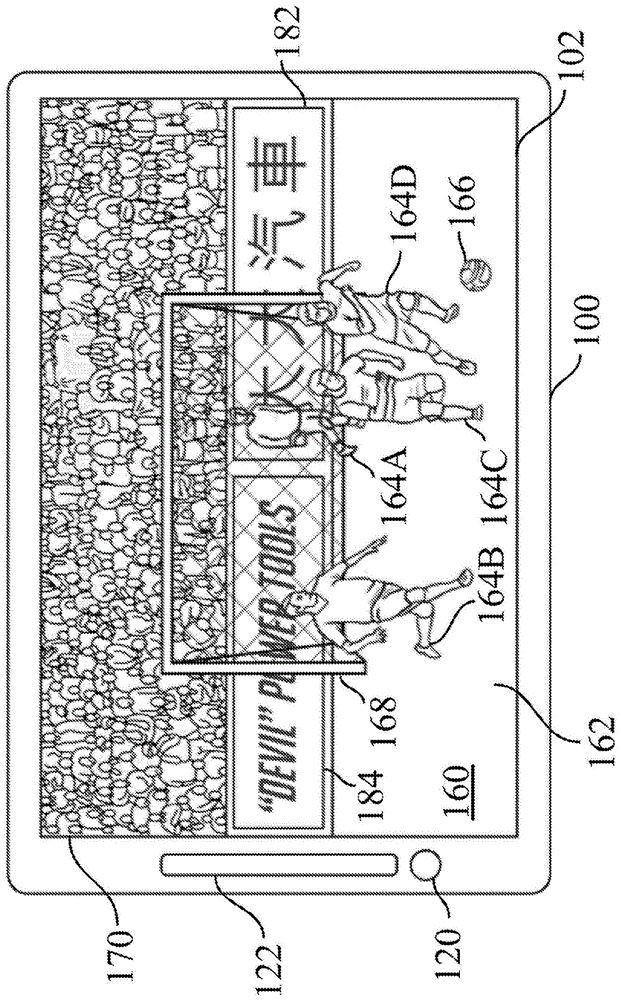
图1描绘在电子装置上的实况足球比赛视频流式传输或广播的示例的屏幕截图。在一些示例中,观看者/观众喜欢观看在例如智能装置100的电子装置上实况足球比赛视频流式传输/广播。智能装置100可以是台式计算机、膝上型计算机、智能电话、平板计算机、可穿戴装置或护目镜。智能装置100类似于且包含下文在图9中所描述的计算系统1100的所有或一些组件。在一些实施例中,智能装置100包含触敏显示器102、前置摄像头120和扬声器122。在其它示例中,电子装置可以是电视机、监视器或其它视频显示装置。
经由位于足球场/足球体育场处的视频录制装置向观看者流式传输/广播实况足球比赛视频。实况足球比赛视频流式传输/广播包括多个实况足球比赛视频帧。在一些示例中,允许观看者经由网站、应用程序软件或软件程序在智能装置100上观看实况足球比赛视频。网站、应用程序软件或软件程序可以是免费的或可收费的。
如图1中所描绘,视图160包含但不限于足球场162、球员164a、164b、164c和164d、足球166、球门168、观众170、第一广告牌182和第二广告牌184。在视图160中,实况足球比赛视频流式传输/广播中的球员164a、164b、164c和164d以及球门168是在第一广告牌182和第二广告牌184前方的对象,并且还在观看者在智能装置100上观看实况足球比赛视频时遮挡第一广告牌182和第二广告牌184。
对实况足球比赛视频帧中显示的对象没有限制。例如,视频帧可以包含十块广告牌、两个球门、一个足球、一个裁判和二十二个球员,可以包含三块广告牌、两个足球、一个球门和两个球员,可以包含两块广告牌和一个球门,或可以包含两块广告牌。对在广告牌前方并且还遮挡广告牌的对象没有限制。例如,对象可以包含球员164a和164b、足球166和球门168,可以包含足球166和球门168,或可以包含球员164c和164d以及足球166。
第一广告牌182和第二广告牌184是在实况足球比赛视频中的静态对象。在视图160中,球员164a-164d和球门168在第一广告牌182和第二广告牌184前方。球员164a-164d和球门168遮挡第一广告牌182和第二广告牌184。第一广告牌182和第二广告牌184由至少一个受训练的深度神经网络确定为目标对象。球员164a-164d和球门168由受训练的深度神经网络确定为非目标对象。对广告牌的位置没有限制。广告牌可以位于足球场周围的任何位置处。
通过将足球比赛的多张照片和/或视频作为训练数据馈送到训练模块来获得受训练的深度神经网络,在所述训练模块处执行运行深度学习算法的进程。训练模块可以位于智能装置100或服务器中。在一些示例中,受训练的深度神经网络包括适合于识别一个或多个目标对象的第一受训练的深度神经网络以及适合于识别一个或多个非目标对象的第二受训练的深度神经网络。
在一些示例中,第一广告内容和第二广告内容分别显示在第一广告牌182和第二广告牌184的表面上。第一广告内容涉及中国汽车品牌并且第二广告内容涉及英国电动工具品牌(这些分别显示在实时地或近实时地流式传输或广播的实况足球比赛中的第一广告牌182和第二广告牌184上)。来自不同国家的数十亿观看者观看实况足球比赛视频。然而,对于非中国观看者,它们可能不理解第一广告内容。另外,并非每一观看者对电动工具(第二广告内容)感兴趣。基于观看者偏好、观看者背景或与观看者相关联的其它信息,需要第一和第二广告内容适合于观看者。
图2a和2b描绘使用划界构件来确定目标对象的真实边界以便预定图形图像覆盖在其上的示例。在一些示例中,智能装置100接收实况足球比赛视频。实况足球比赛视频包括多个实况足球比赛视频帧。当智能装置100通过由深度学习训练的至少一个深度神经网络识别多个实况足球比赛帧的第一实况足球比赛视频帧中的一个或多个目标对象时,一个或多个预定图形图像被配置成覆盖一个或多个目标对象。然而,由于不能够确定一个或多个目标的真实边界,因此预定图形图像可能与一个或多个目标对象未对准。
如图2a中所描绘,为简单起见,本文中描述作为目标对象的第一广告牌182。视图260a显示在触敏显示器102上并且包含生成为围绕广告牌182的范围的第一划界构件290。类似划界构件还应用于第二广告牌184。第一划界构件290可以呈环形、盒形或任何形状。基于常规方式生成第一划界构件290而不将任何数学函数应用于其上(例如,线性回归),因此第一划界构件290不与广告牌184的真实边界对准,并且当预定图形图像覆盖在广告牌384上时,预定图形图像不能够与广告牌对准。
为了优化划界构件的精度,仅举例来说,智能装置100被配置成扫描接收到的实况足球比赛视频帧,以通过受训练的深度神经网络识别属于广告牌182的一组或多组像素。基于所识别的一组或多组像素,形成第二划界构件292。视图260b包含与第一广告牌182的真实边界基本上对准的第二划界构件292,如图2b中所描绘(基本上匹配第一广告牌182的轮廓/形状)。例如,智能装置100以预定顺序,例如从左到右、从上到下、从右到左以及从下到上扫描多个实况足球比赛视频帧中的第一实况足球比赛视频帧。智能装置100从上到下扫描第一实况足球比赛视频帧,以便通过受训练的深度神经网络确定属于第一广告牌182的第一组像素。
