拍照辅助方法及终端设备与流程
本发明涉及图像处理技术领域。更具体地,涉及一种拍照辅助方法及终端设备。
背景技术:
目前,智能手机等终端设备对于用户拍照体验的提升越来越重视,特别是对于人像拍照而言。若能帮助指导用户调整拍照姿势则可实现有效的拍照辅助,从而提升用户体验。
因此,需要提供一种拍照辅助方法及终端设备。
技术实现要素:
本发明的目的在于提供一种拍照辅助方法及终端设备,以解决现有技术存在的问题中的至少一个。
为达到上述目的,本发明采用下述技术方案:
本发明第一方面提供了一种拍照辅助方法,包括:
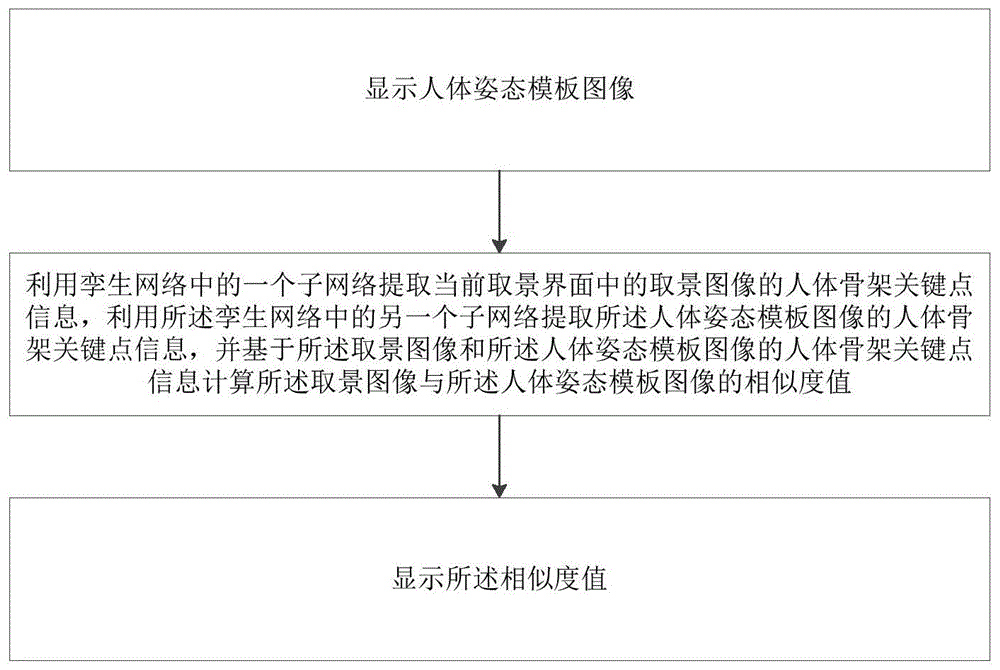
显示人体姿态模板图像;
利用孪生网络中的一个子网络提取当前取景界面中的取景图像的人体骨架关键点信息,利用所述孪生网络中的另一个子网络提取所述人体姿态模板图像的人体骨架关键点信息,并基于所述取景图像和所述人体姿态模板图像的人体骨架关键点信息计算所述取景图像与所述人体姿态模板图像的相似度值;
显示所述相似度值。
本发明第一方面提供的拍照辅助方法,一方面可基于显示的人体姿态模板图像对用户拍照的姿势进行指导,另一方面可精确高效地计算出用户拍照的姿势与模板的相似度量化值并据其对用户拍照的姿势进行指导,可显著提升用户体验,具有较高的应用价值。
可选地,所述孪生网络中的两个子网络分别为堆叠沙漏网络。
此可选方式采用的堆叠沙漏网络可精确提取图像中的人体骨架关键点信息。
可选地,所述堆叠沙漏网络为4阶堆叠沙漏网络。
此可选方式可保证堆叠沙漏网络能够充分全面地提取输入图像中包含的人体骨架关键点信息,从而保证提取图像中的人体骨架关键点信息的精确性,且可保证提取的速度在可接受范围内,实现了提取精度与速度的平衡。
可选地,在所述利用孪生网络中的一个子网络提取当前取景界面中的取景图像的人体骨架关键点信息,利用所述孪生网络中的另一个子网络提取所述人体姿态模板图像的人体骨架关键点信息之前,该方法还包括:
利用多个由样本取景图像和预存的模板库包含的人体姿态模板图像组成的训练数据,训练得到孪生网络。
此可选方式可训练得到有效的孪生网络,从而保证孪生网络提取图像中的人体骨架关键点信息的普适性和精确性。
可选地,所述训练数据包括标注了主观相似度值的样本取景图像和预存的模板库包含的人体姿态模板图像。
此可选方式以标注了主观相似度值的训练数据训练孪生网络,可使得训练得到的孪生网络具有基于用户主观评价的相似度评价能力,相比于利用人体骨架关键点之间的二范数距离等客观指标进行相似度评价的方式,更符合用户的期望。
可选地,所述基于所述取景图像和所述人体姿态模板图像的人体骨架关键点信息计算所述取景图像与所述人体姿态模板图像的相似度值进一步包括:
根据所述取景图像的人体骨架关键点信息损失值、所述人体姿态模板图像的人体骨架关键点信息损失值及所述取景图像的人体骨架关键点信息与所述人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,计算得到作为所述取景图像与所述人体姿态模板图像的相似度值的总体损失值。
可选地,所述根据所述取景图像的人体骨架关键点信息损失值、所述人体姿态模板图像的人体骨架关键点信息损失值及所述取景图像的人体骨架关键点信息与所述人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,计算得到作为所述取景图像与所述人体姿态模板图像的相似度值的总体损失值的计算公式为:
l=α*(l11+l22)+l12
其中,l为总体损失值,l11为取景图像的人体骨架关键点信息损失值,l22为人体姿态模板图像的人体骨架关键点信息损失值,l12为取景图像的人体骨架关键点信息与人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,α为权重参数。
