一种基于web检索和新词发现的领域词典构建方法与流程
本发明涉及自然语言处理领域、深度学习领域、和web检索领域,具体是一种基于web检索和新词发现的领域词典构建方法。
背景技术:
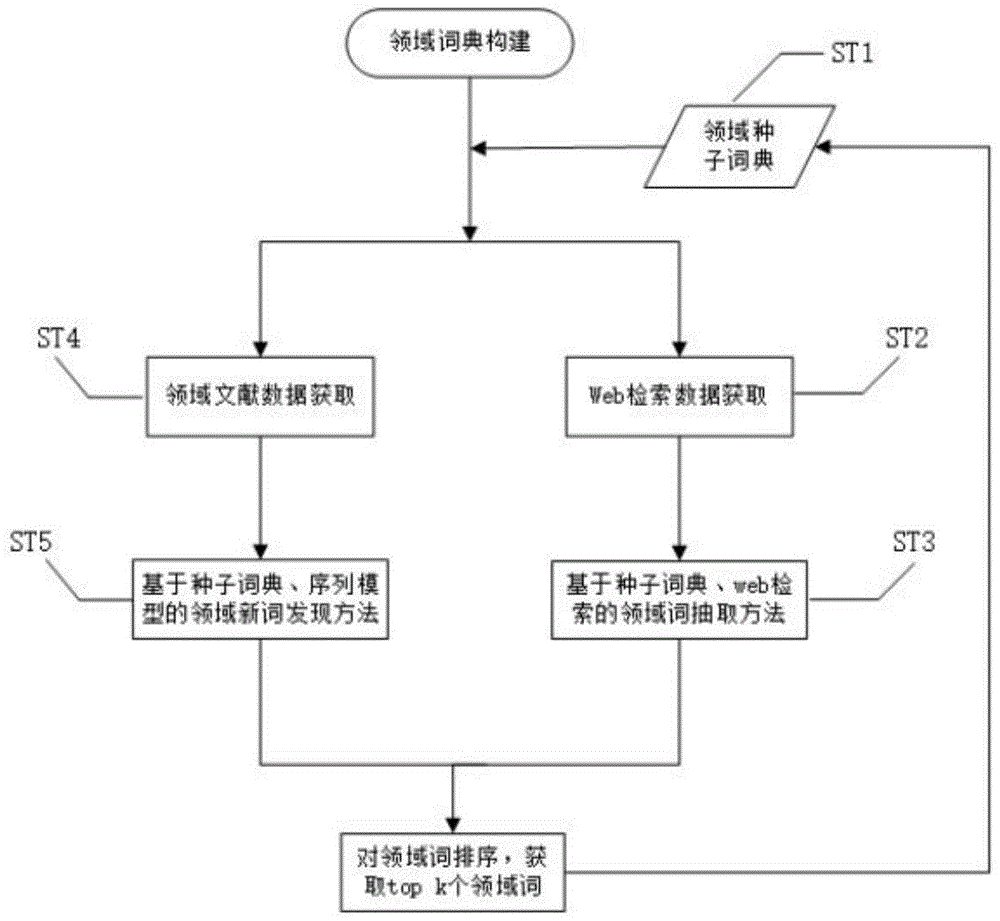
:21世纪以来,“人工智能”走进了大众视野,同时正在不断的改变着我们的生活。例如,苹果的siri,京东的仓库机器人,支付宝的二维码,百度、微软、阿里等聊天机器人,都是人工智能的体现,给我们日常生活中带来了便利。其中,自然语言处理是人工智能技术一个典型领域之一,经过多年的研究,这一领域已经获得显著的成果。如机器翻译,问答系统,阅读理解,文本生成等。这些成果中,都对词典有着不同程度的依赖。将词典抽取的对应特征词汇作为输入,基于机器学习模型或者算法,进行机器翻译,问题分析等,使得分析的可靠性大大增加。尤其在特定领域的知识问答和阅读理解,使用大而宽泛的词典,不能达到较好的分析效果。因此,快速有效的构建一个领域词典,是自然语言处理中一项重要任务。随着通信互联网技术的蓬勃发展以及web3.0时代的到来,国家政府、企业团体、互联网用户以不同的形式参与进来。国家以新闻媒体的形式,企业团体以企业网站的形式,互联网用户以讨论平台、论坛的形式分享不同领域的信息,这些信息中有着不同的领域主题,涌现大量的新词。因此,互联网是领域词典构建的一个重要信息来源。同时,特定领域的书籍,期刊等一些文献也是词典构建的一个重要信息来源。因此,从网络和书籍获取特定领域数据是有效的途径之一。领域词典构建有很多可行方法,相关研究也较多。尹文科等人基于维基百科链接结构图,集合lsi算法和cpmw算法提出了一种领域词典构建方法。然而lsi模型存在很多不足,很难选择合适的主题数,同时svd计算非常耗时,由于lsi不是一个概率模型,缺乏统计基础,结果难以直观解释。李伟卿等人提出一种构建产品特征的特征词典方法,该方法在大量的标注数据基础上,基于同义词词林扩展版和word2vec工具,计算语义相似程度,对特征进行总结,从而构建产品特征词典。然而,需要标注数据,耗时人力和时间。并且这些词典构建方法未考虑一些新词的出现。因此,在构建领域词典时,需要添加新词发现模块。传统的新词发现方法主要是基于统计的方法和基于规则的方法实现新词发现。基于统计的方法适用领域广,缺点是准确率不高,需求大量语料,计算量大。基于规则的方法是利用语言特征构建规则库,准确率高但同时构建规则过程复杂,领域迁移能力差。基于信息熵和左右熵的方法,计算两个相邻的词的相关性,更好的确定词语的粘合度和词语边界。基于bilstm-crf深度神经网络模型,能够更好的学习文本上下文,同时能够识别出更多的低频新词。因此,首先,基于web检索、种子词典抽取领域词,然后,基于bilstm-crf、种子词典、互信息和统计规则方法发现领域新词,最终构建领域词典。技术实现要素:本发明要解决的技术问题就是克服以上的技术缺陷,提供一种基于web检索和新词发现的领域词典构建方法。