对扫描的预定顺序没有限制。例如,预定顺序可以从右到左、从上到下、从下到上、从左到右。对扫描区域没有限制。例如,智能装置100可以部分地扫描第一实况足球比赛视频帧,即智能装置100可以扫描第一实况足球比赛视频帧的含有目标对象的区域。用于部分扫描的一个益处在于减少在扫描较少像素时的计算成本。
在第一组像素中,智能装置100随后将通过从左到右扫描而将第一组像素中的一个或多个像素识别为极端点302a(基于2d坐标),如图3a中所描绘。极端点是在相邻像素中的突出位置中的像素。随后将至少一个数学函数应用于极端点302a以获得线304a。数学函数可以采用多个形式中的一个,包含但不限于线性回归。线304a将对应于第二划界构件292的顶部界线。
智能装置100随后将从上到下、从右到左和从下到右扫描第一实况足球比赛视频帧,以分别获得如图3b、3c和3d中所描绘的极端点302b、302c和302d。线性回归将应用于极端点302b、302c和302d中的每一个,因此形成线304b、304c和304d。线304b、304c和304d分别对应于第二划界构件292的左界线、底部界线和右界线。
基于第二划界构件292确定第一广告牌182的真实边界。第二划界构件292限定在第一广告牌182的表面上的区域294。智能装置100将确定原始实况足球比赛视频帧中的第一广告牌182的3d视觉特征,例如,透视投影形状、照明或任何其它特征。预定图形图像合适地覆盖在所述区域上。预定图形图像可以包含第一广告牌182的3d视觉特征。为了使预定图形图像感觉像是真实的(如同它应该已经在真实环境中的适当位置),目标对象(第一广告牌182)的3d视觉特征应用于预定图形图像。从目标对象中提取3d特征。3d特征包含但不限于亮度、分辨率、纵横比、视角。以视角和纵横比为例,由于3d对象投影到2d屏幕,因此3d规则对象可能变为梯形,测量梯形的角度和边长。用相同的角度和边长变换预定图形图像,即,预定图形图像变换为相同梯形且随后合适地覆盖在目标对象上。以亮度为另一示例,目标对象分成相等大小的较小区域。区域越小,则亮度的分辨率越高,但是需要计算能力越高。对于每一区域,估计亮度。一种估计方法是使用opencv来测试所述特定区域的β值。随后,相同β值应用于预定图形图像的对应区域。
第二划界构件292的形状取决于目标对象(广告牌182)的实际形状。对目标对象的形状没有限制。从目标对象的一组或多组像素确定极端点以及应用于其的线性回归可以用于确定任何形状的目标对象的真实边界。
图4描绘基于第一观看者个人信息显示在电子装置上的处理后的实况足球比赛视频的示例的屏幕截图。仅借助于示例,通过所使用的电子装置(例如智能装置400)接收实况足球比赛视频。
实况足球比赛视频包括多个实况足球比赛视频帧。允许第一观看者经由智能装置400观看实况足球比赛视频。通过显示可能适合于第一观看者或观看者可能感兴趣的广告内容,接收到的实况足球比赛视频帧将在智能装置400处进行处理。
在多个实况足球比赛视频帧中的第一实况足球比赛视频帧中,智能装置400将通过由深度学习训练的至少一个深度神经网络识别一个或多个目标对象(第一实况足球比赛视频帧中的静态对象)和一个或多个非目标对象(对象在静态对象前方并且还可以遮挡第一实况足球比赛视频帧中的静态对象)。在这种情况下,智能装置400通过受训练的深度神经网络将第一广告牌182和第二广告牌184确定为目标对象并且将球员164a、164b、164c和164d以及球门168确定为非目标对象。
如图4中所描绘,视图460显示在智能装置400的触敏显示器402上。视图460包含足球场162、球员164a、164b、164c和164d、足球166、球门168、观众170以及第一广告牌182和第二广告牌184。在这种情况下,基于第一观看者个人信息,与中国汽车品牌有关的第一广告内容和与英国电动工具品牌有关的第二广告内容由第一和第二预定广告内容替代。
智能装置400将第一广告牌182和第二广告牌184识别为目标对象。将生成第二划界构件292以围绕广告牌182和184的每一范围。第二划界构件292被配置成确定第一广告牌182和第二广告牌184的真实边界,并且限定第一广告牌182和第二广告牌184的每个表面上的区域294。
当区域294限定在第一广告牌182和第二广告牌184的每个表面上时,分别将第一预定图形图像486和第二预定图形图像488合适地覆盖在第一广告牌182和第二广告牌184的表面上。第一预定图形图像486和第二预定图形图像488属于存储在智能装置400的存储器或服务器中的多个预定图形图像。基于第一观看者个人信息,第一预定图形图像486和第二预定图形图像488分别示出第一预定广告内容和第二预定广告内容。第一预定图形图像486和第二预定图形图像488可以分别包含在原始实况足球比赛视频帧中的第一广告牌182和第二广告牌184的3d视觉特征,例如,透视投影形状、照明或任何其它特征。
一旦第一预定图形图像486和第二预定图形图像488分别平放在第一广告牌182和第二广告牌184上,随后就将非目标对象覆盖在第一广告牌182和第二广告牌184前方,其中位置与原始实况足球比赛视频帧中的那些位置相同或基本上相似。在多个实况足球比赛视频帧中的后续实况足球比赛视频帧中,将预定图形图像486和488覆盖在广告牌182和184上,随后将非目标对象覆盖在广告牌182和184前方。以此方式,平放在广告牌上的任何图形图像看起来自然,并且感觉好像这些图形图像在现实世界中应该在广告牌上。
