信息处理装置、程序以及信息处理方法与流程
1.本发明涉及信息处理装置、程序以及信息处理方法。
背景技术:
2.随着个人计算机和互联网的普及,用户可访问的电子化文档的量增大。为了从这样的大规模的文档中发现期望的文档,要求高效的文档检索技术。
3.在文档检索中,为了用计算机对自然语言的含义进行处理,有用的是将具有含义的字符或字符串的最小单位即令牌(token)用表示其含义的向量来表达。
4.对一个令牌赋予一个向量的方法是主流,但在这样的方法中,对于根据上下文而具有多个含义的令牌,无法消除含义的模糊性。因此,已提出获得能够考虑上下文的令牌的向量的方法。
5.在文档检索中,需要高精度地测量作为检索输入的检索语句即检索查询、与作为检索对象的检索对象语句之间的含义的相似度。为了测量高精度的相似度,有用的是计算检索查询与检索对象语句的令牌间相似度。
6.例如,在非专利文献1中记载有如下的语句间相似度的计算方法:针对检索查询x中包含的各令牌xi,选择检索对象语句yj中包含的各令牌y
jk
中相似度最高的令牌,利用将针对这i个单词的组合计算出的令牌间相似度φ(xi,y
jk
)进行平均而得到的值。
7.现有技术文献
8.非专利文献
9.非专利文献1:梶原智之、小町守共著、「平易
なコーパスを
用
いないテキスト
平易化」、自然言語処理、25(2)、223-249、2018年
技术实现要素:
10.发明要解决的课题
11.在语句间相似度的计算中,需要在检索查询中包含的全部令牌和检索对象语句中包含的全部令牌的全部组合中计算相似度,计算量变得庞大,难以实用化。
12.例如,在对一个令牌赋予一个向量表达的情况下,事先计算令牌间的全部相似度,并将其预先保存在查找表等数据中,由此能够在检索时省略相似度的计算。然而,在使用能够考虑出现上下文的令牌的向量表达的情况下,各令牌的含义依赖于上下文而变化,因此无法事先计算令牌间的相似度。
13.因此,本发明的一个或多个方式的目的在于,减轻文档检索中的相似度的计算负荷。
14.用于解决课题的手段
15.本发明一个方式的信息处理装置的特征在于,具有:检索对象存储部,其存储包含多个检索对象令牌的多个检索对象语句,所述多个检索对象令牌分别是具有含义的最小单位;相似度判定信息存储部,其存储相似度判定信息,所述相似度判定信息表示所述多个检
索对象令牌的各检索对象令牌与检索语句中包含的多个检索令牌的各检索令牌的组合是高相似度还是低相似度,所述多个检索令牌是具有含义的最小单位;以及语句间相似度计算部,其针对在所述相似度判定信息中表示是所述高相似度的组合,计算令牌间相似度,针对在所述相似度判定信息中表示是所述低相似度的组合,将令牌间相似度设为预先确定的值,由此计算所述检索语句与所述多个检索对象语句的各检索对象语句之间的语句间相似度。
16.本发明一个方式的程序的特征在于,使计算机作为以下部分发挥功能:检索对象存储部,其存储包含多个检索对象令牌的多个检索对象语句,所述多个检索对象令牌分别是具有含义的最小单位;相似度判定信息存储部,其存储相似度判定信息,所述相似度判定信息表示所述多个检索对象令牌的各检索对象令牌与检索语句中包含的多个检索令牌的各检索令牌的组合是高相似度还是低相似度,所述多个检索令牌是具有含义的最小单位;以及语句间相似度计算部,其针对在所述相似度判定信息中表示是高相似度的组合,计算令牌间相似度,针对在所述相似度判定信息中表示是低相似度的组合,将令牌间相似度设为预先确定的值,由此计算所述检索语句与所述多个检索对象语句的各检索对象语句之间的语句间相似度。
17.本发明一个方式的信息处理方法计算包含多个检索对象令牌的多个检索对象语句与包含多个检索令牌的检索语句之间的多个语句间相似度,所述多个检索对象令牌分别是具有含义的最小单位,所述多个检索令牌是具有含义的最小单位,该信息处理方法的特征在于,受理所述检索语句的输入,针对在相似度判定信息中表示是高相似度的组合,计算令牌间相似度,针对在所述相似度判定信息中表示是低相似度的组合,将令牌间相似度设为预先确定的值,由此计算所述检索语句与所述多个检索对象语句的各检索对象语句之间的语句间相似度,所述相似度判定信息表示所述多个检索对象令牌的各检索对象令牌与所述多个检索令牌的各检索令牌的组合是高相似度还是低相似度。
18.发明效果
19.根据本发明的一个或多个方式,能够减轻文档检索中的相似度的计算负荷。
附图说明
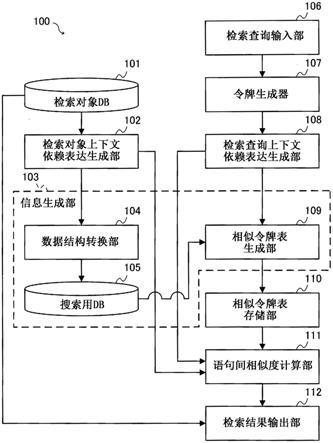
20.图1是概略地表示作为实施方式1的信息处理装置的文档检索装置的结构的框图。
21.图2是表示检索对象令牌排列的例子的概略图。
22.图3是表示检索对象上下文依赖表达排列的例子的概略图。
23.图4是表示检索查询令牌排列的例子的概略图。
24.图5是表示检索查询上下文依赖表达排列的例子的概略图。
25.图6是表示相似令牌表的例子的概略图。
26.图7是概略地表示用于实现文档检索装置的硬件结构的框图。
27.图8是表示实施方式1的检索对象上下文依赖表达生成部中的处理的流程图。
28.图9是表示数据结构转换部中的处理的流程图。
29.图10是表示令牌生成器(tokenizer)中的处理的流程图。
