基于大数据分析技术对环境质量进行监测的方法与流程
本发明涉及大数据分析领域,尤其涉及基于大数据分析技术对环境质量进行监测的方法。
背景技术:
随着中国工业经济的急剧发展和能源的加速开采,人们的生活质量得到了提升,同时也涌现出大量环境问题,这就使得环境监测工作变得十分迫切。
在互联网发展迅速的时代下,很多社交媒体如微博、百度贴吧和一些个人博客已经彻底改变了人们的生活方式,这些社交媒体每天都会传播很多信息,有新闻、广告和个人对环境的态度。根据中国互联网信息中心的报告显示,人们在互联网上花的时间越来越多,并且这种上升态势在将来还会持续。
在大数据环境下,我们意识到采用大数据分析技术来对各个省市不同时间段的发表在微博和百度贴吧上的关于环境问题具有情感倾向的大量信息进行分析,从而实现监测环境质量的效果。将我们的结果和中国科学院发表的中国宜居城市报告是非常吻合的,这说明我们的方式是可行的。根据以往的环境监测方法,大多都是采用传感器进行实地探测,有的安装在移动手机上,有的安装在车上,这些方法都在极大的程度上依赖传感器这些硬件,在时间和空间跨度问题上也有很大的局限性。
支持向量机是一种可训练的机器学习方法,在二分类问题上有很大的优势性。我们这里只需要挑选少量的关于环境的情感倾向信息,并通过目测判断这些信息的情感倾向,用这些信息来训练支持向量机模型。然后通过训练的模型来对不同地区不同时间段的大量关于环境问题的情感倾向进行预测。
技术实现要素:
(一)发明目的
为解决背景技术中存在的技术问题,本发明提出基于大数据分析技术对环境质量进行监测的方法,主要通过收集社交媒体上大量关于环境问题的言论,通过构建环境质量预测模型来对与环境相关言论的情感倾向进行预测,并通过一定的公式来计算环境质量指数,用来表示各个地区不同时间段的环境质量。
(二)技术方案
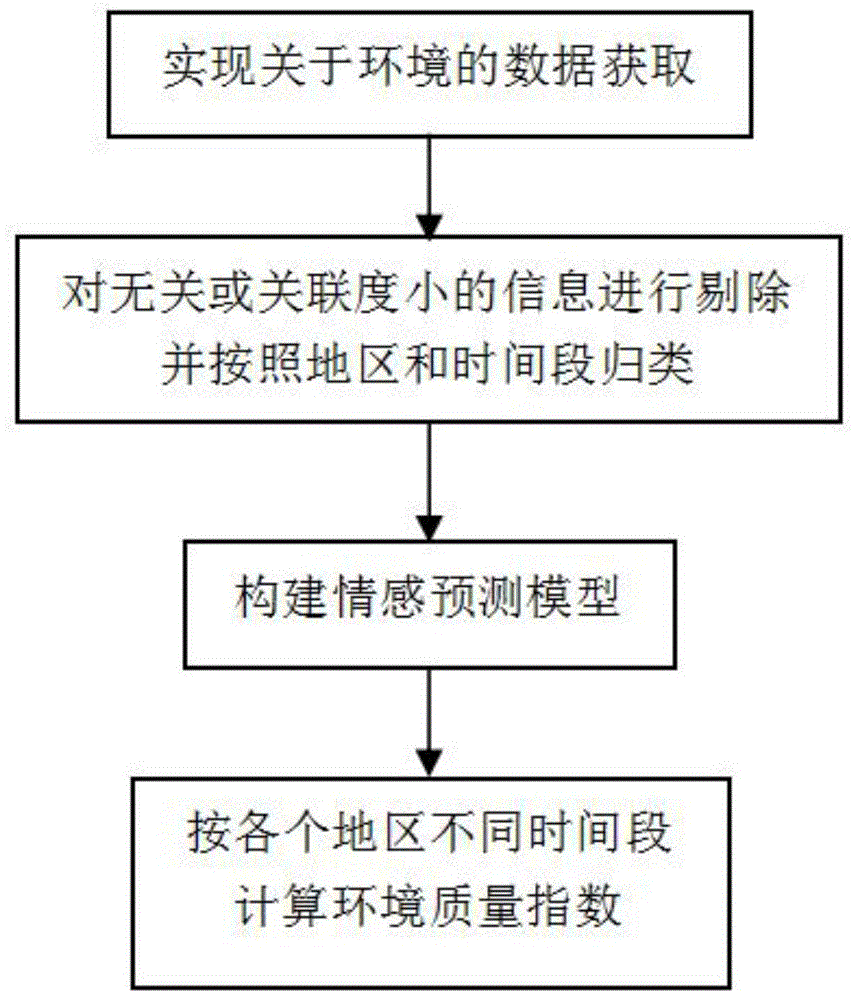
为解决上述问题,本发明提出了基于大数据分析技术对环境质量进行监测的方法,包括以下步骤:
s1:选择数据获取手段对社交媒体上的信息进行获取;
s2:对获取的数据进行清洗和按照地区和时间段进行归类;
s3:选取训练集和测试集构建高效的情感预测模型;
s4:使用情感预测模型对每条数据进行关于环境的情感倾向预测,并计算出各个省份的环境质量指数。
优选的,通过支持向量机模型实现媒体数据关于环境的情感倾向预测,以分析不同地区不同时间的环境质量。
优选的,应用于其他领域的情感倾向预测。
本发明中,主要通过收集社交媒体上大量关于环境问题的言论,通过构建环境质量预测模型来对与环境相关言论的情感倾向进行预测,并通过一定的公式来计算环境质量指数,用来表示各个地区不同时间段的环境质量。
本发明中,系统通过高效的预测性能,来分析各个地区不同时间段的情感倾向,最终通过环境质量指数计算公式来计算环境质量指数eqi,最终通过比较eqi来达到监测不同地区不同时间段的环境质量的效果。
附图说明