一旦由受训练的深度神经网络识别多个实况足球比赛视频帧的第一足球比赛视频帧(例如,视图460)中的目标对象,通过使用视频对象跟踪算法跟踪目标对象。对于多个实况足球比赛视频帧中的后续实况足球比赛视频帧,使用视频对象跟踪算法识别所跟踪的目标对象。当新的目标对象出现在后续实况足球比赛视频帧中时,受训练的深度神经网络保持识别所述新的目标对象。所属领域的技术人员已知视频对象跟踪算法。可以使用已知的视频对象跟踪算法,例如medianflow、moss(最小输出误差平方和)。
使用视频对象跟踪算法的一个益处是节省神经网络培训成本,这是根据一系列巨大训练数据集和计算能力进行的。受训练的深度神经网络可能无法识别多个实况足球比赛视频帧中的每一个中的目标对象。如果不执行跟踪,则在多个实况足球比赛视频帧中的一些中,当目标对象无法由受训练的深度神经网络识别时,不会将预定图形图像覆盖在目标对象上。在这种情况下,需要高度准确的受训练的深度神经网络,这需要巨大训练数据集和强大计算能力。另外,如果不执行跟踪,则需要在多个实况足球比赛视频帧(具有目标对象)中的每一个中确定目标对象的真实边界,这需要强大计算能力和更多处理时间。
在一些示例中,允许第一观看者在用户界面或任何平台/媒体处预先输入其个人信息。用户界面可以由网站、应用程序软件或实施本发明的软件程序提供。个人信息可以包含年龄、性别、教育程度、地址、国籍、宗教、职业、婚姻状况、家庭成员、偏好的语言、地理位置、工资、爱好或与第一观看者相关的任何其它信息。
在其它示例中,第一观看者的个人信息还可以通过第一观看者的其它在线活动而不是预先输入获得。例如,基于其在线购物记录,可以推断出其对某些商品的喜好以及其兴趣和爱好。
例如,第一观看者的第一个人信息是男性、已婚、有一个小孩、35岁、居住在旧金山,母语为英语、律师、电影爱好者和旅行者。基于其个人信息,预定图形图像可以包含与高端hifi/家庭影院设备、豪华手表、豪华汽车、家用产品、保健产品、航空公司和/或旅行社有关的广告内容。大多数预定广告内容中使用的语言是英语。期望在第一广告牌182和第二广告牌184上显示与第一观看者的日常生活紧密相关的预定广告内容。例如,第一预定图形图像486可以包含与豪华手表品牌有关的第一预定广告内容,并且第二预定图形图像488可以包含与豪华汽车品牌有关的第二预定广告内容。第一和第二预定信息都是英语。现在,第一观看者能够在实况足球比赛视频流式传输/广播期间观看广告内容,所述广告内容可能会吸引其注意力(通过处理后的实况足球比赛视频帧)。
或者,允许在例如服务器的电子装置中处理实况足球比赛视频。服务器从视频录制装置接收实况足球比赛视频。实况足球比赛视频包括多个实况足球比赛视频帧。服务器将通过存储在服务器中的受训练的深度神经网络识别接收到的实况足球比赛视频帧中的一个或多个目标对象和一个或多个非目标对象。在这种情况下,服务器将广告牌182和184确定为目标对象,并且将球员164a、164b、164c和164d以及球门268确定为非目标对象。
基于第一用户个人信息,原始实况足球比赛视频帧中的第一广告内容和第二广告内容将由分别显示在第一预定图形图像486和第二预定图形图像488上的第一和第二预定广告内容替代。将第一预定图形图像486合适地覆盖在第一广告牌182的表面上。将第二图形图像488合适地覆盖在第二广告牌184的表面上,随后将非目标对象覆盖在第一广告牌182和第二广告牌184前方,其中位置与原始实况足球比赛视频帧中的那些位置相同或基本上相似。随后将处理后的实况足球比赛视频图像传输到智能装置400。第一观看者能够在智能装置400的触敏显示器402上观看处理后的实况足球比赛视频。
在一个变型例中,服务器从视频录制装置接收实况足球比赛视频。实况足球比赛视频包括多个实况足球比赛视频帧。服务器将通过使用受训练的深度神经网络识别接收到的多个实况足球比赛视频帧中的一个或多个目标对象和一个或多个非目标对象。受训练的深度神经网络存储在服务器中。服务器确定目标对象的真实边界,确定目标对象的3d视觉特征并且跟踪目标对象。
随后,服务器将所有此信息作为实况足球视频帧的元数据,接着将具有元数据对象的原始实况足球视频帧发送到观看者装置(智能装置400)。智能装置400读取元数据对象,并且根据由元数据对象提供的信息将存储在智能装置400中的预定图形图像安置在目标对象(第一广告牌182和第二广告牌184)上,以形成处理后视频。处理后视频随后将显示在智能装置400上。
图5描绘基于第二观看者个人信息显示在电子装置上的处理后的实况足球比赛视频的示例的屏幕截图。在一些示例中,第二观看者是单身男性、居住在东京、25岁,母语为日语、销售人员和体育爱好者。实况足球比赛视频将在第二观看者所使用的电子装置中进行处理以观看实况足球比赛视频,所述电子装置例如智能装置500,或例如服务器(如上文所提及)的其它电子装置。智能装置500从视频录制装置接收实况足球比赛视频。实况足球比赛视频包括多个实况足球比赛视频帧。
在多个实况足球比赛视频帧中的第一实况足球比赛视频帧中,智能装置500将通过由深度学习训练的至少一个深度神经网络识别一个或多个目标对象(第一实况足球比赛视频帧中的静态对象)和一个或多个非目标对象(对象在静态对象前方并且还遮挡第一实况足球比赛视频帧中的静态对象)。在这种情况下,智能装置500通过受训练的深度神经网络将广告牌182和184确定为目标对象并且将球员164a、164b、164c和164d以及球门168确定为非目标对象。