30.图11是表示检索查询上下文依赖表达生成部中的处理的流程图。
31.图12是表示相似令牌表生成部中的处理的流程图。
32.图13是表示语句间相似度计算部中的处理的流程图。
33.图14是表示检索结果输出部中的处理的流程图。
34.图15是概略地表示作为实施方式2的信息处理装置的文档检索装置的结构的框图。
35.图16是表示实施方式2的检索对象上下文依赖表达生成部中的处理的流程图。
36.图17是概略地表示作为实施方式3的信息处理装置的文档检索装置的结构的框图。
37.图18是表示检索对象维度削减部中的处理的流程图。
38.图19是表示检索查询维度削减部中的处理的流程图。
具体实施方式
39.实施方式1
40.图1是概略地表示作为实施方式1的信息处理装置的文档检索装置100的结构的框图。
41.文本检索装置100具有检索对象数据库(以下称作检索对象db)101、检索对象上下文依赖表达生成部102、信息生成部103、检索查询输入部106、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表存储部110、语句间相似度计算部111以及检索结果输出部112。
42.此外,信息生成部103具有数据结构转换部104、搜索用数据库(以下称作搜索用db)105以及相似令牌表生成部109。
43.检索对象db 101是存储检索对象语句以及与检索对象语句对应的检索对象令牌排列的检索对象存储部。检索对象令牌排列是排列多个令牌而成的,设由一个检索对象令牌排列构成一个语句。另外,令牌是具有含义的最小单位,并且是字符或字符串。此外,检索对象令牌排列中包含的令牌也被称作检索对象令牌。并且,设在检索对象db 101中保存有多个检索对象语句以及与多个检索对象语句对应的多个检索对象令牌排列。
44.以下,作为例子,考虑检索与某个检索查询对应的条文的文档检索任务。具体而言,针对检索查询“夏天的休假是从何时到何时?”,考虑从多个条文中检索对应的条文“休息日如下。夏季休息日
……”
的任务。在此,多个条文成为多个检索对象语句。
45.在该情况下,检索对象令牌排列也可以是图2所示的二维排列形式。在图2所示的检索对象令牌排列的例子中,在第p行保存有第p条的条文,在第p行第q列中保存有第p条的条文的从开头起第q个检索对象令牌。在此,在图2中,检索对象令牌是由
“”
包围的字符或字符串。
46.检索对象上下文依赖表达生成部102从检索对象db 101取得检索对象令牌排列。然后,检索对象上下文依赖表达生成部102生成对取得的检索对象令牌排列中包含的全部检索对象令牌的上下文依赖表达(即检索对象上下文依赖表达)进行排列而得到的检索对象上下文依赖表达排列。生成的检索对象上下文依赖表达排列被提供给数据结构转换部104和语句间相似度计算部111。在此,上下文依赖表达是向量,检索对象上下文依赖表达是检索对象向量。
47.例如,检索对象上下文依赖表达生成部102是生成与检索对象令牌排列中包含的
检索对象令牌的含义对应的向量即检索对象向量的检索对象向量生成部。在此,检索对象上下文依赖表达生成部102根据与包含检索对象令牌的检索对象令牌排列对应的检索对象语句的上下文,确定检索对象令牌的含义,并以表示确定的含义的方式生成检索对象向量。
48.具体而言,检索对象上下文依赖表达生成部102分别针对检索对象令牌排列中包含的多个检索对象令牌,确定与上下文对应的含义。并且,检索对象上下文依赖表达生成部102通过按照多个检索对象令牌各自的排列来排列表示确定的含义的多维向量,能够生成检索对象上下文依赖表达排列。
49.检索对象上下文依赖表达排列例如也可以是图3所示的二维排列形式。在图3所示的检索对象上下文依赖表达排列中,在第p行保存有第p条的条文,在第p行第q列中保存有第p条的条文的与从开头起第q个检索对象令牌对应的作为上下文依赖表达的向量。
50.另外,关于确定与检索对象令牌对应的上下文依赖表达的方法,使用公知的方法即可。例如,关于能够考虑出现上下文的令牌的向量表达的获得方法,例如记载在下述的文献中。
51.jacobdevlin,ming-wei chang,kenton lee,and kristina toutanova,“bert:pre-training of deep bidirectional transformers for language understanding”,corr,abs/1810.04805,may 24,2018
52.数据结构转换部104从检索对象上下文依赖表达生成部102取得检索对象上下文依赖表达排列。然后,数据结构转换部104将取得的检索对象上下文依赖表达排列转换成搜索用数据结构。生成的搜索用数据结构被存储在搜索用db 105中。
53.搜索用数据结构根据使用的k近似最近邻搜索算法,从任意的公知数据结构中选择即可。例如,在利用ann(approximate nearest neighbor search:近似最近邻搜索)作为k近似最近邻搜索算法的情况下,选择k-d树的数据结构即可。此外,在利用lsh(locality sensitive hashing:局部敏感哈希)作为k近似最近邻搜索算法的情况下,选择基于哈希函数的映射结果作为数据结构即可。在此,说明利用ann作为k近似最近邻搜索算法并将k-d树的数据结构作为搜索用数据结构的例子。
