一种自动量刑的方法和系统与流程
本发明是关于一种自动量刑的方法和系统,属于智能量刑
技术领域:
。
背景技术:
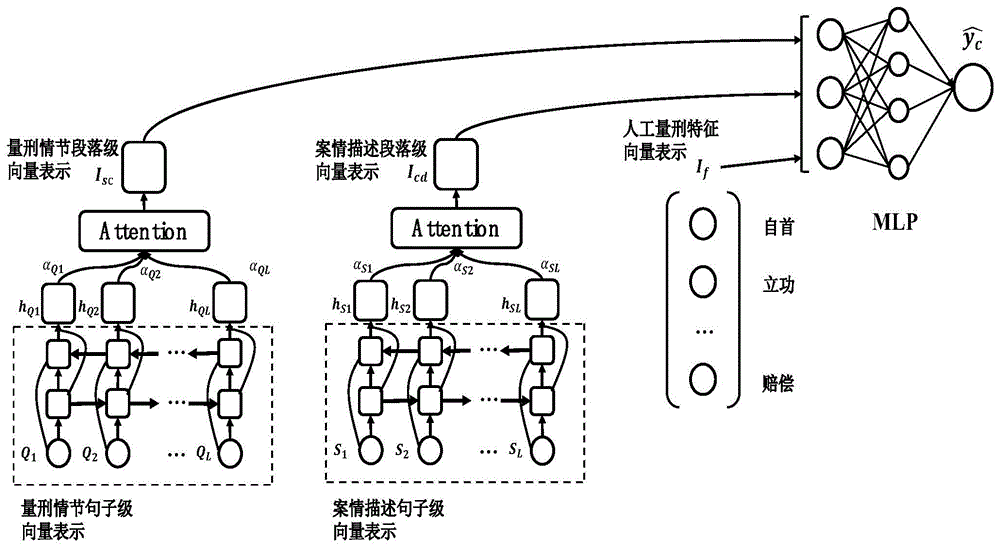
:近年来,机器学习和深度学习等人工智能技术在信息检索、文本、图像和语音处理等领域的取得显著成果,法律判决等任务的智能化引起了学界的关注。法律任务智能化不仅可以提升司法人员办案的效率也可以一定程度使司法过程更加透明、公正。法律判决智能化的两项重要任务是定罪和量刑。其中自动量刑通过给定案情描述和罪名自动预测犯罪人刑期的一项任务。量刑主要对犯罪人的主刑进行裁量,一些案件还包括附加刑的裁量。我国刑法中主刑的刑罚包括管制、拘役、有期徒刑、无期徒刑和死刑。附加刑的刑罚主要包括罚金和剥夺政治权利等。目前,智能量刑系统主要三种方法精心自动量刑,其一是采用统计和概率的方法,但此种方法会损失案情描述信息和量刑情节信息。其二是基于人工构建量刑特征的机器学习量刑研究方法,此种方法虽然提升了量刑准确率,但是存在损失案情描述语义信息等问题。第三种是基于案情描述向量表示的深度学习方法定罪预测,其虽具有语义信息、案情描述信息和量刑情节,但量刑情节中明显有一些内容对于量刑是非常重要的,而另一些则是一般性描述,对于量刑结果没有什么影响。故该方法将量刑情节无差别的进行深度学习,不仅数据处理量大,而且会弱化重要情节的重要性,导致最终输出结果偏离正确结果,导致量刑错误。本实施例将引入量刑情节权重信息,融合量刑情节层次化向量表示和案情描述向量表示及人工构建的量刑特征构建深度神经网络,从而提升量刑的准确率。技术实现要素:针对上述现有技术的不足,本发明的目的是提供了一种自动量刑的方法和系统,其引入量刑情节权重信息,融合量刑情节层次化向量表示和案情描述向量表示及人工构建的量刑特征构建深度神经网络,从而提升量刑的准确率。为实现上述目的,本发明提供了一种自动量刑的方法,包括以下步骤:s1.选定数据库,提取数据库中案情描述、量刑情节和人工量刑特征;s2.获得案情描述、量刑情节和人工量刑特征的层次化向量;s3.将案情描述、量刑情节和人工量刑特征的层次化向量作为输入基于神经网络的多层感知器,采用多层感知器的输出预测刑期。进一步,步骤s1中,还包括从选定的数据库中提取案件的实际刑期,即由法官确定的刑期,计算实际刑期与预测刑期的差值,并对差值进行打分,差值越小,分值越高。进一步,s1中提取数据库中案情描述、量刑情节和人工量刑特征包括:将数据库中提取到的文本进行分词,形成词向量,去除曾用词和停用词,并采用skip-gram算法训练对案情进行描述的词向量。进一步,s1中提取数据库中案情描述、量刑情节和人工量刑特征包括:将数据库中提取到的数据将其转换为量刑时对应的数据区间,并采用量刑时对应的数据区间对数据库中的数据。进一步,步骤s2中采用带注意力机制的bi-lstm模型生成句子级案情描述向量,根据句子级案情描述向量,通过bi-lstm模型和注意力机制得到段落级量刑情节向量。进一步,段落级案情描述向量的计算公式为:vt=wht+b其中,s是句子级案情描述向量,ht是第t个位置的隐含层向量,αt是第t个位置句子级案情描述向量的权重,vt是段落级案情描述向量,uw,w,b是随机初始化参数矩阵。