如图5中所描绘,视图560显示在智能装置500的触敏显示器502上。视图560包含足球场162、球员164a、164b、164c和164d、足球166、球门168、观众170以及第一广告牌182和第二广告牌184。在这种情况下,基于第二观看者个人信息,与中国汽车品牌有关的第一广告内容和与英国电动工具品牌有关的第二广告内容由第一和第二预定广告内容替代。
智能装置500将广告牌182和184识别为目标对象。将生成第二划界构件292以围绕广告牌182和184的每一范围。第二划界构件292适用于确定第一广告牌182和第二广告牌184的真实边界,并且限定第一广告牌182和第二广告牌184的每个表面上的区域294。
当区域294限定在第一广告牌182和第二广告牌184的每个表面上时,分别将第一预定图形图像586和第二预定图形图像588合适地覆盖在第一广告牌182和第二广告牌184的表面上。第一预定图形图像586和第二预定图形图像588属于存储在智能装置500的存储器或服务器中的多个预定图形图像。基于第二观看者个人信息,第一预定图形图像586和第二预定图形图像588分别示出第一预定广告内容和第二预定广告内容。第一预定图形图像586和第二预定图形图像588可以分别包含在原始实况足球比赛视频帧中的第一广告牌182和第二广告牌184的3d视觉特征,例如,透视投影形状、照明或任何其它特征。以此方式,平放在广告牌上的任何预定图形图像看起来自然,并且感觉好像这些预定图形图像在现实世界中应该在广告牌上。
一旦第一预定图形图像586和第二预定图形图像588分别平放在第一广告牌182和第二广告牌184上,随后就将非目标对象覆盖在第一广告牌182和第二广告牌184前方,其中位置与原始实况足球比赛视频帧中的那些位置相同或基本上相似。在多个实况足球比赛视频帧中的后续实况足球比赛视频帧中,将预定图形图像586和588覆盖在广告牌182和184上,随后将非目标对象覆盖在广告牌182和184前方。
基于第二观看者个人信息,预定图形图像可以包含与运动设备、计算机、可穿戴设备、入门级汽车、旅行社和/或社交媒体。大多数广告内容中使用的语言是日语。期望在第一广告牌182和第二广告牌184上显示与第二观看者的日常生活紧密相关的广告内容。例如,第一预定图形图像586可以包含与日本视频游戏品牌有关的广告内容,并且第二预定图形图像588可以包含与日本运动设备品牌有关的广告内容。现在,第二观看者能够在实况足球比赛视频流式传输/广播期间观看广告内容,所述广告内容可能会吸引其注意力(通过处理后的实况足球比赛视频帧)。
图6描绘基于地理位置显示在电子装置上的处理后的实况足球比赛视频的示例的屏幕截图。在一些示例中,第三观看者使用智能装置600来观看实况足球比赛视频。智能装置600位于美国。智能装置600从视频录制装置接收实况足球比赛视频。将在智能装置600中处理接收到的实况足球比赛视频。或者,还允许在服务器中处理实况足球比赛视频。
如图6中所描绘,视图660显示在智能装置600的触敏显示器602上。视图660包含足球场162、球员164a、164b、164c和164d、足球166、球门168、观众170以及第一广告牌182和第二广告牌184。
智能装置600将通过由深度学习训练的至少一个深度神经网络识别一个或多个目标对象(原始实况足球比赛视频帧中的静态对象)和一个或多个非目标对象(对象在静态对象前方并且遮挡原始实况足球比赛视频帧中的静态对象)。在这种情况下,智能装置600通过受训练的深度神经网络将广告牌182和184确定为目标对象并且将球员164a、164b、164c和164d以及球门168确定为非目标对象。
在这种情况下,第一预定图形图像686被配置成合适地覆盖在第一广告牌182的表面上。第二图形图像688被配置成合适地覆盖在第二广告牌184的表面上。第一预定图形图像686包含第一预定广告内容,并且第二预定图形图像688包含第二预定广告内容。例如,第一预定图形图像686可以包含与英国运动设备有关的第一预定广告内容,并且第二预定可以包含与英国汽车品牌有关的第二预定广告内容。
对于预定图形图像686和688中包含什么预定广告内容没有限制。例如,预定图形图像可以包含与家用产品、专业服务、时尚产品、食品和饮料产品、电子产品或英国的任何产品/服务有关的广告内容。
现在参考图7,示出用于在电子装置上生成并提供过程实况视频的示例过程700。在一些示例中,在具有显示器、一个或多个图像传感器的电子装置(例如,智能装置400)处实时地或近实时地实施过程700。过程700包含接收实况视频,例如,实况足球比赛视频(框701)。从位于足球场的视频录制装置接收实况足球比赛视频。实况足球比赛视频包括多个实况足球比赛视频帧(原始实况足球比赛视频帧)。
智能装置400随后将确定多个实况足球比赛视频帧中的第一实况足球比赛视频帧中的目标对象和非目标对象。例如,第一实况足球比赛视频帧包含足球场162、球员164a、164b、164c和164d、足球166、球门168、观众170,以及第一广告牌182和第二广告牌184。第一广告牌182和第二广告牌184是在原始实况足球比赛视频帧中的静态对象。球员164a、164b、164c和164d以及球门168是在静态对象前方的对象并且还遮挡静态对象。
