一种双阈值顺序聚类方法与流程
本发明涉及机器学习和数据挖掘领域,更具体地,涉及一种双阈值顺序聚类方法。
背景技术:
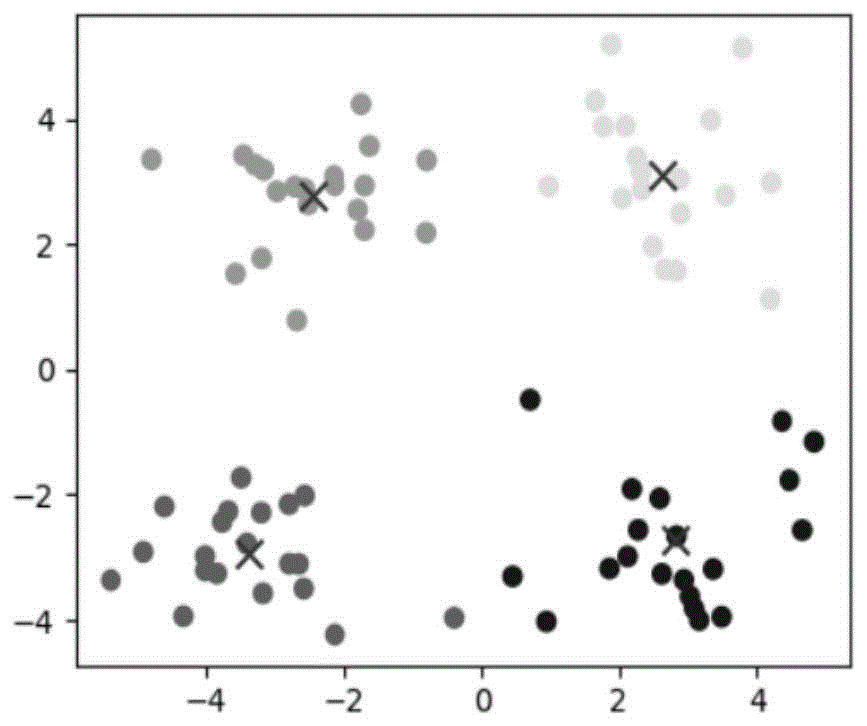
聚类是一种无监督的数据分析方法,主要处理没有先验信息的数据,广泛用于数据挖掘领域。一般认为将物理或抽象的数据对象集合分成由相似的数据对象组成的多个分组或者簇的过程被称为聚类,参见图1。图1是具有4个自然簇的二维数据,每个颜色代表一个自然分组。由聚类所生成的分组或者簇是一组数据对象的集合,同一个分组或者簇中的数据对象彼此相似,不同分组或者簇中的数据对象彼此相异。簇内数据对象越相似,聚类效果越好。
目前发展起来的聚类方法有很多种,大多为层次聚类和划分聚类。而顺序聚类算法独立于其他聚类方法,它们更直接而且更快速,适用于密集型聚类。这种算法需要把特征向量依次使用一次或多次,过程简单但也有缺点。
顺序聚类算法对整个数据集x(有n个数据/向量)进行一次扫描,每次迭代中,计算当前向量与聚类的距离。因为最后的聚类数q被认为远小于n,所以可见算法的复杂度是o(n)。
现有的顺序聚类算法阈值的设定没有依据。若阈值过小,会生成不必要的聚类;若阈值过大,那么聚类的簇数量太少,聚类效果不明显。所以阈值的选取极为关键,而这也是该算法存在的问题。
技术实现要素:
本发明提供一种双阈值顺序聚类方法,降低因阈值的不合理和随机的数据顺序而产生的正确率。
为解决上述技术问题,本发明的技术方案如下:
一种双阈值顺序聚类方法,应用于顺序聚类系统中,所述顺序聚类系统包括数据库与处理器,所述方法包括以下步骤:
s1:处理器从数据库提取数据集x={x}n,规模为n,n∈n;
s2:处理器确定阈值
s3:处理器确定聚类簇数量q的值;
s4:根据阈值
传统地顺序聚类算法依赖阈值
参考k-means的思想,定义一个平均畸变程度(将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度,计算所有簇的畸变程度得出平均畸变程度)。该定义用来衡量聚类结果的可信度。因为平均畸变程度能体现出聚类结果的可信度,畸变程度越小则说明聚类后的每个簇中点都很紧凑,符合聚类的要求,若畸变程度大,则说明聚类后的簇中点相对松散,不是很好的聚类结果。但如果过度追求可信度,将
优选地,步骤s2中确定阈值
s2.1:每次以相同的顺序表示数据,不同的阈值
s2.2:根据不同阈值
s2.3:以横坐标为
s2.4:阈值
优选地,步骤s3中确定聚类簇数量q的值,具体为:
以不同的顺序表示数据,以相同的阈值,执行多次顺序聚类,取不同顺序情况下各聚类簇数量平均值q作为聚类簇数量q。如果不定义q值,则聚类结果存在不确定性,聚类簇个数没有限制。聚类簇个数如果很大,那么聚类便没有意义。
优选地,步骤s4中根据阈值
s4.1:通过顺序排列好数据集中的所有数据,依次进行运算:
以第一个数据点作为初始质心,并归为a簇,依次算出其他点到a簇质心的距离d:
(1)若
(2)若
s4.2:后面的数据点要同时计算与现有的所有簇的质心距离,重复步骤s4.1,直到所有点都被第一次归类;
s4.3:第一次遍历数据集x’,并且留下一项x’的待分类数据集,保持已归类的数据结果,将x’中的数据依次执行步骤s4.1至s4.2,直到所有点都被归类。
