用于实现矩阵运算的方法和设备与流程
背景技术:
通过计算机从向量和匹配维度的矩阵来以数学方式确定标量积需要大量的加法和乘法,因此需要计算机中的大量存储空间。相反,通过内存中计算借助于对应维度的矩阵来计算标量积需要较少的存储空间。这同样适用于微分方程组的求解。
将专用硬件(例如点积引擎)用于这种应用。
期望实现一种相对于专用硬件更有效的可能性来执行这种计算。
技术实现要素:
这通过独立权利要求的主题来实现。
用于实现矩阵运算的一种相关方法规定,为了所述矩阵运算根据借助于第一忆阻器布置的第一模拟相加来确定第一数字结果,其中根据借助于第二忆阻器布置的第二模拟相加来确定第二数字结果,并且其中将所述第一结果和所述第二结果数字相加。各种忆阻器布置中的模拟相加使得可以快速计算出模拟结果。通过对模拟结果进行数字相加来完成所述矩阵运算,并将该矩阵运算数字地提供以用于进一步处理。
优选规定,根据第一模拟结果确定所述第一数字结果,其中根据第二模拟结果确定所述第二数字结果,其中至少部分在时间上重叠地确定模拟结果。这种并行化加快了计算。
优选规定,将第一电压施加到所述第一忆阻器布置的第一忆阻器上,其中至少部分在时间上与此重叠地将第二电压施加到所述第一忆阻器布置的第二忆阻器上,其中在所述第一忆阻器布置的第一输出端上检测第一总和电流,所述第一总和电流表征流过所述第一忆阻器和所述第二忆阻器的电流,其中至少部分在时间上与此重叠地将所述第一电压施加到所述第二忆阻器布置的第三忆阻器上,其中至少部分在时间上与此重叠地将所述第二电压或第三电压施加到所述第二忆阻器布置的第四忆阻器上,其中在所述第二忆阻器布置的第二输出端上检测第二总和电流,所述第二总和电流表征流过所述第三忆阻器和所述第四忆阻器的电流,其中根据第一总和电流和第二总和电流确定所述结果。通过高度并行化,加快了矩阵乘法的计算。
优选规定,根据第一矩阵的第一元素定义所述第一电压,其中根据所述第一矩阵的第二元素定义所述第二电压,其中根据第二矩阵的第一元素定义所述第一忆阻器的第一电阻值,其中根据所述第二矩阵的第二元素定义所述第二忆阻器的第二电阻值,并且其中所述结果表征矩阵的标量积。通过高度并行化,可以非常快速地执行标量积的计算。
优选规定,根据所述第二矩阵的元素来对忆阻器的至少一个电阻值编程。由此为新的计算简单地对所述装置进行初始化。
优选规定,根据所述第二矩阵的元素来定义或编程至少两个忆阻器的电阻值。为了并行化,在所述装置中多次使用同一矩阵。由此进一步加快了计算。
优选地规定,以矩阵布置来布置多个忆阻器,其中所述第二矩阵或多个第二矩阵定义所述多个忆阻器的电阻值布置,并且其中所述矩阵布置中的忆阻器具有电阻值或用所述电阻值对所述忆阻器编程,所述电阻值在所述电阻值布置中,特别是就其索引而言,与其在所述矩阵布置中的位置相对应。该对应特别清楚。
优选地规定,至少两组忆阻器具有电阻值或用电阻值对至少两组忆阻器编程,所述电阻值是根据同一第二矩阵的元素定义的。这种分组使得所述对应显著更为容易。
优选地规定,将所述矩阵布置中的至少两组忆阻器中的至少一部分忆阻器用于确定同一个总和电流。这些矩阵被一个位于另一个下方地映射在同一行中。由此可以使用具有低分辨率的模数转换器。
优选地规定,来自所述矩阵布置中的至少两组忆阻器中一组的至少一个忆阻器在确定所述至少两组忆阻器中另一组的忆阻器的总和电流时不予考虑。由此可以完全利用具有高分辨率的模数转换器。
优选地规定,所述第一电压是模拟信号,该模拟信号由数模转换器根据由所述第一矩阵的第一元素定义的数字信号产生,和/或所述第二电压是模拟信号,该模拟信号由数模转换器根据由所述第一矩阵的第二元素定义的数字信号产生。因此可以非常熟练地产生用于计算的输入变量。