智能装置400将通过至少一个受训练的深度神经网络将第一广告牌182和第二广告牌184确定为目标对象并且将球员164a、164b、164c和164d以及球门168确定为非目标对象(框702)。
智能装置400将以预定顺序,例如从左到右、从上到下、从右到左以及从下到上扫描第一实况足球比赛视频帧,以通过受训练的深度神经网络识别属于目标对象的像素组(框703)。为简单起见,本文中将描述作为目标对象的第一广告牌182。相同过程还应用于第二广告牌184。
基于从左到右扫描,智能装置400通过受训练的深度神经网络识别属于第一广告牌182的第一组像素。在第一组像素中,智能装置400随后将基于像素的y坐标值而将第一组像素中的一个或多个像素识别为极端点302a。例如,如图3a中所描绘,当从左到右扫描时,像素312a的位置高于像素310a和314a的位置(像素312a具有比像素310a和314a大的y坐标值)。因此,像素312a被识别为极端点302a。随后,像素318a被识别为另一极端点302a,因为其位置高于其相邻的右和左像素(像素316a和320a)两者。使用相同方式,像素322a和像素328a被识别为其它极端点302a。用反例进一步加以说明,像素324a不被视为极端点302a。尽管像素324a高于像素326a(像素324a具有比326a大的y坐标值),但是像素324a低于像素322a(像素324a具有比322a小的y坐标值)。要识别为极端点,像素必须高于与其紧邻的两个像素。随后将线性回归应用于极端点302a以获得第一线304a(框704)。对于规则形状或直线,线性回归可以包含公式y=b+ax,其中a和b是根据线性回归过程估计的常数。x和y是图像帧上的坐标,即智能装置或任何其它视频播放器的屏幕上的坐标。对于不规则形状或曲线,线性回归可以包含公式
基于从上到下扫描,智能装置400通过受训练的深度神经网络识别属于广告牌182的第二组像素。在第二组像素中,智能装置400随后将基于像素的x坐标值而将第二组像素中的一个或多个像素识别为极端点302b。例如,如图3b中所描绘,当从上到下扫描时,像素312b的位置比像素310b和314b的位置更靠左(像素312b具有比像素310b和314b小的x坐标值)。因此,像素312b被识别为极端点302b。随后,像素318b被识别为极端点302b,因为其位置比其相邻的上和下像素(像素316b和320b)两者更靠左。使用相同方式,像素322b和像素328b被识别为其它极端点302b。用反例进一步加以说明,像素316b不被视为极端点302b。尽管像素316b比像素314b更靠左(像素316b具有比314b小的x坐标值),但是像素316b比像素318b更靠右(像素316b具有比318b大的x坐标值)。要识别为极端点,像素必须比与其紧邻的两个像素更靠左。随后将线性回归应用于极端点302b以获得第二线304b(框704)。
基于从右到左扫描,智能装置400识别属于广告牌182的第三组像素。在第三组像素中,智能装置100随后将基于像素的y坐标值而将第三组像素中的一个或多个像素识别为极端点302c。例如,如图3c中所描绘,当从右到左扫描时,像素312c的位置低于像素310c和314c的位置(像素312c具有比像素310c和314c小的y坐标值)。因此,像素312c被识别为极端点302c。随后,像素318c被识别为另一极端点302a,因为其位置低于其相邻的右和左像素(像素316c和320c)两者。使用相同方式,像素322c和像素328c被识别为其它极端点302c。用反例进一步加以说明,像素324c不被视为极端点302c。尽管像素324c低于像素326c(像素324c具有比326c小的y坐标值),但是像素324c高于像素322c(像素324c具有比322c大的y坐标值)。要识别为极端点,像素必须低于与其紧邻的两个像素。随后将线性回归应用于极端点302c以获得第三线304c(框704)。
基于从下到上扫描,智能装置400识别属于广告牌182的第四组像素。在第三组像素中,智能装置400随后将基于像素的x坐标值而将第三组像素中的一个或多个像素识别为极端点302d。例如,如图3d中所描绘,当从下到上扫描时,像素312d的位置比像素310d和314d的位置更靠右(像素312d具有比像素310d和314d大的x坐标值)。因此,像素312d被识别为极端点302b。随后,像素318d被识别为极端点302d,因为其位置比其相邻的上和下像素(像素316d和320d)两者更靠右。使用相同方式,像素322d和像素328d被识别为其它极端点302d。用反例进一步加以说明,像素316d不被视为极端点302d。尽管像素316d比像素314d更靠右(像素316d具有比314d大的x坐标值),但是像素316d比像素318b更靠左(像素316d具有比318d小的x坐标值)。要识别为极端点,像素必须比与其紧邻的两个像素更靠右。随后将线性回归应用于极端点302d以获得第四线304d(框704)。
基于线304a-304d形成第二划界构件292(框704)。线304a和304c分别对应于第二划界构件292顶部界线和第二划界构件292的底部界线。线304b和304d分别对应于第二划界构件292的左界线和第二划界构件292的右界线。第二划界构件292与第一广告牌182的真实边界基本上对准(基本上匹配第一广告牌182的轮廓/形状)。第二划界构件292限定在第一广告牌182的表面上的区域294。智能装置100将确定原始实况足球比赛视频帧中的第一广告牌182的3d视觉特征,例如,透视投影形状、照明或任何其它特征(框705)。
