通过迁移学习生成具有不同疲劳程度的视频数据集的系统和方法与流程
1.本公开大体上涉及驾驶员疲劳的检测,具体涉及生成视频数据集以训练应用程序以供用于识别驾驶员何时疲倦。
背景技术:
2.驾驶员疲劳或困倦正日益成为车辆事故的常见原因。驾驶员困倦检测和监控对于确保安全的驾驶环境至关重要,这不仅对困倦的驾驶员来说是如此,而且对于可能会受到困倦的驾驶员影响的附近其他驾驶员来说也是如此。具有监控驾驶员能力的车辆允许车辆采取措施以防止或协助防止因驾驶员困倦而导致的事故。举例来说,可以启用报警系统以警告驾驶员其处于困倦状态,或者可以启用自动功能,诸如制动和转向以控制车辆,直到驾驶员不再疲倦为止。然而,很少有公共数据集可以训练应用程序以对特定驾驶员执行此种检测和监控,其中每个驾驶员都具有其自身的个人能力以承受各种程度的疲劳,以及具有不同指标以显示特定驾驶员的各种睡意程度。因此,如果根据单一标准来确定驾驶员的睡意状态,驾驶员检测和监控系统可能会过度响应或响应不足,这可能不会提高驾驶员的安全性。
技术实现要素:
3.根据本公开的一个方面,存在一种用于训练应用程序以识别驾驶员疲劳的计算机实施的方法:使用第一神经网络从多个第二面部表情图像生成多个第一面部表情图像,其中,根据从所述第一神经网络学习的所述多个第二面部表情图像的第一表示来重构所述多个第一面部表情图像;基于所述第一表示,使用第二神经网络从表达当前疲劳程度之前的疲劳程度的第三面部表情图像和第二图像生成表达所述当前疲劳程度的第一图像,其中,根据所述第一表示以及从所述第二神经网络学习的所述第三面部表情图像的第二表示来重构所述第一图像和所述第二图像;在相应的光流期间,从所述第一图像和所述第二图像生成内插视频数据的多个中间图像,其中,所述光流通过融合所述第一图像和所述第二图像来形成并且位于所述第一图像与所述第二图像之间的时间帧中;以及,至少使用所述第一图像和所述第二图像以及所述内插视频数据的所述多个中间图像来编译驾驶员的假疲劳状态视频,以在其中训练所述应用程序以检测所述驾驶员疲劳。
4.任选地,在任一前述方面中,其中,所述第一个神经网络执行以下步骤:将所述多个第二面部表情图像映射到相应的第一表示;以及,将所述相应的第一表示映射到具有与所述多个第二面部表情图像相同的表情的所述多个第一面部表情图像。
5.任选地,在任一前述方面中,其中,所述第二个神经网络包括执行以下步骤的条件变分自动编码器:对所述第三面部表情图像和所述第二图像进行编码,并且输出描述所述第二表示的每个维度的分布的参数;以及,通过计算每个参数相对于输出损失的关系对所述第二表示的每个维度的所述分布进行解码,以重构所述第三面部表情图像和所述第二图
像。
6.任选地,在任一前述方面中,其中,所述第二神经网络还包括执行以下步骤的生成式对抗网络(generative adversarial network,gan):将所述重构图像与所述第三面部表情图像进行比较,以生成鉴别器损失;将所述重构图像与处于相同程度的地面真实图像进行比较,以生成重构损失;基于所述鉴别器损失和所述重构损失,预测所述重构图像具有与所述第三面部表情图像相对应的外观的可能性;以及,当所述预测将所述第一图像分类为真实图像时,将所述重构图像作为表达当前疲劳程度的所述第一图像而输出、并且作为表达所述当前疲劳程度之前的疲劳程度的所述第二图像而输入到所述条件变分自动编码器。
7.任选地,在任一前述方面中,其中,所述重构损失指示所述第三面部表情图像与所述重构图像之间的相异度,并且所述鉴别器损失指示生成不正确的预测的成本,所述预测是指所述重构图像具有所述第三面部表情图像的所述外观。
8.任选地,在任一前述方面中,所述计算机实施的方法还包括:根据在不同时间帧处的所述第一图像与所述第二图像之间的差异,以不同的疲劳程度迭代地生成所述第一图像,直到所述重构损失和所述鉴别器损失的总值满足预定标准。
9.任选地,在任一前述方面中,其中,生成所述多个中间图像还包括:在所述相应的光流期间,预测所述第一图像与所述第二图像之间的中间图像;以及,内插所述第一图像和所述第二图像,以生成所述相应的光流,以在其中生成所述驾驶员的所述假疲劳状态视频。
10.任选地,在任一前述方面中,其中,生成所述多个中间图像还包括:接收以输入顺序布置的中间图像的序列;使用编码器处理中间图像的所述序列,以将中间图像的所述序列转换成中间图像的所述序列的替代性表示;以及,使用解码器处理中间图像的所述序列的所述替代性表示,以生成中间图像的所述序列的目标序列,所述目标序列包括根据输出顺序布置的多个输出。
11.任选地,在任一前述方面中,其中,所述第一表示通过学习分布将所述多个第二面部表情图像映射到所述第一表示。
12.任选地,在任一前述方面中,其中,所述第二表示通过学习分布将所述第三面部表情图像映射到所述第二表示。
13.根据本公开的一个其它方面,提供一种用于训练应用程序以识别驾驶员疲劳的设备,所述设备包括:非瞬时性存储器,其包括指令;以及一个或多个处理器,其与所述存储器通信,其中,所述一个或多个处理器执行所述指令以:使用第一神经网络从多个第二面部表情图像生成多个第一面部表情图像,其中,根据从所述第一神经网络学习的所述多个第二面部表情图像的第一表示来重构所述多个第一面部表情图像;基于所述第一表示,使用第二神经网络从表达当前疲劳程度之前的疲劳程度的第三面部表情图像和第二图像生成表达所述当前疲劳程度的第一图像,其中,根据所述第一表示以及从所述第二神经网络学习的所述第三面部表情图像的第二表示来重构所述第一图像和所述第二图像;在相应的光流期间,从所述第一图像和所述第二图像生成内插视频数据的多个中间图像,其中,所述光流通过融合所述第一图像和所述第二图像来形成并且位于所述第一图像与所述第二图像之间的时间帧中;以及,至少使用所述第一图像和所述第二图像以及所述内插视频数据的所述多个中间图像来编译驾驶员的假疲劳状态视频,以在其中训练所述应用程序以检测所述驾驶员疲劳。
14.根据本公开的又一个其它方面,存在一种非瞬时性计算机可读介质,其存储用于训练应用程序以识别驾驶员疲劳的指令,所述指令在由一个或多个处理器执行时,使所述一个或多个处理器执行以下步骤:使用第一神经网络从多个第二面部表情图像生成多个第一面部表情图像,其中,根据从所述第一神经网络学习的所述多个第二面部表情图像的第一表示来重构所述多个第一面部表情图像;基于所述第一表示,使用第二神经网络从表达当前疲劳程度之前的疲劳程度的第三面部表情图像和第二图像生成表达所述当前疲劳程度的第一图像,其中,根据所述第一表示以及从所述第二神经网络学习的所述第三面部表情图像的第二表示来重构所述第一图像和所述第二图像;在相应的光流期间,从所述第一图像和所述第二图像生成内插视频数据的多个中间图像,其中,所述光流通过融合所述第一图像和所述第二图像来形成并且位于所述第一图像与所述第二图像之间的时间帧中;以及至少使用所述第一图像和所述第二图像以及所述内插视频数据的所述多个中间图像来编译驾驶员的假疲劳状态视频,以在其中训练所述应用程序以检测所述驾驶员疲劳。