优选地规定,所述第一电压和所述第二电压相差一个因子,特别是2的幂,该因子特别是根据模数转换器的分辨率或根据矩阵运算所基于的比特因子分解来定义的。因此,特别是可以根据模数转换器的分辨率来影响所述信号的分辨率。还可以根据基础的矩阵运算是1比特分解还是2比特分解来区分所述因子。
优选地规定,所述第一总和电流至少包括第一电流和第二电流,其中在将所述第一电压施加到所述第一忆阻器时,所述第一电流流过所述第一忆阻器,并且其中在将所述第二电压施加到所述第二忆阻器时,所述第二电流流过所述第二忆阻器。这是对各个电流的特别有利的考虑。
优选地规定,将所述第一电压同时施加到所述第一忆阻器和第三忆阻器上,或者其中将所述第二电压同时施加到至少第二忆阻器和第四忆阻器上,其中检测流过所述第一忆阻器和所述第二忆阻器的电流的第一总和电流,其中检测流过所述第三忆阻器和/或所述第四忆阻器的电流的第二总和电流,并且其中根据第一总和电流和第二总和电流来确定所述结果。这使得可以并行评估多个计算。
优选地规定,由模数转换器根据总和电流来确定定义至少一个比特的值的数字信号。由此特别熟练地确定存储器的寄存器的值。
优选地规定,确定多个总和电流,其中根据所述多个总和电流确定多个比特,其中将至少一个根据总和电流之一定义的比特与至少一个根据另一个总和电流定义的比特相加。通过将比特与另一比特相加或通过将多个比特同时与多个比特相加,可以改变分辨率。
优选地规定,寄存器中的至少一个比特在与来自另一个寄存器的另一比特相加之前,相对于所述结果的最低有效比特朝着所述结果的最高有效比特的方向移位地布置。由此可以利用增加的电压来操控各个忆阻器,从而可以降低模数转换器的分辨率。
优选地规定,寄存器中的至少一个比特在与来自另一个寄存器的另一比特相加之前,相对于所述结果的最低有效比特与所述另一比特相邻地布置。由此寄存器中的空间得到了特别有效的利用。
优选地规定,以矩阵布置来布置多个忆阻器,其中第二矩阵或多个第二矩阵定义多个忆阻器的电阻值布置,并且其中所述矩阵布置中的忆阻器具有电阻或用电阻值对所述忆阻器编程,所述电阻值在所述电阻值布置中,特别是就其索引而言,与其在所述矩阵布置中的位置相对应。这种分配可以特别容易地显示。
用于实现矩阵运算的设备包括第一忆阻器布置和第二忆阻器布置,其中所述设备包括第一模数转换器和第二模数转换器,并且其中所述设备被构造为为了矩阵运算根据借助于所述第一忆阻器布置和所述第一模数转换器进行的第一模拟相加来确定第一数字结果,以及根据借助于所述第二忆阻器布置和所述第二模数转换器的第二模拟相加来确定第二数字结果。该设备使得可以快速计算所述矩阵运算。
优选地规定,将第一电压施加到忆阻器布置的第一忆阻器上,其中可以至少部分在时间上与此重叠地将第二电压施加到所述忆阻器布置的第二忆阻器上,其中可以在所述忆阻器布置的第一输出端上检测第一总和电流,所述第一总和电流表征流过所述第一忆阻器和所述第二忆阻器的电流,其中可以至少部分在时间上与此重叠地将所述第一电压施加到所述忆阻器布置的第三忆阻器上,其中可以至少部分在时间上与此重叠地将所述第二电压施加到所述忆阻器布置的第四忆阻器上,其中可以在所述忆阻器布置的第二输出端上检测第二总和电流,所述第二总和电流表征流过所述第三忆阻器和所述第四忆阻器的电流。
优选地规定,多个忆阻器布置形成矩阵布置。这可以特别有效地显示。
优选地规定,所述数模转换器被构造为检测关于至少一个总和电流的信息。
优选地规定,所述设备包括用于产生所述第一电压的第一模数转换器和用于产生所述第二电压的第二模数转换器。因此可以更好地操控该设备。
优选地规定,所述设备设置忆阻器布置,其中两个忆阻器布置在所述矩阵布置的行和列的节点处,所述两个忆阻器就其取决于电荷的电阻值来说可以在相反的方向上变化。