一旦实况足球比赛视频帧中的目标对象(第一广告牌182)由受训练的深度神经网络识别,就通过使用视频对象跟踪算法跟踪目标对象(框706)。对于多个实况足球比赛视频帧中的后续实况足球比赛视频帧,使用视频对象跟踪算法识别所跟踪的目标对象。当新的目标对象出现在后续实况足球比赛视频帧中时,受训练的深度神经网络保持识别所述新的目标对象。
基于第一观看者个人信息,将预定图形图像合适地覆盖在区域294上(框707)。在一个示例中,将含有第一预定图形图像486的第一图形图像层覆盖在含有第一广告牌182的第一目标对象层上,结果是将第一预定图形图像486合适地覆盖在第一广告牌182的区域294上。第一预定图形图像486包含原始实况足球比赛视频帧中的第一广告牌182的3d视觉特征。以此方式,平放在第一广告牌182上的第一预定图形图像486看起来自然,并且感觉好像第一预定图形图像486在现实世界中应该在第一广告牌182上。当确定目标对象以及其真实边界时,框707将应用于多个实况足球比赛视频帧中的后续帧。
一旦将第一图形图像层覆盖在第一目标对象层上,就将含有非目标对象的第一非目标对象层覆盖在图形图像层上。非目标对象随后将安置于第一广告牌182前方,其中位置与原始实况足球比赛视频帧的那些位置相同或基本上相似(框708)。当确定目标对象以及其真实边界时,框708将应用于多个实况足球比赛视频帧中的后续帧。
当框707和框708应用于多个实况足球比赛视频帧时,形成处理后的实况足球比赛视频,包含平放在第一广告牌182上的第一预定图形图像486和平放在第二广告牌184上的第二预定图形图像488。允许第一观看者实时地或近实时地在智能装置400的触敏显示器402上观看处理后的实况足球比赛视频,如同第一观看者观看包含现实世界中显示豪华手表品牌广告的第一广告牌182和现实世界中显示豪华汽车品牌广告的第二广告牌184的实况足球比赛。
在一个变型例中,电子装置可以是伺服器。服务器执行如图12中所说明的过程1200。例如,允许服务器执行框1201到框1208(其等效于执行过程700的框701到框708)。在框1209处,服务器将通过在多个实况足球比赛视频帧中的后续帧中,将一个或多个预定图形图像(第一预定图形图像486)覆盖在一个或多个目标对象(第一广告牌182)上以及将一个或多个非目标对象覆盖在一个或多个预定图形图像来生成处理后的实况视频。服务器随后将在框1210处将处理后的实况足球比赛视频传输到一个或多个其它电子装置(例如,台式计算机、膝上型计算机、智能装置、监视器、电视机或任何其它视频显示装置)以显示在其上。
在一个变型例中,服务器执行如图13中所示出的过程1300的框1301到框1306(其等效于执行过程700的框701到框706)。服务器在框1307处将所有信息(从框1301到框1306产生)作为实况足球比赛视频帧的元数据,随后在框1308处将具有元数据的实况足球比赛视频帧发送到观看者装置(例如,智能装置400)。智能装置400随后将框707到框708应用于实况足球比赛视频帧。处理后视频随后将显示在智能装置400的触敏显示器402上。
预先训练智能装置100或服务器,以通过由深度学习训练的至少一个深度神经网络识别一个或多个目标对象和一个或多个非目标对象。图8描绘用于训练至少一个深度神经网络的示例过程800,所述深度神经网络驻存在例如智能装置100或服务器中,以识别实况视频(例如,实况足球比赛视频)中的目标对象和非目标对象。智能装置100或服务器包含至少一个训练模块。在框801处,由训练模块接收足球比赛的多张照片和/或视频作为训练数据,在所述训练模块处训练至少一个深度神经网络。深度神经网络可以是卷积神经网络(cnn),或cnn与递归神经网络(rnn)组合的变型,或任何其它形式的深度神经网络。足球比赛的照片和/或视频可以包含多个视频帧,其中球员和球门在广告牌前方并且还遮挡广告牌。需要以不同的背景或照明在不同视角获取训练数据的足球比赛的照片和/视频。足球比赛的多张照片和/或视频包含但不限于足球、球员、裁判、球门、广告牌/横幅、观众、足球场。
在框802处,数据扩增应用于足球比赛(训练数据)的接收到的照片和/或视频。数据扩增可以指代紧接着足球比赛的接收到的照片和/或视频的任何处理,以便增加训练数据的分集。例如,可以翻转训练数据以获得镜像,可能将噪声添加到训练数据,或可以改变训练数据的亮度。在框803处,训练数据随后将应用于运行深度学习算法的进程,以便在训练模块处训练深度神经网络。
在框804处,形成至少一个受训练的深度神经网络。受训练的深度神经工作适合于分别识别一个或多个目标对象和一个或多个非目标对象。一个或多个目标对象是实况足球比赛视频中的静态对象(例如,广告牌)。一个或多个非目标对象是在实况足球比赛视频中的一个或多个目标对象前方的对象(例如,球员和/或球门)。一个或多个非目标对象还遮挡实况足球比赛视频帧中的一个或多个目标对象。在其它实施例中,训练过程还可以产生第一受训练的深度神经网络和第二受训练的深度神经网络。第一受训练的深度神经网络适用于识别一个或多个目标对象,并且第一受训练的深度神经网络适用于识别一个或多个非目标对象。