15.提供本发明内容来以简化形式引入一些概念,这些概念将在下文的具体实施方式中进一步描述。本发明内容既不旨在识别要求保护的主题的关键特征或必要特征,也不旨在用于帮助确定要求保护的主题的范围。要求保护的主题不限于解决背景技术中指出的任何或所有缺点的实施方案。
附图说明
16.本公开的方面通过示例的方式进行展示,并且不受附图的限制,对于附图,相同的附图标记指示元件。
17.图1a展示了根据本技术的实施例的驾驶员监控系统。
18.图1b示展示了根据图1a的驾驶员监控系统的详细示例。
19.图2展示了表情识别网络的示例。
20.图3展示了示例性的面部疲劳程度生成器网络。
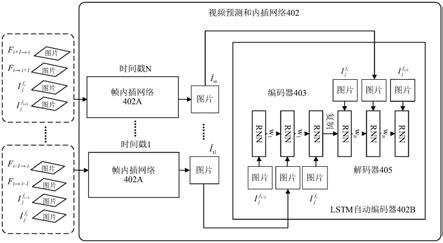
21.图4a展示了视频预测和内插网络。
22.图4b展示了根据图4a的示例性的帧内插网络。
23.图4c展示了具有lstm自动编码器的展开视图的图4a的视频预测和内插网络的示例。
24.图5a至5d展示了根据本技术的实施例的示例流程图。
25.图6展示了可在其上实施本公开的实施例的计算系统。
具体实施方式
26.现在将参照附图描述本公开,这些附图大体上涉及驾驶员注意力检测。
27.本技术涉及使用由假疲劳状态视频数据集训练的应用程序对特定驾驶员进行驾驶员疲劳检测,所述驾驶员疲劳也称为驾驶员困倦、疲倦和睡意。用于训练应用程序以检测驾驶员疲劳的传统数据集通常基于不特定于单个驾驶员的公共数据集。通常,这会导致应用程序在不存在驾驶员疲劳的情况下检测到驾驶员疲劳,或者在存在驾驶员疲劳时检测不到驾驶员疲劳。在实施例中,通过所公开的技术生成与特定或单个驱动器相关联的个体化假疲劳状态视频数据集。这些数据集是通过内插图像序列以及使用各种机器学习技术和神
经网络预测图像的下一帧或序列来生成的。
28.应当理解的是,本公开的当前实施例可以以多种不同的形式来实施,并且权利要求范围不应被解释为限于本文中所阐述的实施例。相反,提供这些实施例使得本公开将是彻底和完整的,并且将本发明的实施例概念充分传达给本领域技术人员。实际上,本公开旨在覆盖包括在如由所附权利要求定义的本公开的范围和精神内的这些实施例的替代物、修改和等同物。此外,在本公开的当前实施例的以下详细描述中,阐述了许多具体细节以便提供透彻的理解。然而,本领域普通技术人员将清楚的是,可以在没有此些具体细节的情况下实践本公开的当前实施例。
29.图1a展示了根据本技术的实施例的驾驶员分心系统。驾驶员分心系统106示出为安装在或以其它方式包括在车辆101内,所述车辆还包括驾驶员102可以坐在其中的驾驶室。驾驶员分心系统106,或其一个或多个部分可以由驾驶室内计算机系统和/或由移动计算设备实施,所述移动计算设备诸如但不限于智能手机、平板电脑、笔记本电脑、膝上型电脑等。
30.根据本技术的某些实施例,驾驶员疲劳系统106从一个或多个传感器获得(或收集)车辆101的驾驶员102的当前数据。在其它实施例中,驾驶员疲劳系统106还从一个或多个数据库140获得(或收集)关于驾驶员102的附加信息,这是因为所述附加信息涉及驾驶员的特征,诸如面部特征、历史头部姿势和眼睛注视信息等。驾驶员疲劳系统106对车辆101的驾驶员102的当前数据和/或附加信息进行分析,从而识别驾驶员的头部姿势和眼睛注视。在一个实施例中,驾驶员疲劳系统106另外监控并收集车辆数据和场景信息,如下文所描述。可以使用一个或多个计算机实施的神经网络和/或一些其它计算机实施的模型来执行此种分析,如下文所解释。
31.如图1a所示,驾驶员疲劳系统106通信地耦合到捕获设备103,所述捕获设备可以用于获得车辆101的驾驶员的当前数据以及车辆数据和场景信息。在一个实施例中,捕获设备103包括传感器和其它设备,这些传感器和其它设备用于获得车辆101的驾驶员102的当前数据。捕获的数据可以由处理器104进行处理,所述处理器包括硬件和/或软件以检测和追踪驾驶员运动、头部姿势和注视方向。如下文将参照图1b另外详细地描述的,捕获设备可以另外包括一个或多个摄像头、麦克风或其它传感器以捕获数据。在另一实施例中,捕获设备103可以捕获车辆正在行驶的路线的前向场景(例如,周围环境和/或场景信息)。前向传感器可以包括例如雷达传感器、激光传感器、激光雷达传感器、光学成像传感器等。应了解的是,传感器还可以覆盖车辆101的侧面、后部和顶部(面向上和面向下)。
32.在一个实施例中,捕获设备103可以在驾驶员疲劳系统106的外部,如图1a所示,或者可以被包括为驾驶员疲劳系统106的一部分,这取决于具体的实施方案。下文参照图1b描述根据本技术的某些实施例的驾驶员疲劳系统106的附加细节。
33.仍然参照图1a,驾驶员疲劳系统106还示出为通信地耦合到包括在车辆101内的各种不同类型的车辆相关传感器105。此些传感器105可以包括但不限于速度计、全球定位系统(global positioning system,gps)接收器,以及时钟。驾驶员疲劳系统106还示出为通信地耦合到一个或多个通信网络130,所述一个或多个通信网络提供对一个或多个数据库140和/或其它类型的数据存储的访问。数据库140和/或其它类型的数据存储可以存储车辆101的车辆数据。此些数据的示例包括但不限于驾驶记录数据、驾驶性能数据、驾驶执照类
型数据、驾驶员面部特征、驾驶员头部姿势、驾驶员注视等。此些数据可以存储在位于车辆101内的本地数据库或其它数据存储中。然而,数据可能存储在相对于车辆101远程定位的一个或多个数据库140或其它数据存储中。因此,此些数据库140或其它数据存储可以通过一个或多个通信网络130通信地耦合到驾驶员分心系统。
34.通信网络130可以包括数据网络、无线网络、电话网络、或它们的任何组合。预期数据网络可以是任何局域网(local area network,lan)、城域网(metropolitan area network,man)、广域网(wide area network,wan)、公共数据网(例如,互联网)、短距离无线网络、或任何其它合适的分组交换网络。