一种基于端到端关系网络的视觉SLAM闭环检测方法与流程
本发明属于定位与地图技术领域,具体涉及一种基于端到端关系网络的视觉slam闭环检测方法。
背景技术:
闭环检测在计算机视觉领域常被称为位置识别,对整个slam系统意义重大。闭环检测的目的是识别机器人当前所处的位置是否是先前访问过的位置。在移动机器人的定位和建图中,通过相邻帧间的图像来估计轨迹并恢复空间结构,不可避免地存在累积漂移。闭环检测通过正确检测“机器人回到曾经位置”这件事情,可以显著减少累积误差,对构建一致的环境地图非常重要。此外,闭环检测由于关联了历史信息,当机器人由于突然运动、严重遮挡或运动模糊导致跟踪失败时,可以利用闭环检测进行重新定位。因此,闭环检测在提高整个slam系统地鲁棒性和有效性方面发挥着至关重要的作用。
技术实现要素:
本发明的目的是为了解决现有闭环检测方法中相似性度量受限于特征提取难以提高检测精度的问题,提出了一种基于端到端关系网络的视觉slam闭环检测方法。
本发明的技术方案是:一种基于端到端关系网络的视觉slam闭环检测方法,包括以下步骤:
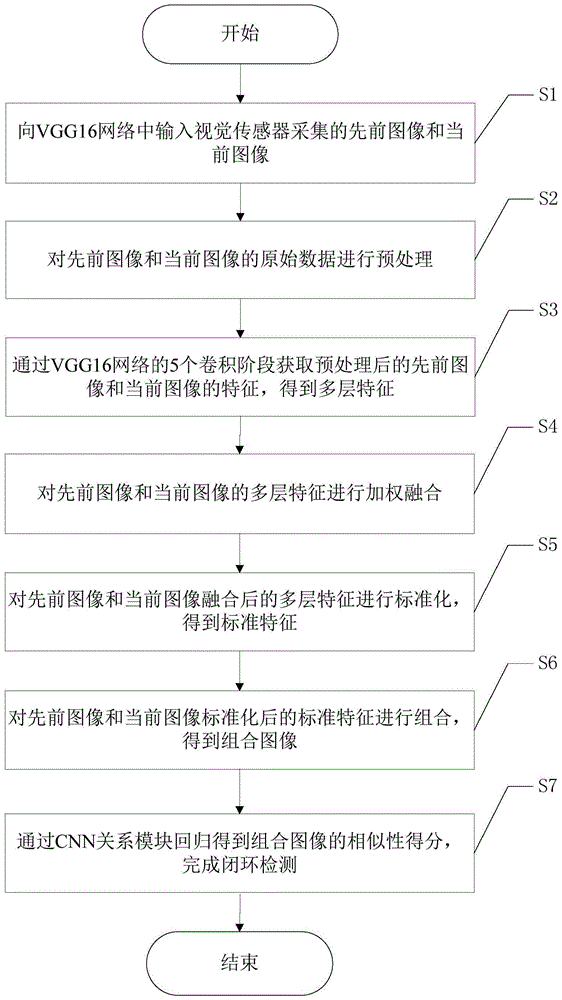
s1:向vgg16网络中输入视觉传感器采集的先前图像和当前图像;
s2:对先前图像和当前图像的原始数据进行预处理;
s3:通过vgg16网络的5个卷积阶段获取预处理后的先前图像和当前图像的特征,得到多层特征;
s4:对先前图像和当前图像的多层特征进行加权融合;
s5:对先前图像和当前图像融合后的多层特征进行标准化,得到标准特征;
s6:对先前图像和当前图像标准化后的标准特征进行组合,得到组合图像;
s7:通过cnn关系模块回归得到组合图像的相似性得分,完成闭环检测。
本发明的有益效果是:本发明提供了一种基于端到端关系网络的视觉slam闭环检测方法。与现有的基于深度学习的闭环检测方法相比,本发明的加权融合来自不同中间层的不同尺度的特征,并可以自动学习其重要性。融合后的特征不仅保持了一定的不变性,而且包含更多的高层语义信息,更有效地克服感知偏差和感知变异,在统一的框架内将特征提取与相似性度量联合起来,将原始图片数据送入网络可以直接从像素点度量两个图像的相似性,避免学习冗余特征,使得学习到的特征更加适应相似性度量要求的可区分性,可以更加准确地检测闭环并节省检测时间,提高闭环检测地精度。
进一步地,步骤s2包括以下子步骤:
s21:调整先前图像和当前图像的尺寸为224×224;
s22:将调整大小后的先前图像和当前图像转换为224×224×3的张量;
s23:对转换张量后的先前图像和当前图像进行标准化操作,完成对先前图像和当前图像的原始数据预处理。
上述进一步方案的有益效果是:在本发明中,对先前图像和当前图像的原始数据进行预处理可满足卷积神经网络对输入数据的尺度要求。
进一步地,步骤s23中,标准化操作的公式为
上述进一步方案的有益效果是:在本发明中,对每张图片采取标准化操作,便于后续步骤实施。
进一步地,步骤s3包括以下子步骤:
s31:对vgg16网络的5个卷积阶段进行结构划分:第一卷积阶段和第二卷积阶段均采用卷积+卷积+池化的结构;第三卷积阶段、第四卷积阶段和第五卷积阶段均采用卷积+卷积+卷积+池化的结构;
s32:通过不同的卷积阶段对预处理后的先前图像和当前图像数据提取特征,得到基本特征,其基本特征提取公式为
s33:通过池化对基本特征进行压缩,得到多层特征,其压缩公式为
上述进一步方案的有益效果是:在本发明中,对图像提取基本特征并且压缩,可去除冗余信息,并增加了基本特征的平移不变性。
进一步地,步骤s31中,vgg16网络的5个卷积阶段的卷积核尺寸均为3×3,卷积核数量分别为64、128、256、512和512,池化层均采用最大池化,池化核的尺寸均为2×2。
上述进一步方案的有益效果是:在本发明中,针对不同的卷积阶段定义不同的卷积核数量,并规定其尺寸,使得检测方法准确简洁。
进一步地,步骤s4包括以下子步骤:
s41:通过vgg16网络将第三卷积阶段、第四卷积阶段和第五卷积阶的最后一层卷积层定义为conv3_3、conv4_3和conv5_3;
