本发明属于大数据信息检索技术领域,涉及语义增强的异构信息网络上top-k相似度搜索方法,具体为一种异构信息网络下支持相似性搜索的神经网络模型设计方法,以应对大数据信息检索的挑战。
背景技术:
异构信息网络是包含多种类型节点和节点之间关系边的逻辑网络,定义在其上的元路径包含了丰富的语义信息。近几年,异构信息网络上的数据挖掘任务引起了工业界和学术界的广泛关注,其中网络上对象的相似性搜索是一个关键技术。异构信息网络上的top-k相似性搜索侧重于通过评估这些节点之间的相似度来获得一组相关节点。
当前已有大量的相关研究:
在异构信息网络上对对象节点进行表示学习,通过计算向量距离计算节点相似度。yuxiaodong等在kdd2017发表了论文《metapath2vec:scalablerepresentationlearningforheterogeneousnetworks》,提出模型对同构网络表示学习方法deepwalk改进,通过随机游走实现了异构信息网络上的节点嵌入方法。王等在www2019发表论文《heterogeneousgraphattentionnetwork》,提出异构图神经网络模型han,han使用节点级注意力和语义级注意力,通过语义级注意力来区分元路径来获取语义信息。张等在kdd2019上发表论文《heterogeneousgraphneuralnetwork》提出的模型hetgnn也使用了注意力机制,根据节点丰富的内容信息和在异构信息网络中的结构信息对不同类型的节点进行统一的网络表示学习。
推荐任务以度量对象的相似度实现用户-对象/用户/…的推荐。胡等在kdd2018发表《leveragingmeta-pathbasedcontextfortop-nrecommendationwithaneuralco-attentionmodel》,提出具有共同注意机制的深度神经网络模型mcrec。利用丰富的基于元路径的上下文捕获用户和商品之间的相似性,实现对用户进行top-k相似商品的推荐。
搜索任务中通过对象的相似性度量实现k个最相似对象的搜索。孙等在vldbendowment上发表论文《pathsim:metapathbasedtop-ksimilaritysearchinheterogeneousinformationnetworks》利用元路径来解决相似性搜索问题,通过考虑顶点之间的可达性和可见性来定义两个同类型对象之间的相似性。石等在ieeetkde上发表了《hetesim:ageneralframeworkforrelevancemeasureinheterogeneousnetworks》。hetesim作为pathsim的扩展,可以度量不同类型对象的相似性。pham等的《w-pathsim:novelapproachofweightedsimilaritymeasureincontent-basedheterogeneousinformationnetworksbyapplyingldatopicmodeling》利用主题的加权余弦相似度对pathsim提出了另一种改进。