另外,无线网络可以是例如蜂窝网络,并且可以采用各种技术,包括:增强型数据速率全球演进(enhanced data rates for global evolution,edge)、通用分组无线业务(general packet radio service,gprs)、全球移动通信系统(global system for mobile communication,gsm)、互联网协议多媒体子系统(internet protocol multimedia subsystem,ims)、通用移动通信系统(universal mobile telecommunications system,umts)等;以及任何其它合适的无线介质,例如,全球微波接入互操作性(worldwide interoperability for microwave access,wimax)、长期演进(long term evolution,lte)网络、码分多址(code division multiple access,cdma)、宽带码分多址(wideband code division multiple access,wcdma)、无线保真(wireless fidelity,wi-fi)、无线局域网(wireless lan,wlan)、蓝牙技术、互联网协议(internet protocol,ip)数据广播、卫星、移动自组织网络(satellite,mobile ad-hoc network,manet)等;或它们的任何组合。通信网络130可以例如通过通信设备102(图1b)提供驾驶员分心系统106与数据库140和/或其它数据存储器之间的通信能力。
35.虽然参照车辆101来描述图1a的实施例,但是应了解的是,所公开的技术可以应用于广泛的技术领域,并且不限于车辆。例如,除车辆外,所公开的技术可以用于虚拟或增强现实设备中或模拟器中,其中可能需要头部姿势和注视估计、车辆数据和/或场景信息。
36.现在将参照图1b描述根据本技术的某些实施例的驾驶员疲劳系统106的附加细节。|驾驶员疲劳系统106包括捕获设备103、一个或多个处理器108、车辆系统104、机器学习引擎109、输入/输出(input/output,i/o)接口114、存储器116、视觉/音频警告装置118、通信设备120和数据库140(其也可以是驾驶员疲劳系统的一部分)。
37.捕获设备103可以负责基于捕获的驾驶员运动和/或音频数据,使用定位于驾驶室内的一个或多个捕获设备,诸如传感器103a、摄像头103b或麦克风103c来监控和识别驾驶员行为(包括疲劳)。在一个实施例中,捕获设备103被定位成捕获驾驶员的头部和面部的运动,而在其它实施方案中,还捕获驾驶员的躯干和/或驾驶员的四肢和手部的运动。例如,检测和追踪108a、头部姿势估计器108b和注视方向估计器108c可以监控由捕获设备103捕获的驾驶员运动,以检测特定姿势,诸如头部姿势,或者检测驾驶员是否正看向特定方向。
38.其它实施例包括通过麦克风103c与驾驶员运动数据一起或分开捕获的音频数据。捕获的音频可以是例如由麦克风103c捕获的驾驶员102的音频信号。可以对音频进行分析,以检测可以根据驾驶员状态而变化的各种特征。此些音频特征的示例包括驾驶员语音、乘客语音、音乐等。
39.尽管捕获设备103被描述为具有多个组件的单一设备,但是应了解的是,每个组件(例如,传感器、摄像头、麦克风等)可以是位于车辆101的不同区域中的单独组件。例如,传
感器103a、摄像头103b、麦克风103c和深度传感器103d各自可以位于车辆驾驶室的不同区域中。在另一示例中,捕获设备103的单个组件可以是另一组件或设备的一部分。例如,摄像头103b和视觉/音频118可以是放置在车辆驾驶室中的移动电话或平板电脑(未示出)的一部分,而传感器103a和麦克风103c可以单独位于车辆驾驶室中的不同位置中。
40.检测和追踪108a监控由捕获设备103捕获的驾驶员102的面部特征,然后可以继检测驾驶员的面部之后提取所述面部特征。术语面部特征包括但不限于围绕眼睛、鼻子和嘴巴区域的点(或面部标志)以及勾勒出驾驶员102的所检测到的面部的轮廓部分的点。基于监控到的面部特征,可以检测驾驶员102的眼球的一个或多个眼睛特征的初始位置。眼睛特征可以包括虹膜以及眼球的第一和第二眼角。因此,例如,检测一个或多个眼睛特征中的每一个的位置包括:检测虹膜的位置、检测第一眼角的位置以及检测第二眼角的位置。
41.头部姿势估计器108b使用监控到的面部特征来估计驾驶员102的头部姿势。如本文所用,术语“头部姿势”描述的角度是指驾驶员的头部相对于捕获设备103的平面的相对定向。在一个实施例中,头部姿势包括驾驶员的头部相对于捕获设备平面的偏航角和俯仰角。在另一实施例中,头部姿势包括驾驶员的头部相对于捕获设备平面的偏航角、俯仰角和滚转角。
42.注视方向估计器108c估计驾驶员的注视方向(和注视角度)。在注视方向估计器108c的操作中,捕获设备103可以捕获(例如,车辆驾驶员的)图像或图像组。捕获设备103可以向注视方向估计器108c发送图像,其中注视方向估计器108c从图像中检测面部特征并且追踪(例如,随着时间)驾驶员的注视。一种这样的注视方向估计器是smart eye 的眼睛追踪系统。
43.在另一实施例中,注视方向估计器108c可以从捕获的图像中检测眼睛。例如,注视方向估计器108c可以依赖眼睛中心来确定注视方向。简言之,可以假设驾驶员相对于其头部的定向向前注视。在一些实施例中,注视方向估计器108c通过检测瞳孔或虹膜位置或使用几何模型来提供更精确的注视追踪,所述几何模型基于所估计的头部姿势,以及虹膜以及第一眼角和第二眼角中的每一个的所检测到的位置。瞳孔和/或虹膜追踪使得注视方向估计器108c能够检测从头部姿势去耦合的注视方向。驾驶员经常以很少或没有头部运动来视觉地扫描周围的环境(例如,向左或向右(或向上或向下)扫视以更好地看到其直接视线之外的物品或对象)。这些视觉扫描针对道路上或附近的对象(例如,以查看道路标志、道路附近的行人等)以及针对车辆驾驶室内的对象(例如,以查看诸如速度的控制台读数、操作收音机或其它内置式设备、或查看/操作个人移动设备)频繁发生。在一些情况下,驾驶员可能以最小的头部运动来扫视(例如,在其眼角外的)这些对象中的一些或全部。通过追踪瞳孔和/或虹膜,注视方向估计器108c可以检测向上、向下和侧向扫视,这些扫视原本在简单地追踪头部位置的系统中是无法被检测的。
44.在一个实施例中,并且基于检测到的面部特征,注视方向估计器108c可以使处理器108确定注视方向(例如,操作员在车辆上的注视方向)。在一些实施例中,注视方向估计器108c接收一系列图像(和/或视频)。注视方向估计器108c可以检测多个图像(例如,一系列图像或图像序列)中的面部特征。因此,注视方向估计器108c可以随着时间追踪注视方向,并且将此种信息存储在例如数据库140中。
45.除了上述姿势和注视检测之外,处理器108还可以包括图像校正器108d、视频增强
器108e、视频场景分析器108f、和/或其它数据处理和分析,以确定由捕获设备103捕获的场景信息。
46.图像校正器108d接收捕获的数据,并且可以进行校正,诸如视频稳定化。例如,道路上的颠簸可能会使数据抖动、模糊或失真。图像校正器可以使图像稳定以对抗水平和/或竖直抖动,和/或可以对平移、旋转和/或缩放进行校正。
