用户类别识别模型的训练方法和用户类别识别方法与流程
【技术领域】
本说明书涉及数据处理技术领域,尤其涉及一种用户类别识别模型的训练方法和用户类别识别方法。
背景技术:
随着移动互联网技术的发展,在手机等移动终端上运行的移动应用,极大地方便了人们的生活。由于移动终端的用户基本保持不变,因此可以对移动应用进行个性化设置,使得移动应用满足用户的个性化需求。
为了让移动应用能够满足用户的个性化需求,需要先确定用户的类别,再根据用户的类别进行相应的设置。但是对于新用户来说,移动应用无法获取用户的历史信息,使得用于分析用户类别的信息不充分,不能确定用户的类别。
相关技术中,通过获取用户的联系人信息,来分析该用户的社会关系,进而确定用户的类别,准确度不高。因此,亟需一种能够在用户信息不充分的情况下,对用户类别进行准确识别的技术方案。
技术实现要素:
本说明书实施例旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本说明书实施例的第一个目的在于提出一种用户类别识别模型的训练方法,使得训练完的用户类别识别模型能够在用户信息不充分的情况下,基于待识别用户的联系人列表和对应的软件特征,实现用户类别识别。
本说明书实施例的第二个目的在于提出一种用户类别识别方法。
本说明书实施例的第三个目的在于提出一种用户类别识别模型的训练装置。
本说明书实施例的第四个目的在于提出一种用户类别识别装置。
本说明书实施例的第五个目的在于提出一种计算机设备。
本说明书实施例的第六个目的在于提出一种计算机设备。
本说明书实施例的第七个目的在于提出一种非临时性计算机可读存储介质。
本说明书实施例的第八个目的在于提出一种非临时性计算机可读存储介质。
为达上述目的,本说明书实施例第一方面实施例提出了一种用户类别识别模型的训练方法,包括:获取样本用户的常用软件列表和联系人列表,以及类别标签;获取所述样本用户的常用软件列表中每个常用软件对应的软件特征;将所述样本用户的联系人列表输入所述用户类别计算模型,以生成所述样本用户属于预设类别的概率;将所述样本用户对应的软件特征,和所述样本用户属于预设类别的概率,输入用户类别识别模型,以生成所述样本用户的识别结果;其中,所述用户类别识别模型包括图神经网络和注意力神经网络;根据所述样本用户的识别结果和所述样本用户的类别标签,对所述用户类别识别模型中的参数,以及所述样本用户的常用软件列表中每个常用软件对应的软件特征进行优化;以及当满足预设条件时,完成对所述用户类别识别模型的训练。
和现有技术相比,本说明书实施例基于待识别用户的联系人列表和对应的软件特征,来对用户类别进行识别,能够在用户信息不充分的情况下,实现对待识别用户类别的准确识别。
另外,本说明书实施例的用户类别识别模型的训练方法,还具有如下附加的技术特征:
可选地,所述将所述样本用户对应的软件特征,和所述样本用户属于预设类别的概率,输入所述用户类别识别模型,以生成所述样本用户的识别结果,包括:将所述样本用户对应的软件特征输入所述注意力神经网络;其中,所述注意力神经网络用于确定所述常用软件列表中每个常用软件的影响度;基于所述样本用户对应的软件特征,和所述常用软件列表中每个常用软件的影响度,确定所述样本用户的用户特征;根据所述样本用户的用户特征,以及所述样本用户属于预设类别的概率,生成所述样本用户的识别结果。
可选地,所述根据所述样本用户的识别结果和所述样本用户的类别标签,对所述用户类别识别模型中的参数,以及所述样本用户的常用软件列表中每个常用软件对应的软件特征进行优化,包括:根据所述样本用户的类别标签和所述样本用户属于预设类别的概率,生成所述用户类别计算模型的计算误差;根据所述样本用户的类别标签和所述样本用户的识别结果,生成所述用户类别识别模型的识别误差;基于所述用户类别计算模型的计算误差,对所述用户类别识别模型的识别误差进行加权处理;根据加权处理后的所述识别误差,对所述用户类别识别模型中的参数,以及所述样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
可选地,所述将所述样本用户的联系人列表输入所述用户类别计算模型,以生成所述样本用户属于预设类别的概率,包括:根据全部所述样本用户的联系人列表,生成所述样本用户的关系网络;其中,所述关系网络包括多个节点,每个所述节点与所述样本用户相对应;对所述样本用户的关系网络进行无监督学习处理,以确定每个所述样本用户对应的所述图节点的图特征;将所述样本用户对应的所述图节点的图特征输入分类器,以生成所述样本用户属于预设类别的概率。
可选地,所述用户类别计算模型为逾期风险计算模型,所述逾期风险计算模型通过所述联系人列表,计算所述样本用户为逾期用户的概率,所述用户类别识别模型为逾期风险预测模型,所述逾期风险预测模型通过所述软件特征和所述样本用户为逾期用户的概率,确定所述样本用户的逾期风险。
本说明书实施例第二方面实施例提出了一种用户类别识别方法,包括:获取待识别用户的常用软件列表和联系人列表;获取所述待识别用户的常用软件列表中每个常用软件对应的软件特征;将所述待识别用户的联系人列表输入用户类别计算模型,以生成所述待识别用户属于预设类别的概率;将所述待识别用户对应的软件特征,和所述待识别用户属于预设类别的概率,输入如前述训练方法训练完的用户类别识别模型中;以及根据所述用户类别识别模型的输出,对所述待识别用户进行识别。
另外,本说明书实施例的用户类别识别方法,还具有如下附加的技术特征:
可选地,所述用户类别计算模型为逾期风险计算模型,所述逾期风险计算模型通过所述联系人列表,计算所述待识别用户为逾期用户的概率,所述用户类别识别模型为逾期风险预测模型,所述逾期风险预测模型通过所述软件特征和所述待识别用户为逾期用户的概率,确定所述待识别用户的逾期风险。
本说明书实施例第三方面实施例提出了一种用户类别识别模型的训练装置,包括:第一获取模块,用于获取样本用户的常用软件列表和联系人列表,以及类别标签;第二获取模块,用于获取所述样本用户的常用软件列表中每个常用软件对应的软件特征;第一输入模块,用于将所述样本用户的联系人列表输入所述用户类别计算模型,以生成所述样本用户属于预设类别的概率;第二输入模块,用于将所述样本用户对应的软件特征,和所述样本用户属于预设类别的概率,输入用户类别识别模型,以生成所述样本用户的识别结果;其中,所述用户类别识别模型包括图神经网络和注意力神经网络;优化模块,用于根据所述样本用户的识别结果和所述样本用户的类别标签,对所述用户类别识别模型中的参数,以及所述样本用户的常用软件列表中每个常用软件对应的软件特征进行优化;以及训练模块,用于当满足预设条件时,完成对所述用户类别识别模型的训练。
另外,本说明书实施例的用户类别识别模型的训练装置,还具有如下附加的技术特征:
可选地,所述第二输入模块,包括:第一输入子模块,用于将所述样本用户对应的软件特征输入所述注意力神经网络;其中,所述注意力神经网络用于确定所述常用软件列表中每个常用软件的影响度;确定子模块,用于基于所述样本用户对应的软件特征,和所述常用软件列表中每个常用软件的影响度,确定所述样本用户的用户特征;第一生成子模块,用于根据所述样本用户的用户特征,以及所述样本用户属于预设类别的概率,生成所述样本用户的识别结果。
可选地,所述优化模块,包括:第二生成子模块,用于根据所述样本用户的类别标签和所述样本用户属于预设类别的概率,生成所述用户类别计算模型的计算误差;第三生成子模块,用于根据所述样本用户的类别标签和所述样本用户的识别结果,生成所述用户类别识别模型的识别误差;第一处理子模块,用于基于所述用户类别计算模型的计算误差,对所述用户类别识别模型的识别误差进行加权处理;优化子模块,用于根据加权处理后的所述识别误差,对所述用户类别识别模型中的参数,以及所述样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
可选地,所述第一输入模块,包括:第四生成子模块,用于根据全部所述样本用户的联系人列表,生成所述样本用户的关系网络;其中,所述关系网络包括多个节点,每个所述节点与所述样本用户相对应;第二处理子模块,用于对所述样本用户的关系网络进行无监督学习处理,以确定每个所述样本用户对应的所述图节点的图特征;第二输入子模块,用于将所述样本用户对应的所述图节点的图特征输入分类器,生成所述样本用户属于预设类别的概率。
可选地,所述用户类别计算模型为逾期风险计算模型,所述逾期风险计算模型通过所述联系人列表,计算所述样本用户为逾期用户的概率,所述用户类别识别模型为逾期风险预测模型,所述逾期风险预测模型通过所述软件特征和所述样本用户为逾期用户的概率,确定所述样本用户的逾期风险。
本说明书实施例第四方面实施例提出了一种用户类别识别装置,包括:第三获取模块,用于获取待识别用户的常用软件列表和联系人列表;第四获取模块,用于获取所述待识别用户的常用软件列表中每个常用软件对应的软件特征;第三输入模块,用于将所述待识别用户的联系人列表输入用户类别计算模型,以生成所述待识别用户属于预设类别的概率;第四输入模块,用于将所述待识别用户对应的软件特征,和所述待识别用户属于预设类别的概率,输入如前述训练装置训练完的用户类别识别模型中;以及识别模块,用于根据所述用户类别识别模型的输出,对所述待识别用户进行识别。
另外,本说明书实施例的用户类别识别装置,还具有如下附加的技术特征:
可选地,所述用户类别计算模型为逾期风险计算模型,所述逾期风险计算模型通过所述联系人列表,计算所述待识别用户为逾期用户的概率,所述用户类别识别模型为逾期风险预测模型,所述逾期风险预测模型通过所述软件特征和所述待识别用户为逾期用户的概率,确定所述待识别用户的逾期风险。
本说明书实施例第五方面实施例提出了一种计算机设备,包括存储器和处理器;所述存储器上存储有可由处理器运行的计算机程序;所述处理器运行所述计算机程序时,执行如前述方法实施例所述的用户类别识别模型的训练方法。
本说明书实施例第六方面实施例提出了一种计算机设备,包括存储器和处理器;所述存储器上存储有可由处理器运行的计算机程序;所述处理器运行所述计算机程序时,执行如前述方法实施例所述的用户类别识别方法。
本说明书实施例第七方面实施例提出了一种非临时性计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如前述方法实施例所述的用户类别识别模型的训练方法。
本说明书实施例第八方面实施例提出了一种非临时性计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如前述方法实施例所述的用户类别识别方法。
本说明书实施例附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本说明书实施例的实践了解到。
【附图说明】
为了更清楚地说明本说明书实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。
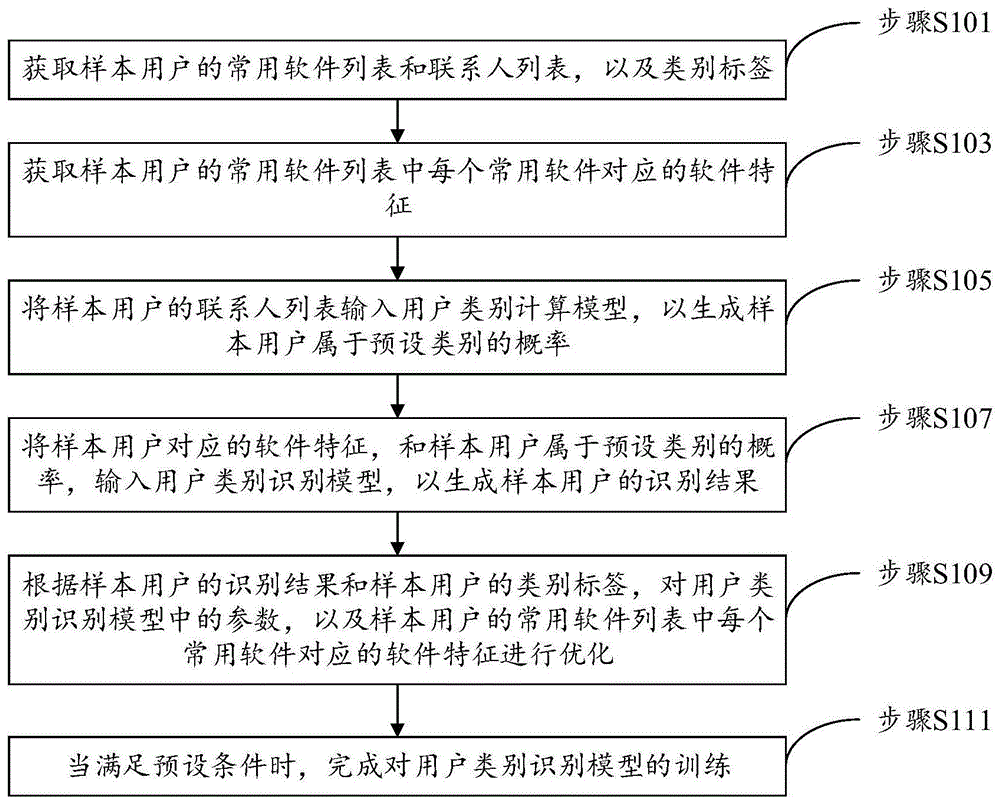
