一种基于YOLO的动作实时监测方法与流程
本发明涉及动作监控技术领域,尤其涉及一种基于yolo的动作实时监测方法。
背景技术:
在社区监控中,主要还是靠保安轮岗值守监控画面,这样不但耗费大量人力,而且人工值守监控画面也有很大的缺陷,不能实时对监控中危险人物以及危险动作发出预警。
如cn110569711a现有技术公开了一种,基于kinect的图形识别,在静态图像识别中,当操作者距离远,捕获图像比较模糊,无法精确提取图像信息,同时,存在动态识别中存在处理速度慢的缺点。另一种典型的如cn102521579a的现有技术公开的一种基于二维平面摄像头推的动作识别方法及系统,采用静态固定姿势来表示确认或者进入,操作非常不方便,不够自然,加大了用户对各种固定姿势的记忆负担,并且现有技术的二维平面下的人机交互普遍存在算法复杂,动作识别效率不高的问题。再来看如cn109389076a的现有技术公开的一种图像分割方法及装置,传统的图像皮肤分割方法主要是基于人体皮肤肤色实现的,然而人体皮肤的肤色在不同的场景下变化很大,比如在阳光下的皮肤会很亮并且部分区域有阴影,在室内时皮肤会很暗并且如果灯光不够皮肤会很较黑。传统方法的分割效果的鲁棒性较差,不能对图像中不同人的皮肤区域进行区分,在复杂场景的效果就更不理想了。
为了解决本领域普遍存在检测手段单一、检测不准确和无法监控目标的动作行为等等问题,作出了本发明。
技术实现要素:
本发明的目的在于,针对目前动作监控所存在的不足,提出了一种基于yolov3的动作实时监测方法。
为了克服现有技术的不足,本发明采用如下技术方案:
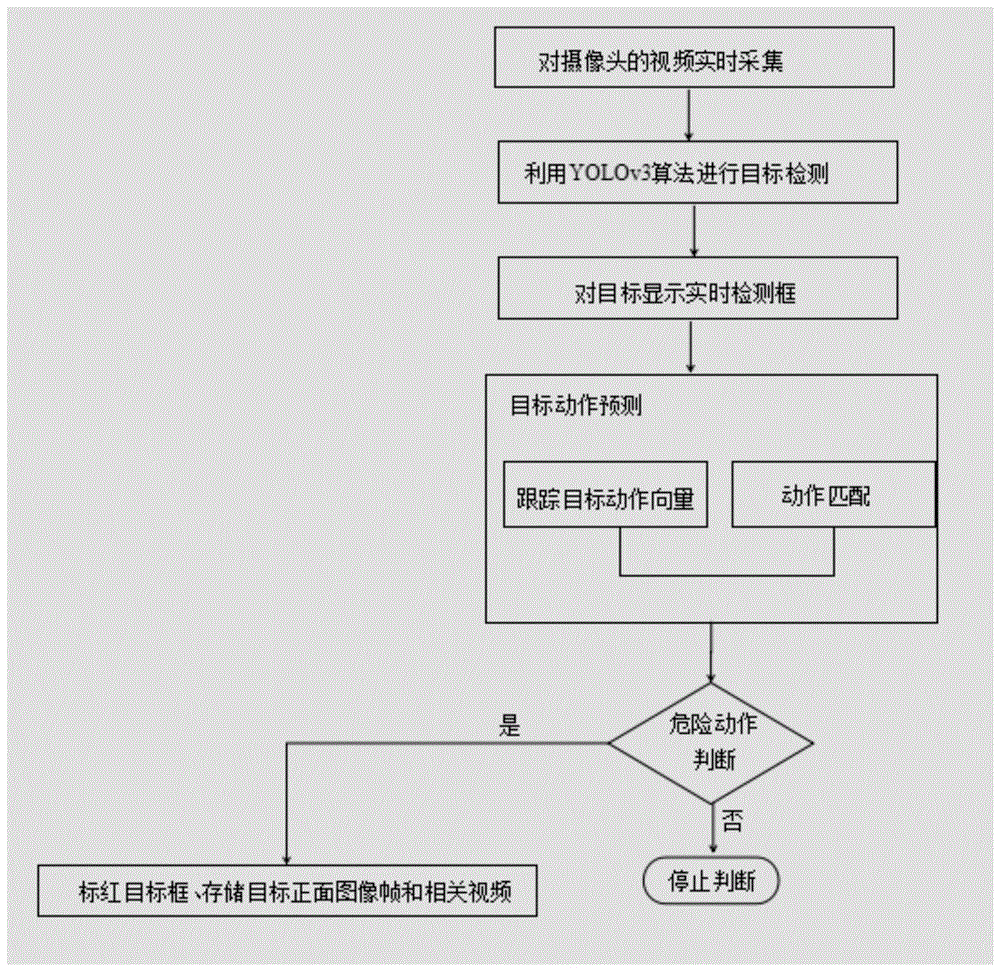
一种基于yolo的动作实时监测方法,所述监测方法包括以下步骤:
s1:建立场景模型,所述场景模型被配置为对摄像头所处位置进行视频采集;
s2:对所述场景模型中的目标检测,获得检测框;
s3:构建并训练深度学习提取网络,将所有的人物的检测框输入到该网络,得到所有检测框的特征向量;
s4:预测视频跟踪目标的动作向量,利用检测框的特征向量和预测的动作向量对跟踪目标进行危险动作匹配或预测,得到最佳匹配和预测检测框;
s5:对危险动作的目标检测框进行标红处理;
s6:报警提示。
可选的,所述场景模型的建模方法包括收集检测装置的场景图形、收集图形帧数和收集图像的像素,跟踪所述图形帧数的趋势并把所述趋势应用在分析装置中,所述分析装置把收集的场景图像进行区域的划分,所述区域包括第一图形帧的第一区域和第一图形帧的第二区域,所述第一区域被配置为对同一第一图形帧中的第二区域中收集像素数据的像素参数,并使用传感器控制单元调整输出像素数据速率。
可选的,所述检测框的选取方法包括:
通过边缘检测算法得到图像的边缘图,并通过优化处理器进行优化得到轮廓图;
通过轮廓图获取图像的超像素点,任意两个相邻的区域之间均有一个不相似度值;
对获取的区域进行整合,将边沿图和所述轮廓图进行两两合并,并利用场景模型输出像素与所述不相似度值进行整合,得出重叠的部分得到最终的检测框。
可选的,所述网络提取的方法包括:从构成所述第一图像帧的所有区域中收集所有图像像素数据,从所述第一图像帧中重新组装图像像素数据;获取与第一图像帧相关的标识符,针对第一图像帧以不同的周期收集第一区域和第二区域。
可选的,所述网络的训练方法包括:通过众多图像数据模型以支持预测场景理解来预测即将到来的成像参数变化的措施,标识或预测第一个图像帧中区域中的显着类型是什么,并识别没有任何显着项目的区域,并向传感器控制单元发送指导成像仪分辨率、动态范围和帧速率,最适合具有显著区域内类型,并保持或减少所述成像器分辨率、动态范围或者区域内没有显著特征的帧频,使其不超过带宽限制;并在内存存储、功耗限制、图像传感器、传感器控制单元和图像处理单元之间的通信回路。