47.视频增强器108e可以在照明不佳或数据高压缩的情况下执行额外的增强或处理。视频处理和增强可以包括但不限于伽马校正、去雾浊和/或去模糊。可以运行其它视频处理增强算法以减少低照度视频的输入中的噪声,然后使用对比度增强技术,诸如但不限于色调映射,直方图拉伸和均衡化,以及伽马校正,以恢复低照度视频中的视觉信息。
48.视频场景分析器108f可以识别来自捕获设备103的视频的内容。例如,视频的内容可以包括来自车辆中的前向摄像头103b的场景或场景序列。视频分析可能涉及多种技术,包括但不限于诸如特征提取、结构分析、对象检测、以及追踪的低水平内容分析,以及诸如场景分析、事件检测和视频挖掘的高水平语义分析。例如,通过识别输入的视频信号的内容,可以确定:车辆101是沿着高速公路行驶还是在市区范围内行驶,道路上是否有任何行人、动物或其它对象/障碍物等。通过同时执行图像分析(例如,视频场景分析等)或在执行其之前来执行图像处理(例如,图像校正、视频增强等),可以以特定于被执行的分析的类型的方式来准备图像数据。例如,减少模糊的图像校正可以通过清除用于对象识别的边缘线的外观来允许视频场景分析被更准确地执行。
49.车辆系统104可以提供与车辆的任何状态、车辆周围环境、或连接到车辆的任何其它信息源的输出相对应的信号。车辆数据输出可以包括例如:模拟信号(诸如当前速度)、由单个信息源(诸如时钟、温度计、以及诸如全球定位系统(global positioning system,gps)传感器等的位置传感器)提供的数字信号、通过车辆数据网络(诸如:发动机控制器局域网(controller area network,can)总线,可以通过所述总线传送发动机相关信息;气候控制can总线,可以通过所述总线传送气候控制相关信息;以及多媒体数据网络,通过所述网络,多媒体数据在车辆中的多媒体组件之间进行通信)传播的数字信号。例如,车辆系统104可以从发动机can总线检索由车轮传感器估计的车辆当前速度、基于车辆的电池和/或电力分配系统的车辆电力的状态、车辆的点火状态等。
50.输入/输出接口114使用各种输入/输出设备来使信息被呈现给用户和/或其它组件或设备。输入设备的示例包括键盘、麦克风、触摸功能(例如,用于检测物理触摸的电容式传感器或其它传感器)、摄像头(例如,所述摄像头可以采用可见或不可见波长,诸如红外频率,来将运动识别为不涉及触摸的手势)等等。输出设备的示例包括视觉/音频警告装置118,诸如显示器、扬声器等等。在一个实施例中,输入/输出(i/o)接口114从捕获设备103接收驾驶员102的驾驶员运动数据和/或音频数据。驾驶员运动数据可以与例如驾驶员102的眼睛和面部相关,可以由处理器108进行分析。
51.驾驶员疲劳系统106收集的数据可以存储在数据库140、存储器116、或它们的任何组合中。在一实施例中,收集的数据来自车辆101外部的一个或多个源。存储的信息可以是与驾驶员分心和安全相关的数据,诸如由捕获设备103捕获的信息。在一个实施例中,存储在数据库140中的数据可以是针对车辆101的一个或多个驾驶员收集的数据的集合。在一个实施例中,收集的数据是车辆101的驾驶员的头部姿势数据。在另一实施例中,收集的数据
是车辆101的驾驶员的注视方向数据。收集的数据还可以用于生成数据集和信息,所述数据集和信息可以用于训练用于机器学习的模型,诸如机器学习引擎109。
52.在一个实施例中,存储器116可以存储可由以下各项执行的指令:处理器108、机器学习引擎109、以及可由处理器108加载并执行的程序或应用程序(未示出)。在一个实施例中,机器学习引擎109包括存储在存储器116中的可由处理器108执行的可执行代码,并且选择存储在存储器116(或数据库140)中的一个或多个机器学习模型。可以使用例如根据在下文中描述的实施例生成的数据集、使用众所周知和常规的机器学习和深度学习技术,诸如卷积神经网络(convolutional neural network,cnn)的实施,来开发和训练机器模型。
53.图2展示了表情识别网络的示例。表情识别网络202接收任意面部图像201a,所述面部图像可以使用诸如摄像头103以及扫描仪的捕获设备,以及诸如数据库104的图像数据库等来捕获。由具有自动编码风格网络架构的表情识别网络202对本质上可以是任意的任意面部图像201a进行处理,以输出面部表情图像201b。然后将在自动编码学习期间学习到的表示用于协助形成数据集,以训练机器模型,诸如上文描述的那些模型。然后可以使用机器模型来生成驾驶员的假疲劳状态视频,所述视频可以结合个体化数据使用,以训练应用程序以检测特定驾驶员的驾驶员疲劳(即,困倦、睡意或疲倦)。
54.在执行自动编码学习中,输入到表情识别网络202的任意面部图像201a被分类为种类或类别。在一个实施例中,输入的任意面部图像201a是任意的面部表情,诸如愤怒、恐惧或中性图像,并且输出的面部表情图像201b是已经被分类为种类或类别的面部表情或情感图像,所述面部表情或情感诸如厌恶、悲伤、喜悦或惊奇。
55.在一个示例中,表情识别网络202使用神经网络,诸如自动编码器(auto-encoder,ae)或条件变分自动编码器(conditional variational auto-encoder,cvae),从输入的任意面部图像201a生成面部表情图像201b。表情识别网络202旨在有效地学习潜在或所学表示(或代码),即,所学表示zg,其从任意面部图像201a生成输出的表情201b。例如,恐惧的任意图像可以使用所学表示zg来生成惊奇的面部表情图像。
56.学习在附接到所学表示z的层(例如,编码器层和解码器层)中进行。例如,将输入的任意面部图像201a输入到第一层(例如,编码器204)中。所学表示zg压缩(减小)输入的任意面部图像201a的尺寸。输入的任意面部图像201a在第二层(例如,解码器206)中重构,所述第二层输出与输入的任意面部图像201a相对应的面部表情图像201b。更具体地说,表情识别网络202被训练成将输入的任意面部图像201a编码为所学表示zg,由此可以根据所学表示zg来重构输入的任意面部图像201a。在一个实施例中,编码器204根据z=σ(wx+b)创建所学表示zg,其中“w”是编码权重,“b”是偏差向量,“σ”是逻辑函数(诸如sigmoid函数或修正线性单元),并且“x”是输入的任意面部图像201a。表情识别网络202还含有解码器206,所述解码器根据x
′
=σ
′
(w
′
z+b
′
)重构输入的任意面部图像201a,其中“w
′”
是解码权重,“b
′”
是偏差向量,“σ”是逻辑函数,并且“x”是输出的面部表情图像201b。所述学习包括使与编码和解码相关的重构错误最小化,使得min
w,b
||y-x||f。
57.然后,可以将所学表示zg用于训练另外的机器模型,如下文参照图3所提供的解释。
