一种基于强化学习的智能体自动决策方法与流程
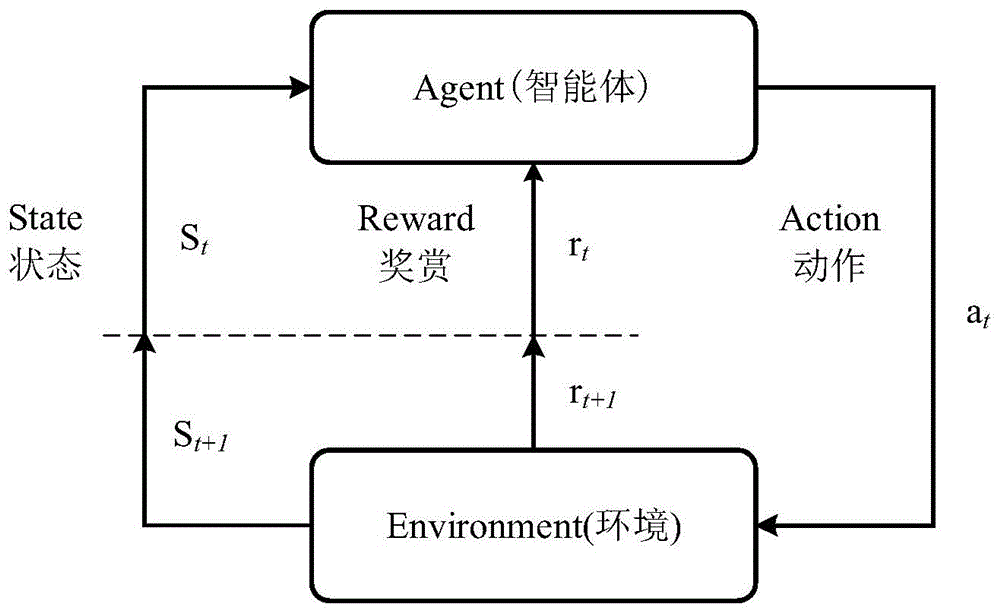
本发明属于机器学习技术领域,更为具体地讲,涉及一种基于强化学习的智能体自动决策方法。
背景技术:
强化学习(reinforcementlearning,rl)最初源于心理学,用于模仿智能生物的学习模式,是一类以环境状态(state)作为输入,以适应环境(environment)为目标的特殊的无模型机器学习方法。图1是强化学习的过程示意图。如图1所示,强化学习的核心思想是通过与环境的不断交互和不断试错(explorer),利用从环境中得到的反馈信号(reward)实现对一系列策略(policy)的优化。
强化学习已经涉及与应用到了很多领域,例如自动驾驶、推荐系统、机器人、直升机飞行、游戏等等领域。例如,目前强化学习在游戏领域得到了快速的发展,主要以谷歌公司的deepmind团队为代表,从状态有限游戏围棋的alphago到如今状态无限的大型经典即时战略游戏星际争霸2(starcraft2)的alphastar,都是使用了精心设计的强化学习训练后得到较优模型,自动生成最优目标策略来实现。在自动驾驶领域,强化学习可以使得汽车在无人无地图无规则的条件下,从零开始自主学习驾驶,通过摄像头和其他传感器将周围环境的信息作为输入并解析,例如区分障碍物类别、障碍物的相对速度和相对距离、道路的宽度和曲率等等。
在当前强化学习领域,dqn(deepq-learning)算法是一种较为常用的方法,该方法将q-learning和深度学习(deeplearning)结合,其中q-learning是通过不停地探索和更新q表中的q(质量)值从而计算出智能体行动的最佳路径,深度学习就是用神经网络来学习数据。在dqn算法中,其q值不用q表记录,而是用神经网络来预测q值,并通过不断更新神经网络从而学习到最优的行动路径。dqn包含两个神经网络,一个为目标网络,用于预测q值,另一个为评价网络,用于获取q评估值。目标网络的参数相对固定,是评价网络的一个历史版本。在智能体运行过程中会维护一个经验样本池,用于记录每一个状态下的行动、奖励、和下一个状态的结果,评价网络从记忆库中随机提取样本进行训练,实现参数更新,目标网络定期将评价网络的参数复制过来完成参数更新。
在现有方法中,由于经验样本池中只存储相关达成规定目标状态的轨迹策略,对于规定探索次数和规定时间步中未达到欲达目标的相关轨迹策略执意丢弃,可能会造成所构造的经验样本池内可用数据较少,也即是说有效样本数少,轨迹中策略所达奖励稀疏,大量浪费资源,包括人工设计奖励函数成本、编写代码成本、硬件设施成本等。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于强化学习的智能体自动决策方法,对经验样本池进行扩充,提高神经网络训练性能,从而提升智能体自动决策的准确度。
为了实现以上发明目的,本发明基于强化学习的智能体自动决策方法包括以下步骤:
s1:确定智能体的环境状态s以及动作空间a,其中动作空间a包含至少一个可选动作;
s2:构建目标网络和评价网络,其中目标网络的输入为环境状态,其输出为智能体各个可选动作的第一选择概率;评价网络的输入各个可选动作的第一选择概率,其输出为实施第一选择概率动作的后效奖励值;
s3:确定智能体的初始环境状态s0和目标环境状态g,通过目标网络和评价网络得到智能体各步的动作,记智能体从初始环境状态s0到达目标环境状态g所需的步数为k,每步获取当前策略πk的元组为(sk-1,ak-1,sk,rk,g),其中sk-1表示第k步动作执行前的环境状态,ak-1表示第k步执行的动作,sk表示第k步动作执行后所达到的环境状态,rk表示第k步动作得到的即时奖励值;将k步策略构成轨迹策略并存入经验样本池中;
s4:根据经验样本池现有的轨迹策略生成新的轨迹策略,其具体方法如下:记现有的某个轨迹策略中包含k步策略,每步策略为πk=(sk-1,ak-1,sk,rk,g),将第k*步动作执行后所达到的环境状态
s5:根据预先设置好的更新周期对评价网络进行参数更新,在参数更新时从经验样本池中选择若干轨迹策略对评价网络进行训练,目标网络根据预先设置好的更新周期将评价网络的参数复制至目标网络,完成目标网络的更新。目标网络的更新周期大于评价网络的更新周期。