可选的,所述动作向量提取方法包括:通过传感器进行识别场景环境中的人物的动作,把所述动作进行模型的建立,并在所述模型中进行动作的元素的建立,并预测所述动作的运动趋势;
通过传感器以一定的间隔周期进行所述动作数据的采集,并与所述模型的预测的动作对比,并存储在事件模型中;
基于所述事件模型中的动作数据提取动作姿势分析,对所述姿势向量进行提取,得出动作矩阵集合,并带入公式(1)中,得出所述动作向量,
其中,θ为向量y和向量g之间的夹角,ζζ为动作矩阵叉积f的方向。
可选的,所述预测和自适应场景建模模块维持或降低以下各项中的至少一项:成像仪分辨率、动态范围和在没有显着项的区域内的帧频。
本发明所取得的有益效果是:
1.通过采用在所述场景模型中进行采集使得对场景模型中的各个物品进行细致的掌握,保证场景的完善的建立,保证所述摄像头还在实时的对所述场景中的物品进行实时检测,并对重要目标进行检测,获得所述检测框;
2.通过采用所述模型进行网络的提取,使得所述场景模型达到深度学习的目的,使得所述摄像头和所述场景模型能够进行实时或者智能的监控,保证所述场景模型对所述特征向量的高效的提取;
3.通过采用所述识别库中预置若干中危险动作类型使得所述摄像头在实时进行监控的过程中,能够对所述危险动作进行识别,在识别的过程中,所述摄像头监控到的实时画面中的动作向量与预置进行所述识别库中的动作向量进行对比,若存在相同,则进行报警,如果不相同,所述摄像头继续监控;
4.通过采用多个图像传感器,所述图像传感器采用多个传感器的组合形式形成传感器矩阵,使得对图像进行实时的采集,保证对所述图像的采集的效率;
5.通过采用所述检测框能够进行标红处理使得所述摄像头进行着重的注意,使得所述检测框中的物体能够进行实时的检测,保证对所述人物的动作进行识别;
6.通过采用众多图像数据模型以支持预测场景理解来预测即将到来的成像参数变化的措施,标识或预测第一个图像帧中区域中的显着类型是什么,并识别没有任何显着项目的区域,并向传感器控制单元发送指导成像仪分辨率、动态范围和帧速率,最适合具有显著区域内类型,并保持或减少所述成像器分辨率、动态范围或者区域内没有显著特征的帧频,使其不超过带宽限制。
附图说明
从以下结合附图的描述可以进一步理解本发明。图中的部件不一定按比例绘制,而是将重点放在示出实施例的原理上。在不同的视图中,相同的附图标记指定对应的部分。
图1为本发明的程序流程图。
图2为本发明的控制流程图。
图3为本所述场景模型的建模方法的控制流程图。
图4为所述检测框的选取方法的控制流程图。
图5为所述网络提取的方法的控制流程图。
图6为所述网络的训练方法的控制流程图。
图7为所述动作向量提取方法控制流程图。
具体实施方式
为了使得本发明的目的.技术方案及优点更加清楚明白,以下结合其实施例,对本发明进行进一步详细说明;应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。对于本领域技术人员而言,在查阅以下详细描述之后,本实施例的其它系统.方法和/或特征将变得显而易见。旨在所有此类附加的系统.方法.特征和优点都包括在本说明书内.包括在本发明的范围内,并且受所附权利要求书的保护。在以下详细描述描述了所公开的实施例的另外的特征,并且这些特征根据以下将详细描述将是显而易见的。