受训练的深度神经网络将存储于智能装置100的存储器中,受训练的深度神经网络将与安装在智能装置100中的应用程序软件或软件程序一起使用。当应用程序软件或软件程序接收实况足球比赛视频时,受训练的深度神经网络应用于接收到的实况足球比赛视频,以便实时地或近实时地识别一个或多个目标对象和一个或多个非目标对象。
或者,服务器可以完全执行过程800,或可以部分地执行过程800。例如,允许服务器执行框801到框804。服务器随后将受训练的深度神经网络传输到一个或多个其它电子装置(例如,台式计算机、膝上型计算机、智能装置或电视机)以识别目标对象和非目标对象。
仅出于示例性目的,视频流式传输或广播含有可能不适合于每一观众,可能不被每一观众理解,或可能不吸引每一观众的一些内容。图9a描绘显示在电子装置上的视频流式传输或广播的示例的屏幕截图。在一些示例中,图4的第一用户在智能装置400的触敏显示器402上观看视频(视频可以是实况视频或录制的视频)。对视频的来源没有限制。视频可以由tv公司、在线视频共享平台、在线社交媒体网络或任何其它视频制造者/视频共享平台提供。例如,第一用户观看来自在线视频共享平台的视频。视频包括多个视频帧。如图9a中所描绘,视图960a显示在触敏显示器402上并且包含智能装置400被训练成通过深度学习识别多个视频帧中的一个或多个目标对象。在一些示例中,位于建筑物处的告示牌/广告牌被视为目标对象。智能装置400包含至少一个训练模块,在所述至少一个训练模块处,通过馈送含有位于建筑物处的告示牌/广告牌的多张照片和多个视频来训练至少一个深度神经网络(用于识别告示牌/广告牌)。受训练的深度神经网络将存储于智能装置400中。基于受训练的深度神经网络,智能装置400能够将位于建筑物处的第一告示牌982和第二告示牌984识别为目标对象。对于除目标对象之外的对象,智能装置400会将其视为非目标对象。
视图960a包含目标对象(例如,第一告示牌982和第二告示牌984)和非目标对象(例如,建筑物962和964以及车辆966和968)。第一告示牌982含有与日本电器制造商相关联的广告内容,并且第二告示牌984含有与日本书店相关联的广告内容。智能装置400包含受训练的深度神经网络,智能装置400能够通过所述受训练的深度神经网络识别多个视频帧中的告示牌/广告牌(目标对象)。智能装置400随后将执行上述一个或多个过程。
图9b描绘从基于个人信息的用户将预定图像覆盖在图9a的视频帧上产生的处理后视频的示例的屏幕截图。如图9b中所描绘,通过执行上述过程,视图960b显示在显示器402上,并且包含基于第一用户个人信息分别合适地覆盖在告示牌982和984上的第一预定图形图像986和第二预定图形图像988。
第一预定图形图像986包含与豪华汽车品牌有关的第一预定广告内容,并且第二预定图形图像988包含与豪华手表品牌有关的第二预定广告内容。将含有第一预定图形图像986和第二预定图形图像988的第二图形图像层覆盖在含有告示牌982和984的第二目标对象层上。将含有非目标对象(例如建筑物962和964以及车辆966和968)的第二非目标层覆盖在第二图形图像层上。通过实时地或近实时地覆盖多个视频帧中的多个层,形成处理后视频。
图10a是含有一个或多个目标对象的视频流式传输或广播的另一示例的屏幕截图。在一个实施例中,训练智能装置1000以通过深度学习识别一个或多个目标对象。目标对象是视频(视频可以是实况视频或录制的视频)中的飞机1090(在a航空公司)。智能装置400包含与存储器中的目标对象相关联的至少一个受训练的深度神经网络。图4的第一用户使用智能装置400来享受视频流式传输或广播。例如,第一用户观看来自在线视频共享平台的视频。视频包括多个视频帧。如图10a中所描绘,视图1060a包含目标对象(飞机1090)和其它非目标对象,例如建筑物1062和1064、车辆1066和1068、告示牌/广告牌1082和1084。在一些示例中,飞机被视为目标对象。智能装置400包含至少一个训练模块,在所述至少一个训练模块处,通过馈送含有飞机的多张照片和多个视频来训练至少一个深度神经网络(用于识别飞机)。受训练的深度神经网络将存储于智能装置400中。基于受训练的深度神经网络,智能装置400能够将天空中的飞机1090识别为目标对象。对于除目标对象之外的对象,智能装置400会将其视为非目标对象。
智能装置400包含受训练的深度神经网络,智能装置400能够通过所述受训练的深度神经网络识别多个实况视频帧中的飞机1090。智能装置400随后将执行上述一个或多个过程。
图10b描绘从将预定图像覆盖在图10a的实况视频帧上产生的处理后视频的示例的屏幕截图。如图10b中所描绘,视图1060b包含通过执行上述过程覆盖在目标对象(飞机1090)和非目标对象上的预定图形图像1092。预定图形图像1092包含与b航空公司有关的第一预定广告内容。将含有预定图形图像1092的第三图形图像层覆盖在含有飞机1090的第三目标对象层上。将含有非目标对象(例如建筑物1062和1064、车辆1066和1068、告示牌/广告牌1082和1084)的第三非目标层覆盖在第三图形图像层上。通过实时地或近实时地覆盖多个视频帧中的多个层,形成处理后视频。