54.另外,这些算法在下述文献中已有说明。
55.和田俊和著、「最近傍探索
の
理論
とアルゴリズム
」、研究報告
コンピュータビジョンとイメージメディア
、no.13、2009年
56.搜索用db 105存储由数据结构转换部104转换后的搜索用数据结构。
57.检索查询输入部106是受理作为检索语句的检索查询的输入的检索输入部。检索查询包含多个令牌。检索查询中包含的令牌也被称作检索令牌。
58.例如,检索查询输入部106将“夏天的休假是从何时到何时?”这样的提问句作为检索查询来受理输入。
59.令牌生成器107从检索查询输入部106取得检索查询。然后,令牌生成器107是令牌确定部,其从取得的检索查询中确定检索查询令牌,生成对检索查询令牌进行排列而得到的检索查询令牌排列。生成的检索查询排列被提供给检索查询上下文依赖表达生成部108。另外,检索查询令牌排列中包含的令牌也被称作检索查询令牌。
60.例如,令牌生成器107使用语素分析等任意的公知技术,从检索查询中确定作为具有含义的最小单位的令牌,通过排列确定的令牌来生成检索查询令牌排列。
61.图4是表示检索查询令牌排列的例子的概略图。
62.在图4所示的例子中,在检索查询令牌排列的第r个中保存有检索查询的第r个令牌。
63.检索查询上下文依赖表达生成部108从令牌生成器107取得检索查询令牌排列。然后,检索查询上下文依赖表达生成部108生成对检索查询上下文依赖表达进行排列而得到的检索查询上下文依赖表达排列,该检索查询上下文依赖表达是针对取得的检索查询令牌排列中包含的全部令牌即检索查询令牌的上下文依赖表达。生成的检索查询上下文依存表达排列被提供给相似令牌表生成部109和语句间相似度计算部111。在此,检索查询上下文依赖表达是检索向量。
64.例如,检索查询上下文依赖表达生成部108是生成与检索令牌的含义对应的向量即检索向量的检索向量生成部。在此,检索查询上下文依赖表达生成部108根据检索语句的上下文来确定检索令牌的含义,并以表示确定的含义的方式生成检索向量。
65.具体而言,检索查询上下文依赖表达生成部108分别针对检索查询令牌排列中包含的多个检索查询令牌,确定与上下文对应的含义。然后,检索查询上下文依赖表达生成部108通过按照多个检索查询令牌各自的排列对表示确定的含义的多维向量进行排列,能够生成检索查询上下文依赖表达排列。另外,关于确定与检索查询令牌对应的上下文依赖表达的方法,与上述的检索对象上下文依赖表达同样地,使用公知的方法即可。
66.图5是表示检索查询上下文依赖表达排列的例子的概略图。
67.在图5所示的例子中,在检索查询上下文依赖表达排列的第r个保存有与检索查询的第r个令牌对应的作为上下文依赖表达的向量。
68.相似令牌表生成部109从检索查询上下文依赖表达生成部108取得检索查询上下文依赖表达排列,从搜索用db 105取得搜索用数据结构。然后,相似令牌表生成部109根据取得的检索查询上下文依赖表达排列和搜索用数据结构,按照检索对象令牌和检索查询令牌的每个组合,生成作为表示相似度相对较高还是相对较低的相似度判定信息的相似令牌表。生成的相似令牌表被存储到相似令牌表存储部110。
69.例如,相似令牌表生成部109对检索对象令牌和检索查询令牌的全部组合计算相似度,使用计算出的相似度,通过比判定相似度是否相对较高的蛮力搜索(brute-force search)更高效的公知的搜索方法,对检索对象令牌和检索查询令牌的全部组合判定相似度相对较高还是相对较低即可。例如,相似令牌表生成部109使用检索k个(k为1以上的整数)附近点的k近似最近邻搜索,针对某个检索查询令牌检索相似度相对较高的k个检索对象令牌即可。然后,相似令牌表生成部109将搜索到的k个检索对象令牌设为相似度相对较高的令牌,将剩余的检索对象令牌设为相似度相对较低的令牌即可。另外,k近似最近邻搜索算法使用ann或lsh这样的公知技术即可。
70.图6是表示相似令牌表的例子的概略图。
71.图6所示的例子是查找表,在输入了上述的检索查询“夏天的休假是
…”
时,该查找表针对该检索查询中包含的各令牌,表示全部的检索对象语句中包含的各令牌的相似度在全部的检索对象语句中相对较高或者较低。
72.在图6所示的例子中,行表示检索查询令牌,列表示检索对象令牌。“〇”表示相似度相对较高,
“×”
表示相似度相对较低。例如,在检索查询令牌“夏天的”中,检索对象令牌“休息日”和“夏季”的相似度在全部检索对象语句中包含的令牌中相对较高。
73.在此,在相似令牌表的生成中,能够应用k近似最近邻搜索算法,因此具有能够减少计算量的优点。
74.另外,在图6中,为了容易说明,在行中保存有检索查询令牌,在列中保存有检索对象令牌,在此,在行中保存有与检索查询令牌对应的检索上下文依赖表达(即检索向量),在列中保存有与检索对象令牌对应的检索对象上下文依赖表达(即检索对象向量)。
