边缘计算服务器及边缘计算方法与流程
本发明涉及人工智能技术领域,尤其涉及一种边缘计算服务器及边缘计算方法。
背景技术:
目前的人工智能领域,处理终端设备数据的计算点往往发生在云端数据中心,大致过程为物联网终端设备产生数据,发送到云端数据中心,人工智能进行计算,再将数据返回终端,以此实现互联效果。
这样的处理方式,一方面带来的是网络节点的堵塞,延长终端设备的响应时间,另一方面,随着pb级别的数据源源不断的传送到云端,云端服务器所承载的压力也随着增大。
技术实现要素:
本发明的主要目的在于提供一种边缘计算服务器及边缘计算方法,旨在解决现有技术中云端服务器压力过大的技术问题。
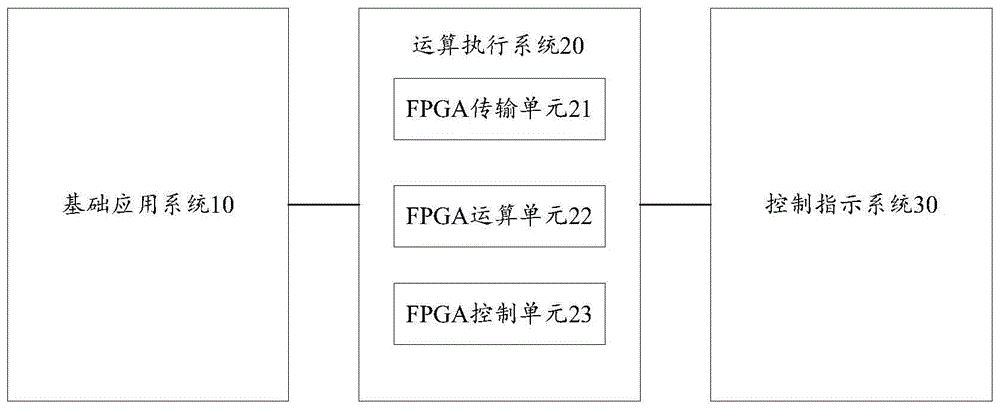
为实现上述目的,本发明提供一种边缘计算服务器,所述边缘计算服务器包括:基础应用系统、运算执行系统和控制指示系统;
所述基础应用系统,用于获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统,所述算法库中包括计算器视觉算法、神经网络算法、深度学习算法和运动控制算法;
所述运算执行系统,用于基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果;
所述控制指示系统,用于对所述计算结果进行显示。
可选地,所述运算执行系统包括fpga传输单元、fpga运算单元和fpga控制单元;
所述fpga传输单元,用于接收所述基础应用系统发送的待计算数据和数据计算算法;
所述fpga运算单元,用于基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果;
所述fpga控制单元,用于控制所述控制指示系统对所述计算结果进行显示。
可选地,所述fpga运算单元,还用于通过并行流水线执行策略来基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果。
可选地,所述fpga运算单元,还用于在所述数据计算算法为神经网络算法时,通过矩阵乘法实现对卷积层和全连接层的并行计算。
可选地,所述基础应用系统,还用于接收通过软件开发工具包sdk所输入的编程程序,根据所述编程程序对所述算法库进行编程调试。
为实现上述目的,本发明提供一种边缘计算方法,所述边缘计算方法基于边缘计算服务器实现,所述边缘计算服务器包括:基础应用系统、运算执行系统和控制指示系统;
所述边缘计算方法包括以下步骤:
基础应用系统获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统,所述算法库中包括计算器视觉算法、神经网络算法、深度学习算法和运动控制算法;
运算执行系统基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果;
控制指示系统对所述计算结果进行显示。
可选地,所述运算执行系统包括fpga传输单元、fpga运算单元和fpga控制单元;
所述运算执行系统基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果,包括:
fpga传输单元接收所述基础应用系统发送的待计算数据和数据计算算法;
fpga运算单元基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果;
fpga控制单元控制所述控制指示系统对所述计算结果进行显示。
可选地,所述fpga运算单元基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果,包括:
fpga运算单元通过并行流水线执行策略来基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果。
可选地,所述fpga运算单元基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果之前,所述边缘计算方法还包括:
fpga运算单元在所述数据计算算法为神经网络算法时,通过矩阵乘法实现对卷积层和全连接层的并行计算。
可选地,所述基础应用系统获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统之前,所述边缘计算方法还包括:
基础应用系统接收通过软件开发工具包sdk所输入的编程程序,根据所述编程程序对所述算法库进行编程调试。
本发明通过基础应用系统获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统,所述算法库中包括计算器视觉算法、神经网络算法、深度学习算法和运动控制算法,运算执行系统基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果,控制指示系统对所述计算结果进行显示,通过各系统之间的配合,从而实现了边缘计算,无需将所有的数据均上传至云端服务器进行处理,降低了云端服务器的压力。
附图说明
图1为本发明边缘计算服务器一实施例的结构框图;
图2为本发明边缘计算方法一实施例的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明边缘计算服务器一实施例的结构框图。
在第一实施例中,所述边缘计算服务器包括:基础应用系统10、运算执行系统20和控制指示系统30;