在一个变型例中,目标对象由与目标对象具有相同性质的预定图形图像替代。图10c描绘从将预定图像合适地覆盖在图10a的实况视频帧上产生的处理后视频的示例的屏幕截图。如图10c中所描绘,视图1060c包含通过执行上述过程合适地覆盖在目标对象(在a航空公司的飞机1090)和非目标对象上的预定图形图像1094(包含在b航空公司的飞机)。将含有预定图形图像1094的第四图形图像层覆盖在含有飞机1090的第四目标对象层上。将含有非目标对象(例如建筑物1062和1064、车辆1066和1068、告示牌/广告牌1082和1084)的第四非目标层覆盖在第四图形图像层上。通过实时地或近实时地覆盖多个视频帧中的多个层,形成处理后视频(如同在b航空公司的飞机出现在视频流式传输/广播中)。
现在参考图11,描绘了被配置成执行任何上述过程和/或操作中的任一个的示例性计算系统1100的组件。例如,计算系统1100可以用于实施上述智能装置100,所述智能装置实施以上实施例或关于图7和图8描述的过程700和800的任何组合。计算系统1100可以包含例如处理器、存储器、存储装置和输入/输出外围设备(例如,显示器、键盘、触控笔、绘图装置、磁盘驱动器、互联网连接、摄像头/扫描仪、麦克风、扬声器等)。然而,计算系统1100可以包含用于执行过程的一些或所有方面的电路或其它专用硬件。
在计算系统1100中,主系统1102可以包含主板1104,所述主板例如上面安装有组件的印刷电路板,其具有连接输入/输出(i/o)区段1106、一个或多个微处理器1108和存储器区段1110的总线,所述存储器区段可以具有与其相关的闪存卡1138。存储器区段1110可以含有用于执行过程700和800或本文中所描述的其它过程中的任一个的计算机可执行指令和/或数据。i/o区段1106可以连接到显示器1112(例如,以显示视图)、触敏表面1114(以接收触摸输入并且在一些情况下可以与显示器组合)、麦克风1116(例如,以获得音频记录)、扬声器1118(例如,以播放音频记录)、磁盘存储单元1120、媒体驱动单元1122。媒体驱动单元1122可以读取/写入非暂时性计算机可读存储媒体1124,其可以含有用于实施过程700和800或上述任何其它过程的程序1126和/或数据。
另外,非暂时性计算机可读存储媒体可以用于存储(例如,有形地体现)一个或多个计算机程序,以用于借助于计算机执行上述过程中的任一个。计算机程序可以例如以通用编程语言(例如,pascal、c、c++、java等)或一些专用的应用程序专用语言来编写。
计算系统1100可以包含各种传感器,例如前置摄像头1128和后置摄像头1130。这些摄像头可以被配置成捕获各种类型的光,例如可见光、红外光和/或紫外光。另外,摄像头可以被配置成基于它们接收的光捕捉或生成深度信息。在一些情况下,深度信息可以从与摄像头不同的传感器生成,但是仍然可以与来自摄像头的图像数据组合或集成。包含在计算系统1100中的其它传感器或输入装置包含数字罗盘972、加速计1134和陀螺仪1136。还可以包含其它传感器和/或输出装置(例如,点阵投射器、ir传感器、光电二极管传感器、飞行时间传感器等)。
虽然计算系统1100的各种组件在图9中单独地描绘,但是各种组件可以组合在一起。例如,显示器1112和触敏表面1114可以一起组合成触敏显示器。
在一个变型例中,计算系统1100可以用于实施上述服务器,所述服务器实施以上实施例或关于图7和图8描述的过程700和800的任何组合。服务器可以包含例如处理器、处理器、存储装置,和输入/输出外围设备。在服务器中,主系统1102可以包含主板1104,所述主板例如上面安装有组件的印刷电路板,其具有连接输入/输出(i/o)区段1106、一个或多个微处理器1108和存储器区段1110的总线,所述存储器区段可以具有与其相关的闪存卡1138。存储器区段1110可以含有用于执行过程700和800或本文中所描述的其它过程中的任一个的计算机可执行指令和/或数据。媒体驱动单元1122可以读取/写入非暂时性计算机可读存储媒体1124,所述非暂时性计算机可读存储媒体可以含有程序1126和/或用于实施过程700和800或上述任何其它过程的数据。
另外,非暂时性计算机可读存储媒体可以用于存储(例如,有形地体现)一个或多个计算机程序,以用于借助于计算机执行上述过程中的任一个。计算机程序可以例如以通用编程语言(例如,pascal、c、c++、java等)或一些专用的应用程序专用语言来编写。
本文中描述了各种示例性实施例。以非限制性的意义参考这些示例。提供它们是为了说明所公开发明的更广泛适用的方面。在不脱离各种实施例的真实精神和范围的情况下,可以进行各种改变并且可以替换等同物。另外,可以进行许多修改,以使特定情形、材料、物质组成、过程、过程动作或步骤适宜于各种实施例的目标、精神或范围。此外,如所属领域技术人员将理解,本文中描述和说明的每个单独的变型具有离散的组件和特征,其可以容易地与任何其它几个实施例的特征分离或组合,而不脱离各种实施例的范围或精神。
还应注意,实施例可以描述为过程,过程描绘为流程图、作业图、数据流图、结构图或框图。尽管流程图可将操作描述为连续过程,但许多操作可以并行或同时执行。另外,操作的顺序可以重新安排。过程在其操作完成时终止,但是可以具有不包含在图中的额外步骤。过程可以对应于方法、函数、过程、子例程、子程序等。当过程对应于函数时,其终止对应于所述函数返回到调用函数或主函数。
- 还没有人留言评论。精彩留言会获得点赞!