75.如上所述,数据结构转换部104、搜索用db 105和相似令牌表生成部109构成信息生成部103,该信息生成部103生成作为相似度判定信息的相似令牌表。
76.信息生成部103从由多个检索对象向量表示的多个点中,搜索位于由多个检索向量内的一个检索向量表示的点附近的一个或多个附近点,由此将与由该一个检索向量表示的点对应的一个检索令牌和与该一个或多个附近点对应的一个或多个检索对象令牌的一个或多个组合判定为高相似度,将该一个检索令牌和与该一个或多个附近点以外的一个或多个点对应的一个或多个检索对象令牌的一个或多个组合判定为低相似度,由此生成相似令牌表。在此,信息生成部103使用比计算与一个检索向量对应的点和与多个检索对象向量对应的多个点之间的全部距离的蛮力搜索更高效的搜索方法,搜索一个或多个附近点。
77.相似令牌表存储部110是存储作为相似度判定信息的相似令牌表的相似度判定信息存储部。
78.相似令牌表表示多个检索对象令牌的各检索对象令牌与多个检索令牌的各检索令牌的组合是高相似度还是低相似度。
79.语句间相似度计算部111从相似令牌表存储部110取得相似令牌表,从检索对象上下文依赖表达生成部102取得检索对象上下文依赖表达排列,从检索查询上下文依赖表达生成部108取得检索查询上下文依赖表达排列。然后,语句间相似度计算部111根据取得的相似令牌表、检索对象上下文依赖表达排列和检索查询上下文依赖表达排列,计算检索查询与检索对象语句之间的相似度即语句间相似度。计算出的语句间相似度被提供给检索结果输出部112。
80.这里,语句间相似度计算部111针对在相似令牌表中表示是高相似度的组合,计算令牌间相似度,针对在相似令牌表中表示是低相似度的组合,将令牌间相似度设为预先确定的值,由此减轻计算语句间相似度时的计算负荷。另外,语句间相似度计算部111在计算令牌间相似度时,由多个检索对象向量内的一个检索对象向量表示的点和由多个检索向量内的一个检索向量表示的点之间的距离越短,则使得该一个检索对象向量与一个检索向量的组合的令牌间相似度越高。然后,语句间相似度计算部111分别针对多个检索令牌,确定与多个检索对象语句内的一个检索对象语句中包含的多个检索对象令牌的各检索对象令牌之间的组合中的令牌间相似度的最大值,根据确定的最大值的平均值,计算检索语句与该一个检索对象语句之间的语句间相似度。
81.以下,对语句间相似度的计算进行说明。
82.在语句间相似度的计算中,使用任意的令牌间相似度来计算语句间相似度即可。例如,使用上述的非专利文献1记载的maximum alignment(最大对齐)方式,计算语句间相似度即可。
83.在此,首先说明基于通常的maximum alignment方式的语句间相似度的计算,然
后,说明实施方式1中的高速化的语句间相似度的计算。
84.在基于通常的maximum alignment方式的语句间相似度的计算中,针对检索查询x中包含的各检索查询令牌xi,在检索对象语句yj中包含的各检索对象令牌y
jk
中,选择令牌间相似度最高的令牌。然后,通过对在选择出的i=|x|个检索对象令牌中计算出的令牌间相似度φ(xi,y
jk
)进行平均而得到的值来计算语句间相似度。
85.在将检索查询x和第j个检索对象语句yj的语句间相似度设为s(x,yj)时,以上的基于maximum alignment方式的语句间相似度的计算如下述的(1)式那样公式化。
[0086][0087]
这里,xi表示检索查询x的第i个检索查询令牌,y
jk
表示检索对象语句yj的第k个检索对象令牌,φ(xi,y
jk
)表示检索查询令牌xi与检索对象令牌y
jk
之间的令牌间相似度。对于令牌间相似度,使用检索查询令牌的向量与检索对象令牌的向量之间的距离(例如,上下文依赖表达的余弦相似度)等。
[0088]
在maximum alignment方式中,通过以上的思路,计算检索查询和各检索对象语句的语句间相似度。
[0089]
这相当于如下述的(2)式所示,求出检索查询与全部检索对象语句之间的语句间相似度s并生成检索查询与各检索对象语句的语句间相似度s(x,y)。
[0090][0091]
在此,s(x,y)的第j个元素是检索查询x与检索对象语句yj之间的语句间相似度。
[0092]
接着,进行上述maximum alignment方式的式子变形。
[0093]
现在,用下述的(3)式定义由检索查询令牌xi和全部检索对象令牌构成的相似度矩阵a(i)。
[0094][0095]
在此,相似度矩阵a(i)是由下述的(4)式表示的类型的矩阵。
[0096][0097]
另外,|y|是全部的检索对象语句的数量,|yj|是第j个检索对象语句中包含的检索对象令牌的数量。
[0098]
另外,对于满足下述的(5)式的行l,由于不存在与第|y
l
|+1行之后对应的检索对象令牌,因此无法计算令牌间相似度φ。因此,也可以进行用0填充该令牌间相似度的零填充(zero-padding)处理。
[0099]
[0100]
然后,如下述的(6)式所示定义相似度的最大值max。
[0101][0102]
在该情况下,检索查询与各检索对象语句的语句间相似度s(x,y)能够如下述的(7)式那样变形。
[0103][0104]