本发明基于强化学习的智能体自动决策方法,确定智能体的环境状态以及动作空间,构建用于确定可选动作第一选择概率的目标网络以及用于确定实施第一选择概率动作的后效奖励值的评价网络,确定智能体的当前环境状态和目标环境状态,通过目标网络和评价网络得到智能体各步的动作,构成轨迹策略存入经验样本池,根据经验样本池中现有的轨迹策略生成新的轨迹策略对经验样本池进行扩充,根据预先设置好的更新周期采用经验样本池中的样本对评价网络和目标网络进行参数更新。采用本发明可以提高神经网络训练性能,从而提升智能体自动决策的准确度。
附图说明
图1是强化学习的过程示意图;
图2是本发明基于强化学习的智能体自动决策方法的具体实施方式流程图;
图3是本实施例中智能汽车自动驾驶网络的结构示意图;
图4是本实施例中基于经典dqn算法进行智能汽车自动驾驶决策的平均得分曲线图;
图5是本实施例中基于本发明进行智能汽车自动驾驶决策的平均得分曲线图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
实施例
图2是本发明基于强化学习的智能体自动决策方法的具体实施方式流程图。如图2所示,本发明基于强化学习的智能体自动决策方法的具体步骤包括:
s201:获取智能体信息:
确定智能体的环境状态s以及动作空间a,其中动作空间a包含至少一个可选动作。
本实施例中以智能汽车的自动驾驶为例,其环境状态为智能汽车所处的道路环境,通常包括智能汽车所拍摄的前方道路图像和传感器所采集到的风速、湿度等参数,动作空间包括智能汽车的多个驾驶动作:汽车行进速度、转速、角度偏移量。
s202:构建目标网络和评价网络:
构建目标网络和评价网络,其中目标网络的输入为环境状态,其输出为智能体各个可选动作的第一选择概率,通过目标网络可以实现对输入环境状态的自动特征提取。评价网络的输入各个可选动作的第一选择概率,其输出为实施第一选择概率动作的后效奖励值。图3是本实施例中智能汽车自动驾驶网络的结构示意图。
s203:获取轨迹策略:
确定智能体的初始环境状态s0和目标环境状态g,通过目标网络和评价网络得到智能体各步的动作,记智能体从初始环境状态s0到达目标环境状态g所需的步数为k,每步获取当前策略πk的元组为(sk-1,ak-1,sk,rk,g),其中sk-1表示第k步动作执行前的环境状态,ak-1表示第k步执行的动作,sk表示第k步动作执行后所达到的环境状态,rk表示第k步动作得到的即时奖励值。将k步策略构成轨迹策略并存入经验样本池中。
s204:扩充经验样本池:
为了提高经验样本池中的经验样本质量,可以根据经验样本池现有的轨迹策略生成新的轨迹策略,其具体方法如下:记现有的某个轨迹策略中包含k步策略,每步策略为πk=(sk-1,ak-1,sk,rk,g),将第k*步动作执行后所达到的环境状态
本发明通过对经验样本池进行了扩充,将未达目标环境状态的部分策略存入,增加矩阵中的奖励正值,将稀疏奖励问题给转化成非稀疏奖励,有效地扩展了经验池中完成任务获得正值奖励的经验数量。在智能体运行过程中会对经验样本池进行维护,保留新的轨迹策略,删除旧的轨迹策略,即采用先入先出的维护模式,以保证对目标网络和评价网络的训练适应最新的环境状态。
s205:网络更新:
根据预先设置好的更新周期对评价网络进行参数更新,在参数更新时从经验样本池中选择若干轨迹策略对评价网络进行训练,目标网络根据预先设置好的更新周期将评价网络的参数复制至目标网络,完成目标网络的更新。目标网络的更新周期大于评价网络的更新周期。
为了更好地说明本发明的技术效果,采用经典dqn算法作为对比方法,和本发明在智能汽车自动驾驶平台中的应用效果进行应用验证。本次验证中轨迹策略的生成和网络更新交叉进行,在对评价网络更新时利用小批量梯度下降法进行。设置控制的最大帧数为200000,重放池队列大小为10000,预达目标取值为5,批尺寸为5,采用adam优化器。将每100次轨迹策略的得分(即轨迹策略的折扣即时奖励和,也就是q值)进行平均,以对比两种方法的应用效果。图4是本实施例中基于经典dqn算法进行智能汽车自动驾驶决策的平均得分曲线图。图5是本实施例中基于本发明进行智能汽车自动驾驶决策的平均得分曲线图。比较图4和图5可知,本发明的得分逐渐增大并且平均得分值十分稳定,而经典dqn算法的得分不高且不稳定,这是因为经典dqn算法在进行网络训练时采用随机经验采样和奖励稀疏,导致目标网络和评价网络的性能不高,而本发明通过扩充经验样本池,使以上问题得到了改善。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!