进一步,s2中将量刑情节的文字内容拆分成句子,对于每个句子,采用注意力机制生成句子级量刑情节向量,并基于多个句子级量刑情节向量,采用双向长短时记忆神经网络得到段落级量刑情节向量。进一步,将每个句子级量刑情节向量拆分成若干量刑情节,对于每个量刑情节,采用注意力机制生成量刑情节向量,并基于多个量刑情节向量,得到句子级量刑情节向量。进一步,句子级的量刑情节相量的公式为:score(qt,s)=qtws其中s是句子级案情描述向量,qt是第t个量刑情节的量刑情节向量,w是训练时随机初始化的参数矩阵,αt是量刑情节权重,t是量刑情节的个数,qi是句子级案情描述向量的量刑情节,pt是第t个量刑情节对刑期影响程度的离散化表示。本发明还公开了一种自动量刑的系统,包括:特征提取模块,用于提取数据库中案情描述、量刑情节和人工量刑特征;向量获得模块,用于获得案情描述、量刑情节和人工量刑特征的层次化向量;刑期预测模块,用于将案情描述、量刑情节和人工量刑特征的层次化向量作为输入基于神经网络的多层感知器,采用多层感知器的输出预测刑期。本发明由于采取以上技术方案,其具有以下优点:(1)提出量刑情节的层次化向量表示,引入量刑情节权重信息;(2)提出一种融合案情描述与量刑情节量化信息及人工特征的神经网络模型;(3)选取量刑实践中具备代表性的盗窃罪和危险驾驶罪两种罪行,研究并抽取其量刑特征,在真实数据集上进行大量实验,并与经典机器学习模型、深度学习模型做对比,实际证明了本实施例中系统和方法对量刑任务的准确率有较大提升,能有效弥补人工抽取罪行情节特征的机器学习模型所损失的语义信息和基于案情描述的深度神经模型可能损失的量刑情节信息。附图说明图1为本发明一实施例中自动量刑的方法的逻辑关系图;图2为本发明一实施例中量刑情节层次化向量的逻辑关系图。具体实施方式为了使本领域技术人员更好的理解本发明的技术方向,通过具体实施例对本发明进行详细的描绘。然而应当理解,具体实施方式的提供仅为了更好地理解本发明,它们不应该理解成对本发明的限制。在本发明的描述中,需要理解的是,所用到的术语仅仅是用于描述的目的,而不能理解为指示或暗示相对重要性。实施例一本实施例公开了一种自动量刑的方法,如图1所示,包括以下步骤:s1.选定数据库,提取数据库中案情描述、量刑情节和人工量刑特征;s2.获得案情描述、量刑情节和人工量刑特征的层次化向量;s3.将案情描述、量刑情节和人工量刑特征的层次化向量作为输入基于神经网络的多层感知器(mlp),采用多层感知器的输出预测刑期。本方法引入量刑情节权重信息,融合量刑情节层次化向量表示和案情描述向量表示及人工构建的量刑特征构建深度神经网络,从而提升量刑的准确率。步骤s1具体操作过程如下:s1.1选择数据库本实施例使用的数据库是“中国法研杯”司法人工智能挑战赛所公开的数据集,该数据集来自中国裁判文书网。如表1所示,本实施例选取盗窃罪和危险驾驶罪的数据作为量刑研究的数据集。表1盗窃罪和危险驾驶量刑研究的数据集情况罪行训练集测试集验证集盗窃罪363,15343,16143,161危险驾驶罪336,12240,29740,297s1.2分词和词向量表示本实施例中对裁判文书中的案情描述使用jieba分词模块进行分词、去停用词处理。选取word2vec中skip-gram算法训练案情描述的词向量。在训练词向量模型时,本实施例共收集了1927872篇法律裁判文书用于训练,特征向量的维度设置为100,当前词与预测词在一个句子中的最大距离设置为3。