图1为本说明书实施例所提出的一种用户类别识别模型的训练方法的流程示意图;
图2为本说明书实施例所提供的样本用户和常用软件的关系示意图;
图3为本说明书实施例所提出的另一种用户类别识别模型的训练方法的流程示意图;
图4为本说明书实施例所提出的又一种用户类别识别模型的训练方法的流程示意图;
图5为本说明书实施例所提出的用户类别识别模型的训练方法的一个示例的流程图;
图6为本说明书实施例所提出的一种用户类别识别方法的流程示意图;
图7为本说明书实施例所提出的另一种用户类别识别方法的流程示意图;
图8为本说明书实施例所提出的用户类别识别方法的一个示例的流程图;
图9为本说明书实施例所提出的一种用户类别识别模型的训练装置的结构示意图;
图10为本说明书实施例所提出的另一种用户类别识别模型的训练装置的结构示意图;
图11为本说明书实施例所提出的又一种用户类别识别模型的训练装置的结构示意图;
图12为本说明书实施例所提出的一种用户类别识别装置的结构示意图;以及
图13为本说明书实施例所提出的另一种用户类别识别装置的结构示意图。
【具体实施方式】
下面详细描述本说明书的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过样本附图描述的实施例是示例性的,旨在用于解释本说明书实施例,而不能理解为对本说明书实施例的限制。
下面样本附图描述本说明书实施例的用户类别识别模型的训练方法和用户类别识别方法。
基于上述现有技术的描述可以知道,相关技术中,通过获取用户的联系人信息,来分析该用户的社会关系,进而确定用户的类别,准确度不高。
针对这一问题,本说明书实施例提出了一种用户类别识别模型的训练方法,使得训练完的用户类别识别模型能够在用户信息不充分的情况下,基于待识别用户的联系人列表和对应的软件特征,来对用户类别进行准确识别。
图1为本说明书实施例所提出的一种用户类别识别模型的训练方法的流程示意图。如图1所示,该方法包括以下步骤:
步骤s101,获取样本用户的常用软件列表和联系人列表,以及类别标签。
其中,样本用户是已经确定了类别的用户,样本用户的类别通过类别标签进行标记。
常用软件是指用户在最近一段时间内使用过的软件,比如将最近5个月内用户使用过的全部软件进行罗列,即可生成常用软件列表。
需要说明的是,为了对用户类别识别模型进行训练,以及对用户类别计算模型的准确度进行测试,可以获取样本用户过去10个月使用过的软件,并将后5个月使用过的软件作为训练数据,列入常用软件列表,将前5个月使用过的软件作为测试数据,用于检测用户类别识别模型的准确度。
联系人列表可以是通过抓取用户的通讯录中的信息生成,又可以是通过抓取用户的通话记录后生成,也可以是通过抓取用户的社交软件中的好友信息生成,还可以是通过上述多种方式生成。
需要说明的是,样本用户的数量可以为多个,而不同样本用户的常用软件列表中的常用软件可能存在重复。图2为本说明书实施例所提供的样本用户和常用软件的关系示意图。如图2所示,样本用户有用户a、b、c、d和e,用户a的常用软件列表中包括有常用软件1、2和5,用户b的常用软件列表中包括有常用软件1、2和3,用户c的常用软件列表中包括有常用软件3、4和5,用户d的常用软件列表中包括有常用软件1,用户e的常用软件列表中包括有常用软件2和5,将所有样本用户的常用软件列表中的常用软件进行统计,得到常用软件总表。
步骤s103,获取样本用户的常用软件列表中每个常用软件对应的软件特征。
其中,常用软件对应的软件特征以软件特征向量的形式存在。
应当理解,对于用户类别识别模型来说,影响识别准确度的因素有两个,一个是用户类别识别模型的参数,另一个是用户类别识别模型的输入特征。
因此,本说明书实施例所提出的用户类别识别模型的训练方法在训练过程中,同时对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化,也就是对软件特征向量的数值进行优化。
具体来说,在训练开始时,随机生成每个常用软件的初始化软件特征向量,在用户类别识别模型的训练过程中,不断对软件特征向量中的数值进行优化,当用户类别识别模型的训练完成后,将优化后的软件特征向量进行存储,并与常用软件进行对应。
在对待识别用户进行用户类别识别时,针对待识别用户的常用软件列表中的每个常用软件,从存储区域获取对应的软件特征向量。
步骤s105,将样本用户的联系人列表输入用户类别计算模型,以生成样本用户属于预设类别的概率。
可以理解,通过样本用户的联系人列表,可以确定样本用户的社会关系,通过对社会关系的分析,可以计算出样本用户属于预设类别的概率。
需要说明的是,此处计算得到的样本用户属于预设类别的概率是基于样本用户的联系人列表计算生成的,数据源单一,是对联系人列表这一类别的数据进行深入分析后生成的结果,能够作为综合识别样本用户的类别的重要样本数据。因此,可以将其作为用户类别识别模型的输入数据。
可以理解,在样本用户的联系人列表不发生变化的情况下,生成的样本用户属于预设类别的概率不变。因此只需在训练开始时生成样本用户属于预设类别的概率,在下一次训练过程中无需再次计算样本用户属于预设类别的概率。
步骤s107,将样本用户对应的软件特征,和样本用户属于预设类别的概率,输入用户类别识别模型,以生成样本用户的识别结果。
其中,用户类别识别模型包括图神经网络和注意力神经网络。
步骤s109,根据样本用户的识别结果和样本用户的类别标签,对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
