一种端到端的多任务车辆品牌识别方法与流程
本发明涉及道路监控领域,尤其是涉及一种端到端的多任务车辆品牌识别方法。
背景技术:
在道路监控领域,车辆是这个领域中必不可少的重要组成部分,是道路监控的主体,每辆车的存在都是唯一的,目前的车牌识别技术已经比较成熟,可以通过车牌信息进行识别区分,但对于道路上常常出现的假牌套牌、车牌遮挡模糊等情况还难以发现。
技术实现要素:
有鉴于此,本发明旨在提出一种端到端的多任务车辆品牌识别方法,可以识别出车辆类型信息,进一步,有效提升车辆品牌识别的精度,增加多重信息的利用,可以有效发现假牌套牌以及改装车等违法现象,为智慧城市以及道路监管提供有力辅助信息。
为达到上述目的,本发明的技术方案是这样实现的:
一种端到端的多任务车辆品牌识别方法,包括步骤:
s1.将在道路监控到的车辆图像中获得的车辆信息输入到卷积神经网络;
s2.卷积神经网络权重矩阵对输入的车辆信息进行计算,获取车辆特征信息;
s3.卷积神经网络检测器输出车标位置信息,卷积神经网络分类器输出车辆类型及车辆品牌信息。
进一步的,步骤s1中所述的车辆信息包括车标位置相关、车辆品牌相关、车辆类型相关信息,具体包括车灯信息、车辆保险杠信息、散热器栅罩信息。
进一步的,所述卷积神经网络权重矩阵采用yolo网络进行训练获取。
进一步的,所述yolo网络训练包括训练样本的准备、卷积神经网络的设计与训练和模型的优化。
进一步的,训练样本的准备包括获取图像数据和标注数据,所述图像数据覆盖每类车辆品牌的样本数据,且每类大于或等于五千张;所述标注数据是对每张图像中车标的坐标位置、车辆类型、车辆品牌进行标注,标注后以文本形式进行储存。
进一步的,所述卷积神经网络的设计基础为yolo网络,并在yolo网络的基础上进行剪裁。
进一步的,所述模型的优化是不断对模型进行迭代,以取得不断优化的模型。
相对于现有技术,本发明所述的一种端到端的多任务车辆品牌识别方法具有以下优势:
本发明对车标位置、车辆品牌以及车辆类型信息同时进行学习并输出结果,这三者之间同为车辆的相关信息,相互之间互相关联,在学习过程中可以充分有效利用这三者之间的相互关系,使得辅助任务车辆类型信息能够提供有益的效益,更加可信充分的输出车辆品牌信息,可以广泛应用于道路监控、智慧交通、智慧城市等场景,为道路监管以及城市监控提供了有效的解决方案。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
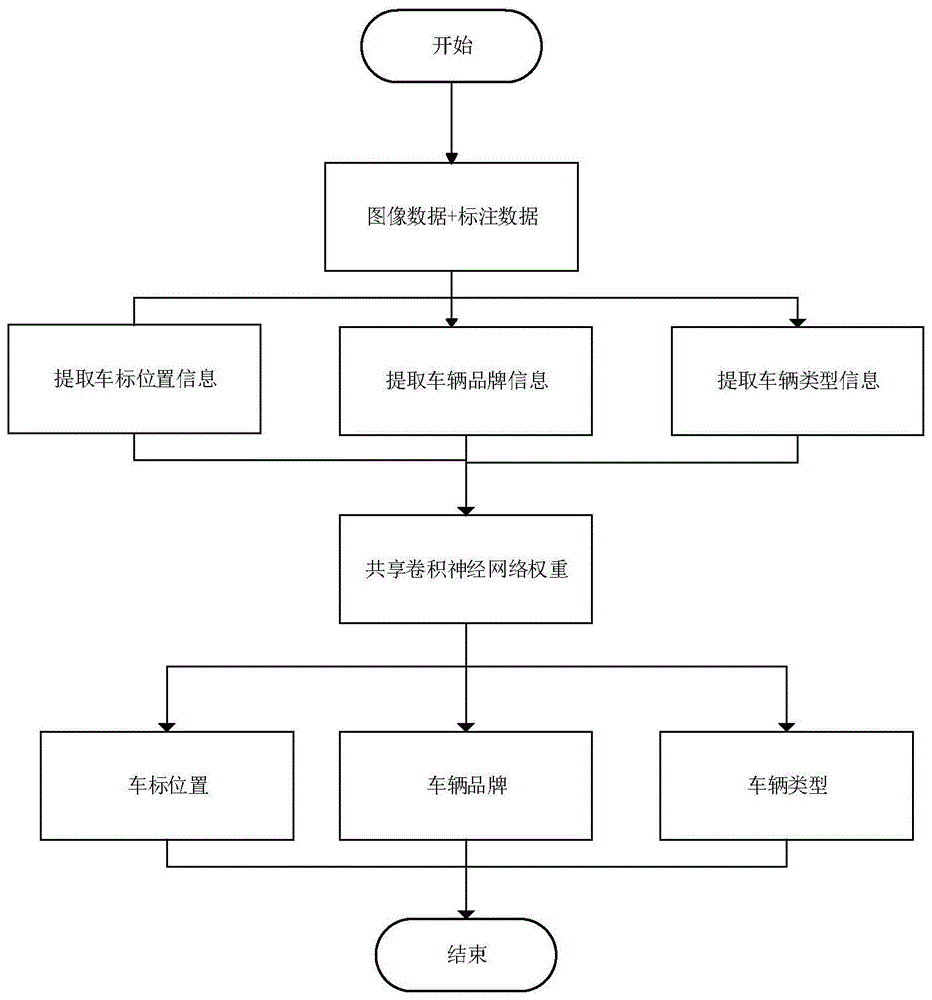
图1为本发明实施例所述的一种端到端的多任务车辆品牌识别方法流程图。
具体实施方式
下面将参考附图并结合实施例来详细说明本发明。
如图1所示,一种端到端的多任务车辆品牌识别方法,包括步骤:
s1.将在道路监控到的车辆图像中获得的车辆信息输入到卷积神经网络;
s2.卷积神经网络权重矩阵对输入的车辆信息进行计算,获取车辆特征信息;
s3.卷积神经网络检测器输出车标位置信息,卷积神经网络分类器输出车辆类型及车辆品牌信息。
步骤s1中所述的车辆信息包括车标位置相关、车辆品牌相关、车辆类型相关信息,具体包括车灯信息、车辆保险杠信息、散热器栅罩信息。
所述卷积神经网络权重矩阵采用yolo网络进行训练获取。
所述yolo网络训练包括训练样本的准备、卷积神经网络的设计与训练和模型的优化。
训练样本的准备包括获取图像数据和标注数据,所述图像数据覆盖每类车辆品牌的样本数据,且每类大于或等于五千张;所述标注数据是对每张图像中车标的坐标位置、车辆类型、车辆品牌进行标注,标注后以文本形式进行储存。
卷积神经网络的设计使用yolo网络,对yolo网络进行剪裁,剪裁后yolo网络的权重矩阵参数大小有所缩减,提高运行速率。
