一种基于提升树模型的学业预警方法与流程
本发明属于计算机数据挖掘
技术领域:
,具体涉及一种基于提升树模型的学业预警方法。
背景技术:
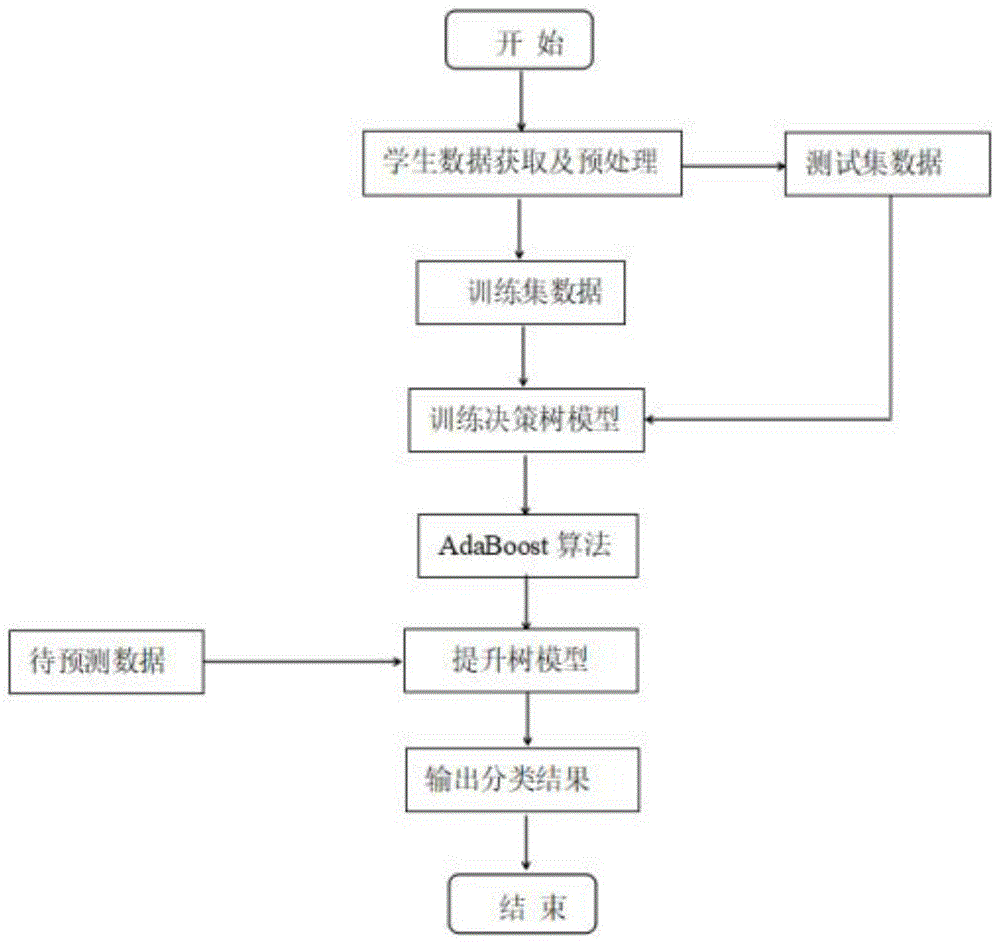
:目前随着我国高等教育的发展,经调研数据分析显示,2019年高中生通过高考,上大学的概率已经达到了百分之百,普通高等院校的数量达到了两千五百多所。但是,由于部分高校教育管理不善,学生挂科、延迟毕业甚至拿不到学位证的情况频繁发生,导致学校毕业生就业情况不佳,以至于学校生源下降,招不满学生。因此,如何提高培养学生的质量问题以及如何提高学生就业、升学的竞争能力,成为一个高校亟需解决的重要问题,其中学业成绩成为培养学生质量的一个关键性指标。在我国高校,负责学生的日常生活方面问题的是辅导员,教师主要负责学生的课程理论和专业技能教学。辅导员与教师之间缺乏有效的沟通,这可能导致一些学生因缺乏管理而忽视学习,以至于最后推迟毕业或因学习成绩差而辍学。学生的学习成绩往往受到许多因素的影响,包括学生以前的成绩、学习能力、老师的指导等。如果能够根据学生的日常生活学习作息规律,来对学生的学业进行预警,可以大幅度地减少学生挂科的概率,增加学生的就业竞争能力。同时根据对学生学业的预警,对学生可能出现的问题及时加强管理教育,为了学生能通过学术考试,这将极大地方便辅导员为学生进行教育管理,对提高学生的培养质量将起到重要的作用。在高校学业预警领域中,数据挖掘技术逐渐成为重要的研究方向,并进一步为教育领域提供了变革的动力。教育大数据作为一门新兴学科,致力于开发各种方法来探索来自教育环境的独特的且越来越大规模的数据,并使用这些方法更好的了解学生以及他们的学习环境。无论是从学生使用交互式学习环境以及计算机支持的协作学习中获取的教育数据,或是从学校获取的管理数据,这些数据通常都具有多个层次的有意义的层级结构。这些层级结构通常需要由数据本身的属性来决定,而不是预先确定。时间、顺序以及背景问题教育数据研究中发挥着重要作用。近些年来,国内外的高校越来越倡导建设以大数据和物联网为基础的“智慧校园”,即以各种应用服务系统为载体,充分凝聚教学、管理、生活、学习以及科研,实现校园工作、生活、学习一体化的环境。类似校园网、校园一卡通等设施的完善大大方便了教师和学生们的工作与生活。数据挖掘是把数据分析与统计分析相结合,然后对数据进行归纳,从数据中找出价值。学生学业预警,是通过已获取的数据源,结合相关的算法模型,从而推断出需要预警的学生,所有的方法的目的都是提高数据预测的准确率和效率。现有的高校教学管理系统中,只是对学生学习成绩数据的管理,没有意识到学生其他行为数据的管理。对学生的行为数据收集不足或者空有数据而不去利用,难以对学生学业成绩的提高起到一定的积极作用。对于学生的成绩数据,目前教学管理系统仅仅是存档录入系统,并且存入的都是往年的学生成绩数据。对学生评价只能通过过去的学业成绩进行分析,以结果去预测结果,不知道平时的生活学习状态。这样不能根本上从学生的日常生活作息规律预测,未采用相应的数据处理模型,无法实现对学生学业成绩的智能预测。