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”.“下”.“左”.“右”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或组件必须具有特定的方位.以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
实施例一:一种基于yolo的动作实时监测方法,所述监测方法包括以下步骤:s1:建立场景模型,所述场景模型被配置为对摄像头所处位置进行视频采集;s2:对所述场景模型中的目标检测,获得检测框;s3:构建并训练深度学习提取网络,将所有的人物的检测框输入到该网络,得到所有检测框的特征向量;s4:预测视频跟踪目标的动作向量,利用检测框的特征向量和预测的动作向量对跟踪目标进行危险动作匹配或预测,得到最佳匹配和预测检测框;s5:对危险动作的目标检测框进行标红处理;s6:报警提示。在本实施例中,所述摄像头采用〖yolov〗_3摄像头,保证对场景进行实时的监控,并保证危险动作的识别达到精准的效果。所述〖yolov〗_3摄像头兼顾实时监控和动作识别的工作,达到最佳的识别效果。
实施例二:一种基于yolo的动作实时监测方法,所述监测方法包括以下步骤:s1:建立场景模型,所述场景模型被配置为对摄像头所处位置进行视频采集;s2:对所述场景模型中的目标检测,获得检测框;s3:构建并训练深度学习提取网络,将所有的人物的检测框输入到该网络,得到所有检测框的特征向量;s4:预测视频跟踪目标的动作向量,利用检测框的特征向量和预测的动作向量对跟踪目标进行危险动作匹配或预测,得到最佳匹配和预测检测框;s5:对危险动作的目标检测框进行标红处理;s6:报警提示。具体的,本发明公开了一种基于yolo的动作实时监测方法,主要是为了解放人工监视监控的繁重工作以及对生产线上危险动作的实时监视。本方案实现如下:1)首先对社区,工地以及流水线上关键摄像头的视频采集;2)对视频中出现的人物进行目标检测,yolo强大的检测能力,能够对视频中出现的人物进行实时检测,并获取出现的人物的检测框;3)构建并训练深度学习提取网络,将所有的人物的检测框输入到该网络,得到所有检测框的特征向量;4)预测视频跟踪目标的动作向量,利用检测框的特征向量和预测的动作向量对跟踪目标进行危险动作(如吸烟)匹配或预测,得到最佳匹配和预测检测框;5)对危险动作的人物目标检测框进行标红处理,并存储该人物目标的正面帧图片或特征图片,向值班人员发出监控预警和监控现场的警告响声。进一步的,将yolo目标检测算法应用到视频监控当中,并对检测到的人物进行动作学习,建立危险动作库以及预警画面库,预测监控中人物下一个画面将出现的动作;对监控场景进行细化,本方法将主要运用在以下三个场景:深夜的小区视频监控,对偷盗、入室偷窃、尾随等危险画面进行监控和预警;工地禁止吸烟场所下,对工人危险吸烟行为进行监控;工厂流水线监控,监控流水线上工人对机器操作的动作,当工人操作不当或将发生危险时,及时做出预警,并且可以监控流水线上非工作工人等闲杂人等画面,保护关键技术和机器操作;当系统对人物目标框做出危险预警时,云端数据平台将存储此人物的正面高清图片或危险动作的视频片段;危险预警与实地摄像头预警相结合,实时且有效。在本实施例中,所述yolo优选的采用型号为yolov3。