设置了一种设备,所述设备具有微处理器、开关装置和特别是具有寄存器的存储器,所述寄存器被构造为操控前述设备。
附图说明
其他有利的实施方式从下面的描述和附图中得出。在附图中:
图1示意性地示出了矩阵布置,
图2示意性地示出了忆阻器布置,
图3示出了第一计算方案,
图4示意性地示出了电路,
图5示出了用于计算的方法中的步骤,
图6示出了第二计算方案,
图7示出了忆阻器布置中的矩阵分配,
图8示出了第三计算方案,
图9示意性地示出了具有引出线的忆阻器布置,
图10示出了第四计算方案,
图11示意性地示出了具有其他引出线的忆阻器布置,
图12示出了第五计算方案,
图13示意性地示出了其他忆阻器布置,
图14示出了第六计算方案,
图15示意性地示出了其他忆阻器布置,
图16示出了第七计算方案。
具体实施方式
在下面的描述中,忆阻器是指当施加到忆阻器上的电压超过阈值时该忆阻器的电阻可以通过流过的电流改变的电子部件。例如通过迭代算法将忆阻器编程为特定的电阻值,该迭代算法将具有定义的大小、持续时间和形状的电压脉冲施加到所述忆阻器上。在每个电压脉冲之后,优选地通过计算来检查所述忆阻器是否已经达到其电阻值的目标值。
利用这样的算法,只能以足够的精度将忆阻器编程为少量离散的电阻值。为此,例如通过数模转换器将数字编码的电阻值转换为对应的电压脉冲。为了计算每个电压脉冲之后的电阻值,将模拟电流信号检测为模拟结果并由模数转换器数字化。数字化结果的精确度取决于所述模数转换器的质量,利用所述模数转换器将模拟结果在进行了计算后又转换回数字范围。由于将值从数字转换为模拟以及再从模拟转换为数字,可以假定这些计算受到一定程度的不清晰性的影响。其原因是诸如所述转换器的数字残留误差或非线性的转换误差。噪声也可能影响所述结果,特别是在所述转换器的分辨率很高的情况下。
忆阻器可以用于多种效应。应用该效应的一种物理系统具有可变的电阻,该电阻受过去流向一个或多个忆阻器的电流的影响。
忆阻器可以以维度为n×m的矩阵形式布置在所述物理系统中,并用作相同维度n×m的数学矩阵的系数或权重。在这种物理系统中,忆阻器形成系数或权重的存储器。
忆阻器可以表示廉价的物理系统,因为忆阻器的空间需求很小。模数转换器和数模转换器没有这些优点。所述物理系统的精确度主要取决于忆阻器值的可实现分辨率、所述模数转换器和所述数模转换器的质量以及由此还取决于所述模数转换器和所述数模转换器的价格。
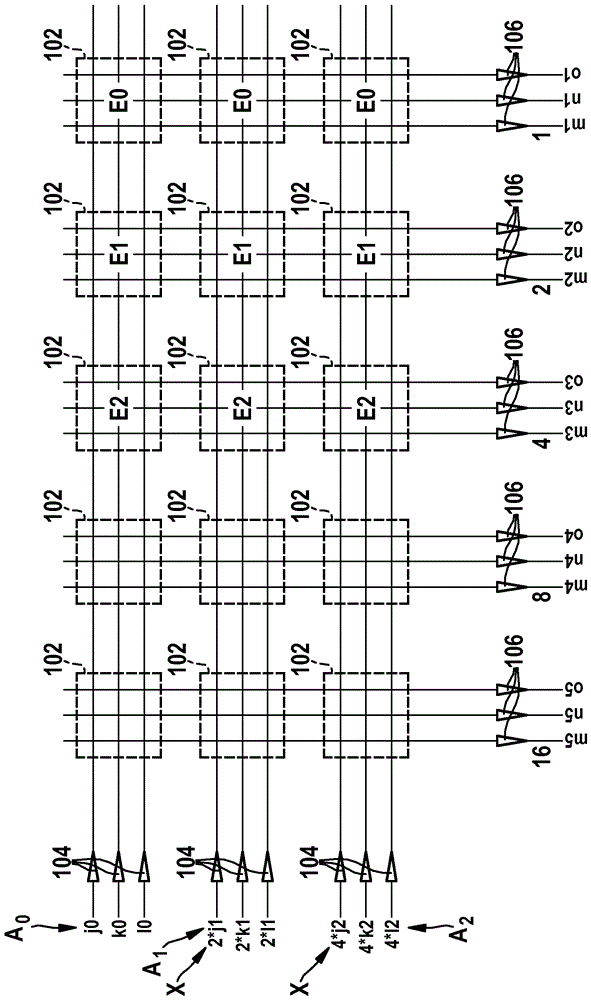
在图1中示例性地为用于实现矩阵运算(例如,矩阵乘法)的设备示意性地示出了矩阵布置100。
矩阵装置100包括多个忆阻器布置102,这些忆阻器布置的结构在图2中以忆阻器布置102为例详细示出。
忆阻器形成忆阻器阵列,其中这些忆阻器中的第一个布置在公共行线上。
在该示例中,也如图2所示,忆阻器布置102包括九个忆阻器a,...,i。第一忆阻器a布置在第一行线ji和第一列线mz之间。第二忆阻器b布置在第二行线ki和第一列线mz之间。第三忆阻器c布置在第三行线li与第一列线mz之间。第四忆阻器d布置在第一行线ji和第二列线nz之间。第五忆阻器e布置在第二行线ki与第二列线nz之间。第六忆阻器f布置在第三行线li与第二列线nz之间。第七忆阻器g布置在第一行线ji与第三列线oz之间。第八忆阻器h布置在第二行线ki与第三列线oz之间。第九忆阻器i布置在第三行线li与第三列线oz之间。
在该示例中,忆阻器布置102形成维度为3×3的对称忆阻器矩阵。该维度可以更大或更小。该忆阻器矩阵可以是不对称的。