应当理解,训练开始时,随机生成每个常用软件的初始化软件特征向量,此时样本用户获取对应常用软件的软件特征为初始化软件特征向量,在步骤s109,对样本用户的常用软件列表中每个常用软件对应的软件特征进行优化之后,将优化后的软件特征向量作为下一次训练过程开始时的软件特征向量。也就是说,随着训练的不断进行,软件特征向量中的数值不断优化,直到训练结束。
可以理解,当样本用户为多个时,一个样本用户对应于多个软件特征向量,一个软件特征向量也对应于多个样本用户。在训练过程中,与软件特征向量对应的每个样本用户的识别结果和类别标签,都会对该软件特征向量的优化产生影响。
步骤s111,当满足预设条件时,完成对用户类别识别模型的训练。
具体地,可以是当用户类别识别模型对全部训练数据进行处理后,完成对用户类别识别模型的训练,也可以是当用户类别识别模型的参数优化次数达到预设次数,完成对用户类别识别模型的训练,本说明书实施例对此不做限定。
综上所述,本说明书实施例所提出的一种用户类别识别模型的训练方法,将样本用户的联系人列表输入用户类别计算模型,以生成样本用户属于预设类别的概率。将样本用户对应的软件特征,和样本用户属于预设类别的概率,输入用户类别识别模型,以生成样本用户的识别结果。根据样本用户的识别结果和样本用户的类别标签,对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。当满足预设条件时,完成对用户类别识别模型的训练。由此,使得训练完的用户类别识别模型能够在用户信息不充分的情况下,基于待识别用户的联系人列表和对应的软件特征,来对用户类别进行准确识别。
为了能够提升用户类别识别模型的识别准确度,本说明书实施例还提出了另一种用户类别识别模型的训练方法,图3为本说明书实施例所提出的另一种用户类别识别模型的训练方法的流程示意图。如图3所示,该方法包括以下步骤:
步骤s201,获取样本用户的常用软件列表和联系人列表,以及类别标签。
步骤s203,获取样本用户的常用软件列表中每个常用软件对应的软件特征。
步骤s205,根据全部样本用户的联系人列表,生成样本用户的关系网络。
其中,关系网络包括多个节点,每个节点与样本用户相对应。
需要说明的是,本说明书实施例需要根据样本用户的社交关系,来确定用户属于预设类别的概率。当样本用户的联系人列表中包括其他的样本用户时,该样本用户即与其他的样本用户之间建立了社交关系,进一步地,可以根据全部样本用户的联系人列表,生成样本用户的关系网络。
步骤s207,对样本用户的关系网络进行无监督学习处理,以确定每个样本用户对应的图节点的图特征。
其中,无监督学习是一种根据类别未知的训练样本实现机器学习的技术方案,即通过对样本用户的关系网络进行分析,对关系网络中的图节点进行自学习,确定每个图节点的图特征。
步骤s209,将样本用户对应的图节点的图特征输入分类器,以生成样本用户属于预设类别的概率。
需要说明的是,本说明书实施例中的样本用户是用于训练用户类别识别模型的训练数据,而本说明书实施例中的分类器是已经训练好的分类器,因此将样本用户对应的图节点的图特征根据图节点的图特征,生成样本用户属于预设类别的概率。进而使用样本用户属于预设类别的概率,来对用户类别识别模型进行训练。
对于分类器的训练,可以预先通过样本图特征和对应的类别标签进行,属于分类器的训练方案,与本说明书中用户类别识别模型的训练方法关系不大,本说明书实施例对此不再赘述。
步骤s211,将样本用户对应的软件特征输入注意力神经网络。
其中,注意力神经网络用于确定常用软件列表中每个常用软件的影响度。
具体地,本说明书实施例所提出的用户类别识别模型中的注意力神经网络包括输入层,隐藏层和输出层,将样本用户的常用软件列表中的每个常用软件对应的软件特征向量输入输入层,经过加权处理后进入隐藏层,使用softmax逻辑回归模型生成每个常用软件的影响度,具体可以用以下公式生成:影响度=softmax(软件特征向量·权值),那么常用软件列表中所有常用软件的影响度可以形成影响度向量。
需要说明的是,训练开始时,注意力神经网络中的权值为随机初始化值,在步骤s223,对用户类别识别模型中的参数进行优化之后,对注意力神经网络中的权值进行更新,在下一次训练过程中,对使用更新后权值进行计算,进而使用softmax逻辑回归模型生成样本用户的影响度,样本用户的影响度以影响度向量的形式存在。
基于前述说明,可以知道,本说明书实施例所提出的用户类别识别模型包括注意力神经网络和图神经网络。图神经网络的输入包括每个常用软件对应的软件特征向量和注意力神经网络生成的影响度向量,以及样本用户属于预设类别的概率,后续的步骤s213和步骤s215由图神经网络实现。
步骤s213,基于样本用户对应的软件特征,和常用软件列表中每个常用软件的影响度,确定样本用户的用户特征。
具体地,将样本用户的影响度向量和每个常用软件对应的软件特征向量,以及样本用户的逾期概率输入图神经网络,软件特征向量与影响度向量结合,可以生成样本用户的用户特征向量。具体可以用以下公式生成:用户特征向量=∑(软件特征向量*影响力向量)。
步骤s215,根据样本用户的用户特征,以及样本用户属于预设类别的概率,生成样本用户的识别结果。
具体地,将样本用户属于预设类别的概率作为一维特征拼接到用户特征向量后,经过多层非线性映射后进行合并,可以得到融合的特征向量,使用softmax归一化指数函数对融合的特征向量进行分类,能够确定样本用户的识别结果。