此可选方式基于损失函数实现相似度值的计算,以基于用户主观评价的取景图像与人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值为基础,结合提取的取景图像的人体骨架关键点信息与取景图像相比的损失和提取的人体姿态模板图像的人体骨架关键点信息与人体姿态模板图像相比的损失,可保证计算得到的取景图像与人体姿态模板图像的相似度值的精确性,保证对用户进行拍照指导的效果。
可选地,所述显示人体姿态模板图像进一步包括:将人体姿态模板图像半透明显示于当前取景界面。
此可选方式可进一步提升对用户进行拍照指导的效果。
可选地,在所述显示人体姿态的模板图像之前,该方法还包括:将用户上传的人体姿态模板图像作为人体姿态模板图像,或,响应于用户对预存的模板库包含的人体姿态模板图像的选择,获取人体姿态模板图像。
本发明第二方面提供了一种执行本发明第一方面提供的拍照辅助方法的终端设备,包括显示装置、图像采集装置及处理器;
所述处理器,用于分别提取所述图像采集装置的当前取景界面中的取景图像和所述人体姿态模板图像的人体骨架关键点信息,并基于所述取景图像和所述人体姿态模板图像的人体骨架关键点信息计算所述取景图像与所述人体姿态模板图像的相似度值;
所述显示装置,用于显示人体姿态模板图像和所述相似度值。
本发明的有益效果如下:
本发明所述技术方案一方面可基于显示的人体姿态模板图像对用户拍照的姿势进行指导,另一方面可精确高效地计算出用户拍照的姿势与模板的相似度量化值并据其对用户拍照的姿势进行指导,可显著提升用户体验,具有较高的应用价值。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的说明;
图1示出本发明实施例提供的拍照辅助方法的流程图。
图2示出孪生网络的网络结构示意图。
图3示出沙漏网络的网络结构示意图。
图4示出取景图像与对应的热力图的示意图。
具体实施方式
为了更清楚地说明本发明,下面结合优选实施例和附图对本发明做进一步的说明。附图中相似的部件以相同的附图标记进行表示。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
如图1所示,本发明的一个实施例提供了一种拍照辅助方法,包括:
显示人体姿态模板图像;
利用孪生网络中的一个子网络提取当前取景界面中的取景图像的人体骨架关键点信息,利用所述孪生网络中的另一个子网络提取所述人体姿态模板图像的人体骨架关键点信息,并基于所述取景图像和所述人体姿态模板图像的人体骨架关键点信息计算所述取景图像与所述人体姿态模板图像的相似度值,其中,人体骨架关键点是指骨架上的关键部位的位置点,例如头部、肩部、肘部、手部、腰部、膝关节或者踝关节等关键部位的关键位置点;
显示所述相似度值。
本实施例提供的拍照辅助方法,一方面可基于显示的人体姿态模板图像对用户拍照的姿势进行指导,另一方面可精确高效地计算出用户拍照的姿势与模板的相似度量化值并据其对用户拍照的姿势进行指导,可显著提升用户体验,具有较高的应用价值。其中,由于采用孪生网络架构,孪生网络的两个子网络可以进行参数共享,因此在训练网络模型时可以同时训练两个子网络而不需要增加参数量。另外,由于采用计算并显示当前取景界面中的取景图像与人体姿态模板图像的相似度值的方式,而并非采用已拍摄得到的图像与人体姿态模板图像进行比较,因此,更便于用户及时根据显示的相似度值调整拍照姿势,避免拍摄得到姿势不理想的多张照片后再筛选删除,提升对用户指导的效果。
如图2所示,在本实施例的一些可选的实现方式中,所述孪生网络中的两个子网络分别为堆叠沙漏网络。
此实现方式采用的堆叠沙漏网络可精确提取图像中的人体骨架关键点信息。除此实现方式之外,孪生网络中的两个子网络也可采用其他结构的卷积神经网络。
在本实施例的一些可选的实现方式中,所述堆叠沙漏网络为4阶堆叠沙漏网络,即,堆叠沙漏网络包括串联的4个沙漏网络。
此实现方式可保证堆叠沙漏网络能够充分全面地提取输入图像中包含的人体骨架关键点信息,从而保证提取图像中的人体骨架关键点信息的精确性,且可保证提取的速度在可接受范围内,实现了提取精度与速度的平衡。