异构信息网络上的对象节点在不同的元路径语义下有不同的结构特征,同时对象本身还具有特定的内容信息。以上方法或者使用单一的元路径训练模型,不能捕获丰富的元路径语义信息,或者虽然结合多条元路径却无法根据训练的目标动态调整语义结构,上面提出的部分网络表示学习的方法虽然考虑内容和结构信息,但它们均是首先根据节点的内容信息对节点嵌入,在此基础上,将内容嵌入结果作为初始值,继续进行结构上的训练。这些方法存在的问题是节点嵌入向量中的内容信息会随着之后结构嵌入训练而逐渐削弱甚至消失。因此,如何解决以上问题,提出能够捕获对象的内容信息和结构信息并整合多条元路径下语义的模型是一个需要解决的巨大挑战。
技术实现要素:
为克服以上提出的问题,本发明设计一种用于在异构信息网络上进行对象top-k相似性搜索的双通道卷积神经网络模型。
已知整个异构信息网络的结构和网络中每个节点对应的文本描述信息,模型输出每个节点与其它节点的相似度。本发明设计的模型基于双通道卷积神经网络来整合内容信息和结构信息,以下步骤1和步骤2中进行的操作均在内容信息处理通道和结构信息处理通道中同步进行。
本发明的技术方案如下:
语义增强的异构信息网络上top-k相似度搜索方法,包括如下步骤:
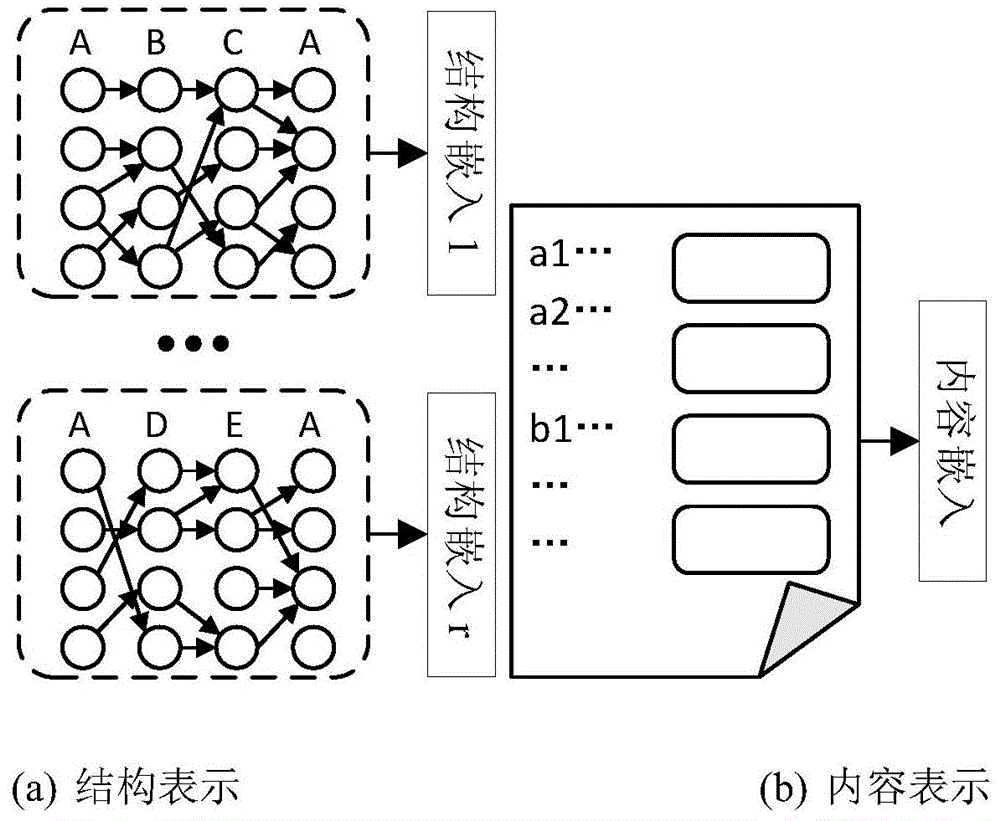
步骤1:节点表示。使用预训练方法生成异构信息网络数据集中所有节点的内容和结构表示。由于节点具有内容信息和结构信息,如图1所示,内容信息指节点的文字描述、图像、标签等信息。结构信息是指网络上节点与他人的连接关系。
具体操作包括以下两部分:
1-1)使用自然语言处理领域的模型预训练得到节点的内容表示其中a是a类型节点的数目,d1是节点的内容嵌入维度。
1-2)在指定不同语义的r条元路径下分别使用基于异构网络的网络表示学习训练模型,最后得到节点的结构表示其中d2为节点结构嵌入维数。是对应元路径pi下的嵌入结果,i∈{1,…,r}。
步骤2:路径表示。为了捕获两个待度量相似度的节点之间的元路径所具有的丰富语义特性,并且保留节点的结构特征和内容特征,为连接两者的元路径pi分别生成一个内容表示向量和一个结构表示向量并通过注意力机制整合多条元路径,具体步骤如下:
2-1)对节点进行内容和结构的集成嵌入。如图2所示的模型架构,将节点在r条元路径下的嵌入表示输入全连接神经网络层,分别得到节点的结构表示βs,内容表示βc以及综合表示βs+c。
2-2)为了捕获两个节点之间元路径蕴含的丰富的语义信息,模型以路径实例作为输入。如图3所示,以度量相似度的节点a1和a2为端点,在指定的元路径上对路径进行采样,得到路径实例pi,j,其中i指元路径编号,j指路径实例编号。根据相邻节点间边的参数,使用对称随机游走(srw)来获得路径实例的权重,舍弃了一些权重较低的路径实例。
2-3)将路径实例pi,j上的节点用αc和αs进行表示,分别通过卷积层进行嵌入得到路径实例的内容表示和结构表示其中i∈{1,…,r},j∈{1,…,t}代表元路径和路径实例的编号。之后,通过池化层获得每个元路径的内容表示和结构表示本部分模型结构见图4。
2-4)为了同时整合多条元路径所蕴含的语义信息并动态调整不同元路径的重要程度,设计元路径间的注意力机制,如图5所示。对于目标节点am,元路径pi对于它的重要程度得分为:
其中w1,w2是模型参数,是元路径pi的内容表示和结构表示。
将计算得到的不同元路径对于节点am的重要程度得分score(am,pi)输入softmax层进行归一化处理,得到元路径pi的注意力权重。计算方法为:
其中am和an是待度量相似度的两个对象节点。
根据注意力权重计算两个节点之间的综合语义表示:
其中,包含了两个节点间的内容综合表示和结构综合表示。
以上步骤1和步骤2实现了内容信息和结构信息两个通道的训练,每个通道完整的模型架构见图6。
步骤3:设计注意力层以结合两个卷积神经网络通道训练得到的内容和结构信息,模型框架如图7所示。具体操作如下:
3-1)计算内容信息的注意力得分:
3-2)计算结构信息的注意力得分:
以上w3,w4均为模型参数。
3-3)计算内容信息表示的注意力权重:
3-4)计算结构信息表示的注意力权重:
3-5)计算整合内容信息和结构信息的两个节点间信息综合表示:
其中表示连接操作,即连接两个加权后的向量。将内容信息表示和结构信息表示分别与注意力权重相乘后连接起来,与直接将它们加权求和相比,此功能可以有效地帮助我们减少信息丢失。
步骤4:通过将以上综合表示cs输入mlp(multi-layerperceptron,多层感知器)中,输出两个节点间的相似度打分,即:
ym,n=sigmoid[f(cs)]
其中f是具有两个全连接层,激活函数为relu的mlp,其输出送入sigmoid层中以获得最终相似度打分。
以上步骤构成了模型的完整架构,模型由输入到输出的整体架构如图8所示。
步骤5:使用对数损失函数训练模型。在给定元路径条件下,相似节点之间应具有更多路径实例,并且它们的相似度得分ym,n大于其他节点。这里使用负采样,采集没有路径实例相连接的节点对作为负样本。
将相似节点对分数设置为1,将不相似节点对分数设置为0,模型训练目标函数表述为:
其中yi是模型是输出变量,n+是正样本集,n-是负样本集,ρi是预测的输入实例相似的概率。
本发明的有益效果:
本发明模型利用卷积神经网络的两个通道同时分别训练内容信息和结构信息,并且采用了两种注意力机制,用于动态的区分不同元路径的语义差异性以及结合对象的内容和结构信息进行模型的综合训练。
附图说明
图1为本发明技术方案中节点结构信息表示和内容信息表示的说明图。其中:图1(a)为本发明技术方案中节点结构信息表示的说明图。图1(b)为本发明技术方案中节点内容信息表示的说明图。
图2为本发明技术方案中对节点集成嵌入的结构图。
图3为本发明技术方案中模型数据输入的设计图。
图4为本发明技术方案中每条通道内每个元路径的表示框架。
图5为本发明技术方案中元路径间的注意力机制。
图6为本发明技术方案中每个通道的模型架构。
图7为本发明技术方案中利用注意机制结合内容和结构信息的结构图。
图8为本发明技术方案设计模型的整体架构图。
图9为本发明实施例中提出的模型与其它模型在不同搜索数量下结果比较图。
具体实施方式
本发明设计一种用于在异构信息网络上进行对象top-k相似性搜索的双通道卷积神经网络模型。为了使本发明的目的、技术方案及优势更加清晰,下面结合学术社交网络(包含节点类型有作者a,论文p,会议v),设计元路径包括a-p-v-p-a(两个作者的论文在同一个会议上发表)和a-p-a(两个作者同时参与撰写一篇论文),度量两个作者之间的相似度,完成为作者搜索与他最相似的k名作者的任务。
参考附图和具体实施例对本发明做进一步详细说明:
步骤1:节点表示。使用预训练方法生成异构信息网络数据集中所有节点的内容和结构表示。由于节点具有内容信息和结构信息,内容信息指节点的文字描述,图像,标签等信息。结构信息是指网络上节点与他人的连接关系。具体操作包括以下两部分:
1-1)使用doc2vec(一种用于获取句子的向量表示的非监督式算法,是word2vec的拓展)训练节点的文本描述信息,得到节点的内容表示其中a是a类型节点的数目,设置节点的内容嵌入维度为128。
1-2)在元路径a-p-v-p-a和a-p-a下分别使metapath2vec++训练学术社交网络图,得到节点的结构表示这里设置节点结构嵌入维数为128。是对应元路径a-p-a下的嵌入结果,是对应元路径a-p-v-p-a下的嵌入结果。
步骤2:路径表示。为了捕获两个待度量相似度的作者之间的元路径所具有的丰富语义特性,并且保留节点的结构特征和内容特征,为连接两者的元路径papa和papvpa分别生成内容表示向量和结构表示向量并通过注意力机制整合多条元路径,具体步骤如下:
2-1)对节点进行内容和结构的集成嵌入。将和输入全连接神经网络层d1,得到节点的结构表示βs。将αc输入全连接神经网络层d2,得到内容表示βc。将αc输入全连接神经网络层d3,得到βs+c。
2-2)模型以路径实例作为输入。以度量相似度的节点a1和a2为端点,在指定的元路径上对路径进行采样,得到路径实例papa,j和papvpa,j,其中j指路径实例编号。根据相邻节点间边的参数,使用对称随机游走(srw)来获得路径实例的权重,舍弃了一些权重较低的路径实例。
2-3)将路径实例papa,j上的节点用αc和进行表示,将路径实例papvpa,j上的节点用αc和进行表示,分别通过卷积层进行嵌入得到路径实例的内容表示和结构表示其中j∈{1,…,t}代表路径实例的编号。之后,通过池化层获得元路径的内容表示和结构表示
2-4)设计元路径间的注意力机制动态调整不同元路径的重要程度。对于目标节点am,元路径papa对于它的重要程度得分为:
元路径papvpa对于它的重要程度得分为:
其中w1,w2是模型参数,是元路径的内容表示和结构表示。
将计算得到的不同元路径对于节点am的重要程度得分score(am,papa)和score(am,papvpa)输入softmax层进行归一化处理,得到元路径的注意力权重。计算方法为:
其中am和an是待度量相似度的两个对象节点。
根据注意力权重计算两个节点之间的综合语义表示:
其中,包含了两个节点间的内容综合表示和结构综合表示。
步骤3:设计注意力层以结合内容和结构信息。具体操作如下:
3-1)计算内容信息的注意力得分:
3-2)计算结构信息的注意力得分:
以上w3,w4均为模型参数。
3-3)计算内容信息表示的注意力权重:
3-4)计算结构信息表示的注意力权重:
3-5)计算整合内容信息和结构信息的两个节点间信息综合表示:
其中表示连接操作,即连接两个加权后的向量。将内容信息表示和结构信息表示分别与注意力权重相乘后连接起来,与直接将它们加权求和相比,此功能可以有效地帮助我们减少信息丢失。
步骤4:通过将以上综合表示cs输入mlp(multi-layerperceptron,多层感知器)中,输出两个作者间的相似度打分,即:
ym,n=sigmoid[f(cs)]
其中f是具有两个全连接层,激活函数为relu的mlp,其输出送入sigmoid层中以获得最终相似度打分。