需要说明的是,softmax归一化指数函数包括全连接层和分类层,将融合的特征向量输入全连接层,分类层生成不同结果对应的概率,根据概率大小确定样本用户的识别结果。
步骤s217,根据样本用户的类别标签和样本用户属于预设类别的概率,生成用户类别计算模型的计算误差。
可以理解,样本用户属于预设类别的概率是将样本用户的联系人列表输入用户类别计算模型后生成的,用户属于预设类别的概率和类别标签的差值,就是用户类别计算模型与实际情况的计算误差,计算误差越大,说明对于该样本用户,用户类别计算模型的计算准确度越低,在用户类别识别模型的训练过程中,需要重点关注该样本用户,以提升用户类别识别模型的识别准确度。
步骤s219,根据样本用户的类别标签和样本用户的识别结果,生成用户类别识别模型的识别误差。
步骤s221,基于用户类别计算模型的计算误差,对用户类别识别模型的识别误差进行加权处理。
可以理解,样本用户对应的用户类别计算模型的计算误差越大,在模型训练中越需要关注该样本用户。因此,可以基于用户类别计算模型的计算误差确定对应的权值,对该样本用户对应的用户类别识别模型的识别误差进行加权处理,以提升计算误差较大的样本用户对模型训练的影响,减小计算误差较小的样本用户对模型训练的影响。
为了减少加权处理的计算量,一种可能的实现方式是,可以对样本用户按照计算误差的数值大小进行分组,将同一分组内的样本用户设置相同大小的权值,进而对用户类别识别模型的识别误差进行加权处理。
另一种可能的实现方式是,先通过公式δ=|y-α|来计算用户类别计算模型的计算误差,其中,y为样本用户的类别标签,α为样本用户属于预设类别的概率,δ为用户类别计算模型的计算误差。再通过公式l=δ*{[α*-log(sigmoid(y))]+[(1-α)*-log(1-sigmoid(y))]},实现对δ的10-分箱处理,l即为权值,进而对用户类别识别模型的识别误差进行加权处理。
步骤s223,根据加权处理后的识别误差,对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
步骤s225,当满足预设条件时,完成对用户类别识别模型的训练。
需要说明的是,前述对步骤s101-步骤s111的说明解释,也适用于本说明书实施例的步骤s201-步骤s225,此处不再赘述。
从而,实现了对用户类别识别模型的识别准确度的提升。
随着电子金融业务的不断成熟,电子金融平台开始对个人提供借贷服务,对于平台上新注册的个人用户,无法准确地进行个人逾期风险的预测,使得平台向其提供个人借贷服务时存在较大的风险,为了让本说明书实施例所提出的用户类别识别模型能够用于个人用户逾期风险的预测,本说明书实施例还提出了又一种用户类别识别模型的训练方法。将前述用户类别计算模型作为逾期风险计算模型,通过联系人列表,计算样本用户为逾期用户的概率,用户类别识别模型为逾期风险预测模型,通过软件特征和样本用户为逾期用户的概率,确定样本用户的逾期风险。图4为本说明书实施例所提出的又一种用户类别识别模型的训练方法的流程示意图。如图4所示,该方法包括以下步骤:
步骤s301,获取样本用户的常用软件列表和联系人列表,以及逾期标签。
其中,样本用户是已经在个人借贷平台上存在过逾期行为或者从未产生逾期行为的用户,并通过逾期标签进行标记,存在过逾期行为的用户用1进行标记,从未产生逾期行为的用户用0进行标记。由于样本用户的常用软件列表和联系人列表,以及逾期标签都已确定,因此,可以通过样本用户的相关数据,以及逾期标签对逾期风险预测模型进行训练。
步骤s303,获取样本用户的常用软件列表中每个常用软件对应的软件特征。
步骤s305,根据全部样本用户的联系人列表,生成样本用户的关系网络。
其中,关系网络包括多个节点,每个节点与样本用户相对应。
步骤s307,对样本用户的关系网络进行无监督学习处理,以确定每个样本用户对应的图节点的图特征。
步骤s309,将样本用户对应的图节点的图特征输入分类器,以生成样本用户的逾期概率。
步骤s311,将样本用户对应的软件特征输入注意力神经网络。
其中,注意力神经网络用于确定常用软件列表中每个常用软件的影响度。
步骤s313,基于样本用户对应的软件特征,和常用软件列表中每个常用软件的影响度,确定样本用户的用户特征。
步骤s315,根据样本用户的用户特征,以及样本用户的逾期概率,生成样本用户的逾期风险。
步骤s317,根据样本用户的逾期标签和样本用户的逾期概率,生成逾期风险计算模型的计算误差。
步骤s319,根据样本用户的逾期标签和样本用户的逾期风险,生成逾期风险预测模型的预测误差。
步骤s321,基于逾期风险计算模型的计算误差,对逾期风险预测模型的预测误差进行加权处理。
步骤s323,根据加权处理后的预测误差,对逾期风险预测模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
步骤s325,当满足预设条件时,完成对逾期风险预测模型的训练。
需要说明的是,前述对步骤s201-步骤s225的说明解释,也适用于本说明书实施例的步骤s301-步骤s325,此处不再赘述。
从而,实现了将用户类别识别模型作为逾期风险预测模型,用于个人用户逾期风险的预测。
为了更加清楚地说明本说明书实施例所提出的用户类别识别模型的训练方法是如何用于逾期风险预测模型的训练的,下面进行举例说明。