在该示例中,矩阵布置100包括以三行和五列布置的十五个忆阻器布置102。矩阵布置100的第一行的忆阻器布置102的布置在该忆阻器矩阵的同一行中的忆阻器使用同一个第一行线并且与第一输入端j0连接。矩阵布置100的第二行的忆阻器布置102的布置在该忆阻器矩阵的同一行中的忆阻器使用同一个第二行线并且与第一输入端k0连接。矩阵布置100的第三行的忆阻器布置102的布置在该忆阻器矩阵的同一行中的忆阻器使用同一个第三行线并且与第一输入端l0连接。矩阵布置100的第一列的忆阻器布置102的布置在该忆阻器矩阵的同一列中的忆阻器使用同一个第一列线并且与第一输出端m5连接。矩阵布置100的第二列的忆阻器布置102的布置在该忆阻器矩阵的同一列中的忆阻器使用同一个第二列线并且与第二输出端n5连接。矩阵布置100的第三列的忆阻器布置102的布置在该忆阻器矩阵的同一列中的忆阻器使用同一个第三列线并且与第二输出端o5连接。
根据该电路图,矩阵布置100的其余忆阻器布置102与输入端j1,k1,11,j2,k2,12以及输出端m4,n4,o4,m3,n3,o3,m2,n2,o2,m1,n1,o1连接。
通常,图2中所示的忆阻器布置102的索引i说明矩阵装置100中的忆阻器布置102布置在其中的行。对于忆阻器布置102,图2中所示的索引z表征矩阵装置100中的忆阻器布置102布置在其中的列。在该示例中,将矩阵布置100的第一列分配给计算结果的最高有效比特msb。在该示例中,将矩阵布置100的最后一列分配给计算结果的最低有效比特lsb。每三个用相同索引表示的图1所示的相邻输出端被组合为列。从左侧的第一列到右侧的最后一列,为这些列分配因子16、8、4、2、1。这些因子说明2的幂,利用该幂在结果的数字求和中考虑列的模拟求和的结果。例如,根据矩阵运算所基于的比特因子分解来定义所述因子。
在该示例中,在每个行线上布置数模转换器104,该数模转换器104向忆阻器阵列供应输入电压。如果以二进制进行所述计算,则省略数模转换器104。数模转换器104必须能够映射列电流。所述列电流表示一列中最大权重的总和。在此要考虑到在一些设计中,该列的行电压已经配备有因子。在每个列线上布置数模转换器106。读出模拟结果的模数转换器106需要与所述忆阻器矩阵的大小相对于并且与输入变量的比特宽度相适配的分辨率,以便在其输出端上以足够的分辨率数字地输出输出值。在4×4矩阵的情况下,例如每列相加四个值,从而在这种情况下数模转换器106必须覆盖至少4倍大的值范围。如果已经为行电压赋值了一个因子,则必须对应地增大所述值范围。这对应于2比特倍大的值范围。还可以根据数模转换器的分辨率来定义分配给列的因子。这可能需要下面描述的输入电压适配。
在该示例中,如下所述,数模转换器104的输入端和模数转换器106的输出端以行或列分组地组合,并且被构造为执行以下计算。
通过该过程,可以以任意精确度计算与矩阵有关的计算。如下所述,矩阵的输入值和权重均被分解为各个比特。在该示例中,将输入值0×03分解为1比特因子,然后对应于0*2^2+1*2^1+1*2^0。
根据该方案,制定了整个矩阵运算。例如,可以将具有3比特宽的输入值和3比特权重的矩阵运算分解为81个每个1比特的矩阵运算,其中所有矩阵运算同时进行。
为此同时需要81个忆阻器。所使用的数模转换器和模数转换器仅需分辨少量级别。
在组件的分辨率方面可以对所述矩阵进行灵活的设计。这意味着:
数模转换器和模数转换器的分辨率是可伸缩的。例如,可以将矩阵的维度确定为,使得使用许多以较低分辨率工作或反过来的模数转换器。
如果将所使用的模数转换器的速度选择得比矩阵(即其部件或元素)的反应速度更快,或者如果使用的模数转换器和所使用的矩阵允许这一点,则在一方面规定,对模数转换器进行多路复用。该多路复用可以在所述矩阵内进行,也可以在存储器中的其他矩阵上进行。