在本实施例以外的场景中,还可以应用到教育行业中,有效解决现在大部分的教室都安装有监控,但是繁杂的人工筛选画面甄别学生是否有作弊行为,已经不适合当前的大型考试监控防作弊行为以及作弊追责,繁杂以及超多的画面和时常,人工的甄别已经远远不能做到准确和实时了,急需一种智能的监控,实时检测监控中目标的行为并预测目标的行为动作是否属于“危险”动作。在所述场景模型中,通过所述摄像头进行数据侧采集,使得所述场景的模型能够进行建立。在本实施例中,所述摄像头设有景深摄像头,使得所述场景摄像头能够进行各种场景的收集,另外,所述场景模型的建立基于实时的视频的采集,使得所述摄像头所处的位置的图像或者视频能够被用于场景的建立。另外,在本实施例中,所述图形和所述视频采集后通过场景模块进行场景模型的构建,使得所述场景包括场景的标识、场景位置和场景中标志物的分布。通过在所述场景模型中进行采集使得对场景模型中的各个物品进行细致的掌握,保证场景的完善的建立。在所述场景模型被建立后,所述摄像头还在实时的对所述场景中的物品进行实时检测,并对重要目标进行检测,获得所述检测框。所述检测框用于对重点人物进行识别。识别的参数包括:人物的性别,脸型和动作等。另外,在进行所述场景模型的建立后,要想达到对特定场景的特定的人物进行需要对所述场景模型进行训练,具体的,需要对所述模型进行网络的提取,使得所述场景模型达到深度学习的目的。使得所述摄像头和所述场景模型能够进行实时或者智能的监控,保证所述场景模型对所述特征向量的高效的提取。在本实施例中,对所述检测框中的人物或者动作进行检测,并生成相应的特征向量。在本实施例中,还设有识别库,所述识别库中预置若干中危险动作类型使得所述摄像头在实时进行监控的过程中,能够对所述危险动作进行识别。在识别的过程中,所述摄像头监控到的实时画面中的动作向量与预置进行所述识别库中的动作向量进行对比,若存在相同,则进行报警,如果不相同,所述摄像头继续监控。另外,在存在危险动作后,所述检测框就会对所述场景模型中的任务或者动作进行标红处理,使得存在相似动作进行报警提示。所述报警提示包括但不局限于以下列举的几种情况:蜂鸣器报警、指示灯报警和警示语音报警等。在本实施例中,在整个系统中还设有处理器,所述处理器与所述摄像头控制连接,所述处理器与报警装置进行控制连接,所述报警装置被配置为发出警示音用于度报警提示进行提示的效果,在本实施例中,所述警示装置用于对所述报警提示进行集中的控制。在本实施例中,所述摄像头也能够采用多个图像传感器,所述图像传感器采用多个传感器的组合形式形成传感器矩阵,使得对图像进行实时的采集。另外,在本实施例中,还设有若干各个图像预处理器和分析模块,每个图像预处理器可以复用到传感器选择器和合成器模块中,传感器选择器的输出可以连接到图像场景理解和分析模块。图像场景理解和分析模块的输出可以连接到预测和自适应场景建模模块,该模块为传感器控制单元馈电,该传感器控制单元耦合并向图像传感器提供动态反馈。每个图像处理器可以包含至少其自己的具有像素的图像传感器或与之协作。每个图像预处理器可以具有多个图像传感器,例如四边形传感器、单个图像传感器,但是随后将两个或更多图像处理器配置为在分布式工作体系结构中一起协作。两个或更多个图像处理器包括:第一图像预处理器,其具有自己的带有像素的图像传感器,例如图像传感器一以及第二图像预处理器,其具有自己的图像、具有像素的传感器,例如图像传感器二等。这两个或更多图像预处理器可以在分布式工作体系结构中共同协作,以捕获每个图像处理器的不同区域中的任何一个,与一个图像处理器重叠的区域中的任何一个捕获第一图像帧的基本视频以及任何一个两者的组合。
所述场景模型的建模方法包括收集检测装置的场景图形、收集图形帧数和收集图像的像素,跟踪所述图形帧数的趋势并把所述趋势应用在分析装置中,所述分析装置把收集的场景图像进行区域的划分,所述区域包括第一图形帧的第一区域和第一图形帧的第二区域,所述第一区域被配置为对同一第一图形帧中的第二区域中收集像素数据的像素参数,并使用传感器控制单元调整输出像素数据速率。具体的,整个系统中还设有传感器控制单元,所述传感器控制单元与图像传感器协作以在一个图像帧内为一个或多个图像预处理器创建多个区域。因此,一个图像帧内的多个区域。捕获该图像帧的每个区域都包含自己的一组像素,以捕获像素数据。所述传感器控制单元可以与一个或多个图像预处理器协作,以能够改变像素的每个区域的操作模式以控制该区域的像素参数。所述像素参数包括:帧速率、分辨率、图像大小、积分时间等中的任何一个。所述图像处理器可以将例如多个区域中的第一区域中的像素参数设置为与同一图像帧内的第二区域中的像素参数不同。