步骤5:使用对数损失函数和负采样,采集在路径a-p-a和a-p-v-p-a上均没有路径实例相连接的作者节点对作为负样本,每个正样本对应采集5个负样本。
将相似节点对分数设置为1,将不相似节点对分数设置为0,模型训练目标函数表述为:
其中yi是模型是输出变量,n+是正样本集,n-是负样本集,ρi是预测的输入实例相似的概率。
下面通过实验对本发明的技术效果进行说明:
1.实验条件说明
选取aminer(由清华大学计算机科学与技术系教授唐杰率领团队建立的科技情报大数据挖掘与服务系统平台)的学术社交网络数据集作为实验数据,在ubuntu18.04环境下分别测试了本发明提出的模型,该模型的变体以及其它基线模型。
本发明的变体包括以下3中:
变体1:步骤3中对两个通道训练结果的结合不使用注意力机制,直接将两个训练结果向量进行连接。
变体2:使用单通道,只对结构信息进行训练。
变体3:使用单通道,只对内容信息进行训练。
与本发明进行对比的基线包括:
metapath2vec.apvpa:设定元路径a-p-v-p-a,使用异构信息网络表示学习模型metapath2vec++对节点进行嵌入,根据向量相似度来度量两个作者类型节点的相似度,从而进行top-k相似性搜索。
metapath2vec.apa:设定元路径a-p-a,使用异构信息网络表示学习模型metapath2vec++对节点进行嵌入,从而进行top-k相似性搜索。
doc2vec:利用对作者的文本描述信息进行节点嵌入,根据向量相似度来度量两个作者类型节点的相似度,从而进行top-k相似性搜索。
2.实验结果分析
挑选十名学术社交网络上活跃的权威作者,对其进行相似作者的标注,并进行这十名作者的top-10相似度搜索。通过将发明的模型与其变体模型和基线模型进行比较来进行对发明结果的评估。实验测试了准确率和ndcg(normalizeddiscountedcumulativegain,归一化折损累计增益),结果如下表格。
模型准确率和ndcg值的比较:
根据表中的结果,发明的模型的准确率和ndcg值均由于其他对比模型。
其中发明模型的性能优于变体1,说明在内容和结构之间使用注意力机制有利于提高模型性能。变体1优于变体2和变体3,表明全面考虑内容信息和结构信息非常重要。发明的模型及其变体的性能均优于基线,这表明模型考虑多个元路径以获取丰富的节点间语义信息是非常合理的。此外,doc2vec性能最差的主要原因是此数据集中的辅助结构信息丰富,而文本描述信息相对不足。
接下来,我们改变top-k相似性搜索中k的值,以评估其对模型及对比模型ndcg的影响,结果如图9所示。
图9的图例中的model是我们发明的模型,v1(variant1)指变体1,v2(variant2)指变体2,v3(variant3)指变体3。
实验结果表明,对于所有模型,随着k值增大,ndcg值趋于增加状态,且发明的模型始终可实现最佳性能。而且在大多数情况下,发明模型及变体1(考虑内容信息和结构信息)的ndcg准确性比其他仅考虑单节点信息的方法要高。此外,doc2vec模型的搜索性能最差,主要是因为我们使用的学术社交网络中节点的结构信息丰富,而内容信息相对稀缺。因此,不考虑内容信息的变体2也具有相对较好的性能是非常合理的。由于仅考虑一个元路径,因此metapath2vec.apvpa和metapath2vec.apa的搜索性能相对较低,仅优于doc2vec。