s1.3数值离散化将数据库中提取到的数据将其转换为量刑时对应的数据区间,并采用量刑时对应的数据区间对数据库中的数据。例如盗窃罪中的盗窃金额巨大一般是以3000-5000元为起点,若案情描述中涉案金额是4235元,则离散化表示为3000-5000元。步骤s2具体操作过程如下:在以往的量刑研究中,有许多将案情描述向量表示作为量刑模型的输入,也有将人工量刑特征作为量刑模型的输入。如在上文相关工作中提到的,只有人工量刑特征会损失案情信息,只有案情描述的向量表示会损失量刑情节相关的信息。如图1模型中,模型输入由三种向量拼接组成:案情描述向量icd、量刑情节向量isc和人工量刑特征向量if。其中,s1,s2,…sl是句子级案情描述向量;icd是段落级案情描述向量。是各个句子级案情描述向量的权重;是各个句子级案情描述向量的隐含层;是句子级量刑情节向量;是句子级量刑情节向量的权重;是句子级量刑情节向量的隐含层;sc是段落级量刑情节向量;α1,α2,...,αt是某个句子级案情描述向量中量刑情节向量的权重;p1,p2,...,pt是量刑情节对刑期影响程度的离散化表示;q1,q2,...,qt是量刑情节向量。由于自动量刑任务中的案情描述通常是多个段落组成的长文本,以往工作中的案情描述表示多是基于句子级的向量表示,可能会由于文本长度损失案情信息。本实施例的案情描述的向量表示采用句子级和段落级的层次化向量表示。步骤s2中采用带注意力机制的bi-lstm模型生成句子级案情描述向量,根据句子级案情描述向量,通过bi-lstm模型和注意力机制得到段落级量刑情节向量。段落级案情描述向量的计算公式为:vt=wht+b其中,s是句子级案情描述向量,ht是第t个位置的隐含层向量,αt是第t个位置句子级案情描述向量的权重,vt是段落级案情描述向量,uw,w,b是随机初始化参数矩阵。在量刑任务中,确定刑期受多个量刑情节的影响,且不同的量刑情节有不同的影响程度。本实施例引入量刑情节的影响程度,并对其进行向量化表示。本实施例中规定量刑情节的加刑和减刑比例都在0%到100%,并将量刑情节的加刑和减刑比例量化在-100%到100%之间,设置10%为一个步长,刑期调整比例可以表示为长度为20的向量。例如某量刑情节的刑期调整比例为减刑20%到50%,其向量表示为[0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。案情描述中每个句子都可能与量刑情节有关,因此模型为每个案情描述句子引入一个量刑情节向量。由于量刑情节有多种,每个案情描述的一个的句子一般只少数几个量刑情节,即该句子对于不同量刑情节的权重是不同的。本实施例将量刑情节的文字内容拆分成句子,对于每个句子,采用注意力机制生成句子级量刑情节向量,并基于多个句子级量刑情节向量,采用双向长短时记忆神经网络得到段落级量刑情节向量。将每个句子级量刑情节向量拆分成若干量刑情节,对于每个量刑情节,采用注意力机制生成量刑情节向量,并基于多个量刑情节向量,得到句子级量刑情节向量。句子级的量刑情节相量的公式为:score(qt,)=qtws其中s是句子级案情描述向量,qt是第t个量刑情节的量刑情节向量,w是训练时随机初始化的参数矩阵,αt是量刑情节权重,t是量刑情节的个数,qi是句子级案情描述向量的量刑情节,pt是第t个量刑情节对刑期影响程度的离散化表示。