图5为本说明书实施例所提出的用户类别识别模型的训练方法的一个示例的流程图。如图5所示,获取样本用户的常用软件列表和联系人列表,生成每个常用软件对应的软件特征向量,将联系人列表输入逾期概率计算模型,生成样本用户的逾期概率。将软件特征向量输入注意力神经网络后,生成影响度向量。将影响度向量和软件特征向量相结合,生成用户特征向量,将逾期概率作为一维特征与用户特征向量进行融合,并经过多次非线性映射后,生成融合的特征向量。使用softmax归一化指数函数对融合的特征向量进行处理后,生成样本用户的逾期风险。
基于样本用户的逾期标签和逾期概率,生成逾期概率计算模型的计算误差,进而按照计算误差的数值范围,确定对应的权值。基于样本用户的逾期标签和逾期风险,生成逾期风险预测模型的预测误差,使用权值对预测误差进行加权处理后,用于对注意力神经网络的权值、图神经网络的参数、软件特征向量的数值进行优化。当满足预设条件时,完成对逾期风险预测模型的训练。
此外,为了能够使用前述训练完的用户类别识别模型进行用户类别识别,本说明书实施例还提出了一种用户类别识别方法。图6为本说明书实施例所提出的一种用户类别识别方法的流程示意图,如图6所示,该方法包括以下步骤:
步骤s401,获取待识别用户的常用软件列表和联系人列表。
步骤s403,获取待识别用户的常用软件列表中每个常用软件对应的软件特征。
步骤s405,将待识别用户的联系人列表输入用户类别计算模型,以生成待识别用户属于预设类别的概率。
步骤s407,将待识别用户对应的软件特征,和待识别用户属于预设类别的概率,输入如前述训练方法训练完的用户类别识别模型中。
步骤s409,根据用户类别识别模型的输出,对待识别用户进行识别。
需要说明的是,前述对用户类别识别模型的训练方法实施例的说明解释,也适用于本说明书实施例的用户类别识别方法,此处不再赘述。
综上所述,本说明书实施例所提出的用户类别识别方法,获取待识别用户的常用软件列表和联系人列表,获取待识别用户的常用软件列表中每个常用软件对应的软件特征。将待识别用户的联系人列表输入用户类别计算模型,以生成待识别用户属于预设类别的概率,将待识别用户对应的软件特征,和待识别用户属于预设类别的概率,输入如前述训练方法训练完的用户类别识别模型中,根据用户类别识别模型的输出,对待识别用户进行识别。由此,实现了在在用户信息不充分的情况下,基于待识别用户的联系人列表和对应的软件特征,对待识别用户进行识别。
为了能让本说明书实施例所提出的用户类别识别方法用于个人用户逾期风险的预测,本说明书实施例还提出了另一种用户类别识别方法。将前述用户类别计算模型作为逾期风险计算模型,通过联系人列表,计算样本用户为逾期用户的概率,用户类别识别模型为逾期风险预测模型,通过软件特征和样本用户为逾期用户的概率,确定样本用户的逾期风险。图7为本说明书实施例所提出的另一种用户类别识别方法的流程示意图。如图7所示,该方法包括以下步骤:
步骤s501,获取待识别用户的常用软件列表和联系人列表。
步骤s503,获取待识别用户的常用软件列表中每个常用软件对应的软件特征。
步骤s505,将待识别用户的联系人列表输入逾期风险计算模型,以生成待识别用户的逾期概率。
步骤s507,将待识别用户对应的软件特征,和待识别用户的逾期概率,输入如前述训练方法训练完的逾期风险预测模型中。
步骤s509,根据逾期风险预测模型的输出,确定待识别用户的逾期风险。
需要说明的是,前述对用户类别识别模型的训练方法实施例的说明解释,也适用于本说明书实施例的用户类别识别方法,此处不再赘述。
从而,实现了将用户类别识别模型作为逾期风险预测模型,用于个人用户逾期风险的预测。
为了更加清楚地说明本说明书实施例所提出的用户类别识别方法是如何用于个人用户的逾期风险预测的,下面进行举例说明。
图8为本说明书实施例所提出的用户类别识别方法的一个示例的流程图。如图8所示,获取待识别用户的常用软件列表和联系人列表,生成每个常用软件对应的软件特征向量,将联系人列表输入逾期概率计算模型,生成待识别用户的逾期概率。将软件特征向量输入注意力神经网络后,生成影响度向量。将影响度向量和软件特征向量相结合,生成用户特征向量,将逾期概率作为一维特征与用户特征向量进行融合,并经过多次非线性映射后,生成融合的特征向量。使用softmax归一化指数函数对融合的特征向量进行处理后,生成待识别用户的逾期风险。
为了实现上述实施例,本说明书实施例还提出了一种用户类别识别模型的训练装置,图9为本说明书实施例所提出的一种用户类别识别模型的训练装置的结构示意图。如图9所示,该装置包括:第一获取模块610,第二获取模块620,第一输入模块630,第二输入模块640,优化模块650,训练模块660。
第一获取模块610,用于获取样本用户的常用软件列表和联系人列表,以及类别标签。
第二获取模块620,用于获取样本用户的常用软件列表中每个常用软件对应的软件特征。
第一输入模块630,用于将样本用户的联系人列表输入用户类别计算模型,以生成样本用户属于预设类别的概率。
第二输入模块640,将样本用户对应的软件特征,和样本用户属于预设类别的概率,输入用户类别识别模型,以生成样本用户的识别结果。
其中,用户类别识别模型包括图神经网络和注意力神经网络。
优化模块650,用于根据样本用户的识别结果和样本用户的类别标签,对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
训练模块660,用于满足预设条件时,完成对用户类别识别模型的训练。
需要说明的是,前述对用户类别识别模型的训练方法实施例的解释说明也适用于该实施例的用户类别识别模型的训练装置,此处不再赘述。
