一种融合语义信息的无监督学习场景特征快速提取方法与流程
本发明涉及图像处理技术领域,涉及一种融合语义信息的无监督学习场景特征快速提取方法。
背景技术:
场景特征提取常常用于提取场景中具有特异性的信息以便于从场景数据库中检索到内容一致的场景,在图像检索、视觉定位、闭环检测等领域有着广泛的应用。
面对复杂多变的场景,如何快速地从中提取稳定不变的特征显是视觉定位任务中的关键技术。手工提取特征被广泛地应用于视觉定位系统中,根据特征描述区域的大小可以分为两类:局部特征和全局特征。基于局部特征的方法,如sift、surf、orb,通过提取特征点的方式对图像进行描述,该方法因为只保留了部分细节信息而缺少整体的结构信息,导致了感知混淆,降低了局部描述符的辨别力。基于全局特征的方法表现出更好的条件不变性,如gist,通过处理整张图像来获得特征描述符,其具有良好的光照不变性,但极易受到视点变化的影响。考虑到较大的图像块保留了整个图像的条件不变性,而较小的图像块保留了图像的局部特征。因此,为了提高特征描述符对剧烈场景变化的鲁棒性,在图像的部分区域上计算全局描述符成为融合局部特征和全局特征各自优势的首选方案。
技术实现要素:
本发明主要解决的技术问题是场景识别问题中的图像特征描述问题。为解决图像中不稳定信息对场景匹配效果产生严重干扰的问题以及二值化特征描述符对复杂场景辨别力不足的问题,本发明提供一种融合语义信息的无监督学习场景特征快速提取方法。该方法通过语义分割模型去除场景中包含不稳定信息的区域,基于该区域结合像素点位置线索筛选出包含丰富空间和上下文信息的像素对,并利用无监督学习算法获取描述力强的二值化特征描述符,能够在减少特征提取运算量的同时提升场景匹配精度。
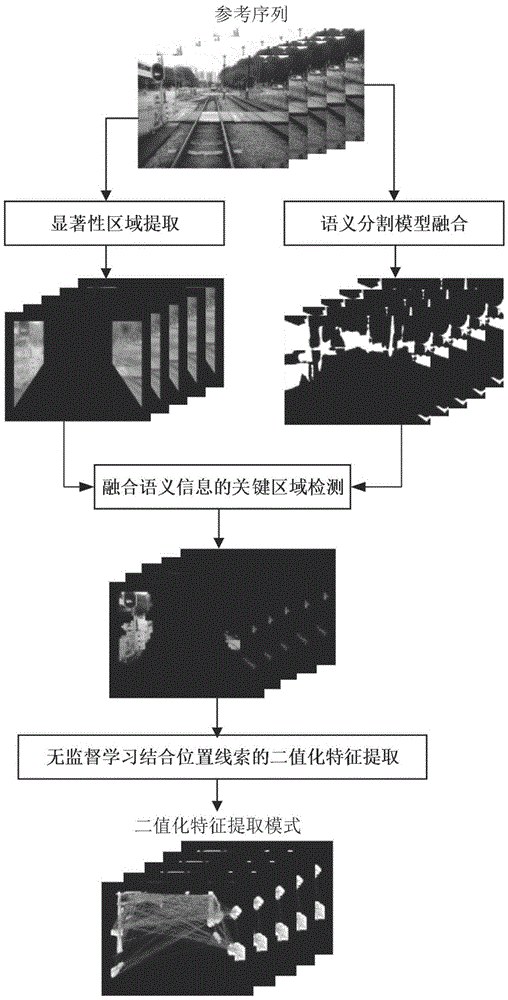
本发明所采用的技术方案是,一种融合语义信息的无监督学习场景特征快速提取方法,包括以下步骤:
步骤1:场景显著性区域提取
首先对视频帧进行预处理,将边缘模糊、扭曲的区域去除。然后使用滑动窗口对视频帧行采样,计算图像中每个像素的显著性分数sp(x,y,ft),保留高于一定阈值的像素作为初步的关键区域。
当滑动窗口位于(x,y)位置时,分别计算当前帧所包含的图像块r(x,y,ft)与其他视频帧相同位置以及其十字邻域内,共五个位置图像块r(x±1,y±1,ft')之间的差别,求和即得到当前帧该位置(x,y)的显著性分数。其中,x,y分别代表像素点在图像坐标系中的横纵坐标值;d(·)表示计算图像块之间差别的函数;ft代表需要计算显著性分数的当前帧,n为当前帧时域邻域内所包含视频帧的个数;sp(x,y,ft)是得到的像素显著性分数。
步骤2:语义分割模型融合
利用多种在cityscapes数据集上训练的语义分割网络模型对视频帧进行分割。按照特异性和稳定性的原则,在分割时,只保留所需要的六类场景分别是:建筑物、墙、电线杆、围栏、信号灯、标志牌。对不同模型分割后的结果,再通过加权融合的方式生成分割精度更高的二值化掩模。
步骤3:融合语义信息的关键区域检测
在步骤1和步骤2基础上,将利用像素显著性分数初步提取到的特征区域与融合后语义分割模型生成的二值化掩模取交集,得到最终精细化后的关键区域。
步骤4:无监督学习结合位置线索的二值化特征提取
首先,基于关键区域检测结果,利用枚举法获得像素对集合。
其次,利用时间域和空间域中像素对包含的亮度信息,计算像素对的显著性分数s(p,fq)。
其中s(p,fq)是当前帧内fq某点对p的显著性分数,d(p,fq)是当前查询帧fq内点对p的两个像素之间的灰度差,d(p,fq)是第i个相邻帧内点对p的两个像素之间的灰度差;m是相邻帧的数量。
然后引入像素点位置线索,保留包含丰富结构信息的像素对集合。提取到的像素对集合中存在两种类型的像素对:一种是两个像素来自同一个特征子区域;另一种是两个像素来自不同的特征子区域。两者二值化的结果分别保留了图像中的局部细节信息和全局结构信息。