为了解决上述问题,本发明的技术方案为:一种基于web检索和新词发现的领域词典构建方法,包含以下实现步骤:(1)种子词典的构建;(2)基于种子词典分别在百度百科,网络新闻,论坛对种子词进行检索,获取web领域数据;(3)基于规则提取百度百科中的领域词,基于ltp中的分词方法和依存句法方法对新闻网络数据和论坛数据进行分词和依存句法分析,然后基于特定的规则进行领域词的抽取;(4)对已经抽取的领域词,进行评估和分析;(5)针对特定领域书籍进行ocr识别,获取文本文档,并对识别后的文本文档,去除案例,公式,图表等,得到特定领域数据的文本文档,并存储到文本数据库中;(6)基于ltp中的词性标注方法和依存句法分析方法对特定领域书籍数据进行分词、词性标注和依存句法分析,然后基于特定的规则进行领域词的抽取,然后针对抽取的新词,执行步骤4;(7)使用结巴分词,加载未识别词词典和种子词典,对特定领域书籍数据进行分词和标注;(8)使用互信息,左右熵对数据进行统计分析,作为序列模型输入的字向量的权重;然后基于序列模型bilstm-crf对标注好的数据进行训练,之后,使用准确率、召回率和f值进行模型评估,最后,基于训练好的模型预测新词,最后,执行步骤4。作为改进,所述步骤(1)种子词典的构建包括:首先给定一个领域范围,通过特定领域的专家进行种子词的添加或者从权威网站获取一部分领域词,作为种子词添加到种子词典中。作为改进,所述步骤(3)获取web领域数据的方法包括:基于种子词典,使用聚焦式网络爬虫方法和增量式网络爬虫两种爬虫方法。作为改进,所述步骤(3)和步骤(6)中实现数据分词和依存句法分析为:使用ltp(哈工大的语言技术平台)工具实现数据分词和依存句法分析。作为改进,所述步骤(4)中的评估方法为:评估方法主要包含两部分,一部分是对抽取模式的评估,一部分是对抽取后的领域词进行统计分析,所述抽取模式的评估可以根据它抽取的信息的准确性和数量来评估其好坏。(4.1)计算抽取的准确性,即抽取模式抽取的信息和领域的相关性,计算公式如下:其中rel-freqi是抽取模式i在相关文本中抽取的信息的数量,total-freqi是抽取模式i在训练语料库(包括相关文本和无关文本)中抽取的信息的数量,因此可以用于衡量相关性(relevantrate)。(4.2)计算抽取的数量,计算公式如下:log2(frequency)其中frequence是抽取模式从相关文本中抽取的信息的数量。(4.3)结合步骤(4.1)和步骤(4.2)的公式,用公式relevantrate*log2(frequency)来给抽取模式评分,其中当relevantrate<=0.5时,得分为0,因为该模式已经不认为与相关文本无关。(4.4)针对选择出的抽取模型,对抽取的词进行统计分析,给定一个语料库,使用文本语料库中存在的抽取模式。给定一个种子词集合,如增值税,会计,附加税等,找出所有能够抽取到种子词的抽取模式,依据抽取词和种子词之间的相关性对各个抽取模型进行打分,计算公式如下:其中score(patternk)是模式k的分数,可由抽取模式的评估方法计算得到。对于抽取信息npi能够被ni个抽取模式抽取得到,那么这个抽取信息的得分为所有能够抽取它的抽取模式的分数的总和乘以0.01再加上ni。(4.5)计算score(patternk)的公式如下:score(patterni)=ri*log(fi)其中fi为模式抽取i的到的种子集的词的去重数量。ni是抽取模式i抽取的所有的词的去重数量,表示抽取到的词与种子集合的相关性。作为改进,所述步骤(5)包括:使用python的第三方模块tesserocr对特定领域的书籍进行ocr识别,获取相应的文本文档,并存储到文本数据库中。作为改进,所述步骤(8)包括:基于互信息和序列模型bilstm-crf实现新词发现。