58.图3展示了面部疲劳程度生成器网络。面部疲劳程度生成器网络302包括cvae 304和生成式对抗网络(generative adversarial network,gan)306。面部疲劳程度生成器网
络302接收诸如图像序列或视频之类的内容,对所述内容进行处理以识别输入的内容是“真实”内容还是“假”内容。
59.在一个实施例中,耦合cvae 304以用于接收内容,对所述内容进行处理以输出所述内容的重构版本。具体而言,cvae 304接收面部表情图像流f
i-1
→i,其中流f包括从第i-1个图像帧至第i个图像帧的图像帧。面部表情图像流f
i-1
→i包括分别来自不同程度l0、l
i-1
至li的面部表情图像至其中,表示具有自然或中性面部表情(例如,以正常或普通的表情状态示出的特定个体的面部表情)的特定个体的标识(identification,id),并且和表示根据先前和当前程度计算出的(即,在先前或当前迭代期间计算出的)面部表情图像。在一个实施例中,面部表情图像是面部疲劳图像。
60.如所展示,cvae 304包括编码器304a和解码器(或生成器)306a。编码器304a接收在不同程度l0、l
i-1
至li处的面部表情图像流f
i-1
→i,并且通过学习分布p(z|x,c)将面部表情图像中的每一个映射到所学表示zi,其中“c”是数据的种类或类别,并且“x”是图像。z=zi+zg。也就是说,将面部表情图像流转换成所学表示zi(例如,特征向量),所述表示可以被认为是编码器304a的输入的压缩表示。在一个实施例中,编码器304a是卷积神经网络(cnn)。
61.如图所示,解码器306a用于使用与所学表示zg(图2)级联的所学表示zi来使编码器304a的输出反转。然后使用级联的所学表示(zi+zg)来生成来自编码器304a的输入的重构版本。输入的这种重构被称为在程度l
i+1
处的重构图像重构图像表示面部表情图像,所述面部表情图像示出了在每次迭代期间针对面部表情流中的每个帧的不同程度的疲劳(例如,困倦、睡意、疲倦等)。
62.gan 306包括发生器(或解码器)306a和鉴别器306b。在一个实施例中,gan 306是cnn。如上文所解释,生成器306a接收级联的所学表示(zi+zg)作为输入,并且输出重构图像gan 306还包括鉴别器306b。耦合鉴别器306b以从生成器306a接收原始内容(例如,)和重构内容(例如,),并且学会区分内容的“真实”样本和“假”样本(即,预测重构内容是真实的还是假的)。这可以通过训练鉴别器306b以减小鉴别器损失loss
gd
来实现,所述鉴别器损失loss
gd
指示通过鉴别器响应于接收原始内容以及由cvae 304生成的重构内容而生成不正确的预测的成本。以这种方式,鉴别器306b的参数用于基于在编码处理期间出现的两个版本之间的差异来区分内容的训练版本和重构版本。例如,鉴别器306b接收在程度l
i+1
处的重构图像(或者如果在初始程度l0处则为自然面部表情图像)和地面真实图像作为输入。为了预测重构图像是真实的还是假的,训练鉴别器306b以使gan 306的损失函数最小化或减少。gan 306的最小化损失函数被定义为min
gan
loss=loss
gd
+loss
ep
,其中loss
gd
表示鉴别器损失,并且loss
ep
表示重构损失。可以使用以下函数来计算loss
gd
:loss
gd
=e[log(d(x))]+e[log(1-d(g(z)))],并且可以使用以下函数来计算其中d()是鉴别器,g()是生成器,e[]是期望值,并且z是所学表示(或代码)。
[0063]
面部疲劳生成网络302使用损失函数来预测重构图像是真实的还是假的,其中针
对真实图像的最小化损失函数的值应小于针对假图像的最小化损失函数的值。在一个实施例中,标签1(真实)分配给原始内容,而标签0(假)则分配给确定为假(非真实)的重构内容。在这种情况下,鉴别器306b可以在相应的鉴别预测低于阈值时预测输入的内容为重构(即,假)版本,并且可以在相应的预测高于阈值时预测输入的内容是真实的(真实图像)。在下一次迭代中,用实际图像取代图像并且用图像取代图像以这种方式,鉴别器306b针对每条输入内容和重构内容输出鉴别预测,所述鉴别预测指示输入内容是原始版本还是重构版本。
[0064]
应了解的是,生成器和/或鉴别器可以包括各种类型的机器学习模型。机器学习模型可以包括线性模型和非线性模型。作为示例,机器学习模型可以包括回归模型、支持向量机、基于决策树的模型、贝叶斯(bayesian)模型和/或神经网络(例如,深度神经网络)。神经网络可以包括前馈神经网络、递归神经网络(例如,长短期记忆递归神经网络)、卷积神经网络或其它形式的神经网络。因此,尽管生成器和鉴别器有时被称为“网络”,但是它们不一定限于神经网络,而是还可以包括其它形式的机器学习模型。
[0065]
图4a展示了视频预测和内插网络。视频预测和内插网络402包括帧内插网络402a和长短期记忆(long short term memory,lstm)自动编码器网络402b。lstm有效地保留运动趋势(模式)并将运动趋势传递到预测帧,而内插网络从较宽的帧生成中间图像。因此,可以在保持运动趋势的同时将帧内插。
[0066]
帧内插网络402a用于从视频内容的原始帧生成新帧。在这样做时,网络以两个连续帧之间定义的时间步长(或时间戳)预测一个或多个中间图像。第一神经网络410近似定义两个连续帧之间的运动的光流数据。第二神经网络412细化光流数据,并且预测每个时间步长的可见度图。根据每个时间步长的细化光流数据,使两个连续的帧翘曲,以产生每个时间步长的成对的翘曲帧。然后,第二神经网络基于可见度图融合所述成对的翘曲帧,以产生每个时间步长的中间图像。在预测的中间图像中,由运动边界和遮挡引起的伪影会减少。
[0067]
在所展示的实施例中公开了帧内插的一个示例。当帧内插网络402a在时间t∈(t-1,t)处具备有诸如图像和的两个输入图像时,可以预测中间(或内插)图像为了执行内插,首先计算两个输入图像之间的双向光流。在一个实施例中,可以利用cnn来计算光流。例如,可以使用两个输入图像和来训练cnn,以联合地预测两个输入图像之间的前向光流f
i-1
→i和后向光流fi→
i-1
(帧之间的光流)。类似地,帧内插网络402a可以接收图像和在所述帧内插网络中,联合地预测输入图像之间的前向光流f
i+1
→i和后向光流fi→
i+1
。如下文中参照图4b更详细的描述,帧内插网络处理输入图像,并且将中间图像输出到
[0068]
内插网络的一个示例描述于“super slomo:用于视频解释的多个中间帧的高质量估计(high quality estimation of multiple intermediate frames for video interpretation)”,jiang等人,《ieee计算机视觉与模式识别会议录》(proceedings of the ieee conference on computer vision and pattern recognition),2018年。