最后,基于初步筛选后的结果,计算每个像素对的分布向量以建立k-means++聚类算法的训练矩阵。分布向量p1<p1,ft>表示了像素对集合中的第一个像素对所包含的两个像素的灰度差在视频帧fi,i∈[t-m,t+m]中的分布,
进行多次迭代训练得到聚类中心;根据聚类中心提取与其距离最近的分布向量所代表的像素对作为视频帧的特征提取模式。
本发明的有益效果是,采用融合后的语义分割模型提取到精确的场景语义特征指导显著性区域提取,减少区域中的无用信息实现对场景中包含特异性信息关键区域的检测,在减少特征提取运算量的同时提升场景匹配的精度。基于检测到的关键区域,分别采用基于像素点位置线索的筛选策略和无监督学习算法,提取到辨别能力强的二值化特征描述符,从而在有效提高场景特征提取方法对剧烈环境变化条件下的鲁棒性的同时降低计算复杂度。
附图说明
图1是本发明的融合语义信息的无监督学习场景特征快速提取方法流程图;
图2是计算像素性分数示意图;
图3是不同语义分割网络得到的结果示例,其中,(a)-(e)分别是是原始图像;deeplab模型冯结果;bisenet模型分割结果;融合后模型分割结果以及真实标定;
图4是关键区域检测结果,其中,(a)是融合语义信息前的关键区域;(b)是融合语义信息后的关键区域;
图5是基于无监督学习的快速场景特征描述算法流程图;
图6是关键区域中两种像素对示意图;
图7是二值化特征抽取模式示例;
图8是不同方法的场景匹配表现,其中,(a)-(d)分别展示了全局特征方法与本发明方法在四组场景真实标定帧中的表现。
表1是不同语义分割模型间的精度对比。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
为实现高精度、高鲁棒性的图像全局-局部特征提取,同时提升场景匹配的效率。本发明考虑到语义特征对场景中显著性区域提取的指导作用以及二值化特征描述符计算效率高的优势,公开了一种融合语义信息的无监督学习场景特征快速提取方法,流程如图1所示,具体按照以下步骤进行:
第一步:场景显著性区域提取
首先对视频帧进行预处理,将边缘模糊、扭曲的区域去除。然后使用滑动窗口对视频帧行采样,计算图像中每个像素的显著性分数s(p(x,y,ft))。
如图2所示,记当前待计算的视频帧为ft,其时域邻域内包含n个视频帧(图2中以n等于4为例)。当滑动窗口位于(x,y)位置时,分别计算当前帧所包含的图像块r(x,y,ft)与其他视频帧相同位置以及其十字邻域内,共五个位置图像块r(x±1,y±1,ft')之间的差别,求和即得到当前帧该位置(x,y)的显著性分数,如式(1)所示。其中,d(·)表示图像块之间的差别,本算法使用hog特征利用欧式距离计算得到,以减少光线带来的影响。r(x±1,y±1,ft')是其他序列帧中相同位置及十字邻域的图像块。s(p(x,y,ft))是最终得到的像素显著性分数。
显著性分数揭示了像素的显著程度。显著性分数高于一定阈值tk的像素所构成的区域将被视为初步提取的关键性区域,如公式(2)与(3)所示:
rkey(ft)={p(x,y,ft)|(x,y)∈roi,s(p(x,y,ft))>tk(ft)}(2)
其中,m是感兴趣区域中所有像素的数量,k是关于特征区域阈值的系数。
使用图像形态学操作闭操作,去除连通区域边缘的毛刺与内部的空洞,得到如图4的(a)所示,初步筛选出的关键区域。
第二步:语义分割模型融合
利用六种在cityscapes数据集上训练的语义分割网络模型对视频帧进行分割,这些网络分别是fcn、pspnet,deeplab、refinenet、dfn、bisenet。针对道路场景数据集的特点,按照特异性和稳定性的原则,在分割时,只保留所需要的六类场景分别是:建筑物、墙、电线杆、围栏、信号灯、标志牌。对不同模型分割后的结果,再通过加权融合的方式生成分割精度更高的二值化掩模。图3中对分割结果进行了可视化展示。
第三步:融合语义信息的关键区域检测
在步骤1和步骤2基础上,将利用像素显著性分数初步提取到的特征区域与融合后语义分割模型生成的二值化掩模取交集,经过图像闭运算得到最终精细化后的关键区域如图4的(b)所示。
