一种基于商品评论的新情感词提取方法与流程
本发明涉及文本分析技术领域,特别涉及一种基于商品评论的新情感词提取方法。
背景技术:
在信息爆炸的互联网时代,电子商务也在逐渐改变着人们的工作与生活,越来越多的人习惯于网购,各大电商平台也成为了各种商品的主要销售渠道。为了更好地了解实际评价以及完善产品服务,电子商务网站几乎都会允许顾客对其所购买地商品发表评论观点。在这些评论中,包含了消费者对产品各个属性特征的评价以及情感观点。然而,这些商品评论信息不仅可以为其他消费者提供客观全面且真实的商品描述,也可以促进产品的研发及公司的发展,从而获得竞争优势。
网络上存在海量的商品评论,这些评论中包含的大量有用信息,对这些评论进行挖掘及情感分析有着极大的实用价值。而对情感词的提取也是对商品评论进行情感分析的基本任务之一,情感词则是人们发表评价观点的最基本的语言单元。近年来,比较具有代表性的情感词典有知网情感词典(hownet)、中国台湾大学的简体中文情感极性词典(ntusd)、大连理工大学的情感词汇本体库等。但是现有情感词典在情感分析任务的使用中存在以下不足:
(1)词典的规模小。绝大部分词典的规模在一万词语以下,无法很好地覆盖这海量的评论信息。
(2)词典的词语比较传统。当前词典中几乎都是有一些已经具有明显情感倾向的词语,仍然存在一些新的或者是情感倾向不足够明显的情感词有待挖掘。例如,“好康”(褒义,释为好看)、“上头”(网络用语,释为一时冲动)。
鉴于传统的通用词典对新情感词的识别能力不够,即有些新的、小众的情感词未被发现,本发明提出了一种基于商品评论的新情感词提取方法。该方法从相邻词词性及位置角度,并结合输入法联想的特点来根据表情符号的位置来提取新情感词,还利用语法树去发现具有同位关系的其他情感词,从而扩大了情感词的覆盖率,为后续的情感分析铺垫了一定的基础。
技术实现要素:
本发明的目的是提供一种基于商品评论的新情感词提取方法,该方法具有覆盖面广、准确率高等优点。为实现该发明目的,本发明提供的新情感词提取方法,其特征在于,包括以下步骤:
步骤1:建立商品评论语料并对其进行预处理。利用分词工具对语料中的每条评论进行分词以及词性、位置标记,并根据依存关系及二元搭配抽取规则提取<主题词,评价词>二元组词对;
步骤2:对新词进行粗粒度提取。结合相邻词词性及位置、主题词和表情符号位置等特征统计旧情感词出现频率,再设置k=4的滑动窗口获取不同词性词语、主题词以及表情符号周围4个字符以内的词语。根据不同特征为候选词设置概率值,再进行概率综合计算,选择排序前30%的词作为候选新情感词;
步骤2.1:利用标注好词性和位置信息的评论作为数据集进行训练,统计情感词出现在不同词性词语周围4个字符以内的频率;利用步骤1中根据依存关系及搭配规则所提取的<主题词,评价词>二元组作为数据集进行训练,统计评价词出现在主题词周围4个字符以内位置的频率;利用标注好表情符号位置信息的评论作为数据集进行训练,统计情感词出现在表情符号周围4个字符以内的频率;