综上所述,本说明书实施例所提出的一种用户类别识别模型的训练装置,在对用户类别识别模型进行训练时,将样本用户的联系人列表输入用户类别计算模型,以生成样本用户属于预设类别的概率。将样本用户对应的软件特征,和样本用户属于预设类别的概率,输入用户类别识别模型,以生成样本用户的识别结果。根据样本用户的识别结果和样本用户的类别标签,对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。当满足预设条件时,完成对用户类别识别模型的训练。由此,使得训练完的用户类别识别模型能够在用户信息不充分的情况下,基于待识别用户的联系人列表和对应的软件特征,来对用户类别进行准确识别。
为了实现上述实施例,本说明书实施例还提出了另一种用户类别识别模型的训练装置,图10为本说明书实施例所提出的另一种用户类别识别模型的训练装置的结构示意图。如图10所示,该装置包括:第一获取模块710,第二获取模块720,第一输入模块730,第二输入模块740,优化模块750,训练模块760。
第一获取模块710,用于获取样本用户的常用软件列表和联系人列表,以及类别标签。
第二获取模块720,用于获取样本用户的常用软件列表中每个常用软件对应的软件特征。
第一输入模块730,用于将样本用户的联系人列表输入用户类别计算模型,以生成样本用户属于预设类别的概率。
第二输入模块740,将样本用户对应的软件特征,和样本用户属于预设类别的概率,输入用户类别识别模型,以生成样本用户的识别结果。
其中,用户类别识别模型包括图神经网络和注意力神经网络。
优化模块750,用于根据样本用户的识别结果和样本用户的类别标签,对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
训练模块760,用于满足预设条件时,完成对用户类别识别模型的训练。
其中,第一输入模块730,包括:第四生成子模块731,用于根据全部样本用户的联系人列表,生成样本用户的关系网络。其中,关系网络包括多个节点,每个节点与样本用户相对应。第二处理子模块732,用于对样本用户的关系网络进行无监督学习处理,以确定每个样本用户对应的图节点的图特征。第二输入子模块733,用于将样本用户对应的图节点的图特征输入分类器,生成样本用户属于预设类别的概率。
第二输入模块740,包括:第一输入子模块741,用于将样本用户对应的软件特征输入注意力神经网络。其中,注意力神经网络用于确定常用软件列表中每个常用软件的影响度。确定子模块742,用于基于样本用户对应的软件特征,和常用软件列表中每个常用软件的影响度,确定样本用户的用户特征。第一生成子模块743,用于根据样本用户的用户特征,以及样本用户属于预设类别的概率,生成样本用户的识别结果。
优化模块750,包括:第二生成子模块751,用于根据样本用户的类别标签和样本用户属于预设类别的概率,生成用户类别计算模型的计算误差。第三生成子模块752,用于根据样本用户的类别标签和样本用户的识别结果,生成用户类别识别模型的识别误差。第一处理子模块753,用于基于用户类别计算模型的计算误差,对用户类别识别模型的识别误差进行加权处理。优化子模块754,用于根据加权处理后的识别误差,对用户类别识别模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
需要说明的是,前述对用户类别识别模型的训练方法实施例的解释说明也适用于该实施例的用户类别识别模型的训练装置,此处不再赘述。
从而,实现了对用户类别识别模型的识别准确度的提升。
为了实现上述实施例,本说明书实施例还提出了又一种用户类别识别模型的训练装置,图11为本说明书实施例所提出的又一种用户类别识别模型的训练装置的结构示意图。如图11所示,该装置包括:第一获取模块810,第二获取模块820,第一输入模块830,第二输入模块840,优化模块850,训练模块860。
第一获取模块810,用于获取样本用户的常用软件列表和联系人列表,以及逾期标签。
第二获取模块820,用于获取样本用户的常用软件列表中每个常用软件对应的软件特征。
第一输入模块830,用于将样本用户的联系人列表输入逾期概率计算模型,以生成样本用户的逾期概率。
第二输入模块840,将样本用户对应的软件特征,和样本用户的逾期概率,输入逾期风险预测模型,以生成样本用户的逾期风险。
其中,逾期风险预测模型包括图神经网络和注意力神经网络。
优化模块850,用于根据样本用户的逾期风险和样本用户的逾期标签,对逾期风险预测模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
训练模块860,用于当满足预设条件时,完成对逾期风险预测模型的训练。
其中,第一输入模块830,包括:第四生成子模块831,用于根据全部样本用户的联系人列表,生成样本用户的关系网络。其中,关系网络包括多个节点,每个节点与样本用户相对应。第二处理子模块832,用于对样本用户的关系网络进行无监督学习处理,以确定每个样本用户对应的图节点的图特征。第二输入子模块833,用于将样本用户对应的图节点的图特征输入分类器,生成样本用户的逾期概率。
第二输入模块840,包括:第一输入子模块841,用于将样本用户对应的软件特征输入注意力神经网络。其中,注意力神经网络用于确定常用软件列表中每个常用软件的影响度。确定子模块842,用于基于样本用户对应的软件特征,和常用软件列表中每个常用软件的影响度,确定样本用户的用户特征。第一生成子模块843,用于根据样本用户的用户特征,以及样本用户的逾期概率,生成样本用户的逾期风险。
