基于双向LSTM和注意力机制的软件技术债务识别方法与流程
本发明属于软件工程领域,具体涉及到一种基于双向lstm和注意力机制的软件技术债务识别技术。
背景技术:
在软件开发过程中,软件项目的最终目标是提交高质量且无缺陷的软件给用户。但是,由于资源受限或者时间不足等原因,开发人员通常会提交不完整的或临时修复的代码。这种现象被wardcunningham隐喻为技术债务,他认为这是一种以牺牲长期代码质量为代价而寻求短期收益的技术折中。与金融债务类似,技术债务也会产生利息,会影响软件的质量、成本和开发效率,因此需要开发者在未来付出额外成本来偿还。
传统的做法是开发人员手动检查软件项目,并确定哪些模块存在技术债务需要被偿还。在实际操作中,由于开发者之间实践经验不同,一些开发人员不知道自己编写的代码存在技术债务。另外,与软件系统中存在的缺陷不同,技术债务通常是看不见的,这导致技术债务不能被及时发现。近年来,越来越多的学者致力于识别技术债务,他们提出不同的技术债务识别方法。一方面,他们从源代码角度出发,通过工具分析源代码并检测代码异常,实现技术债务检测任务。另一方面,开发者会在源代码注释中记录代码中存在的问题,研究者们定义这种技术债务为“自承认的技术债务(self-admittedtechnicaldebt,satd)”,并提出了一些检测satd的方法。如基于模式的检测方法、基于自然语言处理的检测方法和基于文本挖掘的检测方法等。
然而,这些方法对技术债务识别的准确率依旧不理想,因为基于源代码分析的方法存在假阳率较高的问题,在实际中,需要人工参与,并且操作复杂,会浪费开发人员大量时间。另外,由于记录技术债务的代码注释相对较少,而且传统方法很难有效提取代码注释的文本特征,导致目前的基于代码注释的检测方法在功能和性能上都难以达到预期效果。
技术实现要素:
本发明针对现有技术的不足,提供了一种基于双向lstm和注意力机制的软件技术债务识别方法,可有效识别代码注释中的satd。
本发明具体采用的技术方案如下:
步骤(1)获取代码注释集合s=(s1,s2,...,sm),m为代码注释的数量,将其中的每个样本表示成st=<id,project,y,comment>,t=1,2,3,...,m,其中id表示代码注释编号,project表示代码注释所属项目,y表示代码注释的标签,即是否是技术债务(y=1,表示为技术债务;y=0,表示为非技术债务),comment表示代码注释的文本信息。
步骤(2)对每条comment进行预处理,包括删除完全相同的代码注释、历史修订记录、不含英文字母的字符和停用词,并转换大写字母为小写字母;经过预处理后每个样本为st=<id,project,y,precomment>,其中precomment表示预处理后代码注释的文本信息。
步骤(3)使用glove方法对预处理后的每个代码注释文本的每个单词wr生成一个d维的词向量υr。
步骤(4)设置双向lstm和注意力机制模型的参数:numberofhiddenunits(隐藏单元数)、itermax(lstm训练最大迭代次数)、batchsize(批量大小)、l2、learningrate(学习率)、将s分为训练数据集合ζtrain和验证数据集合ζves。
步骤(5)将ζtrain和ζves代码注释文本的每个单词转化为步骤(3)获得的词向量,则每一条代码注释被表示为seq={υ1,υ2,...,υn},n为最长代码注释对应的单词的个数。
步骤(6)将上述得到的seq输入到双向lstm网络层,正向lstm获得seq中单词正向特征向量
步骤(7)使用注意力机制为得到的特征向量hb的每个hk分配一个权重αk,通过计算获得处理后的新的特征向量o。
步骤(8)上述得到的特征向量o通过sigmoid函数得到每个输入样本的预测概率
步骤(9)使用类平衡交叉熵(class-balancedcross-entropy)作为损失函数计算样本真实标签值y和预测概率
步骤(10)训练上述基于注意力机制和双向lstm模型的参数,当达到最大训练次数itermax后,获得训练后的双向lstm和注意力机制模型。
步骤(11)对于一条新的代码注释,首先按步骤(2)进行预处理,然后将预处理后的代码注释输入到步骤(10)获得的双向lstm和注意力机制模型中,最终获得该代码注释的预测概率,如果预测概率大于等于0.5表示该代码注释是技术债务注释,小于0.5表示该代码注释不是技术债务注释。