所述检测框的选取方法包括:通过边缘检测算法得到图像的边缘图,并通过优化处理器进行优化得到轮廓图;通过轮廓图获取图像的超像素点,任意两个相邻的区域之间均有一个不相似度值;对获取的区域进行整合,将边沿图和所述轮廓图进行两两合并,并利用场景模型输出像素与所述不相似度值进行整合,得出重叠的部分得到最终的检测框。具体的,在本实施例中,所述检测框能够进行标红处理使得所述摄像头进行着重的注意,使得所述检测框中的物体能够进行实时的检测,保证对所述人物的动作进行识别。在本实施例中,所述检测框的选取方式通过检测算法得到图像的边缘图,并通过所述处理器对所述边缘图进行处理,并在所述边缘图中对所述超像素点进行识别并选取两个相邻区域内的一个不相似度值进行提取。对所述不近似值进行提取,使得所述检测框与所述检测框周围的其他图像的像素点进行区别开来,使得所述检测框中的重点像素点能够进行凸显。另外,在所述边沿图和所述轮廓图之间进行合并,并利用us噢书场景模型实时检测的图像进行对比,优选的采用最优的图像作为检测框。在所述检测框选取出来后,所述检测框在所述处理器的控制下所述场景模型中的人物或者动作进行识别。对特定所述动作进行识别的过程中,需要对所述处理器和所述摄像头和所述检测框之间进行联动,使得对动作的识别达到精准控制的效果。另外,在所述检测框对所述动作或者人物进行识别的过程中,需要对所述人物或者所述动作的网络进行识别,达到精准监控和识别的效果。
所述网络提取的方法包括:从构成所述第一图像帧的所有区域中收集所有图像像素数据,从所述第一图像帧中重新组装图像像素数据;获取与第一图像帧相关的标识符,针对第一图像帧以不同的周期收集第一区域和第二区域。具体的,所述第一图像帧的区域内中收集所有的图像像素的数据,并在所述第一图像帧中的各个所述图像像素的数据进行重新的组合,使得所述网络能够进行构建。另外,在已经构建的网络中进行第一图像帧的标识,并获取所述第一图像帧中的标识符,所述标识符的认定在由控制算法进行认定,所述控制算法认定所述标识符就是识别所述第一图像帧中的高像素点进行识别并把该高像素点进行标注,用于作为第一图像帧中的标识符。所述第二区域是从所述第一区域中的不同周期进行收集图像。在各个周期中收集的各个所述第二区域包括所述第一区域中不被所述控制算法进行标记的区域,在所述控制算法没有被选中的区域中,所述第二区域就会存储特定的存储器中,使得所述处理器随时的进行调用。
所述网络的训练方法包括:通过众多图像数据模型以支持预测场景理解来预测即将到来的成像参数变化的措施,标识或预测第一个图像帧中区域中的显着类型是什么,并识别没有任何显着项目的区域,并向传感器控制单元发送指导成像仪分辨率、动态范围和帧速率,最适合具有显著区域内类型,并保持或减少所述成像器分辨率、动态范围或者区域内没有显著特征的帧频,使其不超过带宽限制;并在内存存储、功耗限制、图像传感器、传感器控制单元和图像处理单元之间的通信回路。具体的,预测和自适应场景建模模块与传感器控制单元之间存在双向通信回路,以识别先前图像帧中一个或多个区域中的显着性,例如,图像质量方面的重要项目,或预测当前图像帧或未来图像帧中一个或多个区域中的显着项,然后将指南发送到传感器控制单元,以将第一区域中像素集的像素参数更改为与基于显着项的存在或预测存在的第二区域中的像素集合在例如第一区域中而不在第二区域中。