[0069]
lstm自动编码器网络402b学习图像序列的表示。在一个实施例中,lstm自动编码器网络402b使用由lstm单元或存储块形成的递归神经网络(rnns)来进行学习。例如,第一
rnn是将输入图像序列404(例如,图像帧序列)映射为固定长度表示的编码器,然后使用诸如解码器的第二rnn将所述表示解码。lstm自动编码器网络402b中的编码器对诸如图像和的输入图像序列404进行处理,以生成输入图像序列404的表示。
[0070]
在读取最后的输入之后,使用lstm自动编码器网络402b中的解码器对使用输入序列生成的所学表示进行处理。解码器输出针对输入序列的所生成目标序列的预测。目标序列与输入序列的内容相同,顺序相反。在一个实施例中,lstm自动编码器网络402b中的解码器包括一个或多个lstm层,并且用于接收目标序列中的当前输出,以便生成相应的输出评分。给定输出的输出评分表示所述输出是目标序列中的下一输出的可能性,即,预测所述输出是否表示目标序列中的下一输出。作为生成输出评分的一部分,解码器还更新网络的隐藏状态,以生成更新的隐藏状态。下文参照图4c对lstm自动编码器网络402b作出了进一步解释。
[0071]
示例lstm神经网络描述于“使用lstm的视频表示的无监督学习(unsupervised learning of video representations using lstms)”,srivastava等人,多伦多大学,2016年1月。
[0072]
图4b展示了根据图4a的示例性的帧内插网络。帧内插网络402a包括:将翘曲的输入图像融合以生成中间图像的编码器410和解码器412。更具体地说,将两个输入图像和翘曲到特定时间步长t,并且将两个翘曲图像自适应地融合以生成中间图像在一个实施例中,使用流计算cnn来估计两个输入图像之间的双向光流,并且使用流内插cnn来细化流近似并预测可见度图。然后,可以在融合之前将可见度图应用于两个翘曲图像,使内插中间图像中的伪影得以减少。在一个实施例中,流计算cnn和流内插cnn是如在“u-net:用于生物医学图像分割的卷积网络(onvolutional networks for biomedical image segmentation)”,mic-cai,2015年中所描述的u-net架构。
[0073]
在所展示的实施例中,并且对于输入图像和中的每一个,帧内插网络402a包括:流内插网络,其在一个实施例中被实施为编码器410;中间光流网络,其在一个实施例中被实施为解码器412;以及光流翘曲单元(f
t
→i,f
t
→
i+1
)。编码器410接收时间戳(t,t+1)处的序列图像对基于序列图像对计算双向光流计算双向光流针对序列图像对中的两个输入图像之间的至少一个时间步长t,将双向光流线性地组合以近似中间双向光流根据每个时间步长的近似中间双向光流,使每个所述输入图像翘曲(向后),以产生翘曲的输入帧ii→
t
和i
i+1
→
t
。
[0074]
在一个实施例中,解码器412包括:与每个翘曲单元相对应的流细化网络(未示出)以及用于预测时间t∈(i,i+1)处的中间图像i
tn
的图像预测器(未示出)。针对每个时间步长,使用两个输入帧、中间双向光流和两个翘曲输入图像对中间双向光流进行细化。输出细化的中间双向光流(f
t
→i,f
t
→
i+1
)并由图像预测单元进行处理,以产生中间图像在一个实施例中,图像预测单元接收由光流翘曲单元生成的翘曲输入帧i
t
→i和i
t
→
i+1
,并且翘曲输入帧被图像预测单元线性地融合,以产生每个时间步长的中间图像。
[0075]
如上所述,在一个实施例中,将可见度图应用于两个翘曲图像。为了解释遮挡,解
码器412中的流细化网络预测每个时间步长的可见度图v
t
←i和v
t
←
i+1
。由于使用了可见度图,当像素在和中均可见时,解码器412学会自适应地组合来自两个图像的信息。在一个实施例中,在将翘曲图像线性地融合之前,将可见度图应用于翘曲图像,以便产生每个时间步长的中间图像。
[0076]
根据下式合成中间图像至
[0077][0078]
其中是归一化因子,并且根据下式定义内插损失函数:
[0079][0080]
其中u(
·
)是向后翘曲函数,f
t
→i和f
t
→
i+1
是两个输入图像fi→
i+1
和f
i+1
→i之间的中间光流,并且v
t
←i和v
t
←
i+1
是指示像素是否仍然可见的两个可见度图,如“u-net:用于生物医学图像分割的卷积网络”中所述。
[0081]
通过在融合之前将可见度图应用于变形图像,从内插中间图像中排除任何被遮挡的像素的贡献,从而避免或减少了伪影。
[0082]
图4c展示了具有lstm自动编码器的展开视图的图4a的视频预测和内插网络的示例。lstm自动编码器402b的基本构件块是lstm存储单元,由rnn表示。每个lstm存储单元在时间t处均具有状态。为了访问用于读取或修改的存储单元,每个lstm存储块均可以包括一个或多个单元。每个单元包括输入门、遗忘门和输出门,这些门允许单元存储由所述单元生成的先前激活,这些先前激活例如作为用于生成当前激活的隐藏状态或作为要提供给lstm自动编码器402b的其它组件的隐藏状态。如上所述,这些lstm存储块形成在其中进行学习的rnn。
[0083]
在所展示的实施例中,编码器403由多层rnn组成,其中箭头示出信息流的方向。(在每一层中的)每个所述编码器403接收输入图像序列和的单个元素、以及分别由帧内插网络402a-402n生成的相应中间图像至处理输入序列和所述输入序列是由传感器或从数据库收集的图像的集合,并且更新当前隐藏状态,即,通过处理当前接收的输入来修改当前隐藏状态,所述当前隐藏状态是通过处理来自输入序列的先前输入而生成的。然后,可以将相应的权重w1应用于先前隐藏的状态以及输入向量。
[0084]
然后,使用解码器405处理输入序列的所学表示,以生成输入序列的目标序列。解码器405还包括多层rnn,其中箭头示出信息流的方向,其预测时间步长t处的输出。每个rnn接受来自先前元素的隐藏状态,并且产生和输出其自己的隐藏状态。在一个实施例中,使用当前时间步长处的隐藏状态以及相应的权重w2计算输出。可以使用概率向量,例如softmax或其它一些已知函数,来确定最终输出。
[0085]
图5a至5d展示了根据本技术的实施例的示例流程图。在实施例中,流程图可以是至少部分地由展示在各个附图中的并且如本文所描述的硬件和/或软件组件执行的计算机实施的方法。在一个实施例中,可以由公开在图1a和1b中的驾驶员疲劳系统106来执行所公开的流程。在一个实施例中,由诸如处理器108、或处理器802的一个或多个处理器执行的软件组件执行所述流程的至少一部分。