如(7)式所示,为了求出检索查询x与各检索对象语句y的语句间相似度s(x,y),需要求出相似度矩阵a(i)。
[0105]
然而,用于求出相似度矩阵a(i)的计算量是o(|x|σj|yj|)。因此,在检索对象语句为大规模的情况下,σj|yj|的计算量庞大,存在不是实用的计算量的问题。
[0106]
因此,实施方式1中的语句间相似度计算部111使语句间相似度的计算高速化。
[0107]
在高速化前的maximum alignment方式中,按照每个检索对象语句,相对地比较检索查询令牌和其全部检索对象令牌之间的令牌间相似度的值,并取得其最大值,由此如上述的(6)式所示,得到检索查询令牌xi与检索对象语句yj的令牌间相似度的最大值max。
[0108]
然而,在文档检索任务中,在检索对象语句中的令牌间相似度的值相对较高,但是全部检索对象语句中相对较低的情况下,该令牌间相似度对文档间相似度造成影响的可能性较小。
[0109]
因此,语句间相似度计算部111在令牌间相似度在全部检索对象语句中相对较低时,省略该令牌间相似度的计算(例如近似为0),由此使文档间相似度的计算高速化。
[0110]
具体而言,语句间相似度计算部111如下述的(8)式所示对相似度矩阵a(i)进行近似。
[0111][0112]
其中,γ(xi,y
jk
)由下述的(9)式确定。
[0113][0114]
这里,simset(xi)是返回相似令牌表的某个检索查询令牌xi的行中包含的栏的值为
“○”
的检索对象令牌y
jk
的集合的函数。
[0115]
例如,在图6所示的例子中,在检索查询令牌“夏天的”的行中,通过simset(xi)返回检索对象令牌“休息日”和“夏季”。
[0116]
检索结果输出部112从语句间相似度计算部111取得语句间相似度,从检索对象db 101取得检索对象语句。然后,检索结果输出部112按照语句间相似度对检索对象语句进行排序,输出排序后的检索对象语句作为检索结果。
[0117]
在此,关于排序,只要选择语句间相似度的升序或降序等任意的排序方法即可。
[0118]
图7是概略地表示用于实现文档检索装置100的硬件结构的框图。
[0119]
如图7所示,文档检索装置100能够通过具有存储器191、处理器192、辅助存储装置193、鼠标194、键盘195以及显示装置196的计算机190来实现。
[0120]
具体而言,以上所述的检索对象上下文依赖表达生成部102、数据结构转换部104、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表生成部109、语句间相似度计算部111以及检索结果输出部112的一部分或者全部能够由存储器191和执行存储器191中保存的程序的cpu(central processing unit:中央处理单元)等处理器192构成。这样的程序可以通过网络来提供,另外,也可以记录在记录介质中来提供。即,这样的程序例如也可以作为程序产品来提供。
[0121]
另外,检索对象db 101、搜索用db 105以及相似令牌表存储部110能够通过处理器192利用辅助存储装置193来实现。但是,辅助存储装置193不一定需要存在于文档检索装置100内,也可以经由未图示的通信接口利用存在于云上的辅助存储装置。另外,相似令牌表存储部110也可以通过存储器191来实现。
[0122]
检索查询输入部106能够通过处理器192利用作为输入装置的鼠标194和键盘195以及显示装置196来实现。此外,鼠标194和键盘195作为输入部发挥功能,显示装置196作为显示部发挥功能。
[0123]
图8是表示检索对象上下文依赖表达生成部102中的处理的流程图。
[0124]
首先,检索对象上下文依赖表达生成部102从检索对象db 101取得检索对象令牌排列(s10)。
[0125]
接着,检索对象上下文依赖表达生成部102根据上下文来确定取得的检索对象令牌排列中包含的全部检索对象令牌各自的含义,按照取得的检索对象令牌排列对表示确定的含义的检索对象上下文依赖表达(即检索对象向量)进行排列,由此生成检索对象上下文依赖表达排列(s11)。
[0126]
接着,检索对象上下文依赖表达生成部102将生成的检索对象上下文依赖表达排
列提供给数据结构转换部104和语句间相似度计算部111(s12)。
[0127]
图9是表示数据结构转换部104中的处理的流程图。
[0128]
首先,数据结构转换部104从检索对象上下文依赖表达生成部102取得检索对象上下文依赖表达排列(s20)。
[0129]
接着,数据结构转换部104将取得的检索对象上下文依赖表达排列转换成搜索用数据结构,该搜索用数据结构用于通过比蛮力搜索更高效的搜索方法来搜索相对于检索查询令牌具有相对较高的相似度的检索对象令牌(s21)。
[0130]
接着,数据结构转换部104将转换后的搜索用数据结构提供给搜索用db 105(s22)。此外,搜索用db 105存储提供的搜索用数据结构。
[0131]
图10是表示令牌生成器107中的处理的流程图。
[0132]
令牌生成器107从检索查询输入部106取得检索查询(s30)。
[0133]