同时,对现有的数据分析与信息推送中,往往只解决了上述问题的部分问题,如中国专利文献号106778054a,公布日2017-05-31,公开了一种基于数据挖掘在校学生成绩预警方法,包括获取学校已毕业学生的成绩数据并分等,采用apriori算法,挖掘成绩数据中所有符合最小支持度计数值的频繁项集,利用频繁项集得到所有的强关联规则,对在校学生的所有成绩运用强关联规则进行数据运算,得到成绩的预测和预警的发明成果。因此,传统的学生学业预警方法主要是针对上一学期挂科科目学分和累积挂科学分达到阈值的学生,对学生进行预警,准确性达到了,但是时间节点太迟,缺乏时效性。技术实现要素:为了克服上述现有技术的不足,本发明的目的是提供一种基于提升树模型的学业预警方法,通过分析学生在校移动设备终端连接网络的上网数据,提取学生的特征数据,将数据挖掘应用于对学生学业的预警,为研究者提供一种学业预警方法。为了实现上述目的,本发明采用的技术方案是:一种基于提升树模型的学业预警方法,其特征在于,包括如下步骤:步骤1、采集学生在校移动设备终端联网数据与学生成绩数据,以学生在校联网的移动终端设备mac地址与联网登录账号确定学生个体单位,以移动设备不同时间序列中连接不同地点的网络,划分出学生在宿舍区、餐厅区、图书馆区、教学楼区等不同地点的时长,并勾勒出学生在校时空行为轨迹,作为学生特征,以是否需要进行预警作为划分学生数据的标签;其中:采集学生在校移动设备终端联网数据包括:学生个体联网数据信息包括:姓名、学号、性别、身份证号、绑定移动设备终端mac地址、学生上网账号、wi-fi网络设备编号、wi-fi网络设备地理位置;宿舍区联网数据:宿舍区滞留时长、宿舍区上网内容(以与学习有无关联作为划分标准)、进入宿舍区时间、走出宿舍区时间;餐厅区联网数据:早上餐厅区滞留时间、早上餐厅区进入时间、早上餐厅区走出时间、上网内容(以与学习有无关联作为划分标准)、中午餐厅区滞留时间、中午餐厅区进入时间、中午餐厅区走出时间、上网内容(以与学习有无关联作为划分标准)、晚上餐厅区滞留时间、晚上餐厅区进入时间、晚上餐厅区走出时间、餐厅区上网内容(以与学习有无关联作为划分标准);教学楼区联网数据:非上课时间段进入教学楼区时间、非上课时间段教学楼区滞留时长、非上课时间段走出教学楼区时间、非上课时间段上网浏览内容(以与学习有无关联作为划分标准)、上课时间段进入教学楼区时间、上课时间段教学楼区滞留时长、上课时间段走出教学楼区时间、上课时间段上网浏览内容(以与学习有无关联作为划分标准);图书馆区联网数据:图书馆区滞留时长、进入图书馆区时间、走出图书馆区时间、图书馆区上网内容(以与学习有无关联作为划分标准);学生成绩数据集包括:以学生个体为单位的每周期在校联网数据对应的以学生为单位的成绩数据集;步骤2、以学生个体为单位,对数据进行清洗、集成、变换、规约等操作,得到学生规范的数据集;使用学生训练数据集与学生测试数据集,构建基于adaboost算法的提升树模型;学生联网数据特征包括:宿舍区联网时长、晚归宿舍、早回宿舍、宿舍上网内容(以与学习有无关联作为划分标准)、早餐、餐厅上网内容(以与学习有无关联作为划分标准)、上课时间段教学楼区迟到、上课时间段教学楼区早退、上课时间段教学楼区缺勤、上课时间段上网(以与学习有无关联作为划分标准)、非上课时间段教学楼区滞留时间、非上课时间段教学楼区上网(以与学习有无关联作为划分标准)、图书馆滞留时间、图书馆区上网内容(以与学习有无关联作为划分标准);划分学生数据的标签依据包括:是否需要预警作为学生分类的标签,设定阈值m(0~1),计算学生个体的加权平均成绩,班级排名最后排名(人数*阈值m)的学生及挂科的学生作为异常体,即需要预警的群体,其余的学生作为正常体,不需要预警,需要预警的学生分类标签为1,不需要预警的学生分类标签为0。