在一个具体示例中,堆叠沙漏网络中包含的每一个沙漏网络的网络结构如图3所示,沙漏网络的特点为:
(1)右边就像左边的镜像一样,倒序的复制了一份(c4b-c1b),整体上看起来就是一个沙漏;
(2)上面也复制了一份(c4a-c1a),而且每个方块还通过加号与右边对应位置的方块合并。
其中,对于c4b这个网络层,它是由c7和c4b合并来的,这里有两块操作:
(1)c7层通过上采样将分辨率扩大一倍,上采样相当于池化层(pool层)的反操作,为了将特征图(featuremap)的分辨率扩大,比如c7的内核尺寸(kernelsize)为4x4,那么上采样后得到的kernelsize为8x8。
(2)c4a层与c4层的大小保持一致,可以看作是c4层的“副本”,它的kernelsize是c7的两倍,刚好与被上采样后的c7大小一致,可以直接将数值相加,那么就得到了c4b。
对于c3b这个网络层,同样的,先对c4b进行上采样,然后与c3a合并。后面的层不再赘述。
这样将featuremap层层叠加后,最后一个大的featuremap-c1b,既保留了所有层的信息,又与输入原图大小,意味着可以通过1x1卷积生成代表关键点概率的热力图(heatmap),如图4所示,热力图中标记有图像中包含的多个骨架关键点,包含人体骨架关键点信息。
对于串联多个沙漏网络形成的堆叠沙漏网络而言,由于人体骨架关键点之间是可以互相参考预测的,例如知道双肩的位置后,可以更好的预测肘部节点,给出腰部和脚踝位置,又可以用于预测膝盖。既然热力图包含了输入图像的人体骨架关键点,那么热力图也就包含了各人体骨架关键点的相互关系,可以看作是图模型。所以将第一个沙漏网络得到的热力图作为下一个沙漏网络的输入,就意味着第二个沙漏网络可以使用关键点之间的相互关系,从而提升了人体骨架关键点的提取精度。综上,堆叠沙漏网络可利用多尺度特征来提取人体骨架关键点信息,从而能够充分全面地提取输入图像中包含的人体骨架关键点信息。
在本实施例的一些可选的实现方式中,在所述利用孪生网络中的一个子网络提取当前取景界面中的取景图像的人体骨架关键点信息,利用所述孪生网络中的另一个子网络提取所述人体姿态模板图像的人体骨架关键点信息之前,该方法还包括:
利用多个由样本取景图像和预存的模板库包含的人体姿态模板图像组成的训练数据,训练得到孪生网络。
此实现方式可训练得到有效的孪生网络,从而保证孪生网络提取图像中的人体骨架关键点信息的普适性和精确性。
在本实施例的一些可选的实现方式中,所述训练数据包括标注了主观相似度值(例如十分制的1-10分数值)的样本取景图像和预存的模板库包含的人体姿态模板图像。
此实现方式,以标注了主观相似度值的训练数据训练孪生网络,可使得孪生网络向着人体骨架关键点金标准训练,训练得到的孪生网络具有基于用户主观评价的相似度评价能力,相比于利用人体骨架关键点之间的二范数距离等客观指标进行相似度评价的方式,更符合用户的期望。
在本实施例的一些可选的实现方式中,所述基于所述取景图像和所述人体姿态模板图像的人体骨架关键点信息计算所述取景图像与所述人体姿态模板图像的相似度值进一步包括:
根据所述取景图像的人体骨架关键点信息损失值、所述人体姿态模板图像的人体骨架关键点信息损失值及所述取景图像的人体骨架关键点信息与所述人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,计算得到作为所述取景图像与所述人体姿态模板图像的相似度值的总体损失值。
在本实施例的一些可选的实现方式中,所述根据所述取景图像的人体骨架关键点信息损失值、所述人体姿态模板图像的人体骨架关键点信息损失值及所述取景图像的人体骨架关键点信息与所述人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,计算得到作为所述取景图像与所述人体姿态模板图像的相似度值的总体损失值的计算公式为:
l=α*(l11+l22)+l12