由于可以减少状态数,因此忆阻器可以稳定且与温度无关地工作。
在二进制运行的情况下取消数模转换器。在二进制运行中,模数转换器在维度为n×n的矩阵情况下仅需n级分辨率。在二进制运行中,忆阻器分别仅需要两种状态,即1比特。在二进制运行中,可以非常快速地对忆阻器进行编程,特别是无需重复算法。
矩阵布置100可以任意伸缩。矩阵的数量线性取决于权重的分辨率。在该示例中,每个比特都使用一个矩阵。例如,对于具有3比特输入值和3比特输出值的维度为3×3的矩阵,具有三个矩阵的电路布置是合适的,每个矩阵用于计算三次。附加迭代的数量取决于输入值的分辨率。在该示例中,为每个比特设置一个迭代步骤。同样可以使用具有更高分辨率的忆阻器。如果可以用多于一比特的分辨率对忆阻器进行编程,则矩阵的数量将对应地减少。
为了操控所述矩阵布置,将矩阵运算分解为二进制分量。下面基于维度为3×3的矩阵和维度为3×1的向量对此进行描述。
首先,将期望的矩阵运算分解为各个比特
然后将以2为底的因子放在括号外,从而示例性地针对3比特得到解析值:
通过用e0,…替换以下矩阵
得到
在图1中示出了对用于计算该乘积的矩阵布置100的操控。更准确地说,首先在图1所示的节点上向忆阻器赋予来自矩阵e0,e1,e2的值,即对这些忆阻器进行对应的编程。在该示例中,将来自相应矩阵e0,e1,e2的行的值编程为忆阻器布置102的列中的电阻值或电导值,如图2所示。在图1中,用相同的索引表示相应矩阵e0,e1,e2向矩阵布置100的硬件中布置的分配。然后为图1中用j0,j1,j2,k0,k1,k2,l0、11,l2表示的输入端的输入值赋予相同索引的向量a0,a1,a2的值。这意味着这些输入端的数模转换器104施加对应的电压。更确切地说,在该示例中由于逻辑0的比特分解而未施加电压。相反,对于逻辑1则施加更高的电压。
这种矩阵布置100是由忆阻器组成的存储器。如果利用该存储器执行算术运算,即在内存中计算,则首先对应地写入存储器位置(即忆阻器)。然后将电压施加到该矩阵的一行上。在时间上至少部分与此叠加地将一列接地。通过在该行和该列的节点处的忆阻器流到接地点的的电流取决于该忆阻器的电阻值rknoten:i=u/rknoten。
如果将电压同时施加到多行并且又仅将一行接地,则流过该列中的每个忆阻器的电流是uzeile*1/rknoten。在该示例中,组合地操控组[j0,k0,l0],[j1,k1,11]和[j2,k2,l2]中的多个行。
然后在接地点,即在该示例中在连接到地的列的模数转换器106附近的列线上,将这些电流相加,从而对于电阻值为ra,rb,…的布置在行与该列的节点处的忆阻器而言,在向这些行中每一行施加电压uzeile时产生以下总和电流:
这些项是除法之和。如果使用对应的电导值而不是该表示,则评估乘积之和。如果还假定施加到一行上的电压uzeile在该整个行上都是相同的并且多列同时接地,则可以同时执行这些运算中的多个运算。
所产生的总和电流代表针对所考察的列线的计算的模拟结果,并且在该示例中通过相应的模数转换器106检测。模数转换器106优选地具有虚拟零点。这意味着这些列实际上并未接地。地电位通过所述虚拟零点提供。模数转换器106例如是跨阻放大器。该计算的数字结果是在长度为8位的示例中,根据在图3中针对标量j示例性示出的计算方案300,为标量j,k,l中的每个标量确定总和
在该示例中,分配给标量j的列线的数字化结果从矩阵布置100左侧的第一列开始用m5,m4,m3,m2和m1表示。这些数字化结果在图3中布置在行中。在该示例中,在一行中在总和