所述基础应用系统10,用于获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统20,所述算法库中包括计算器视觉算法、神经网络算法、深度学习算法和运动控制算法。
可理解的是,基础应用系统是边缘计算服务器的整体基础系统,主要由linux操作系统、驱动程序、核心算法库、运动控制库、组件、api接口和应用程序组成,各系统模块由linux内核提供的内部通信机制进行通信和数据交互。
在具体实现中,所述基础应用系统10以cpu作为硬件载体运行,并通过网络编程接口和软件开发工具包(sdk)开发环境进行开发调试操作,也就是说,可通过所述基础应用系统接收通过软件开发工具包sdk所输入的编程程序,根据所述编程程序对所述算法库进行编程调试。
需要说明的是,所述基础应用系统10以cpu作为硬件载体运行时,所述硬件载体可集成inteli78200ucpu、8gddr4集成intelhdgraphics620核心显卡和128g硬盘,带有mini-pcie、vga、hdmi、dp、com、lan、usb3.0、mic、rj45等接口。
所述运算执行系统20,用于基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果。
所述运算执行系统20以fpga作为硬件载体运行,为便于实现所述运行执行系统,本实施例中,所述运算执行系统20包括fpga传输单元21、fpga运算单元22和fpga控制单元23;
所述fpga传输单元21,用于接收所述基础应用系统发送的待计算数据和数据计算算法;
所述fpga运算单元22,用于基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果;
所述fpga控制单元23,用于控制所述控制指示系统对所述计算结果进行显示。
需要说明的是,所述运算执行系统20以fpga作为硬件载体运行时,所述硬件载体采用xilinx7015,基于高性能双核armcortex-a9处理系统,每核心一neon协处理器,最高支持866mhz主频,两级高速缓存(每核心32kbi-cache32kbd-cache一级缓存,两核心共享512kb二级缓存),256kb片上ram,外部动态存储器支持ddr3,ddr3l,ddr2,lpddr2,外部静态存储器支持2xqspi,nand,nor,外围接口支持:2xuart,2xcan2.0b,2xi2c,2xspi,4x32bgpio,2xusb2.0(otg),2xtri-modegigabitethernet,2xsd/sdio,8个dma通道(其中4个pl专用)支持加解密、授权(rsa/aes,sha),安全启动。
为提高各单元的使用效率,本实施例中,所述fpga运算单元22可通过并行流水线执行策略来基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果。
为提高神经网络算法的计算效率,本实施例中,所述fpga运算单元22,还用于在所述数据计算算法为神经网络算法时,通过矩阵乘法实现对卷积层和全连接层的并行计算。
由于所述基础应用系统10以cpu作为硬件载体运行,所述运算执行系统20以fpga作为硬件载体运行,此时,cpu和fpga之间的通信接口由pci-e总线担任,主要负责高速数据、高速指令和高清视觉图像传输。pci-e总线采用了串行连接方式,并使用数据包(packet)进行数据传输,采用这种结构有效去除了在pci-e总线中存在的一些边带信号,如intx和pme#等信号。在pci-e总线中,数据报文在接收和发送过程中,需要通过多个层次,包括事务层、数据链路层和物理层pci-e总线的层次组成结构与网络中的层次结构有类似之处,但是pci-e总线的各个层次都是使用硬件逻辑实现的。在pci-e体系结构中,数据报文首先在设备的核心层中产生,然后再经过该设备的事务层、数据链路层和物理层,最终发送出去。而接收端的数据也需要通过物理层、数据链路和事务层,并最终到达devicecore。
具体地,可采用xdma+pci-e的架构,以axi总线进行链接,显示工控设备pci-e协议对fpga的地址bar转换,以偏移地址为需要控制的寄存器或外设的地址线,进行数据读写。
所述控制指示系统30,用于对所述计算结果进行显示。
需要说明的是,所述边缘计算服务器的应用领域主要面向智慧医疗、工业控制和物联网控制。在具体应用时,可实现医疗资产管理、手术室智能化管理、医学影像ai分析等智慧医疗应用场景;而在工业控制场景中,本ai边缘服务器应用场景众多,其中ai视觉识别和自动化生产线控制则是主要应用;最后在于物联网领域中,可实现对智能家居、智能楼宇和智能环境监测等应用。
本实施例通过基础应用系统获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统,所述算法库中包括计算器视觉算法、神经网络算法、深度学习算法和运动控制算法,运算执行系统基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果,控制指示系统对所述计算结果进行显示,通过各系统之间的配合,从而实现了边缘计算,无需将所有的数据均上传至云端服务器进行处理,降低了云端服务器的压力。
参照图2,图2为本发明边缘计算方法一实施例的流程示意图。
在第一实施例中,所述边缘计算方法基于边缘计算服务器实现,可参照图1,所述边缘计算服务器包括:基础应用系统10、运算执行系统20和控制指示系统30;