其中,l为总体损失值,l11为取景图像的人体骨架关键点信息损失值,l22为人体姿态模板图像的人体骨架关键点信息损失值,l12为取景图像的人体骨架关键点信息与人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,α为权重参数,用以调整或者说平衡各损失值的比重。可理解的是,总体损失值l的值越小,表征取景图像与人体姿态模板图像中的人体姿态的相似度越高,即显示的相似度值越小表示被拍摄用户的姿态与人体姿态模板图像中的姿态约接近。
此实现方式基于损失函数实现相似度值的计算,以基于用户主观评价的取景图像与人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值为基础,结合提取的取景图像的人体骨架关键点信息与取景图像相比的损失和提取的人体姿态模板图像的人体骨架关键点信息与人体姿态模板图像相比的损失,可保证计算得到的取景图像与人体姿态模板图像的相似度值的精确性,保证对用户进行拍照指导的效果。
在本实施例的一些可选的实现方式中,所述显示人体姿态模板图像进一步包括:将人体姿态模板图像半透明显示于当前取景界面。
此实现方式可进一步提升对用户进行拍照指导的效果。
在本实施例的一些可选的实现方式中,在所述显示人体姿态的模板图像之前,该方法还包括:将用户上传的人体姿态模板图像作为人体姿态模板图像,或,响应于用户对预存的模板库包含的人体姿态模板图像的选择,获取人体姿态模板图像。
本发明的另一个实施例提供了一种终端设备,包括显示装置、图像采集装置及处理器;
所述处理器,用于分别提取所述图像采集装置的当前取景界面中的取景图像和所述人体姿态模板图像的人体骨架关键点信息,并基于所述取景图像和所述人体姿态模板图像的人体骨架关键点信息计算所述取景图像与所述人体姿态模板图像的相似度值;
所述显示装置,用于显示人体姿态模板图像和所述相似度值。
本实施例提供的终端设备,一方面可基于显示的人体姿态模板图像对用户拍照的姿势进行指导,另一方面可精确高效地计算出用户拍照的姿势与模板的相似度量化值并据其对用户拍照的姿势进行指导,可显著提升用户体验,具有较高的应用价值。
在本实施例的一些可选的实现方式中,所述孪生网络中的两个子网络分别为堆叠沙漏网络。
此实现方式采用的堆叠沙漏网络可精确提取图像中的人体骨架关键点信息。除此实现方式之外,孪生网络中的两个子网络也可采用其他结构的卷积神经网络。
在本实施例的一些可选的实现方式中,所述堆叠沙漏网络为4阶堆叠沙漏网络。
此实现方式可保证堆叠沙漏网络能够充分全面地提取输入图像中包含的人体骨架关键点信息,从而保证提取图像中的人体骨架关键点信息的精确性,且可保证提取的速度在可接受范围内,实现了提取精度与速度的平衡。
在本实施例的一些可选的实现方式中,所述处理器,还用于利用多个由样本取景图像和预存的模板库包含的人体姿态模板图像组成的训练数据,训练得到孪生网络。除此实现方式之外,可由服务器训练孪生网络,训练完成后服务器再将训练得到孪生网络发送至终端设备。其中,终端设备可以是各种电子设备,包括但不限于个人电脑、智能手机、智能手表、平板电脑、个人数字助理等等。服务器可以是提供各种服务的服务器,服务器可以对接收到的数据进行存储、分析等处理,并将处理结果反馈给终端设备。终端设备与服务器通过网络进行通信,该网络可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。
此实现方式可训练得到有效的孪生网络,从而保证孪生网络提取图像中的人体骨架关键点信息的普适性和精确性。
在本实施例的一些可选的实现方式中,所述训练数据包括标注了主观相似度值的样本取景图像和预存的模板库包含的人体姿态模板图像。
此实现方式可实现端到端的基于孪生网络的主观姿态相似度衡量,以标注了主观相似度值的训练数据训练孪生网络,可使得训练得到的孪生网络具有基于用户主观评价的相似度评价能力,相比于利用人体骨架关键点之间的二范数距离等客观指标进行相似度评价的方式,更符合用户的期望。