接着,令牌生成器107从取得的检索查询中,确定作为具有含义的最小单位的检索查询令牌,按照检索查询对确定的检索查询令牌进行排列,由此生成检索查询令牌排列(s31)。
[0134]
接着,令牌生成器107将生成的检索查询令牌排列提供给检索查询上下文依赖表达生成部108(s32)。
[0135]
图11是表示检索查询上下文依赖表达生成部108中的处理的流程图。
[0136]
首先,检索查询上下文依赖表达生成部108从令牌生成器107取得检索查询令牌排列(s40)。
[0137]
接着,检索查询上下文依赖表达生成部108根据上下文确定取得的检索查询令牌排列中包含的全部检索查询令牌各自的含义,按照取得的检索查询令牌排列对作为表示确定的含义的上下文依赖表达(以下也称作检索查询上下文依赖表达)的向量(以下也称作检索查询向量)进行排列,由此生成检索查询上下文依赖表达排列(s41)。
[0138]
接着,检索查询上下文依赖表达生成部108将生成的检索查询上下文依赖表达排列提供给相似令牌表生成部109和语句间相似度计算部111(s42)。
[0139]
图12是表示相似令牌表生成部109中的处理的流程图。
[0140]
首先,相似令牌表生成部109从检索查询上下文依赖表达生成部108取得检索查询上下文依赖表达排列(s50)。
[0141]
此外,相似令牌表生成部109从搜索用db 105取得搜索用数据结构(s51)。
[0142]
接着,相似令牌表生成部109在搜索用数据结构中,使用比蛮力搜索更高效的搜索方法,分别针对检索查询上下文依赖表达排列中包含的全部检索查询上下文依赖表达,从全部检索对象上下文依赖表达中搜索相似度相对较高的检索对象上下文依赖表达,由此生成表示检索查询上下文依赖表达各自与检索对象上下文依赖表达各自的相似度是高还是低的相似令牌表(s52)。
[0143]
接着,相似令牌表生成部109将生成的相似令牌表提供给相似令牌表存储部110(s53)而使其存储。
[0144]
图13是表示语句间相似度计算部111中的处理的流程图。
[0145]
首先,语句间相似度计算部111从相似令牌表存储部110取得相似令牌表(s60)。
[0146]
另外,语句间相似度计算部111从检索查询上下文依赖表达生成部108取得检索查
询上下文依赖表达排列(s61)。
[0147]
进而,语句间相似度计算部111从检索对象上下文依赖表达生成部102取得检索对象上下文依赖表达排列(s62)。
[0148]
接着,语句间相似度计算部111通过参照相似令牌表,针对被判定为相似度高的检索查询令牌与检索对象令牌的组合,计算令牌间相似度,针对被判定为相似度低的组合,设为预先确定的值(例如0),由此计算检索对象语句与检索查询之间的语句间相似度(s63)。
[0149]
接着,语句间相似度计算部111将计算出的语句间相似度提供给检索结果输出部112(s64)。
[0150]
图14是表示检索结果输出部112中的处理的流程图。
[0151]
首先,检索结果输出部112从语句间相似度计算部111取得语句间相似度(s70)。
[0152]
接着,检索结果输出部112按照取得的语句间相似度,对检索对象语句进行排序,由此生成至少能够确定语句间相似度最高的检索对象语句的检索结果(s71)。另外,检索结果输出部112从检索对象db 101取得检索对象语句即可。
[0153]
接着,检索结果输出部112将生成的检索结果显示在例如图7所示的显示装置196,由此输出该检索结果(s72)。
[0154]
如上所述,在实施方式1中,在计算语句间相似度时,能够将被判定为相似度不高的令牌彼此的令牌间相似度设为预先确定的值,因此能够减轻语句间相似度的计算负荷。
[0155]
实施方式2
[0156]
图15是概略地表示作为实施方式2的信息处理装置的文档检索装置200的结构的框图。
[0157]
文本检索装置200具有检索对象db 101、检索对象上下文依赖表达生成部202、信息生成部103、检索查询输入部106、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表存储部110、语句间相似度计算部111、检索结果输出部112以及本体(ontology)db 213。
[0158]
实施方式2中的检索对象db 101、信息生成部103、检索查询输入部106、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表生成部109、相似令牌表存储部110、语句间相似度计算部111以及检索结果输出部112与实施方式1中的检索对象db 101、信息生成部103、检索查询输入部106、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表生成部109、相似令牌表存储部110、语句间相似度计算部111以及检索结果输出部112相同。
[0159]
本体db 213是存储本体的含义关系信息存储部,本体是表示令牌的含义关系的含义关系信息。在实施方式2中,本体将令牌的同义关系和包含关系中的至少任意一方表示为含义关系。
[0160]