对于每一个输入x=(x1,x2,…,xn),都会有一个预测label序列y=(y1,y2,…,yn),其中预测得分公式如下:其中为第i个位置softmax输出为yi的概率,为从yi到yi+1的转移概率,当tag(b-person,b-location…)个数为n的时候,转移概率矩阵为(n+2)*(n+2)。本发明与现有的技术相比的优点在于:本发明基于互信息和左右熵学习字与字之间的粘合度和自由度,然后基于bilstm-crf模型学习文本的上下文信息,整体提升低频词的识别率,基于检索和统计的方法,对抽取的新词和发现的词进行校验,省去人工校验,能够高抽取的领域词的质量。附图说明图1为本发明领域词典构建框架流程图,该流程图包括种子词典构建、基于种子词典、web检索的领域词抽取方法和基于种子词典、序列模型的领域新词发现方法。图2为本发明基于种子词典、web检索的领域词抽取流程图,通过该流程图实现领域词抽取。图3为本发明基于种子词典、序列模型领域新词发现流程图,通过该流程图实现领域新词发现。图4为本发明中bilstm-crf新词发现模型图。图5为本发明实施例在不同序列模型,对新词发现结果在准确率、召回率、f值的评估结果。图6为本发明的流程图。具体实施方式以下通过具体实施例进一步描述本发明,但本发明不仅仅限于以下实施例。在本发明的范围内或者在不脱离本发明的内容、精神和范围内,对本发明进行的变更、组合或替换,对于本领域的技术人员来说是显而易见的,且包含在本发明的范围之内。如图1至图5所示,本发明主要步骤分为领域种子词典构建、web检索数据获取、基于种子词典、web检索的领域词抽取方法和领域文献数据获取和基于种子词典、序列模型的领域新词发现方法,其步骤如下所示:st1:领域种子词典构建,种子词典是为领域词抽取模型和领域新词发现模型,提供一个参考基准。因此,领域种子词典的大小和好坏,将会影响最终领域词典的构建。领域种子词典的包含两种方法,其中一种是专家构建;另外一种从专业书籍获取一部分。领域种子词典大少适当(五十词左右),种子词的类型是多样性(例如,实体词典构建,词典内部尽量包含,人名,地名,机构名等。),以及词性的多样性(如动词、名词)。st2:基于种子词典实现web数据的检索。从st1获取领域种子词典,然后从百度百科、网络新闻和论坛,以种子词为检索词进行检索,之后,获取检索内容,最后,对检索内容进行文本预处理,去除网页格式,数字,字母,下划线,表情符号等一些非文本信息。其具体流程如下。(1)输入:种子词典(2)过程:for种子词in种子词典:在百度百科中,基于聚焦网络爬虫和增量式网络爬虫方法检索种子词,获取检索结果;在网络新闻中,基于聚焦网络爬虫和增量式网络爬虫方法检索种子词,获取检索结果;在论坛中,基于聚焦网络爬虫和增量式网络爬虫方法检索种子词,获取检索结果;对检索结果进行预处理,去除非文本信息,存储到文本数据中。完成一次,种子词更新。结束检索过程。st3:基于规则抽取领域词,然后基于统计方法和检索方式,对抽取词进行评估,其领域词抽取流程图如参照图2所示。首先基于st1和st2获取领域种子词典,以及从web上检索的数据。其次,构建抽取模式,将种子词典作为激活条件,激活抽取模式,最后在进行检索和统计,确定是否放入到领域种子词典中。