优选地,步骤s4.1中质心的计算为所有数据点的横坐标和纵坐标分别加起来再分别求均值点横坐标和纵坐标。
优选地,执行创建新的簇时,检测已建立的簇个数q’是否等于q,若q’=q,则此后不再新建簇,将
优选地,步骤s4还包括:
s4.4:对聚类后的簇进行合并。
在算法运算后,可能出现两个聚类的位置离的近,所以对聚类簇的合并是很理想的。
优选地,步骤s4.4中簇的合并具体为:
定义一个距离值r,用来衡量簇之间的接近程度,比较两个簇的质心,若小于r值,则将两个簇合并。
独立的数据小的簇更适合作合并,因为如果簇内数据过多,很难定义距离值r来判断两个簇之间的相似性,而小簇被大簇同化合并更容易实现。
对于相似性的定义,当两类簇的边界样本点参与相似性计算的比例越多时,它们的相似度应该越大。反之,它们属于同一真实类簇的可能性就越小,所对应的相似度也应该越小。不难理解,以距离值为例,两个簇如果能合并,必定是有较多簇的边界样本点之间相互连接。
与现有技术相比,本发明技术方案的有益效果是:
该方法相对于其他的聚类算法,运算更快,复杂度更低;相对于基础的顺序算法,对阈值的选取有了一定的改进。阈值的选取很重要但没有依据,该方法中的范围选取法能有一定的容错率,虽然会增加一定的运算量,但能降低因阈值的不合理和随机的数据顺序而产生的正确率;该方法对聚类结果的簇数量有了限制,不再完全依赖阈值和数据顺序。
附图说明
图1为二维数据的可视图。
图2为本发明地方法流程示意图。
图3为阈值的选取结果。
图4为聚类簇合并过程示意图,(a)为聚类簇合并前,(b)为聚类簇合并后。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
本实施例提供一种双阈值顺序聚类方法,应用于顺序聚类系统中,所述顺序聚类系统包括数据库与处理器,如图2,所述方法包括以下步骤:
s1:处理器从数据库提取数据集x={x}n,规模为n,n∈n;
s2:处理器确定阈值
s3:处理器确定聚类簇数量q的值;
s4:根据阈值
步骤s2中确定阈值
s2.1:每次以相同的顺序表示数据,不同的阈值
s2.2:根据不同阈值
s2.3:如图3,以横坐标为
s2.4:阈值
步骤s3中确定聚类簇数量q的值,具体为:
以不同的顺序表示数据,以相同的阈值,执行多次顺序聚类,取不同顺序情况下各聚类簇数量平均值q作为聚类簇数量q。
步骤s4中根据阈值
s4.1:通过顺序排列好数据集中的所有数据,依次进行运算:
以第一个数据点作为初始质心,并归为a簇,依次算出其他点到a簇质心的距离d:
(1)若
(2)若
s4.2:后面的数据点要同时计算与现有的所有簇的质心距离,重复步骤s4.1,直到所有点都被第一次归类;
s4.3:第一次遍历数据集x’,并且留下一项x’的待分类数据集,保持已归类的数据结果,将x’中的数据依次执行步骤s4.1至s4.2,直到所有点都被归类。
步骤s4.1中质心的计算为所有数据点的横坐标和纵坐标分别加起来再分别求均值点横坐标和纵坐标。
执行创建新的簇时,检测已建立的簇个数q’是否等于q,若q’=q,则此后不再新建簇,将
步骤s4还包括:
s4.4:对聚类后的簇进行合并。
步骤s4.4中簇的合并具体为:
定义一个距离值r,用来衡量簇之间的接近程度,比较两个簇的质心,若小于r值,则将两个簇合并。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!