[0086]
图5a展示了假疲劳状态视频数据集的编译的流程图。所述数据集是使用迁移学习技术来生成的,可以用于训练应用程序以识别驾驶员疲劳。在步骤502,诸如ae或cvae的神经网络生成从任意面部图像学习的面部表情图像。在一个实施例中,根据从神经网络学习的任意面部图像的所学表示来重构面部表情图像。然后,可以在疲劳程度生成器网络的训练阶段期间应用所学表示。
[0087]
在步骤504,使用在其中几乎看不到表情的中性、自然或正常面部图像以及表示不同疲劳程度的图像流来训练另一神经网络。使用中性面部图像以及图像流来生成表示当前疲劳程度的图像。当所述处理迭代时,图像流发生变化,使得当前图像成为先前的图像,并且生成新的当前图像。在每次迭代中,基于所学表示,从中性面部图像以及表示当前疲劳程度之前的疲劳程度的图像来生成表示当前疲劳程度的图像。根据在步骤502中所学表示以及从神经网络学习的中性面部图像的第二表示来重构表示当前疲劳程度的图像(或重构图像)。然后,可以将重构图像与地面真实模型进行比较,以确定重构图像是真实的还是假的,正如下文所讨论。
[0088]
在步骤506,生成来自重构面部表情的内插视频数据(序列图像数据)的中间图像以及相应光流期间的任意面部图像。在一个实施例中,光流是通过将重构面部表情与任意面部图像融合而形成的,并且位于所述重构面部表情与任意面部图像之间的时间帧中。
[0089]
在步骤508,至少使用重构面部表情和任意面部图像以及内插视频数据的中间图像来编译驾驶员的假疲劳状态视频(即,数据集),以在其中训练应用程序以检测驾驶员疲劳。
[0090]
参照图5b,展示的是诸如cvae 304的神经网络的示例流程图。在所描绘的实施例中,cvae包括编码器和解码器。在步骤510,对包括程度的面部表情图像以及中性面部图像进行编码,并且输出描述所学表示的每个维度的分布的参数。在步骤512,对所学表示的每个维度的分布进行解码,并且计算每个参数相对于输出损失的关系,以将中性面部图像和面部表情图像重构为重构图像。在步骤514,将重构图像与中性图像进行比较以生成鉴别器损失,并且在步骤516,将重构图像与处于相同程度的地面实况进行比较以生成重构损失。在步骤518,基于鉴别器损失和重构损失,做出关于重构图像具有与中性图像相对应的外观的可能性的预测。在步骤520,将重构图像输出为真实图像,并向后传播到cvae的输入,以进行下一次迭代。
[0091]
在图5c中,在522处,步骤502中的神经网络将任意面部图像映射到相应的所学表示,并且在步骤524,所学表示被映射到与任意面部图像具有相同形状或相同图像尺寸的面部表情图像(例如,重构图像具有与任意图像相同的列数和行数)。
[0092]
继续参照图5d,结合gan 306描述了中间图像的生成。在步骤526,在相应的光流期间预测面部表情图像与任意面部图像之间的中间图像。在步骤528,内插图像以生成相应的光流,以在其中生成驾驶员的假疲劳状态视频。在步骤530,以输入顺序布置中间图像序列,
并且在步骤532,使用编码器处理中间图像序列,以将中间图像序列转换成替代性表示。最后,在步骤534,使用解码器处理中间图像序列的替代性表示,以生成中间图像序列的目标序列,其中所述目标序列包括根据输出顺序布置的多个输出。
[0093]
图6展示了可在其上实施本公开的实施例的计算系统。可以对计算系统600进行编程(例如,通过计算机程序代码或指令),以通过如本文所描述的驾驶员疲劳(疲倦)检测提高驾驶员的安全性,并且所述计算系统包括通信机制,诸如用于在计算机系统600的其它内部组件与外部组件之间传递信息的总线610。在一个实施例中,计算机系统600是图1b中的系统106。计算机系统600或其一部分构成用于执行一个或多个步骤的装置,所述一个或多个步骤用于通过驾驶员分心(包括驾驶员疲劳)检测提高驾驶员的安全性。
[0094]
总线610包括一个或多个并行的信息导体,使得信息在耦合到总线610的设备之间快速地传递。用于处理信息的一个或多个处理器602与总线610耦合。
[0095]
一个或多个处理器602对由计算机程序代码所指定的信息(或数据)执行一组操作,所述信息(或数据)与通过驾驶员分心检测提高驾驶员的安全性有关。计算机程序代码是指令或语句的集合,其为处理器和/或计算机系统的操作提供指令以执行指定功能。例如,所述代码可以用编译成处理器的本机指令集的计算机编程语言来编写。所述代码还可以直接使用本机指令集(例如,机器语言)来编写。所述一组操作包括从总线610引入信息并将信息置于总线610上。由称为指令的信息,诸如一个或多个数字的操作代码,将可以由处理器执行的一组操作中的每个操作表示给处理器。由处理器602执行的操作的序列,诸如操作代码的序列,构成处理器指令,也称为计算机系统指令,或简单地说,计算机指令。
[0096]
计算机系统600还包括耦合到总线610的存储器604。存储器604,诸如随机存取存储器(random access memory,ram)或任何其它动态存储设备,存储包括处理器指令的信息,所述处理器指令用于通过驾驶员分心检测提高驾驶员的安全性。动态存储器允许计算机系统600改变存储在其中的信息。ram允许存储在称为存储地址的位置处的信息单元独立于相邻地址的信息被存储和检索。存储器604还被处理器602用来在执行处理器指令期间存储临时值。计算机系统600还包括只读存储器(read only memory,rom)606或耦合到总线610的用于存储静态信息的任何其它静态存储设备。用于存储信息(包括指令)的非易失性(永久)存储设备608,诸如磁盘、光盘或闪存卡,也耦合到总线610。
[0097]
在一个实施例中,由处理器从外部输入设备612,诸如由人类用户操作的键盘、麦克风、红外(infrared,ir)遥控装置、操纵杆、游戏手柄、手写笔、触摸屏、头戴式显示器或传感器,将包括用于使用由上述系统和实施例处理的信息提高疲倦的驾驶员的安全性的指令的信息提供给总线610以供使用。传感器检测其附近的状况,并将这些检测结果转换成可与用于表示计算机系统600中的信息的可测量现象兼容的物理表达。耦合到总线610的主要用于与人类交互的其它外部设备包括:用于呈现文本或图像的显示设备614;以及指点设备616,诸如鼠标、追踪球、光标方向键、或运动传感器,用于控制呈现在显示器614上的小光标图像的位置以及发出与呈现在显示器614和一个或多个摄像头传感器684上的图形元素相关联的命令,所述一个或多个摄像头传感器用于捕获、记录和存储也可能包含音频记录的一个或多个静止和/或运动图像(例如视频、电影等)。
[0098]