在本实施例中,在训练的过程中采用自适应传感器和合成器,自适应传感器参数设置:这些参数用于优化某些感兴趣场景区域中的视觉信息。例如,如果期望在特定区域中具有提高的空间分辨率,则hsr图像传感器即使在较低的帧速率下也能够提供该分辨率。设置确定将哪个图像传感器的像素数据输出用作背景,以及将哪个其他图像传感器的像素数据输出裁剪并粘贴到背景视频中,以优化合成场景中的可操作视觉信息。合成器模块可以:从潜在的多个传感器输入中接收多个区域,并使用帧缓冲器来在空间上对齐每个区域输出的像素数据,并且在时间上对齐每个区域输出的像素数据,然后裁剪和将一个或多个选定区域的输出像素数据中的像素数据粘贴到第一个图像帧的背景视频库中。合成器模块可以使用自适应感兴趣区域设置来确定哪个区域的输出将用作图像帧的背景基础,以及哪个其他区域的像素输出数据将被裁剪并粘贴到图像帧的背景基础中捕获具有该区域显着项的区域时。合成器模块还能够从构成图像帧的所有区域中收集所有图像像素数据,然后合成器模块被配置为至少从在不同周期收集的各个区域中为图像帧重组图像像素数据,使得与该图像帧相关的标识符。特别的,如果图像传感器已使用已知的视野进行了预校准,则可能不需要实时空间对齐。它们只需要校准一次对于固定的视野,或者每当视野发生变化时,例如,任何镜头焦距发生变化都需要进行校准。
所述动作向量提取方法包括:通过传感器进行识别场景环境中的人物的动作,把所述动作进行模型的建立,并在所述模型中进行动作的元素的建立,并预测所述动作的运动趋势;通过传感器以一定的间隔周期进行所述动作数据的采集,并与所述模型的预测的动作对比,并存储在事件模型中;基于所述事件模型中的动作数据提取动作姿势分析,对所述姿势向量进行提取,得出动作矩阵集合,并带入公式(1)中,得出所述动作向量,
其中,θ为向量y和向量g之间的夹角,ζζ为动作矩阵叉积f的方向。具体的,在人物活动的过程中,对所述动作向量进行识别,使得所述摄像头能够进行识别出该动作是否规范,是否得体。在本实施例中,各个所述动作被存储在存储器中,所述存储器中的动作包括事先预置在所述存储器中的动作和在监控的过程中被存储的动作。本实施例中,所述向量的提取在所述传感器以一定周期的间隔内进行数据的采集,采集的数据包括但不局限于以下列举的几种:动作向量的方向、动作向量的转折趋势和预测动作的趋势等。在本实施例中,各个所述动作向量组成动作向量矩阵组,公式(1)中代入所述动作矩阵的向量组,使得所述动作向量得出最终的动作向量。在本实施例中,公式(1)中设有的需要向量y和向量g之间的夹角,以及所述向量y和所述向量g的数据,另外,所述动作向量在所述事件模型中进行得出,所述事件模型包括摄像头中实时监控得出的动作向量的数据,另外,所述姿势分析由所述处理器或者专门负责动作分析的控制器,在本实施例中,优选的采用专门负责的控制器,使得分担所述处理器的控住效果,保证控制器的对所述动作姿势分析的有效性。
所述预测和自适应场景建模模块维持或降低以下各项中的至少一项:成像仪分辨率、动态范围和在没有显着项的区域内的帧频。具体的,图像处理单元可以具有从图像处理单元到传感器控制单元的低等待时间的反馈通信回路。传感器控制单元将像素参数反馈提供给图像处理单元,以便同时独立地更改成像器分辨率、动态范围和图像帧中不同关注区域内的帧频。预测和自适应场景建模模块耦合到传感器控制单元识别和预测图像帧中一个或多个感兴趣区域中的显着项,然后将指导发送到传感器控制单元增加以下各项中的至少一项:成像仪分辨率,动态范围和具有显着项的区域内的帧频。