分类过程如下:1)有本学期有挂科的学生直接定义为需要预警的学生,标签为1;2)排除需要预警的学生,计算剩余每个学生的综合加权平均成绩,具体如下:其中num作为该学生的该学期的课程数量,credit为课程对应的学分,grade为该课程对应的成绩分值,得到综合加权平均成绩之后,根据预警阈值n,划分学生是否需要预警,作为学生成绩的标签;对同一个学生的连续型数据特征离散化处理,简化特征数据,即是否具备这一特征,具备为1,不具备为0。已是离散型数据的特征不用处理,处理过程如下:1)针对连续性数据特征处理过程如下:获取所有学生具备的单个特征数据ai;2)所有学生特征的连续型数据相加求和并获取均值ave;3)设定阈值n,阈值及需要预警学生的比例值;4)针对早归、早退型、缺勤型特征低于阈值n乘以均值,及具备该特征;针对晚归等其他特征数据,高于阈值乘以均值的则具备该特征;计算公式如下:ai≤n*ave5)具备该特征的用1表示,不被该特征的用0表示;针对学生具有的特征数据,依次重复上述一到五步骤,对所有的特征进行离散化处理,步骤3、向构建成功的提升树模型输入待测数据,得到预警数据,分析处理预警数据并发送预警信息给相关人员。所述的上网内容是否与学习有关其特征在于:构建以有关于区分上网内容类别的词库,词类目划分为三类:学习类、娱乐类、未识别类;获取学生上网主域名,将上网主域名在词库中检索,属于学习类的则将学生上网特征定位学习类,属于娱乐类的将上网内容特征定义为上网内容与学习无关,属于未识别类的则将该学生个体的上网数据定义为上网内容与学习无关。所述的步骤2中采集学生在校移动设备联网数据,以学生个体作为单位,以是否需要进行预警作为划分学生的标签,以学生移动设备终端mac地址与学生联网登录账号确定学生个体单位,以移动设备不同时间序列中连接不同地点的网络,划分出学生在宿舍、餐厅、图书馆、教室等不同地点的时长,提取学生特征数据。所述的学生移动设备联网数据采集周期以月份为单位,一学期以四个月进行划分预测,不同月份联网数据相互独立,分别构建出适合不同月份的模型。即以月份为单位进行预警,每月月底或者第二月月初对学生提出一次预警。与现存在的技术相比,本次发明的改进效果和优点在于:本发明一种基于提升树模型的学业预警方法,包括通过采集学生在校移动终端设备联网原始数据,通过提升树模型,在对学生学业预警处理过程中,针对不同的专业的进行不同的预测,这样避免了把所有学生作为一个整体,而忽略了不同的专业,对学生的要求不同,进行针对性的进行预测。本发明一种基于提升树模型的学业预警方法,采用学生移动设备终端的上网数据进行预测,勾勒出学生的在校时空行为轨迹图,方便、直观,可以清晰的呈现给辅导员或班主任,对学生平时学习、生活情况一目了然。本发明一种基于提升树模型的学业预警方法,使用了提升树模型,提升树模型是统计学方法中预测准确率比较高的模型,根据原始数据建立样本模型,并通过输入当前月份学生的联网网信息。