一种空气动力数据集异常数据检测方法与流程
本发明属于气动数据集的技术领域,具体涉及一种空气动力数据集异常数据检测方法。
背景技术:
空气动力(简称气动)数据集/数据库(aerodynamicdatabase),是指在飞行器气动设计过程中有组织有计划地生产的飞行包线范围的气动数据集,一般通过cfd计算、风洞试验、飞行试验等手段获得。比如文献“pamadibn,brauckmanngj,ruthmj,etal.aerodynamiccharacteristics,databasedevelopment,andflightsimulationofthex-34vehicle[j].journalofspacecraftandrockets,2001,38(3):334-344.”中介绍了通过风洞试验、工程计算等多种方法融合建立x-34飞行器的气动数据集;文献“engelundwc,hollandsd,cockrellce,etal.aerodynamicdatabasedevelopmentforthehyper-xairframe-integratedscramjetpropulsionexperiments[j].journalofspacecraftandrockets,2001,38(6):803-810.”中介绍了飞行试验获得的气动数据集的过程。无论那种方法获得数据集,因为试验或计算条件设置不正确、传感器异常、人工统计误操作等原因,往往会产生异常数据。异常数据的存在可能对飞行器的设计、建模、控制等各环节产生不利影响,每一个数据集的生产与收集过程将耗费较大的人力排除这些异常数据。
气动数据本质上是一种物理数据,体现物理规律。正常数据分布,在各维度上总能体现较好的分布曲线,异常数据则不符合正常数据的分布规律。为鉴别异常气动数据的难点主要体现在以下几个方面:
1、数据集大、且单条数据维度高,数据计算量呈指数增长。
2、数据项之间存在耦合关系、行数据之间存在共线性,回归模型。
3、数据来源复杂,数据中可能出现重复、非函数映射关系。
目前尚无针对气动数据集专有的异常数据检测分析工具,主要是人工方法,将数据分组拷贝到excel电子表格,再人工作图、人眼观察,特别依赖专业人员的经验与细心。
技术实现要素:
本发明的目的在于针对现有技术中的上述不足,提供一种空气动力数据集异常数据检测方法,以解决或改善上述的问题。
为达到上述目的,本发明采取的技术方案是:
一种空气动力数据集异常数据检测方法,其包括:
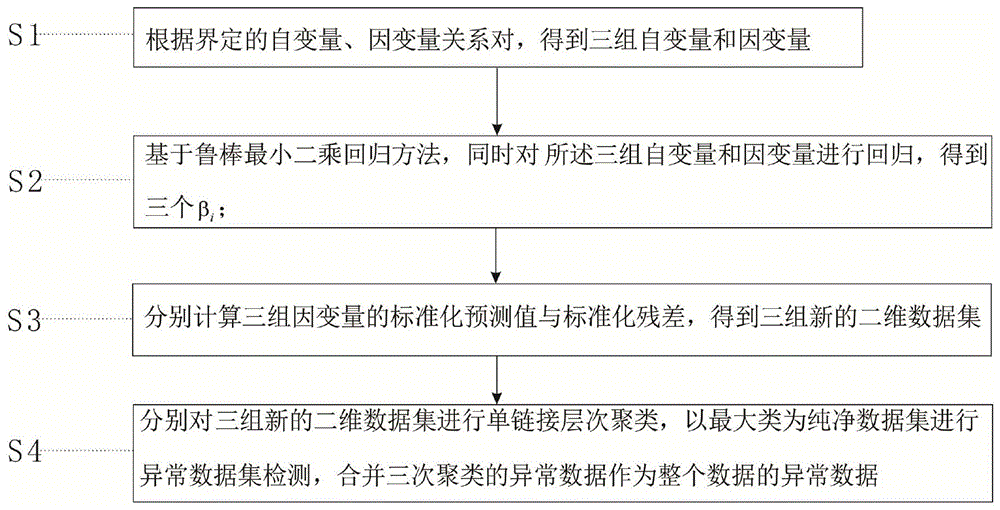
s1、根据界定的自变量、因变量关系对,得到三组自变量和因变量;
s2、基于鲁棒最小二乘回归方法,同时对所述三组自变量和因变量进行回归,得到三个βi,i=1,2,3,其中βi为系数向量;
s3、分别计算三组因变量的标准化预测值与标准化残差,得到三组新的二维数据集;
s4、分别对s3中所得三组新的二维数据集进行单链接层次聚类,以最大类为纯净数据集进行异常数据集检测,合并三次聚类的异常数据作为整个数据的异常数据。
优选地,s1中根据界定的自变量、因变量关系对,得到三组自变量和因变
量为:pi={xi,yi},i=1,2,3.