图1为本发明提出的基于大数据分析技术对环境质量进行监测的方法的流程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
如图1所示,本发明提出的基于大数据分析技术对环境质量进行监测的方法,包括以下步骤:
s1:选择数据获取手段对社交媒体上的信息进行获取;
s2:对获取的数据进行清洗和按照地区和时间段进行归类;
s3:选取训练集和测试集构建高效的情感预测模型;
s4:使用情感预测模型对每条数据进行关于环境的情感倾向预测,并计算出各个省份的环境质量指数。
在一个可选的实施例中,通过支持向量机模型实现媒体数据关于环境的情感倾向预测,以分析不同地区不同时间的环境质量。
本发明中,主要通过收集社交媒体上大量关于环境问题的言论,通过构建环境质量预测模型来对与环境相关言论的情感倾向进行预测,并通过一定的公式来计算环境质量指数,用来表示各个地区不同时间段的环境质量。
在一个可选的实施例中,应用于其他领域的情感倾向预测。
实施例:
s11:对数据的获取基于python3的爬虫技术,用来获取百度贴吧和新浪微博上的关于环境不同地区不同时间段的大量信息,用于在新浪微博中通过关键字搜索关于环境一段时间的微博信息,和在百度贴吧中通过递归爬取各个百度贴吧帖子的获取。
s12:对s11中获取到的数据进行清洗和归类。用于将与本次研究的主题环境问题不相关的文本信息进行剔除然后将这些文本转化为构建情感模型所需要的数据形式。本文主要采用文本排序算法,对所要研究的每一条微博和百度贴吧中的帖子进行环境主题排序,然后将一些与环境质量不相关或者相关度低的信息剔除,将那些相关度非常高的信息提出来用来做情感模型的训练集和预测集。将清洗出来的数据进行归类主要是按照各个省市不同时间段分开归类。
s13:将s12中预处理后的数据划分一部分作为训练集,用来对情感分析模型进行训练,构建能够判断文本对于环境质量的情感倾向的模型。本文对此次分类模型采用的是目前分类算法中比较好的支持向量机算法,训练过程只需要找到一个超平面就能实现情感倾向的预测。而在实现寻找情感倾向的超平面过程中我们使用的是smo算法,因为每次只是做一维优化,所以每个循环中的优化过程的效率很高。
s14:采用s13中得到的情感预测模型,用来计算环境质量指数,通过分析各个地区各个时间段中大量的数据,我们使用eqi来代表环境质量指数,其计算公式如下:
其中,t代表时间段;c代表地区;t代表文本;e(t)代表使用情感倾向模型预测文本t的值;s(c,t)是地区c时间段t中的所有文本信息。
通过以下公式来计算环境质量指数值s:
其中,f(t)代表一个省份中通过情感预测模型预测的所有数据的和的复数,c代表所有省份的所有数据集;s用来表示每个省份的环境质量,s越大说明环境质量越好。
需要说明的是,系统通过高效的预测性能,来分析各个地区不同时间段的情感倾向,最终通过环境质量指数计算公式来计算环境质量指数eqi,最终通过比较eqi来达到监测不同地区不同时间段的环境质量的效果。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!