即可获取到学生是否需要预警的结果,该方法预测效率高、及时性高,同时该方法的样本模型具有通用性。本发明一种基于提升树模型的学业预警方法,提升树是以决策树作为基分类器,采用基于adaboost算法构成的,相对于深度学习模型以及其他模型,分析数据效率要的多,并且相对与深度学习模型不需要大量的数据就可以跑出很好的效果,效率高。附图说明图1为本发明一种基于提升树模型的学业预警方法的整体预测流程图。图2为本发明一种基于提升树模型的学业预警方法的学生数据进行转换处理具体流程图。具体实施方式以下结合实施例及附图对本发明进一步叙述,但本发明不局限于以下实施例。如图1、2所示,为本发明实施例中,提出的一种基于提升树模型的学业预警方法,本发明使用的数据能够清晰的勾勒出以学生个体为单位的学生时空校园轨迹图,较为准确的获取了学生特征数据,采用基于adaboost算法的提升树模型,把决策树弱分类器结合adaboost算法,提升为强分类器,从而达到了较高的精准率与召回率。本方案的基本流程为:一种基于提升树模型的学业预警方法,包括采集学生在校移动设备终端联网数据与学生成绩数据,以学生在校联网的移动终端设备mac地址与联网登录账号确定学生个体单位,以移动设备在不同时间序列中连接不同地点的网络,划分出学生在宿舍区、餐厅去、图书馆区、教学楼区等不同地点的时长,对学生的移动设备终端的联网数据进行分析,提取学生特征,以是否需要预警作为学生分类的标签;学生移动设备终端联网数据采集周期以月为单位,一学期以四个月进行划分预测,不同月份联网数据相互独立,分别构建出适合不同月份的模型。即以月份为单位进行预警,每月月底或者第二月月初对学生提出一次预警。获取学生移动设备终端联网数据,如下:宿舍区联网数据:餐厅区联网数据:教学楼区联网数据:图书馆区联网数据:获取学生移动设备终端联网数据后,对数据进行清理、整理如下,本次发明具体实例对于是否需要预警作为学生分类的标签,设定阈值m(0~1),计算学生个体的加权平均成绩,班级排名最后排名(人数*阈值m)的学生及挂科的学生作为异常体,即需要预警的群体,其余的学生作为正常体,不需要预警,需要预警的学生分类标签为1,不需要预警的学生分类标签为0,分类过程如下:有挂科记录的学生直接定义为需要预警的学生;(2)排除需要预警的学生,计算剩余每个学生的综合加权平均成绩,具体如下:其中num作为该学生的该学期的课程数量,credit为课程对应的学分,grade为该课程对应的成绩分值,得到综合加权平均成绩之后,根据预警阈值m为20%,加权平均成绩排名最后20%的学生划分是需要预警,即为1,其余的学生标签为0,不需要预警。作为本发明的进一步优化,提取原始数据信息中的特征数据,并对该特征数据进行分类赋值并计算赋值后的数据,以作为判断是否为预警数据的标准。在原始学生上网数据中,根据经验提取学生数据特征(未经处理)包括如下:所述的上网内容是否与学习有关其特征在于:构建关于区分上网内容类别的词库,根据主域名地址划分词类目为三类:学习类、娱乐类、未识别类;主域名识别类目为娱乐类和未识别类时,定义上网内容与学习无关。