其中,抽取模型定义如下表:种子词词性种子词与新词依存关系抽取词词性名词,动词主谓关系名词或动词名词,动词动宾关系名词或动词名词,动词间宾关系名词或动词名词,动词定中关系名词名词,动词状中关系名词其中以种子词作为激活条件,满足出去模式中的依存关系,抽取出新词,形成新的词库。然后,基于检索的方法和步骤4中抽取模式评估的方法,对词进行排序。其整体抽取方法具体如下。(1)输入:种子词典,web检索数据(2)过程:基于ltp对web检索数据进行依存分词,词性标注for种子词in种子词典:种子词激活上述抽取模式依据种子词性和新词词性抽取新词存储种子词,抽取模式,新词到文本数据库将新词作为关键词,在百度百科检索,有结果,直接放入到种子词典。基于步骤4中的抽取模式评估,对新词排序,提取前5个词,前3个放入到种子词中,后2个放入到为识别词。(3)输出:种子词典和未识别词典。st4:领域文献数据获取主要有两个方法:一种是从网络爬去文献,获取文本数据;一种是基于特定领域数据,进行ocr识别,获取特定领域的文本数据。st5:基于bilstm-crf模型和种子词典进行新词发现,其新词发现流程图参照图3所示。首先,基于st3对st4获取的数据构建未识别词典,然后,基于互信息统计字与字之间的粘合度和自由度,作为输入字向量的权重,之后,基于种子词典和未识别词典对数据进行标注,最后,基于bilstm-crf模型训练数据,发现新的领域词。其发现领域词的整体方法如下。(1)输入:种子词典,未识别词典,文献数据(2)训练领域字向量x(3)基于互信息和左右熵计算粘合度和自由度w,将wx作为模型输入。(4)基于种子词典,未识别此词典,对训练的进行标注,其标签为(b-new,i-new,e-new,o)4中标签。(5)训练bilstm-crf网络模型,训练过程如下:(5)对已经训练好的模型进行评估(6)利用训练好的模型对语料进行标注,得到新词。(7)将新词作为关键词,在百度百科检索,有结果,直接放入到种子词典。基于步骤4中的抽取模式评估,对新词排序,提取前5个词,前3个放入到种子词中,后2个放入到为识别词。(8)输出:种子词典和未识别词典。实施例一:基于web检索和新词发现的领域词典构建方法。文中采用的实验数据一部分数据是从互联网获取,基于文本文献获取的领域数据。实验环境如下:内存为16g,cpu为inter(r)core(tm)2i5-8400cpu@2.80ghz处理器,操作系统为window10系统,编程语言为python语言。测试新词发现的有效性的基本指标主要有准确率、召回率、f1值,本实验基于三种评估指标进行评估。实施例一方法使用不同的序列模型,针对新词发现,在准确率、召回率和f值方面的评估:在本实例中,其中序列的模型包括crf、lstm、lstm-crf、bi-lstm-crf四种模型,然后基于已经标注的数据,分别使用这四种模型进行训练,以及新词预测,最后,对序列模型进行对比分析。其实验结果如参照图5所示。由图5对比分析,其中单独使用crf序列模型,准确率、召回率、f值是最低的,只是学习了简单的语言模式,lstm长短型记忆模型,打破文本序列长度的限制,使得其实验结果得到提升。本发明使用的bi-lstm-crf模型准确率、召回率和f值分别是84.32、80.67和82.45,该模型学习了,上下文字之间的关系、同时打破文本序列长度的限制,因此,其效果得到了显著提升。以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1