s42:转换conv3_3、conv4_3和conv5_3的尺寸为28×28×256;
s43:对相同大小的conv3_3、conv4_3和conv5_3进行加权融合;其加权融合公式为
上述进一步方案的有益效果是:在本发明中,对最后三个卷积阶段进行加权融合,可以更好地表达图像。
进一步地,步骤s5中,标准化公式为
上述进一步方案的有益效果是:在本发明中,步骤s5中的标准化公式便于处理图像的标准化过程,使用公式快速。
进一步地,步骤s6包括以下子步骤:
s61:转换标准特征f_std1和f_std2的尺寸为256×784,调整其尺寸为448×448;
s62:根据vgg16网络的深度将当前图像和先前时刻图像的标准特征拼接,得到组合图像fcom,其尺寸为448×448×2,并将其作为关系模块的输入,完成先前图像和当前图像标准化后的标准特征组合。
上述进一步方案的有益效果是:在本发明中,根据深度完成图像的拼接,并作为关系模块的输入,便于回归得到图像的相似性得分。
进一步地,步骤s7包括以下子步骤:
s71:设置组合后图像的阈值;
s72:通过relu(·)函数提取fcom中的特征;
s73:根据fcom中的特征,采用sigmoid(·)函数输出组合后图像的相似性得分;
s74:通过比较阈值数值和相似性得分数值的大小,若比较阈值数值大于相似性得分数值,则未发生闭环;若比较阈值数值小于相似性得分数值,则发生闭环;完成闭环检测。
上述进一步方案的有益效果是:在本发明中,根据相似性得分判断是否大于阈值。若相似性得分大于阈值,则发生闭环;若相似性得分小于阈值,则未发生闭环。
附图说明
图1为基于端到端关系网络的视觉slam闭环检测方法的步骤图;
图2为步骤s2的子步骤图;
图3为步骤s3的子步骤图;
图4为步骤s4的子步骤图;
图5为步骤s6的子步骤图;
图6为步骤s7的子步骤图;
图7为实施例的模块示意图;
图8为实施例的加权融合示意图;
图9为实施例的标准特征组合示意图;
图10为实施例的关系模块比较示意图。
具体实施方式
下面结合附图对本发明的实施例作进一步的说明。
如图1所示,本发明提供了一种基于端到端关系网络的视觉slam闭环检测方法,包括以下步骤:
s1:向vgg16网络中输入视觉传感器采集的先前图像和当前图像;
s2:对先前图像和当前图像的原始数据进行预处理;
s3:通过vgg16网络的5个卷积阶段获取预处理后的先前图像和当前图像的特征,得到多层特征;
s4:对先前图像和当前图像的多层特征进行加权融合;
s5:对先前图像和当前图像融合后的多层特征进行标准化,得到标准特征;
s6:对先前图像和当前图像标准化后的标准特征进行组合,得到组合图像;
s7:通过cnn关系模块回归得到组合图像的相似性得分,完成闭环检测。
在本发明实施例中,如图2所示,步骤s2包括以下子步骤:
s21:调整先前图像和当前图像的尺寸为224×224;
s22:将调整大小后的先前图像和当前图像转换为224×224×3的张量;
s23:对转换张量后的先前图像和当前图像进行标准化操作,完成对先前图像和当前图像的原始数据预处理。
在本发明中,对先前图像和当前图像的原始数据进行预处理可满足卷积神经网络对输入数据的尺度要求。
在本发明实施例中,如图2所示,步骤s23中,标准化操作的公式为
在本发明中,对每张图片采取标准化操作,便于后续步骤实施。
在本发明实施例中,如图3所示,步骤s3包括以下子步骤:
s31:对vgg16网络的5个卷积阶段进行结构划分:第一卷积阶段和第二卷积阶段均采用卷积+卷积+池化的结构;第三卷积阶段、第四卷积阶段和第五卷积阶段均采用卷积+卷积+卷积+池化的结构;
s32:通过不同的卷积阶段对预处理后的先前图像和当前图像数据提取特征,得到基本特征,其基本特征提取公式为
s33:通过池化对基本特征进行压缩,得到多层特征,其压缩公式为
在本发明中,对图像提取基本特征并且压缩,可去除冗余信息,并增加了基本特征的平移不变性。
在本发明实施例中,如图3所示,步骤s31中,vgg16网络的5个卷积阶段的卷积核尺寸均为3×3,卷积核数量分别为64、128、256、512和512,池化层均采用最大池化,池化核的尺寸均为2×2。在本发明中,针对不同的卷积阶段定义不同的卷积核数量,并规定其尺寸,使得检测方法准确简洁。