步骤2.2:设置长度为4个字符的滑动窗口来获取不同词性词语、主题词以及表情符号周围4个字符以内的词语,并加入候选词集合。
步骤2.3:根据不同特征,依据它们的出现频率所占比例为每个词语分别设置概率值;
步骤2.4:对候选词集合中的每个词语的概率值进行综合计算,并按照从大到小排序,选择前30%的词语加入新情感词候选集合;
步骤3:将新情感词候选集合与现有情感词典对比后去重;
步骤4:采用同位关系匹配方法进行补充提取,即利用语法树来为情感词匹配具有同等地位的新词,从而发现其他的新情感词;
步骤4.1:对评论语句构建语法树,以语法树为特征,利用svm(支持向量机)来训练,从而自动获取文本对应语法树的结构化信息。
步骤4.2:通过计算两棵语法树t1和t2中相同子树的数目来衡量匹配度。匹配度的计算公式如下:
其中,v1和v2分别表示t1和t2的节点集合,△(v1,v2)表示为以v1和v2为根节点的树中相同子树的数量。
步骤4.3:若该新词所在的评论语句与某情感词的语句之间的匹配度达到阈值,则证明该词与情感词具有相同“地位”,即将该新词加入新情感词候选集合。
步骤5:将目前已经提取的候选新情感词按照词频从大到小排序,设置阈值,删掉频率小于阈值的词语;
步骤6:对已经提取的候选词进行细粒度筛选。结合“点互信息值”和“语料频数差”来筛选,二者值均为0时则删除,否则保留该新情感词;
步骤6.1:对当前新情感词候选集合中的词进行点互信息计算,即计算两个词语的语义相似度,值越大则关联度越大。计算公式如(1)和(2),这里p(word1&word2)表示两个词语同时出现的概率,p(word1)、p(word2)表示word1、word2单独出现的概率,pw为褒义基准词,nw为贬义基准词。
步骤6.2:对当前新情感词候选集合中的词进行语料频数计算,即计算该词在正向语料和负向语料中出现的频数差。计算公式如(3),这里fpos(word)表示词word在正向语料中出现的次数,fneg(word)表示词word在负向语料中出现的次数。
d(word)=fpos(word)-fneg(word)(3)
步骤6.3:若该点互信息值so_pmi(word)等于0,则说明该候选词与情感词没有关联度,即不判定为情感词;若语料频数差值d(word)值为0,则证明它在正向语料中出现的次数与在负向语料中出现的次数相同,即不具有情感倾向性,故不判定为新情感词。若so_pmi(word)和d(word)均为0,则删除该词。
步骤7:与同义词词林做扩展,即找到与同义词词林中的词具有相同同义词的新词,则可认为这个新词也是新情感词;
步骤8:再次与现有情感词典进行对比去重。
本发明提供的基于商品评论的新情感词提取方法,其有益效果体现在:(1)本发明利用相邻词词性、主题词位置等特征来提取新情感词,且考虑到输入法联想的特点来根据表情符号位置特征发现情感词;(2)本发明利用语法树来发现具有同位关系的新情感词,具有很高的准确率,可以有效扩展新情感词的规模;(3)本发明利用点互信息值和语料频数法对所提取的新情感词候选集合做细粒度筛选,使得新情感词提取的判定更加合理。
附图说明