在本实施例的一些可选的实现方式中,所述处理器进一步用于根据所述取景图像的人体骨架关键点信息损失值、所述人体姿态模板图像的人体骨架关键点信息损失值及所述取景图像的人体骨架关键点信息与所述人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,计算得到作为所述取景图像与所述人体姿态模板图像的相似度值的总体损失值。
在本实施例的一些可选的实现方式中,所述处理器进一步用于根据下述计算公式计算得到作为所述取景图像与所述人体姿态模板图像的相似度值的总体损失值:
l=α*(l11+l22)+l12
其中,l为总体损失值,l11为取景图像的人体骨架关键点信息损失值,l22为人体姿态模板图像的人体骨架关键点信息损失值,l12为取景图像的人体骨架关键点信息与人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值,α为权重参数。
此实现方式基于损失函数实现相似度值的计算,以基于用户主观评价的取景图像与人体姿态模板图像的人体骨架关键点信息之间的主观相似度损失值为基础,结合提取的取景图像的人体骨架关键点信息与取景图像相比的损失和提取的人体姿态模板图像的人体骨架关键点信息与人体姿态模板图像相比的损失,可保证计算得到的取景图像与人体姿态模板图像的相似度值的精确性,保证对用户进行拍照指导的效果。
在本实施例的一些可选的实现方式中,所述显示装置进一步用于:将人体姿态模板图像半透明显示于图像采集装置的当前取景界面。
此实现方式可进一步提升对用户进行拍照指导的效果。
在一个具体示例中,终端设备为智能手机,用户a持有智能手机为用户b拍照时,智能手机的屏幕实时显示其摄像头的取景画面且半透明显示人体姿态模板图像,智能手机的处理器利用预存的训练得到的孪生网络中的一个子网络提取摄像头的当前取景画面中用户b的人体骨架关键点信息,利用孪生网络中的另一个子网络提取人体姿态模板图像的人体骨架关键点信息,并基于所述取景图像和所述人体姿态模板图像的人体骨架关键点信息计算所述取景图像与所述人体姿态模板图像的相似度值,相似度值例如为百分制的分数值;智能手机的屏幕还显示相似度值,其中,可利用屏幕的区别于取景画面的显示区域显示相似度值,也可在取景画面的显示区域半通明显示相似度值。这样,用户a可基于智能手机的屏幕显示的人体姿态模板图像和相似度值提示用户b调整拍照姿势,在调整过程中,智能手机的处理器还会持续利用孪生网络中的一个子网络提取摄像头的当前取景画面中用户b的人体骨架关键点信息并通过屏幕实时显示当前的相似度值。
在本实施例的一些可选的实现方式中,所述处理器,还用于将用户上传的人体姿态模板图像作为人体姿态模板图像,或,响应于用户对预存的模板库包含的人体姿态模板图像的选择,获取人体姿态模板图像。
需要说明的是,用户上传人体姿态模板图像可理解为用户将人体姿态模板图像输入终端设备,终端设备接收用户输入的终端设备人体姿态模板图像,其中,所称的“接收”的具体实现对应于用户使用终端设备的方式,例如,用户使用触控屏向智能手机输入人体姿态模板图像,则智能手机接收用户所输入的人体姿态模板图像。另外,预存的模板库可存储于服务器,通过终端设备与服务器的交互实现用户通过终端设备选择预存的模板库包含的人体姿态模板图像,使得终端设备获取人体姿态模板图像,进一步,服务器响应于用户通过终端设备发送的选择指令后,可将预存的模板库包含的人体姿态模板图像的缩略图发送至终端设备供用户选择,终端设备响应于用户的选择操作向服务器发送获取指令后,服务器再根据获取指令将对于的人体姿态模板图像原图发送至终端设备。
需要说明的是,本实施例提供的终端设备的原理及工作流程与上述拍照辅助方法相似,相关之处可以参照上述说明,在此不再赘述。
需要说明的是,在本发明的描述中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于本领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!