y1={cl}
y2={cd}
y3={cm}
其中,m为马赫数,m2为马赫数的平方,α为攻角,α2为攻角的平方,δp为舵偏角,
优选地,βi,满足min||xiβi-yi||,i=1,2,3,||·||为绝对值运行。
优选地,s2中基于鲁棒最小二乘回归方法,同时对所述三组自变量和因变量进行回归,得到三个βi向量。三组回归方式相同,为表达方法直接以x和y表示任意一组自变量与因变量,具体步骤包括:
基于svd分解自变量:
构建基于svd的最小二乘,
获得回归系数的估计
优选地,在s2中采用截断最小二乘,从自变量x与因变量y两个方面同时抵抗异常点的扰动,具体步骤如下:
确定对大数据集进行重复抽样的次数ns,抽样次数ns由样本大小n和回归维度k计算,其中,k等于s1中自变量列数;
当n值较小时,如n<30,则直接进行全排列产生样本,即样本数为
基于svd求最小二乘估计参数,对ns个样本分别计算的带βi,i=1,2,…,ns;
逐一使用βi,i=1,2,…,ns估计所有n个样本的残差平方和矩阵
得到lts回归系数β*,取s中最小值对应到的β*=βi。
优选地,s3中标准化预测值与残差形成的数据集
s3.1、利用β预测获得气动力系数估计值
s3.2、标准化预测值
其中,
优选地,s4中分别对s3中所得三组新的二维数据集进行单链接层次聚类,以最大类为纯净数据集进行异常数据集检测,合并三次聚类的异常数据作为整个数据的异常数据的具体步骤包括:
s4.1、剪切高度为
s4.2、通过纯净集sc建立回归β,并获得该数据集的预测残差的均方根
s4.3、将大小为ne的非纯净集se的数据逐一放回sc,计算放回数据m后的数据集残差均方根
s4.4、比较放回后残差变化比
本发明提供的空气动力数据集异常数据检测方法,具有以下有益效果:
本发明的方法首先根据气动数据特点建立回归关系,为数据建立基本规律,确定了后序大数据下的回归模型的高效性和准确性;其次,根据气动数据特点,将svd分解与lts回归结合,形成适用于气动数据集的鲁棒二乘回归方法,算法参数的选取与气动数据特点结合,解决气动数据中重复、非函数映射、共线性等带来的建模困难;利用标准化预测值与标准化残差建立聚类,降低气动数据集高维度带来的计算复杂性。
附图说明
图1为空气动力数据集异常数据检测方法的流程图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
根据本申请的一个实施例,参考图1,本方案的空气动力数据集异常数据检测方法,包括:
s1、根据界定的自变量、因变量关系对,得到三组自变量和因变量;
s2、基于鲁棒最小二乘回归方法,同时对所述三组自变量和因变量进行回归,得到三个βi,i=1,2,3,其中βi为回归系数;
s3、分别计算三组因变量的标准化预测值与标准化残差,得到三组新的二维数据集;
s4、分别对s3中所得三组新的二维数据集进行单链接层次聚类,以最大类为纯净数据集进行异常数据集检测,合并三次聚类的异常数据作为整个数据的异常数据。
根据本申请的一个实施例,以下将对上述步骤进行详细描述。
为便于描述,以纵向气动力数据集为对象,开展本以下描述,首先一个纵向气动力数据集定义为{m,h,α,δp,cl,cd,cm},分别表示马赫数、高度、攻角、俯仰舵偏角、升力、阻力、俯仰力矩。
s1、根据界定的自变量、因变量关系对,获得三组自变量与因变量;三组自变量与因变量表示为pi={xi,ci},i=1,2,3.,其中,
其中,m为马赫数,m2为马赫数的平方,α为攻角,α2为攻角的平方,δp为舵偏角,
利用建立的基本函数关系,主要是利用了气动数据的物理规律是稳定的且数据项的耦合一般是确定的,以减界定数据训练的维度,一定程度上克服大数据带来的维度灾难。
s2、基于鲁棒最小二乘回归方法,同时对三组数据pi,i=1,2,3进行回归,获得三个βi使之分别满足min||xiβ-ci||,i=1,2,3,其具体步骤如下:
鲁棒截断最小二乘回归,鲁棒性体现在解决气动数据集的数据量大、重复数据、非函数的映射关系等带来的回归困难。首先,对于最小二乘的求解利用svd分解,一是克服矩阵奇异,同时svd分解可采用分块分解,克服数据量大问题。其次,截断最小二乘,进行有放回抽样数据集数上进行最小二乘求解,样本数为xi的列数k(维度)。
s21、利用svd求最小二乘估计参数;
输入大小为n×m的自变量x,和n×1的因变量y,求解系数β,具体的步骤如下:
基于svd分解自变量:
建立基于svd的最小二乘,
获得回归系数的估计
s22、截断最小二乘,是从自变量x与因变量y两个方面同时抵抗异常点的扰动,是一种稳健的回归估计方法,具体步骤如下:
确定对大数据集进行重复抽样的次数ns,抽样次数ns由样本大小n和回归维度k(k等于s1中自变量列数)计算。
当n值较小时,如n<30,则直接进行全排列产生样本,即样本数为
对ns个样本分别采用s21描述的方法求出βi,i=1,2,…,ns。
通过逐一使用βi,i=1,2,…,ns估计所有n个样本的残差平方和矩阵
最后,得到lts回归系数β*,取s中最小值对应到的β*=βi。
s3、分别求三组应变量的标准化预测值与标准化残差,获得三组新的二维数据集表示为
s3.1、利用β预测获得
s3.2、标准化预测值
其中,
s4、分别对pi,s,i=1,2,3进行单链接层次聚类,以最大类为纯净数据集进行异常数据集检测,合并三次聚类的异常数据作为整个数据的异常数据。
其中,建立聚类树后的步骤如下:
s4.1、聚类树剪枝界定“纯净集”,剪切高度为
s4.2、通过纯净集sc建立回归β,并获得该数据集的预测残差的均方根
s4.3、将大小为ne的非纯净集se的数据逐一放回sc,计算放回数据m后的数据集残差均方根
s4.4、比较放回后残差变化比
本发明的方法首先根据气动数据特点建立回归关系,为数据建立基本规律,确定了后序大数据下的回归模型的高效性和准确性;其次,根据气动数据特点,将svd分解与lts回归结合,形成适用于气动数据集的鲁棒二乘回归方法,算法参数的选取与气动数据特点结合,解决气动数据中重复、非函数映射、共线性等带来的建模困难;利用标准化预测值与标准化残差建立聚类,降低气动数据集高维度带来的计算复杂性。
虽然结合附图对发明的具体实施方式进行了详细地描述,但不应理解为对本专利的保护范围的限定。在权利要求书所描述的范围内,本领域技术人员不经创造性劳动即可做出的各种修改和变形仍属本专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!