在所展示的实施例中,诸如专用集成电路(application specific integrated circuit,asic)620的专用硬件耦合到总线610。专用硬件用于出于专用目的而足够快地执
行处理器602不执行的操作。
[0099]
计算机系统600还包括耦合到总线610的通信接口670。通信接口670提供耦合到与其自身的处理器一起操作的各种外部设备的单向或双向通信。一般而言,耦合利用与本地网络680连接的网络链路678,其中,各种外部设备,诸如服务器或数据库,可以连接到所述本地网络。可替代地,链路678可以直接连接到互联网服务提供商(internet service provider,isp)684或连接到网络690,诸如互联网。网络链路678可以是有线的或无线的。例如,通信接口670可以是个人计算机上的并行端口或串行端口或通用串行总线(universal serial bus,usb)端口。在一些实施例中,通信接口670是向相应类型的电话线路提供信息通信连接的综合服务数字网络(integrated services digital network,isdn)卡或数字用户线路(digital subscriber line,dsl)卡或电话调制解调器。在一些实施例中,通信接口670是电缆调制解调器,其将总线610上的信号转换成用于在同轴电缆上的通信连接的信号,或者转换成用于在光纤线缆上的通信连接的光信号。作为另一示例,通信接口670可以是局域网(local area network,lan)卡,以向兼容lan,例如以太网,提供数据通信连接。还可以实施无线链路。对于无线链路,通信接口670发送和/或接收携带诸如数字数据的信息流的电信号、声信号、或包括红外信号和光信号的电磁信号。例如,在诸如像蜂窝电话之类的移动电话的无线手持设备中,通信接口670包括被称为无线电收发器的无线电频带电磁发射器和接收器。在某些实施例中,通信接口670使得能够连接到通信网络,以便使用诸如移动电话或平板电脑的移动设备提高疲倦的驾驶员的安全性。
[0100]
网络链路678通常使用传输介质通过一个或多个网络向使用或处理信息的其它设备提供信息。例如,网络链路678可以通过本地网络680向主机计算机682或向由isp操作的设备684提供连接。isp设备684进而通过现在常被称为互联网690的网络的公共全球分组交换通信网络来提供数据通信服务。
[0101]
连接到互联网的被称为服务器主机682的计算机托管响应于在互联网上接收的信息提供服务的处理。例如,服务器主机682托管提供表示视频数据的信息以用于在显示器614处呈现的处理。预期可以将系统600的组件部署在其它计算机系统之内的多种配置中,所述配置例如,主机682和服务器682。
[0102]
本公开的至少一些实施例涉及对用于实施本文描述的一些或全部技术的计算机系统600的使用。根据本公开的一个实施例,这些技术由计算机系统600响应于处理器602执行包含在存储器604中的一个或多个处理器指令中的一个或多个序列来执行。这些指令,也称为计算机指令、软件和程序代码,可以从另一计算机可读介质,诸如存储设备608或网络链路678,读入到存储器604中。执行包含在存储器604中的指令的序列,使处理器602执行本文描述的方法步骤中的一个或多个。
[0103]
应当理解的是,本主题可以以多种不同的形式来体现,并且不应被解释为限于本文中所阐述的实施例。相反,提供这些实施例使得本主题将是彻底和完整的,并且将本公开充分传达给本领域技术人员。实际上,本主题旨在覆盖包括在如由所附权利要求定义的本主题的范围和精神内的这些实施例的替代物、修改和等同物。此外,在本主题的以下详细描述中,阐述了许多具体细节以便提供对本主题的透彻理解。然而,本领域普通技术人员将清楚的是,可以在没有此些具体细节的情况下实践本主题。
[0104]
本文参照根据本公开的实施例的方法、装置(系统)和计算机程序产品的流程图展
示和/或方块图对本公开的各方面进行了描述。将理解的是,流程图展示和/或框图中的每个框以及流程图展示和/或框图中的框的组合可以由计算机程序指令来实施。这些计算机程序指令可以提供给通用计算机、专用计算机、或其它可编程数据处理装置的处理器,以生产机器,使得通过计算机或其它可编程指令执行装置的处理器执行的指令创建用于实施流程图和/或框图的一个或多个框规定的功能/动作的机制。
[0105]
计算机可读非瞬时性介质包括所有类型的计算机可读介质,包括磁存储介质、光存储介质和固态存储介质,并且明确地排除信号。应当理解的是,软件可以安装在设备中并随设备一起出售。可替代地,可以获取软件并将其加载到设备中,包括经由盘介质或从任何形式的网络或分发系统获取软件,包括例如从软件创建者拥有的服务器或从不属于但由软件创建者使用的服务器获取软件。例如,可以将软件存储在服务器上,以便通过互联网进行分发。
[0106]
计算机可读存储介质排除传播的信号本身,可以由计算机和/或处理器访问,并且包括可移动和/或不可移动的易失性和非易失性内部和/或外部介质。对于计算机,各种类型的存储介质都可以以任何合适的数字格式存储数据。本领域技术人员应当了解的是,可以采用其它类型的计算机可读介质,诸如zip驱动器、固态驱动器、磁带、闪存卡、闪存驱动器、磁带盒等,来存储用于执行所公开架构的新颖方法(动作)的计算机可执行指令。
[0107]
本文中使用的术语仅出于描述特定方面的目的,并且不旨在限制本公开。如本文所用,除非上下文另外明确指出,否则单数形式“一个”、“一种”和“所述”也旨在包括复数形式。还将理解的是,术语“包括(comprises)”和/或“包括(comprising)”在本说明书中使用时,指定存在所述特征、整体、步骤、操作、元件和/或组件,但不排除存在或添加一个或多个其它特征、整体、步骤、操作、元素、组件、和/或它们的组。
[0108]
已经出于展示和描述的目的呈现了本公开的描述,但是并不旨在是穷举的或将本公开限于所公开的形式。在不脱离本公开的范围和精神的情况下,许多修改和变化对于本领域普通技术人员将是显而易见的。选择和描述了本文公开的方面,以便最好地解释本公开的原理以及实际应用,并且使得本领域的其他普通技术人员能够理解具有如适于所预期的特定用途的各种修改的本公开。
[0109]
出于本文件的目的,与所公开的技术相关联的每个流程可以由一个或多个计算设备来连续执行。流程中的每个步骤可以由与其它步骤中使用的计算设备相同或不同的计算设备来执行,并且每个步骤不一定必须由单个计算设备执行。
[0110]
尽管已经以特定于结构特征和/或方法动作的语言描述了本主题,但是应该理解的是,所附权利要求书定义的本主题不必限于上文描述的特定特征或动作。相反,上文描述的特定特征和动作是作为实施权利要求的示例形式而公开的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1