在本发明实施例中,如图4所示,步骤s4包括以下子步骤:
s41:通过vgg16网络将第三卷积阶段、第四卷积阶段和第五卷积阶的最后一层卷积层定义为conv3_3、conv4_3和conv5_3;
s42:转换conv3_3、conv4_3和conv5_3的尺寸为28×28×256;
s43:对相同大小的conv3_3、conv4_3和conv5_3进行加权融合;其加权融合公式为
在本发明中,对最后三个卷积阶段进行加权融合,可以更好地表达图像。
在本发明实施例中,如图1所示,步骤s5中,标准化公式为
在本发明中,步骤s5中的标准化公式便于处理图像的标准化过程,使用公式快速。
在本发明实施例中,如图5所示,步骤s6包括以下子步骤:
s61:转换标准特征f_std1和f_std2的尺寸为256×784,调整其尺寸为448×448;
s62:根据vgg16网络的深度将当前图像和先前时刻图像的标准特征拼接,得到组合图像fcom,其尺寸为448×448×2,并将其作为关系模块的输入,完成先前图像和当前图像标准化后的标准特征组合。
在本发明中,根据深度完成图像的拼接,并作为关系模块的输入,便于回归得到图像的相似性得分。并且为了适应网络训练习惯调整其尺寸为448×448。
在本发明实施例中,如图6所示,步骤s7包括以下子步骤:
s71:设置组合后图像的阈值;
s72:通过relu(·)函数提取fcom中的特征;
s73:根据fcom中的特征,采用sigmoid(·)函数输出组合后图像的相似性得分;
s74:通过比较阈值数值和相似性得分数值的大小,若比较阈值数值大于相似性得分数值,则未发生闭环;若比较阈值数值小于相似性得分数值,则发生闭环;完成闭环检测。
以具体的图像为例,如图7所示,网络结构是双分支的,主要包括四个模块:特征提取模块、特征融合模块、特征组合模块、关系模块。采用图片对作为网络的输入数据,通过网络直接输出闭环检测的结果。这保证了特征提取和相似性度量的有效性,同时加快了闭环检测的速度。如图8所示,对先前图像和当前图像进行加权融合。如图9所示,对先前图像和当前图像标准化后的标准特征进行组合。如图10所示,关系模块包含三层卷积层和两层全连接层。三层卷积层分别采用大小为7×7、5×5和3×3的卷积核,卷积核的数量均为16,采用relu(·)作为激活函数进行非线性映射。每层卷积后面包括批量归一化和最大池化层,池化核大小为2×2,进一步提取fcom中蕴含的特征。第一层全连接层包含100个神经元,采用relu(·)作为激活函数,对卷积层的输出进行加权求和整合出更加抽象的数据特征。第二层全连接层只包含一个神经元,采用sigmoid(·)作为激活函数,输出为两张图片的相似性得分。通过设置合适的阈值,当相似性得分大于阈值时,则认为发生了闭环,小于阈值时,则认为不是闭环。在本实施例中,阈值设为0.5。
本发明的工作原理及过程为:本发明提供了一种简单有效的基于端到端关系网络的闭环检测方法。首先对先前图像和当前图像的数据进行预处理,利用vgg16网络分别提取当前图像和先前时刻图像的特征。再分别对两个图像的多层特征进行加权融合,组合两个图像的特征,利用cnn构成的关系模块回归得到两张图像的相似性得分,并决定是否是闭环。
本发明的有益效果为:本发明提供了一种基于端到端关系网络的视觉slam闭环检测方法。与现有的基于深度学习的闭环检测方法相比,本发明的加权融合来自不同中间层的不同尺度的特征,并可以自动学习其重要性。融合后的特征不仅保持了一定的不变性,而且包含更多的高层语义信息,更有效地克服感知偏差和感知变异,在统一的框架内将特征提取与相似性度量联合起来,将原始图片数据送入网络可以直接从像素点度量两个图像的相似性,避免学习冗余特征,使得学习到的特征更加适应相似性度量要求的可区分性,可以更加准确地检测闭环并节省检测时间,提高闭环检测地精度。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!