图4示意性地示出了电路400,该电路用于操控数模转换器104以向行线施加电压,并且用于操控模数转换器106以检测在列线上产生的电流。在该示例中,实现至少一个电开关装置402,其可以由微处理器404通过至少一个信号线406进行开关。例如,结型场效应晶体管被用作开关装置402中的电开关。矩阵布置100通过至少一个对应的电流源408与开关装置402连接。具有用于计算的寄存器的存储器410经由数据总线412与微处理器404连接。
微处理器404被构造为根据所描述的方法来操控矩阵布置100,以执行所述计算。
该方法的流程在图5中示意性地示出。在步骤502中,分解矩阵运算的待求解的方程。可以更精确地确定矩阵e0,e1,e2。
然后执行步骤504。
在步骤504中,对矩阵布置100的忆阻器布置102进行编程以用于所述计算。在该示例中,根据来自矩阵e0,e1,e2的值对这些忆阻器进行编程。对于具有3比特输入值和3比特输出值的维度为3×3的矩阵来说,具有三个矩阵的电路布置是合适的,每个矩阵用于计算三次。在图1中示出了一种可能的实现方式,其中用e0,e1,e2表示忆阻器布置102向矩阵e0,e1,e2的分配。在该示例中,所有乘以相同因子的矩阵乘法都一个位于另一个下方地布置,即,通过对应的操控来对忆阻器进行选择和编程。高电阻值例如表示逻辑1,而比较低的电阻值例如表示逻辑0。
然后执行步骤506。
在步骤506中,用j0,j1,j2,k0,k1,k2,l0,l1,l2表示的输入端的输入值被赋予根据具有j0,j1,j2,k0,k1,k2,l0,l1,l2的输入值的电压。这意味着这些输入端的数模转换器104施加对应的电压。
至少部分在时间上与此重叠地将得到的总和电流确定为对应列线上的计算的模拟结果。在该示例中,所考察的列线的总和电流由相应的模数转换器106检测。在该示例中,按照第一计算方案300将数字结果写入寄存器中的对应位置上以确定总和
在该示例中,组[j0,k0,l0],[j1,k1,l1]和[j2,k2,l2]被组合地操控,并且为对应的列线确定所述数字结果。
然后执行步骤508。
在步骤508中,为标量j,k,l中的每一个标量确定8比特的总和
根据这种方案,制定了整个矩阵运算。例如,可以将具有3比特宽的输入值和3比特权重的矩阵运算分解为81个每个1比特的矩阵运算,其中所有矩阵运算同时进行。
图6示出了第二计算方案600。按照第二计算方案600的计算实现进一步优化了上述过程,其方式是减少所需的寄存器数量。与第一计算方案300不同,第一数字化结果m1和第三数字化结果m3布置在同一行中。与第一计算方案300不同,第二数字化结果m2和第五数字化结果m1m5布置在同一行中。其余过程如第一计算方案300所述。
在这些计算中不使用本来规则的矩阵布置100中的一些忆阻器。这些计算对所使用的数模转换器106提出了不均匀的要求。用于确定输出值m3的数模转换器106被构造为分辨四个比特,用于确定输出值m4和m2的数模转换器106在该示例中被构造为分辨三个比特。在该示例中,其他数模转换器106被构造为仅分辨两个比特。
如果在矩阵e0,e1,e2的分配中为了对矩阵布置100的行中的忆阻器布置102进行编程进行移位,使得矩阵e0,e1,e2如图7所示一个位于另一个下方,则可以避免这种情况。
在这种情况下,通过经过适配的电压来校正分配的变化。对于所有参与的矩阵,将一行中的分配向右移位会产生因子为2的误差。这通过每次向右移位一个忆阻器布置102来使行上的输入电压提高到2倍来补偿。代替通过翻多倍来乘以因子,可以简单地从供电电压开始借助于分压器来执行除法。移位一个位置就被校正一次,移位两个位置就被校正两次。由此导致对具有输入值[j0,k0,l0],2*[j1,k1,l1]和4*[j2,k2,l2]的组的操控。