学习类娱乐类未识别类http://www.rrzxw.net/https://www.qq.com/其他https://study.163.com/https://www.taobao.com/其他https://ke.qq.com/https://www.jd.com/其他https://www.icourse163.org/http://game.163.com/其他https://www.cnki.net/https://www.tmall.com/其他https://edu.51cto.com/https://www.iqiyi.com/其他http://edu.yy.com/https://www.youku.com/其他https://www.51zxw.net/https://www.mgtv.com/其他https://xue.taobao.com/https://www.mi.com/其他http://www.kekenet.com/https://www.pinduoduo.com/其他对同一个学生的连续型数据特征离散化处理,简化特征数据,即是否具备这一特征,具备为1,不具备为0.已是离散型数据的特征不用处理,处理过程如下:1、针对离散型数据特征,计算每一个学生个体一个月具备该特征的次数并进行从高到低的排名,设定阈值n为20%,既学生具备该特征次数排名前80%的学生个体具备该特征,其余的学生不具备该特征。针对连续性数据特征处理过程如下:获取所有学生具备的单个特征数据ai;所有学生特征的连续型数据相加求和并获取均值ave;设定阈值n,特征阈值n与成绩阈值m对应,本次实例特征阈值n定为20%;针对早归、早退型、缺勤型特征低于阈值n乘以均值,及具备该特征;针对晚归等其他特征数据,高于阈值乘以均值的则具备该特征;计算公式如下:ai≤n*ave具备该特征的用1表示,不被该特征的用0表示;针对学生具有的特征数据,依次重复上述一到五步骤,对所有的特征进行离散化处理。把经过数据与处理过的数据交叉划分训练集,测试集采用训练集交叉分别训练多个决策树模型,然后以决策树为基分类器,采用基于adaboost算法的提升方法,得到提升树模型。提升树模型过程如下:提升树的线性加法模型可以表示为:t()表示单个决策树模型,m表示一共有m个决策树模型,θ表示决策树的参数,提升树算法采用前向分部算法,首先确定f0(x)=0,第m步的模型是:fm(x)=fm-l(x)+t(x,θm)对决策树的参数θ的确定采用经验风险最小化来确定:将几个决策树弱分类器组合,组合公式如下:然后,加个sign函数,该函数用于求数值的正负,数值大于0,为1;小于0,为-1,等于0,为0,得到最终的强分类器g(x)利用前向分布加法模型,adaboost算法可以看成,求式子的最小。tn时样本n对应的正确分类,fm是前m个分类器的结合。然后,假设前m-1个相关的参数已经确定,化简e可以得到:其中,αm是一个常量。然后,其中,tm时分类正确的样本的权值,mm时分类错误的样本的权值。在本发明中,基函数时分类器时分类树,使用指数损失函数,这种情况是adaboost算法的特殊情况,即将adaboost算法中的基分类器使用分类树即可。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1