所述边缘计算方法包括以下步骤:
s10:基础应用系统获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统,所述算法库中包括计算器视觉算法、神经网络算法、深度学习算法和运动控制算法。
可理解的是,基础应用系统10是边缘计算服务器的整体基础系统,主要由linux操作系统、驱动程序、核心算法库、运动控制库、组件、api接口和应用程序组成,各系统模块由linux内核提供的内部通信机制进行通信和数据交互。
在具体实现中,所述基础应用系统10以cpu作为硬件载体运行,并通过网络编程接口和软件开发工具包(sdk)开发环境进行开发调试操作,也就是说,可通过所述基础应用系统接收通过软件开发工具包sdk所输入的编程程序,根据所述编程程序对所述算法库进行编程调试。
需要说明的是,所述基础应用系统10以cpu作为硬件载体运行时,所述硬件载体可集成inteli78200ucpu、8gddr4集成intelhdgraphics620核心显卡和128g硬盘,带有mini-pcie、vga、hdmi、dp、com、lan、usb3.0、mic、rj45等接口。
s20:运算执行系统基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果。
所述运算执行系统20以fpga作为硬件载体运行,为便于实现所述运行执行系统,本实施例中,所述运算执行系统20包括fpga传输单元21、fpga运算单元22和fpga控制单元23;
所述fpga传输单元21,用于接收所述基础应用系统发送的待计算数据和数据计算算法;
所述fpga运算单元22,用于基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果;
所述fpga控制单元23,用于控制所述控制指示系统对所述计算结果进行显示。
需要说明的是,所述运算执行系统20以fpga作为硬件载体运行时,所述硬件载体采用xilinx7015,基于高性能双核armcortex-a9处理系统,每核心一neon协处理器,最高支持866mhz主频,两级高速缓存(每核心32kbi-cache32kbd-cache一级缓存,两核心共享512kb二级缓存),256kb片上ram,外部动态存储器支持ddr3,ddr3l,ddr2,lpddr2,外部静态存储器支持2xqspi,nand,nor,外围接口支持:2xuart,2xcan2.0b,2xi2c,2xspi,4x32bgpio,2xusb2.0(otg),2xtri-modegigabitethernet,2xsd/sdio,8个dma通道(其中4个pl专用)支持加解密、授权(rsa/aes,sha),安全启动。
为提高各单元的使用效率,本实施例中,所述fpga运算单元22可通过并行流水线执行策略来基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果。
为提高神经网络算法的计算效率,本实施例中,所述fpga运算单元22,还用于在所述数据计算算法为神经网络算法时,通过矩阵乘法实现对卷积层和全连接层的并行计算。
由于所述基础应用系统10以cpu作为硬件载体运行,所述运算执行系统20以fpga作为硬件载体运行,此时,cpu和fpga之间的通信接口由pci-e总线担任,主要负责高速数据、高速指令和高清视觉图像传输。pci-e总线采用了串行连接方式,并使用数据包(packet)进行数据传输,采用这种结构有效去除了在pci-e总线中存在的一些边带信号,如intx和pme#等信号。在pci-e总线中,数据报文在接收和发送过程中,需要通过多个层次,包括事务层、数据链路层和物理层pci-e总线的层次组成结构与网络中的层次结构有类似之处,但是pci-e总线的各个层次都是使用硬件逻辑实现的。在pci-e体系结构中,数据报文首先在设备的核心层中产生,然后再经过该设备的事务层、数据链路层和物理层,最终发送出去。而接收端的数据也需要通过物理层、数据链路和事务层,并最终到达devicecore。
具体地,可采用xdma+pci-e的架构,以axi总线进行链接,显示工控设备pci-e协议对fpga的地址bar转换,以偏移地址为需要控制的寄存器或外设的地址线,进行数据读写。
s30:控制指示系统对所述计算结果进行显示。
需要说明的是,所述边缘计算服务器的应用领域主要面向智慧医疗、工业控制和物联网控制。在具体应用时,可实现医疗资产管理、手术室智能化管理、医学影像ai分析等智慧医疗应用场景;而在工业控制场景中,本ai边缘服务器应用场景众多,其中ai视觉识别和自动化生产线控制则是主要应用;最后在于物联网领域中,可实现对智能家居、智能楼宇和智能环境监测等应用。
本实施例通过基础应用系统获取待计算数据,根据所述待计算数据从算法库中查找对应的数据计算算法,将所述待计算数据和数据计算算法发送至所述运算执行系统,所述算法库中包括计算器视觉算法、神经网络算法、深度学习算法和运动控制算法,运算执行系统基于所述数据计算算法对所述待计算数据进行数据计算,获得计算结果,控制指示系统对所述计算结果进行显示,通过各系统之间的配合,从而实现了边缘计算,无需将所有的数据均上传至云端服务器进行处理,降低了云端服务器的压力。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!