优化模块850,包括:第二生成子模块851,用于根据样本用户的逾期标签和样本用户的逾期概率,生成逾期概率计算模型的计算误差。第三生成子模块852,用于根据样本用户的逾期标签和样本用户的逾期风险,生成逾期风险预测模型的预测误差。第一处理子模块853,用于基于逾期概率计算模型的计算误差,对逾期风险预测模型的预测误差进行加权处理。优化子模块854,用于根据加权处理后的预测误差,对逾期风险预测模型中的参数,以及样本用户的常用软件列表中每个常用软件对应的软件特征进行优化。
需要说明的是,前述对用户类别识别模型的训练方法实施例的解释说明也适用于该实施例的用户类别识别模型的训练装置,此处不再赘述。
从而,实现了将用户类别识别模型作为逾期风险预测模型,用于个人用户逾期风险的预测。
为了实现上述实施例,本说明书实施例还提出了一种用户类别识别装置,图12为本说明书实施例所提出的一种用户类别识别装置的结构示意图。如图12所示,该装置包括:第三获取模块910,第四获取模块920,第三输入模块930,第四输入模块940,识别模块950。
第三获取模块910,用于获取待识别用户的常用软件列表和联系人列表。
第四获取模块920,用于获取待识别用户的常用软件列表中每个常用软件对应的软件特征。
第三输入模块930,用于将待识别用户的联系人列表输入用户类别计算模型,以生成待识别用户属于预设类别的概率。
第四输入模块940,用于将待识别用户对应的软件特征,和待识别用户属于预设类别的概率,输入如前述训练装置训练完的用户类别识别模型中。
识别模块950,用于根据用户类别识别模型的输出,对待识别用户进行识别。
需要说明的是,前述对用户类别识别方法实施例的解释说明也适用于该实施例的用户类别识别装置,此处不再赘述。
综上所述,本说明书实施例所提出的用户类别识别装置,在进行用户类别识别时,获取待识别用户的常用软件列表和联系人列表,获取待识别用户的常用软件列表中每个常用软件对应的软件特征。将待识别用户的联系人列表输入用户类别计算模型,以生成待识别用户属于预设类别的概率,将待识别用户对应的软件特征,和待识别用户属于预设类别的概率,输入如前述训练方法训练完的用户类别识别模型中,根据用户类别识别模型的输出,对待识别用户进行识别。由此,实现了在在用户信息不充分的情况下,基于待识别用户的联系人列表和对应的软件特征,对待识别用户进行识别。
为了实现上述实施例,本说明书实施例还提出了另一种用户类别识别装置,图13为本说明书实施例所提出的另一种用户类别识别装置的结构示意图。如图13所示,该装置包括:第三获取模块1010,第四获取模块1020,第三输入模块1030,第四输入模块1040,识别模块1050。
第三获取模块1010,用于获取待识别用户的常用软件列表和联系人列表。
第四获取模块1020,用于获取待识别用户的常用软件列表中每个常用软件对应的软件特征。
第三输入模块1030,用于将待识别用户的联系人列表输入逾期风险计算模型,以生成待识别用户的逾期概率。
第四输入模块1040,用于将待识别用户对应的软件特征,和待识别用户的逾期概率,输入如前述训练装置训练完的逾期风险预测模型中。
识别模块1050,用于根据逾期风险预测模型的输出,确定待识别用户的逾期风险。
需要说明的是,前述对用户类别识别方法实施例的解释说明也适用于该实施例的用户类别识别装置,此处不再赘述。
从而,实现了将用户类别识别模型作为逾期风险预测模型,用于个人用户逾期风险的预测。
为了实现上述实施例,本说明书实施例还提出一种计算机设备,包括存储器和处理器;存储器上存储有可由处理器运行的计算机程序;当处理器运行计算机程序时,执行如前述方法实施例的用户类别识别模型的训练方法。
为了实现上述实施例,本说明书实施例还提出一种计算机设备,包括存储器和处理器;存储器上存储有可由处理器运行的计算机程序;当处理器运行计算机程序时,执行如前述方法实施例的用户类别识别方法。
为了实现上述实施例,实施例还提出一种非临时性计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如前述方法实施例的用户类别识别模型的训练方法。
为了实现上述实施例,实施例还提出一种非临时性计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如前述方法实施例的用户类别识别方法。
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本说明书实施例的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书实施例中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本说明书实施例中的具体含义。
在本说明书实施例中,除非另有明确的规定和限定,第一特征在第二特征“上”或“下”可以是第一和第二特征直接接触,或第一和第二特征通过中间媒介间接接触。而且,第一特征在第二特征“之上”、“上方”和“上面”可是第一特征在第二特征正上方或斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”可以是第一特征在第二特征正下方或斜下方,或仅仅表示第一特征水平高度小于第二特征。
在本说明书的描述中,样本术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本说明书实施例的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!