所述模型的优化是不断对模型进行迭代,以取得不断优化的模型。
本发明卷积神经网络获取过程如下:
i、训练样本的准备:
相关名词解释
训练样本:包括图像数据和标注数据;
图像数据:即图片数据的集合,本发明中即车辆图片数据的集合;
标注数据:描述每张图片信息的文本信息,本发明中包含车标的坐标位置、该辆车的车辆类型、该辆车的车辆品牌,每张图片对应一组描述信息;
车辆品牌:包含奥迪、宝马、大众等100类;
车辆类型:包含小轿车、小型货车、面包车、suv、皮卡、中型货车、中型客车、大型货车、大型客车9类;
训练样本主要包括以下部分:
图像数据:每类车辆品牌的样本数据,每类不少于5千张;其中,图像中车辆信息是依据车牌位置和车辆类型确定的roi区域,由于不同的车辆类型的车牌位置与车标位置、车体比例不一样,需要取不同的位置比例信息,具体实施如下:车牌位置信息为(x,y,w,h),对于车辆类型为小轿车、小货车、面包车、suv、皮卡的,取roi位置为(x-w,y-8*h,3*w,10*h);对于车辆类型为中型货车、中型客车、大型货车、大型客车的,取roi位置为(x-2*w,y-19*h,5*w,20*h)。
数据增强:为了增强网路的泛化能力,我们对已经得到的图像数据进行数据增强处理,以进一步在数量和多样性上对图像数据进行补充,处理方式包括但不限于:在亮度方面、对比度方面、饱和度方面,变换曝光度方面进行调整、以及左右旋转,本发明取左右正负5°之内的旋转;
标注数据:每张图像包含如下信息,车标的坐标位置;该辆车的车辆类型;该辆车的车辆品牌;需要人工进行标注,每张图片对应一组标注数据,以文本形式进行存储;
ii、卷积神经网络的设计与训练
由于考虑到识别效果与运行效率要同时兼顾,本发明采用裁剪后的yolo网络进行多任务训练识别,网络的输入尺寸为256*256,卷积核主要为3*3和1*1两种,用小尺寸的卷积核以最大保持图像的细粒度特征。
网络的具体配置如下:
该网络的最大特点是多尺度同时检测,分别在56层8*8、66层16*16、76层32*32的特征图上进行检测,有助于保持目标的细粒度特征,能够同时兼顾不同大小的目标的检测识别。本发明同时对车辆类型信息作为辅助任务加入训练,主要起归纳偏置的作用,有更高的抗噪能力,以获得更好的泛化能力的模型。该网络的损失函数需要综合车辆类型信息、车标位置和车辆品牌信息的损失,网络损失函数定义如下:
其中前五项,为对车标位置回归误差和车辆品牌的分类误差,第六项为车辆类型的分类误差;
s2表示网络划分网格的大小,在56层yolo输出取s=8,在66层yolo输出取s=16,在76层yolo输出取s=32;b表示每个单元格需要预测的类别数目,取b=3;c为预测的车辆品牌类别数目,即c=100;e为预测的属于车辆类型的类别数目,e=9;
λobj、λnoobj分别为单元格内存在目标和不存在目标的比重信息,防止梯度跨度大导致训练过程不收敛。本案取值λobj=5,λnoobj=0.5;
α为任务重要性因子,由于主任务为车辆品牌识别,车辆品牌分类任务为100类,比车辆类型分类任务为9类要复杂的多,所以我们在损失函数中引入重要性因子α,以做到平衡不同任务的收敛速率,本案取α=0.5;
iii、模型的优化
由于本发明主要应用于实际道路监控中,对模型的泛化能力鲁棒性有很大的要求,而我们在构建数据集的过程中,场景、光线等条件变化有限,我们需要不断扩充数据集,使之包含尽可能多的场景(不同的路口、不同的分辨率、不同的相机架设角度等条件下采集到的图像)、不同的光线变化(白天、夜间、顺光、逆光、阴天、晴天等条件下采集到的图像),不断对模型进行迭代,以取得不断优化的模型。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!