针对输入端处的因子的值x,如下计算得出模数转换器所需的分辨率:
其中y和z是忆阻器状态的最大值,即对于n比特的分辨率来说:y,z=2n-1。
在具有1比特忆阻器的示例中,z=1。行上的输入值同样具有1比特,因此y=1。
对于具有1比特忆阻器和3比特输入值(即每行1比特)的维度为3×3的矩阵,模数转换器必须分辨的状态数为21。
图8示出了第三计算方案800。按照第三计算方案800的计算实现进一步优化了上述过程。与第一计算方案300不同,仅布置第一数字化结果m1、第二数字化结果m2和第三数字化结果m3。与第一计算方案300不同,这些数字化结果具有相同的比特长度。其余过程如第一计算方案300所述。
模数转换器所需的分辨率基本上是由矩阵运算期间可达到的数字范围来得到的。
在一方面规定,导出中间和。如果允许矩阵运算所需的数字范围大于可用的模数转换器的分辨率,则可以例如导出中间和。
在此,所需的全部模数转换器的数量增加,分辨率降低。可以在图9中看到示例性的实现。
与上面基于图7描述的实现不同,在矩阵布置100的第二行和第三行之间的每条列线上分别布置有用于模数转换器106的抽头。可以将列线接地以及将电压施加到行线的顺序选择为,使得对于每个列线电流仅流经布置在该列线上的抽头之一。然后可以将该列线构造为连续的,而不会影响总和电流的计算。该列线可以在第三行和第二行的忆阻器布置之间的引出线的位置处优选永久地电中断,以模拟地确定总和电流。这样产生的模拟中间和由所述抽头检测,然后数字相加。
用[m5,n5,o5]、[m4,n4,o4]、[m3,n3,o3]、[m2,n2,o2]、[m1,n1,o1]表示具有说明第三行的模拟中间和的输出值的组。用[r5,s5,t5]、[r4,s4,t4]、[r3,s3,t3]、[r2,s2,t2]、[r1,s1,t1]表示具有说明第一行和第二行的模拟中间和的输出值的组。
其余过程与上述过程相对应,其中将图10中针对标量j示例性示出的计算方案1000用于标量j,k,l的计算。
分配给标量j的输出值r1,r2和r3以此顺序从总和
在该示例中,考虑第三行的模数转换器需要2比特的分辨率。不考虑第三行的模数转换器需要4比特的分辨率。
可以在不同位置导出这种模拟中间和。在图11中示出了另一种划分,其中导出每个中间和。必要时,可以将电压因子与行适配,或者如果将在中间和的进一步数字计算时考虑所述电压因子,则可以省略所述电压因子。
与上面基于图9描述的布置不同,仅九个忆阻器布置102布置为维度为3×3的矩阵布置。附加地,模数转换器106布置在矩阵布置100的第一列和第二列之间的引出线中。
用[m3,n3,o3]、[m2,n2,o2]、[m1,n1,o1]表示具有说明第三行的中间和的输出值的组。用[r3,s3,t3]、[r2,s2,t2]、[r1,s1,t1]表示具有考虑第二行但不考虑第一行和第三行的输出值的组。具有仅考虑了第一行的输出值的组用[u3,u3,u3]、[u2,v2,w2]、[u1,v1,w1]表示。向同一列线分配了用j,r和u、用k,s和v以及用l,r和w表征的输出端。
可以选择将列线接地和向行线施加电压的顺序,使得对于每个列线电流仅流过一个抽头。然后在该抽头处的列线可以被构造为连续的,而不会影响总和电流的计算。该列线可以在第三行和第二行的忆阻器布置之间的引出线的位置处被永久电中断以确定总和电流。
其余过程与上述过程相对应,其中将图12中针对标量j示例性示出的计算方案1200用于标量j,k,l的计算。
在对行线施加电压时,行电压始终相同。通过在寄存器中的不同比特位置上显现模数转换器的结果,可以实现先前所需的因子,在该示例中是2或4。
第一行和第二行之间的输出值从在总和