此外,本体db 213例如能够通过图7所示的处理器192利用辅助存储装置193来实现。
[0161]
检索对象上下文依赖表达生成部202从检索对象db 101取得检索对象令牌排列。然后,检索对象上下文依赖表达生成部202通过参照本体db 213中存储的本体,将取得的检索对象令牌排列中包含的检索对象令牌分组成能够作为相同含义来处理的组。例如,检索对象上下文依赖表达生成部202将表示在本体中处于同义关系或包含关系的检索对象令牌
作为一个组。具体而言,“休假”和“休息日”由于均为“假期”的含义,换言之,由于处于同义关系,因此,检索对象上下文依赖表达生成部202将它们设为一个组。
[0162]
然后,检索对象上下文依赖表达生成部202对一个组分配一个检索对象上下文依赖表达,生成检索对象上下文依赖表达排列。换言之,检索对象上下文依赖表达生成部202根据确定的含义具有同义关系或包含关系的多个检索对象令牌,生成作为相同的检索对象上下文依赖表达的检索对象向量。例如,检索对象上下文依赖表达生成部202可以将一个组中包含的检索对象令牌中的任意一个检索对象上下文依赖表达作为该组的检索对象上下文依赖表达,也可以将一个组中包含的检索对象令牌的检索对象上下文依赖表达的代表值(例如平均值)作为该组的检索对象上下文依赖表达。
[0163]
图16是表示实施方式2的检索对象上下文依赖表达生成部202中的处理的流程图。
[0164]
首先,检索对象上下文依赖表达生成部202从检索对象db 101取得检索对象令牌排列(s80)。
[0165]
另外,检索对象上下文依赖表达生成部202从本体db 213取得本体(s81)。
[0166]
接着,检索对象上下文依赖表达生成部202根据上下文确定取得的检索对象令牌排列中包含的全部检索对象令牌各自的含义,参照取得的本体,使用确定的含义进行分组,对属于组的检索对象令牌分配一个检索对象上下文依赖表达,对不属于组的检索对象令牌分配针对确定的含义的检索对象上下文依赖表达,由此生成检索对象上下文依赖表达排列(s82)。
[0167]
接着,检索对象上下文依赖表达生成部202将生成的检索对象上下文依赖表达排列提供给数据结构转换部104和语句间相似度计算部111(s83)。
[0168]
如上所述,根据实施方式2,通过将检索对象令牌分组,在相似令牌表生成部109中,判断检索查询令牌与检索对象令牌的相似度是否高的对象数减少,因此能够减轻相似令牌表生成部109中的处理负荷。
[0169]
实施方式3
[0170]
图17是概略地表示作为实施方式3的信息处理装置的文档检索装置300的结构的框图。
[0171]
文本检索装置300具有检索对象db 101、检索对象上下文依赖表达生成部202、信息生成部103、检索查询输入部106、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表存储部110、语句间相似度计算部111、检索结果输出部112、本体db 213、检索对象维度削减部314以及检索查询维度削减部315。
[0172]
实施方式3中的检索对象db 101、信息生成部103、检索查询输入部106、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表生成部109、相似令牌表存储部110、语句间相似度计算部111以及检索结果输出部112与实施方式1中的检索对象db 101、信息生成部103、检索查询输入部106、令牌生成器107、检索查询上下文依赖表达生成部108、相似令牌表生成部109、相似令牌表存储部110、语句间相似度计算部111以及检索结果输出部112相同。
[0173]
但是,实施方式3中的检索查询上下文依赖表达生成部108向检索查询维度削减部315和语句间相似度计算部111提供检索查询上下文依赖表达排列。
[0174]
另外,实施方式3中的检索对象上下文依赖表达生成部202和本体db 213与实施方
式2中的检索对象上下文依赖表达生成部202和本体db 213相同。
[0175]
但是,实施方式3中的检索对象上下文依赖表达生成部202向检索对象维度削减部314和语句间相似度计算部111提供检索对象依赖表达排列。
[0176]
检索对象维度削减部314从检索对象上下文依赖表达生成部202取得检索对象上下文依赖表达排列。然后,检索对象维度削减部314通过进行取得的检索对象上下文依赖表达排列中包含的全部检索对象上下文依赖表达的维度压缩,生成削减该维度后的低维度检索对象上下文依赖表达(即低维度检索对象向量),对该低维度检索对象上下文依赖表达进行排列,生成削减维度后的低维度检索对象上下文依赖表达排列。检索对象维度削减部314将生成的低维度检索对象上下文依赖表达排列提供给数据结构转换部104。另外,维度的压缩使用主成分分析等任意的公知技术即可。
[0177]
另外,实施方式3中的数据结构转换部104将低维度检索对象上下文依赖表达排列转换成搜索数据结构。转换的方法与实施方式1相同。
[0178]