本发明的有益效果:本发明使用双向lstm获取代码注释的上下文信息,同时使用注意力机制表示不同特征的重要性以提高检测satd的准确率。为了克服样本不均衡问题,本发明采用类平衡交叉熵作为损失函数,通过引入一个平衡因子减少负样本(非satd代码注释)对模型的负面影响。通过在一个公开数据集进行实验,证明了该方法在精准率、召回率和f1-score方面均优于传统检测方法。
附图说明
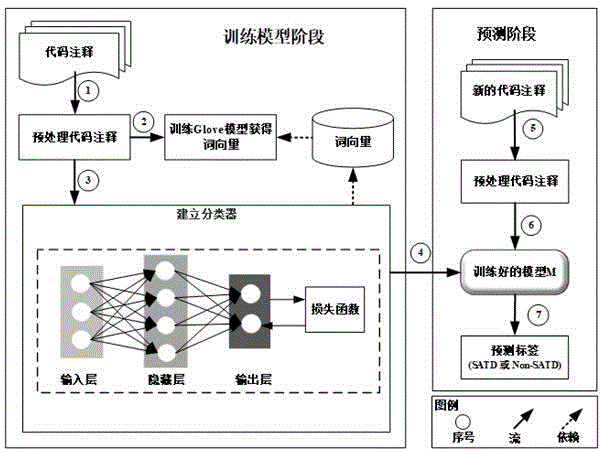
图1为方法的框架流程图;
图2为模型具体流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图1,对本发明提供的基于双向lstm和注意力机制的软件技术债务识别方法进行进一步详细说明。
步骤(1)获取代码注释集合s=(s1,s2,...,sm),m为代码注释数量,将其中每个样本表示成st=<id,project,y,comment>,t=1,2,3,...,m,其中id表示代码注释编号,project表示代码注释所属项目,y表示代码注释的标签,即是否是技术债务(y=1,表示为技术债务;y=0,表示为非技术债务),comment表示代码注释的文本信息。
步骤(2)对每条comment进行预处理,预处理过程分为以下步骤:
2-1、删除数据集中完全相同的代码注释。
2-2、删除代码注释中有关历史修订记录的信息,这部分信息通常以“xx-xx-xx:text”的文本格式,其中“xx-xx-xx”代表日期,“text”表示文本。
2-3、将代码注释中所有单词转换为小写字母。
2-4、删除代码注释中不包含英文字母的字符和停用词,不包含英文字母的字符包括:标点符号、特殊符号、数字。
经过处理后每个样本为st=<id,project,y,precomment>,其中precomment表示预处理后代码注释的文本信息。
步骤(3)使用glove方法对预处理操作之后的每个源代码注释文本的每个单词wk生成一个d维的词向量υk,其中d大小为300;
步骤(4)设置双向lstm和注意力机制模型的参数:
numberofhiddenunits:256;
itermax:50;
batchsize:64;
l2:0.01;
learningrate:0.0001;
spatialdropout1d:0.4;
ζtrain:代码注释样本90%的子集作为训练集;
ζtest:代码注释样本10%的子集作为验证集。
步骤(5)将ζtrain和ζves代码注释文本的每个单词转化为步骤(3)获得的词向量,则每一条代码注释被表示为seq={υ1,υ2,...,υn},n为最长代码注释对应的单词的个数。
步骤(6)将上述得到的seq输入到双向lstm网络层,如图2所示,正向lstm获得seq中单词正向特征向量
步骤(7)使用注意力机制为得到hb的每个hk分配一个权重αk,通过计算获得处理后的新的特征向量o,其计算公式如下;
uk=tanh(wshk+bs)
其中ws表示权重参数向量,bs表示偏置。
步骤(8)将得到的特征向量o采用sigmoid方法得到每个输入样本的预测概率
步骤(9)使用类平衡交叉熵(class-balancedcross-entropy)作为损失函数计算样本真实标签值y和预测概率
其中β为平衡因子。
步骤(10)训练上述基于注意力机制和双向lstm模型的参数,当达到最大训练次数itermax后,获得训练后的双向lstm和注意力机制模型。
步骤(11)对于一条新的代码注释,首先按步骤(2)进行预处理,然后将预处理后的代码注释输入到步骤(10)获得的双向lstm和注意力机制模型中,最终获得该代码注释的预测值,如果预测值大于等于0.5表示该代码注释是技术债务注释,小于0.5表示该代码注释不是技术债务注释。
为了验证本发明提供方法在精准率、召回率和f1-score方面的有效性,引入两个实验案例(基于文本挖掘的satd检测方法和基于自然语言处理的satd检测方法)。通过在一个公开数据集进行留一交叉验证实验,本发明方法在精准率、召回率和f1-score方面获得的平均值分别为81.75%,72.24%和75.86%;而基于文本挖掘的satd检测方法在精准率、召回率和f1-score方面获得的平均值分别为73.61%,66.75%和69.22%;基于自然语言处理的satd检测方法在精准率、召回率和f1-score方面获得的平均值分别为73.23%,67.00%和69.41%;实验结果证明本发明提供的方法,在精准率、召回率和f1-score方面均优于目前存在的检测方法。
- 还没有人留言评论。精彩留言会获得点赞!