第二行和第三行之间的输出值从输出值r1的lsb开始布置,该输出值r1的lsb相对于总和
第三行之后的输出值从输出值m1的lsb开始布置,该输出值m1的lsb相对于总和
在第一和第三行的情况下,两个模数转换器甚至都可以将它们的结果显现在同一个中间和中。
如上所述,所述结果的求和逐列进行。
在这种布置中,仅还需要分辨率为2比特的模数转换器。这些模数转换器可以只由两个比较器组成。这些模数转换器可以在高达ghz的范围内工作。
另一方面涉及将忆阻器的分辨率提高到2比特。这意味着将多个状态编程到一个忆阻器中。在类似于所描述的具有1比特分解的矩阵运算来分解所述矩阵时,要考虑到这一点。
这意味着2比特值被表示为,使得每两个比特,在该示例中是比特0和1,比特2和3,..组合在一起。通过替换具有以下等式的矩阵运算中的变量
得到
类似于1比特分解情况下的过程,对于2比特矩阵得到
将这些方程项实现为忆阻器矩阵同样类似于用于1比特矩阵运算的矩阵布置100。
在图13中示出了从矩阵布置100的描述出发的实现,该矩阵布置100已基于图7进行了描述。特别是矩阵e0,e1,e2和在输入值j1,k1,l1情况下的因子2以及在输入值j2,k2,l2情况下的因子4的布置如上所述。
与图7所示的布置不同,在这些项之前考虑了变化的因子。该示例中使用的矩阵的三个右列的输出值m1,...o5被对应地表征。这种布置对在模数转换器116中实现的分辨率提出了更高的要求。
如该示例中具有z=4和y=1的2比特忆阻器一样,为值x计算所需要的模数转换器116的分辨率:
对于维度为3×3的矩阵,通过2比特忆阻器和3比特输入值(即,矩阵布置100的每行仅1个比特),模数转换器116必须分辨的状态数为84。
在图14中示出的计算方案1400示例性地针对所有标量j,k,l通过12比特总和
使用对应的方法来提高忆阻器的分辨率和输入值。
为此,通过具有因子20,22,24和具有以下替换的向量分解
将先前使用的分解更改如下:
将这些方程项实现为忆阻器矩阵类似于基于图13描述的实现进行。
所得矩阵布置100在图15中示出。与先前的实现不同,现在使用因子4来施加在输入端j1,k1,l1处的电压。与先前的实现不同,现在使用因子16来施加在输入端j2,k2,l2处的电压。
这些项前面的变化的因子导致对模数转换器116的分辨率的要求。在具有1比特忆阻器和3比特输入值的1比特矩阵中,z=1和y=1。在该示例中,使用2比特忆阻器和6比特输入值(即z=2和y=2)来计算所需的模数转换器116的分辨率。对于该示例中所示的维度为3×3并且具有2比特忆阻器和6比特输入值(这些输入值每行有2比特)的矩阵而言,模数转换器116必须分辨的状态数是1008。
在图16中示出的计算方案1600示例性地针对所有标量j,k,l通过12比特总和
n*n矩阵的经典计算需要n2次乘法和n2-n次加法。在8×8矩阵的情况下,这将是具有8比特输入值(即,具有16比特的宽度)的64次乘法和56次加法。大约需要118个时钟。
所提出的方法需要输入值的3*8次移位运算和输出值的8*8次加法以及64次具有3比特分辨率的ad转换。然而,通过高度的并行化,仅需要大约10个时钟。
该方法可以应用于其他变量和分辨率的矩阵。
在一个方面,设置了一种忆阻器布置,其中两个忆阻器布置在矩阵布置100的行和列的节点处,这两个忆阻器在它们的取决于电荷的电阻值方面可以向相反的方向变化。可以用相同的电压同时用倒置的权重对这两个忆阻器进行编程。因此可以同时执行两个电流值计算。但是,在此这两个计算之一使用倒置的权重。由此,模数转换器计数为零,在解释该结果时或在算法中可以将这一点考虑在内。例如,可以使用这种冗余性来检查所述结果的合理性。
- 还没有人留言评论。精彩留言会获得点赞!