图1是本发明具体实施方式提供的新情感词提取方法数据流图。
图2是本发明具体实施方式提供的粗粒度提取方法流程图。
图3是本发明具体实施方式提供的同位关系匹配方法流程图。
图4是本发明具体实施方式提供的语法树结构对比图。
图5是本发明具体实施方式提供的细粒度筛选方法流程图。
图6是本发明说明书摘要提供的新情感词提取方法流程图。
具体实施方式
以下通过具体实施例对本发明提供的新情感词提取方法做进一步解释说明。
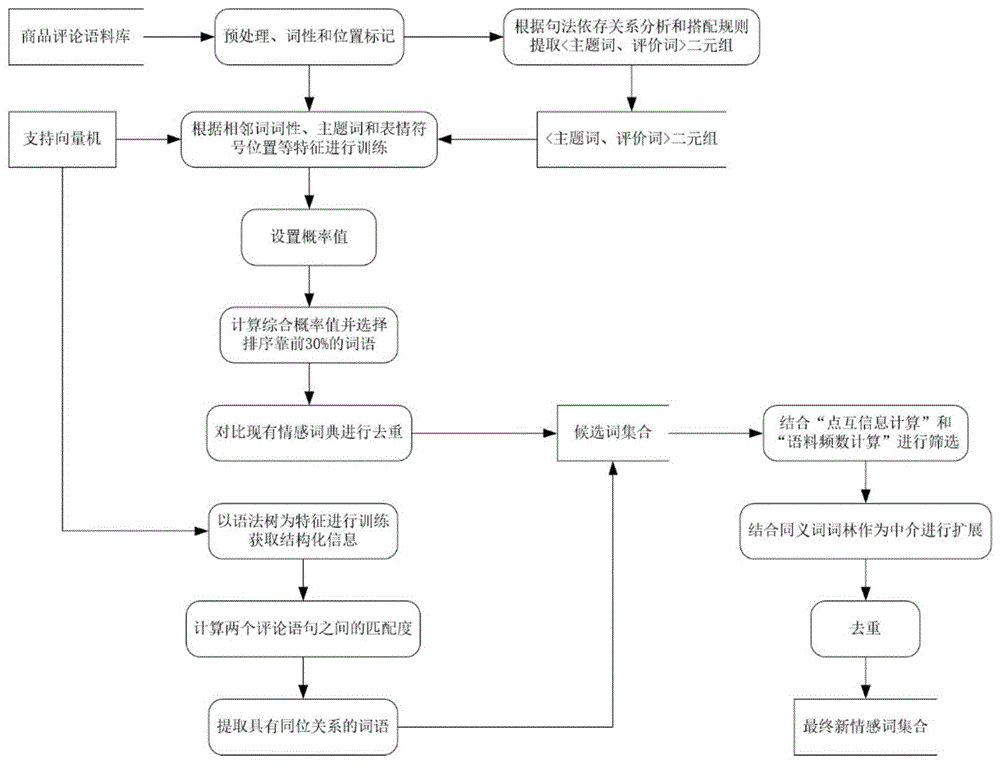
如图1所示,本发明提供的新情感词提取方法的流程图,步骤包括:
步骤1:建立商品评论语料并对其进行预处理。利用分词工具对语料中的每条评论进行分词以及词性、位置标记,并根据依存关系及词性搭配规则提取<主题词,评价词>二元组词对;
步骤1.1:通过爬虫从淘宝、京东等平台爬取商品评论数据,从而建立商品评论语料库;
步骤1.2:利用空格、标点符号和停用词对语料库中的每条评论进行分词,然后对语句进行规范化处理,比如:去除特殊字符、过滤停用词、错别字纠正、简繁体转换等。
步骤1.3:(利用哈工大ltp语言技术平台提供的词性标注)利用斯坦福句法分析器stanfordparser得到评论文本的词性标签和依存句法关系以及二元搭配抽取规则对每条评论提取<主题词,评价词>二元组,如表1和表2;
reln(gov,dep):reln()表示从属关系;gov表示核心词;dep表示从属词。
步骤2:对新词进行粗粒度提取。结合相邻词词性及位置、主题词和表情符号位置等特征统计旧情感词出现频率,再设置k=4的滑动窗口获取不同词性词语、主题词以及表情符号周围4个字符以内的词语。根据不同特征为候选词设置概率值,再进行概率综合计算,选择排序前30%的词作为候选新情感词;
步骤2.1:利用标注好词性和位置信息的评论作为数据集进行训练,统计情感词出现在不同词性词语周围4个字符以内的频率;利用步骤1中根据依存关系及搭配规则所提取的<主题词,评价词>二元组作为数据集进行训练,统计评价词出现在主题词周围4个字符以内位置的频率;利用标注好表情符号位置信息的评论作为数据集进行训练,统计情感词出现在表情符号周围4个字符以内的频率;
步骤2.2:设置长度为4个字符的滑动窗口来获取不同词性词语、主题词以及表情符号周围4个字符以内的词语,并加入候选词集合。
步骤2.3:根据不同特征,依据它们的出现频率所占比例为每个词语分别设置概率值;
例如,若统计出情感词出现在形容词、副词、名词、动词、代词、叹词、助词、介词等词性词语周围4个字符以内位置的频率分别占30%、20%、15%、10%、8%、5%、4%、2%,则为这八种词性位置周围4个字符以内的新词设置的概率值分别为:0.3、0.2、0.15、0.1、0.08、0.05、0.04、0.02。且在形容词、副词、名词、动词、代词、叹词、助词、介词等词性词语周围进行提取新词。若统计出情感词出现在主题词(包括商品名称和商品属性)周围4个字符以内位置的频率占30%,则为主题词周围4个字符以内的新词设置概率值:0.3。若统计出情感词出现在表情符号周围4个字符以内的频率占15%,则为表情符号周围4个字符以内的新词设置概率值为:0.15。