第四步:无监督学习结合位置线索的二值化特征提取
该步骤的详细流程如图5所示。首先,基于关键区域检测结果,利用枚举法获得像素对集合。
其次,如公式(4)所示,利用时间域和空间域中像素对包含的亮度信息,计算像素对的显著性分数s(p,fq)。
其中s(p,fq)是当前帧内fq某点对p的显著性分数,d(p,fq)是当前查询帧fq内点对p的两个像素之间的灰度差,d(p,fq)是第i个相邻帧内点对p的两个像素之间的灰度差。m是相邻帧的数量。
然后引入像素点位置线索,保留包含丰富结构信息的像素对集合。如图6所示,提取到的像素对集合中存在两种类型的像素对:像素对p1中的两个像素来自同一个特征子区域;像素对p2中两个像素来自不同的特征子区域。两者二值化的结果分别保留了图像中的局部细节信息和全局结构信息。像素对来自不同区域,会包含不同的信息。保留空间相关性高的像素对会使信息缺失,为了提高描述符的区分力,需进一步筛选得到相关性低的点对。
最后,基于初步筛选后的结果,计算每个像素对的分布向量以建立k-means++聚类算法的训练矩阵。如公式(5)所示,分布向量p1<p1,ft>表示了像素对集合中的第一个像素对所包含的两个像素的灰度差在视频帧fi,i∈[t-m,t+m]中的分布,
其中
综上所述,通过语义分割模型得到的语义信息对关键区域的检测具有指导作用。利用这种全局与局部相结合的场景二值化特征提取方式,在能够有效地获取对场景外观剧烈变化具有高鲁棒性的特征描述符的同时,提高了场景匹配的计算效率。
针对nordland数据集和香港轻轨数据集,本发明选择了六种模型对参考序列进行分割,利用加权平均的方式将这些模型融合在一起。从参考序列中筛选出50个关键帧进行人工标定,将标定真值与分割得到的结果进行对比计算平均交并比,得到表1所示结果。可以看出,模型融合后得到的分割效果明显优于单个模型。对于场景更为复杂的轻轨数据集而言,效果提升尤为明显。
本发明使用了来自香港港铁(masstransitrailway,mtr)提供的轻轨数据集以及挪威广播公司(norwegianbroadcastingcorporation,nrk)公开的nordland数据集。香港轻轨数据集采集自轻轨507号路线,共包含3组视频序列,视频分辨率640×480像素,帧率为25帧/s,共包含13859帧。每组视频序列包含2段序列,这2段序列采集自同一列火车在不同时间运行在相同的路径上,有人工对齐作为真是标定。数据集中包含了诸多富有挑战性的场景,例如车辆遮挡、光照变化以及场景内容变化等。
nordland数据集包含四段视频,分别采集自春、夏、秋、冬四个季节,其场景包含城市以及自然野外等不同类型环境。采集帧率为25帧/s,分辨率大小为1920×1080像素,不同视频序列中具有相同帧号的视频帧采集自相同的位置。本文使用原始帧率从中选取10000帧作为训练和测试数据,并将视频帧降采样至分辨率大小为640×480像素。
图8展示了以归一化降采样图像为代表的全局特征描述符与本发明提出的全局-局部特征描述符在四组场景真实标定帧中的表现。图中横轴是邻近帧与真实标定位置的相对索引,左侧纵轴为基于全局特征的匹配距离,右侧纵轴为所提出方法的场景匹配分数。匹配距离越小则代表场景越相似,匹配分数越大则代表场景匹配程度越高。在基于全局特征方法的匹配结果中,包括真实标定帧附近的约10个参考帧与当前帧匹配距离均为0。这表明基于全局特征的场景匹配方法无法根据匹配距离区分高相似度场景。与此相对,使用本发明所提出的方法时,匹配分数的峰值总是出现在真实标定位置。以上实验结果证明,本发明所提出的特征提取方法能够保留场景的突出特征,对高度相似的连续场景有较强的区分力,能够对最终获得精确的定位结果起到积极作用。
表1不同语义分割模型间的精度对比
以上具体实施方式仅用于说明本发明的技术方案,而非对其限制。本领域的技术人员应当理解:上述实施方式并不以任何形式限制本发明,凡采用等同替换或等效变换等方式所取得的相似技术方案,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!