检索查询维度削减部315从检索查询上下文依赖表达生成部108取得检索查询上下文依赖表达排列。并且,检索查询维度削减部315是如下的检索维度削减部:通过进行取得的检索查询上下文依赖表达排列中包含的全部检索查询上下文依赖表达的维度压缩,生成削减该维度后的低维度检索查询上下文依赖表达(即低维度检索向量),对该低维度检索查询上下文依赖表达进行排列,生成削减维度后的低维度检索查询上下文依赖表达排列。检索查询维度削减部315将生成的低维度检索查询上下文依赖表达排列提供给相似令牌表生成部109。另外,维度的压缩使用主成分分析等任意的公知技术即可。
[0179]
另外,相似令牌表生成部109使用从检索查询维度削减部315取得的低维度检索查询上下文依赖表达排列和从搜索用db 105取得的搜索用数据结构,生成相似令牌表。另外,生成方法与实施方式1相同。
[0180]
如上所述,在实施方式3中,信息生成部103使用由检索对象维度削减部314生成的低维度检索对象上下文依赖表达排列和低维度检索查询上下文依赖表达排列,生成相似令牌表。
[0181]
具体而言,信息生成部103通过从由多个低维度检索对象向量表示的多个点中搜索位于由多个低维度检索向量内的一个低维度检索向量表示的点附近的一个或多个点(即一个或多个附近点),将与由该一个低维度检索向量表示的点对应的一个检索令牌和与该一个或多个附近点对应的一个或多个检索对象令牌的一个或多个组合判定为高相似度,将该一个检索令牌和与该一个或多个附近点以外的一个或多个点对应的一个或多个检索对象令牌的一个或多个组合判定为低相似度,由此生成相似令牌表。在此,信息生成部103使用比计算与一个低维度检索向量对应的点和与多个低维度检索对象向量对应的多个点之间的全部距离的蛮力搜索更高效的搜索方法,搜索一个或多个附近点。
[0182]
以上所述的检索对象维度削减部314和检索查询维度削减部315的一部分或者全部能够由图7所示的存储器191和执行存储器191中存储的程序的处理器192构成。
[0183]
图18是表示检索对象维度削减部314中的处理的流程图。
[0184]
首先,检索对象维度削减部314从检索对象上下文依赖表达生成部202取得检索对象上下文依赖表达排列(s90)。
[0185]
接着,检索对象维度削减部314通过削减取得的检索对象上下文依赖表达排列中
包含的全部检索对象上下文依赖表达的维度,生成低维度检索对象上下文依赖表达排列(s91)。
[0186]
接着,检索对象维度削减部314将低维度检索对象上下文依赖表达排列提供给数据结构转换部104(s92)。
[0187]
图19是表示检索查询维度削减部315中的处理的流程图。
[0188]
首先,检索查询维度削减部315从检索查询上下文依赖表达生成部108取得检索查询上下文依赖表达排列(s100)。
[0189]
接着,检索查询维度削减部315通过削减取得的检索查询上下文依赖表达排列中包含的全部检索查询上下文依赖表达的维度,生成低维度检索查询上下文依赖表达排列(s101)。
[0190]
接着,检索查询维度削减部315将低维度检索查询上下文依赖表达排列提供给相似令牌表生成部109(s102)。
[0191]
如上所述,根据实施方式3,即使在检索对象上下文依赖表达和检索查询上下文依赖表达的维度较高的情况下,通过削减该维度,也能够减轻相似令牌表生成部109中的处理负荷。
[0192]
在以上所述的实施方式1~3中,在检索对象db 101中存储有多个检索对象语句和与该多个检索对象语句对应的多个检索对象令牌排列,但实施方式1~3并不限定于这样的例子。例如,也可以是,检索对象db 101存储多个检索对象语句,检索对象上下文依赖表达生成部102使用公知的技术生成对应的多个检索对象令牌排列。
[0193]
此外,在以上所述的实施方式1~3中,令牌生成器107生成检索查询令牌排列,但实施方式1~3不限于这样的例子。例如,检索查询上下文依赖表达生成部108也可以根据检索查询,使用公知的技术生成检索查询令牌排列。
[0194]
并且,在以上所述的实施方式1~3中,在检索对象上下文依赖表达生成部102、202和检索查询上下文依赖表达生成部108中,根据令牌生成依赖于上下文的向量,但实施方式1~3不限于这样的例子。例如,也可以不依赖于上下文而生成与令牌一对一地对应的向量。即使在这样的情况下,根据本实施方式,也能够不准备预先存储有作为令牌间的相似度的令牌间相似度的查找表,而减轻语句间相似度的计算负荷。
[0195]
实施方式3是在实施方式2中追加检索对象维度削减部314和检索查询维度削减部315而成的,但也可以在实施方式1中追加它们。
[0196]
标号说明
[0197]
100、200、300:文档检索装置;101:检索对象db;102、202:检索对象上下文依赖表达生成部;103、303:信息生成部;104:数据结构转换部;105:搜索用db;106:检索查询输入部;107:令牌生成器;108:检索查询上下文依赖表达生成部;109:相似令牌表生成部;111:语句间相似度计算部;112:检索结果输出部;213:本体db;314:检索对象维度削减部;315:检索查询维度削减部。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1