步骤2.4:对候选词集合中的每个词语的概率值进行综合计算,并按照从大到小排序,选择前30%的词语加入新情感词候选集合;
步骤3:将新情感词候选集合与现有情感词典对比后去重;
步骤4:采用同位关系匹配方法进行补充提取,即利用语法树来为情感词匹配具有同等地位的新词,从而发现其他的新情感词;
步骤4.1:对评论语句构建语法树,以语法树为特征,利用svm(支持向量机)来训练,从而自动获取评论文本对应语法树的结构化信息。
步骤4.2:通过计算两棵语法树t1和t2中相同子树的数目来衡量匹配度。匹配度的计算公式如下:
其中,v1和v2分别表示t1和t2的节点集合,△(v1,v2)表示为以v1和v2为根节点的树中相同子树的数量。
步骤4.3:若该新词所在的评论语句与某情感词的语句之间的匹配度达到阈值,则证明该词与情感词具有相同“地位”,即将该新词加入新情感词候选集合。
解释:因为语法树是句子结构的图形表达,有利于剖析句子的语法结构。如图4所示,若“这个味道很上头”与“这份礼物很精美”这两个语句对应的语法树之间的匹配度达到阈值,则证明“上头”与“精美”具有同等地位,则把“上头”加入新情感词候选集合。
步骤5:将目前已经提取的候选新情感词按照词频从大到小排序,设置阈值,删掉频率小于阈值的词语;
步骤6:对已经提取的候选词进行细粒度筛选。结合“点互信息值”和“语料频数差”来筛选,二者值均为0时则删除,否则保留该新情感词;
步骤6.1:对当前新情感词候选集合中的词进行点互信息计算,即计算两个词语的语义相似度,值越大则关联度越大。计算公式如(1)和(2),这里p(word1&word2)表示两个词语同时出现的概率,p(word1)、p(word2)表示word1、word2单独出现的概率,pw为褒义基准词,nw为贬义基准词。
步骤6.2:对当前新情感词候选集合中的词进行语料频数计算,即计算该词在正向语料和负向语料中出现的频数差。计算公式如(3),这里fpos(word)表示词word在正向语料中出现的次数,fneg(word)表示词word在负向语料中出现的次数。
d(word)=fpos(word)-fneg(word)(3)
步骤6.3:若该点互信息值so_pmi(word)等于0,则说明该候选词与情感词没有关联度,即不判定为情感词;若语料频数差值d(word)值为0,则证明它在正向语料中出现的次数与在负向语料中出现的次数相同,即不具有情感倾向性,故不判定为新情感词。若so_pmi(word)和d(word)均为0,则删除该词。
步骤7:与同义词词林做扩展,即找到与同义词词林中的词具有相同同义词的新词,则可认为这个新词也是新情感词;
例如:新词a和新词c均与同义词词林中的词b具有相同意义,但是新词c在前面的步骤中未被提取为新情感词,那么此时就将词c加入新情感词集合。
步骤8:再次与现有情感词典进行对比去重。
- 还没有人留言评论。精彩留言会获得点赞!