预测和自适应场景建模模块还可以将指南发送给传感器控制单元,以便然后保持或降低以下各项中的至少一项成像仪分辨率、动态范围和没有显着项的区域内的帧速率,以便不超出任何带宽限制内存存储和一个或多个图像传感器或传感器之间的通信环路施加的功耗限制控制单元和图像处理单元。预测和自适应场景建模模块与图像场景理解和分析模块相互配合。这些模块协作以分析每个图像帧中需要在该图像帧内以更高的成像器分辨率,动态范围和/或帧频进行最佳捕获的感兴趣区域,因为它们包含一个或多个显着项,而同时还有其他项不太重要的关注区域,仅包含不突出的项目,可以使用默认像素参数设置,如:图像帧内的成像器分辨率、动态范围和、帧速率,捕获减少的图像细节,以保持在任何之内带宽限制、存储器存储和一个或多个图像传感器施加的功耗限制,其中像素捕获组成图像帧的感兴趣区域中的像素数据,以及任何带宽限制、存储器存储和、传感器控制单元和图像处理单元之间的通信环路施加的功耗限制。
综上所述,本发明的一种基于yolo的动作实时监测方法,通过采用在所述场景模型中进行采集使得对场景模型中的各个物品进行细致的掌握,保证场景的完善的建立,保证所述摄像头还在实时的对所述场景中的物品进行实时检测,并对重要目标进行检测,获得所述检测框;通过采用所述模型进行网络的提取,使得所述场景模型达到深度学习的目的,使得所述摄像头和所述场景模型能够进行实时或者智能的监控,保证所述场景模型对所述特征向量的高效的提取;通过采用所述识别库中预置若干中危险动作类型使得所述摄像头在实时进行监控的过程中,能够对所述危险动作进行识别,在识别的过程中,所述摄像头监控到的实时画面中的动作向量与预置进行所述识别库中的动作向量进行对比,若存在相同,则进行报警,如果不相同,所述摄像头继续监控;通过采用多个图像传感器,所述图像传感器采用多个传感器的组合形式形成传感器矩阵,使得对图像进行实时的采集,保证对所述图像的采集的效率;通过采用所述检测框能够进行标红处理使得所述摄像头进行着重的注意,使得所述检测框中的物体能够进行实时的检测,保证对所述人物的动作进行识别;通过采用众多图像数据模型以支持预测场景理解来预测即将到来的成像参数变化的措施,标识或预测第一个图像帧中区域中的显着类型是什么,并识别没有任何显着项目的区域,并向传感器控制单元发送指导成像仪分辨率、动态范围和帧速率,最适合具有显著区域内类型,并保持或减少所述成像器分辨率、动态范围或者区域内没有显著特征的帧频,使其不超过带宽限制。
虽然上面已经参考各种实施例描述了本发明,但是应当理解,在不脱离本发明的范围的情况下,可以进行许多改变和修改。也就是说上面讨论的方法,系统和设备是示例。各种配置可以适当地省略,替换或添加各种过程或组件。例如,在替代配置中,可以以与所描述的顺序不同的顺序执行方法,和/或可以添加,省略和/或组合各种部件。而且,关于某些配置描述的特征可以以各种其他配置组合,如可以以类似的方式组合配置的不同方面和元素。此外,随着技术发展其中的元素可以更新,即许多元素是示例,并不限制本公开或权利要求的范围。
在说明书中给出了具体细节以提供对包括实现的示例性配置的透彻理解。然而,可以在没有这些具体细节的情况下实践配置例如,已经示出了众所周知的电路,过程,算法,结构和技术而没有不必要的细节,以避免模糊配置。该描述仅提供示例配置,并且不限制权利要求的范围,适用性或配置。相反,前面对配置的描述将为本领域技术人员提供用于实现所描述的技术的使能描述。在不脱离本公开的精神或范围的情况下,可以对元件的功能和布置进行各种改变。
综上,其旨在上述详细描述被认为是例示性的而非限制性的,并且应当理解,以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!