量刑任务面临不同的罪行有不同的量刑情节,如何提取不同罪行相关的特定量刑特征是量刑任务面临的挑战。针对盗窃罪和危险驾驶罪,本实施例将具有大量实际案例的中国裁判文书网作为提取量刑特征的数据来源,通过对案情描述和判决依据的分析,总结出盗窃罪的17个量刑特征和危险驾驶罪的15个量刑特征,为每个量刑特征构建正则表达式从案情描述中抽取其值,并将其拼接起来构成if。量刑特征见表2、3,其详细说明如下:(1)盗窃罪的量刑特征:盗窃金额:[0,500),[500,4000),[4000,10000),[10000,50000),[50000,100000),[100000,200000),[200000,500000),[500000,1000000),[1000000,5000000),[5000000,~);退赃比例:[0,0],(0,0.3],(0.3,0.6],(0.6,0.9],(0.9,1];盗窃次数:1,2,3,4;犯罪情形:既遂,未遂,犯罪预备,犯罪中止,犯罪既遂未遂均有;其余量刑特征的维度均为一维,“0”表示否,“1”表示是。表2盗窃罪量刑特征表3危险驾驶罪量刑特征特征维度血液酒精浓度4追逐驾驶1饮酒驾驶1超速1超载1超载人数1超载比例1拒绝检查行为1载有危险化学品1无证驾驶1赔偿1自首1立功1认罪态度1谅解和解1(2)危险驾驶罪的量刑特征:血液酒精浓度:0-20,20-80,80-200,200以上;超载人数:超载数值作为特征值;超载比例:比例区间作为特征值;其余量刑特征的维度均为一维,“0”表示否,“1”表示是。本实施例中量刑任务是学习一个映射函数f:rl+n+m→r1,从而得到一个一维的刑期值。本实施例将模型输入通过一个多层感知机,多层感知机对模型输入信息到输出之间的中间向量进行不同程度的组合从而实现回归预测。多层感知机的输出表示如下:yc_pred=w[icd;isc;if]+b其中yc_pred是量刑任务中刑期的回归预测结果,w和b是模型要学习的参数。本实施例中模型训练的损失函数是huberloss,huberloss是一个经常用于回归问题的损失函数。它的主要优点是它是一种平滑近似函数,减小离群样本点的影响,提升模型的鲁棒性。本实施例从数据库中提取实际刑期yc,即法院实际判定的刑期,模型预测值是yc_pred,预测刑期值与刑期标签值之间的差值为:ei=|log(yc+1)-log(yc_pred+1)|设置得分函数s(x)便于计算样本真实值与预测值的偏离程度。刑期标签值和预测值的差值越小,得分越高。在所有样本数据上的总得分定义为:其中,n表示样本的总数,s(ei)表示第i个样本的得分,s表示在所有样本上的总得分。实施例二本实施例还公开了一种自动量刑的系统,包括:特征提取模块,用于提取数据库中案情描述、量刑情节和人工量刑特征;向量获得模块,用于获得案情描述、量刑情节和人工量刑特征的层次化向量;刑期预测模块,用于将案情描述、量刑情节和人工量刑特征的层次化向量作为输入基于神经网络的多层感知器,采用多层感知器的输出预测刑期。上述内容仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以权利要求的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1