基于多模态商品评论分析的商品推荐方法及系统与流程
本公开涉及商品推荐技术领域,尤其涉及基于多模态商品评论分析的商品推荐方法及系统。
背景技术:
本部分的陈述仅仅是提到了与本公开相关的背景技术,并不必然构成现有技术。
在日常生活中,人类能够通过聆听语言和观察表情以及姿态动作等捕捉对方的情感变化,识别情感状态信息,进而进行情感交流。而如果想让机器能够像人一样的感知和理解情感,那么就必须让机器能够对人类这方面的能力进行模拟,进而让机器具有捕捉多模态的情感特征,并对其进行处理,最后表达出相应人类情感的能力。
在现实生活中,我们文字或者语言只是人的综合理解系统的一部分,用于理解和交流我们遇到的情景以及参与的对象。其中情景表征构成了我们的世界模型,并指导这我们的行为和对语言的理解,解决一个句子中代词的指代问题,可以从构建句子所描述的情景表示开始。情景可以是具体的和静态的,例如大妈在跳广场舞。当人们将文本的陈述与熟悉的场景联系起来,也就是文字和图片或者视频信息联系起来,机器就能更好地理解和记忆文本。正如人在交流的时候,会同时使用语言输入和非语言的输入。
在实现本公开的过程中,发明人发现现有技术中存在以下技术问题:
网上商城的商品评论对于商家运营决策是非常重要的,当一个商品的负面评论过多时,商家会考虑减少或停止售卖该商品,转而用一种评论比较好的商品代替,所以商品的评论分析,对于店家来说是非常重要的。现在人们在给商品评论的时候,写文字的越来越少,更多的人是使用视频或者图片加上少量的文字作为用户给这个商品的评价。因为之前的研究多是基于文本的,但是基于文本的评论分析,很难真正理解用户的意图,不能给商家一个正确的评论分析报告。
技术实现要素:
本公开的目的就是为了解决上述问题,提供基于多模态商品评论分析的商品推荐方法及系统,可以更好的利用商品评论中的视频、图片和文本信息,更好的理解用户评论的级别,本公开中我们设计了五种情感级别分别是-2,-1,0,1,2五种,正数代表积极情感,负数代表消极情感,数字越大情感级别越高,0代表中立,使用图像和自然语言深度学习技术,分析评论的情感,并将图像和自然语言处理的两个深度学习模型的分析,综合考虑,得到一个最终的对评论的评级。
为了实现上述目的,本公开采用如下技术方案:
第一方面,本公开提供了基于多模态商品评论分析的商品推荐方法;
基于多模态商品评论分析的商品推荐方法,包括:
获取某商品的评论信息;
对获取的商品的评论信息进行数据预处理;
判断评论信息中是否有图像,如果有图像,则对图像提取图像的情感标签;
判断评论信息中是否有视频,如果有视频,则将视频中的音频提取出来,将音频转换为文本;如果没有视频,则进入下一步;
判断评论信息中是否有音频,如果有音频,则将音频转换为文本;如果没有音频,则进入下一步;
判断评论信息中是否有文本,如果有文本,则将评论信息中的文本与转换得到的文本进行整合,得到整合后的文本;如果没有文本,则返回商品的评论信息获取步骤;
对整合后的文本,提取文本的情感标签;
根据图像的情感标签和文本的情感标签,提取当前商品的推荐标签。
第二方面,本公开提供了基于多模态商品评论分析的商品推荐系统;
基于多模态商品评论分析的商品推荐系统,包括:
获取模块,其被配置为:获取某商品的评论信息;
预处理模块,其被配置为:对获取的商品的评论信息进行数据预处理;
判断模块,其被配置为:判断评论信息中是否有图像,如果有图像,则对图像提取图像的情感标签;
判断评论信息中是否有视频,如果有视频,则将视频中的音频提取出来,将音频转换为文本;如果没有视频,则进入下一步;
判断评论信息中是否有音频,如果有音频,则将音频转换为文本;如果没有音频,则进入下一步;
判断评论信息中是否有文本,如果有文本,则将评论信息中的文本与转换得到的文本进行整合,得到整合后的文本;如果没有文本,则返回获取模块;
提取模块,其被配置为:对整合后的文本,提取文本的情感标签;
输出模块,其被配置为:根据图像的情感标签和文本的情感标签,提取当前商品的推荐标签。
第三方面,本公开还提供了一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成第一方面所述方法的步骤。
第四方面,本公开还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述方法的步骤。
本公开的有益效果:
1本公开能够自动获取商品评论信息,使用多模态信息分析的技术,对评论信息进行分析,获取用户情感。
2本公开相比于传统的评论分析的方式相比,使用到评论中更多的信息,让用户更好的进行分析。
3本公开相比于传统的只分析评论文本的系统来说,本公开的效果更好,提供的报告更加准确。
附图说明
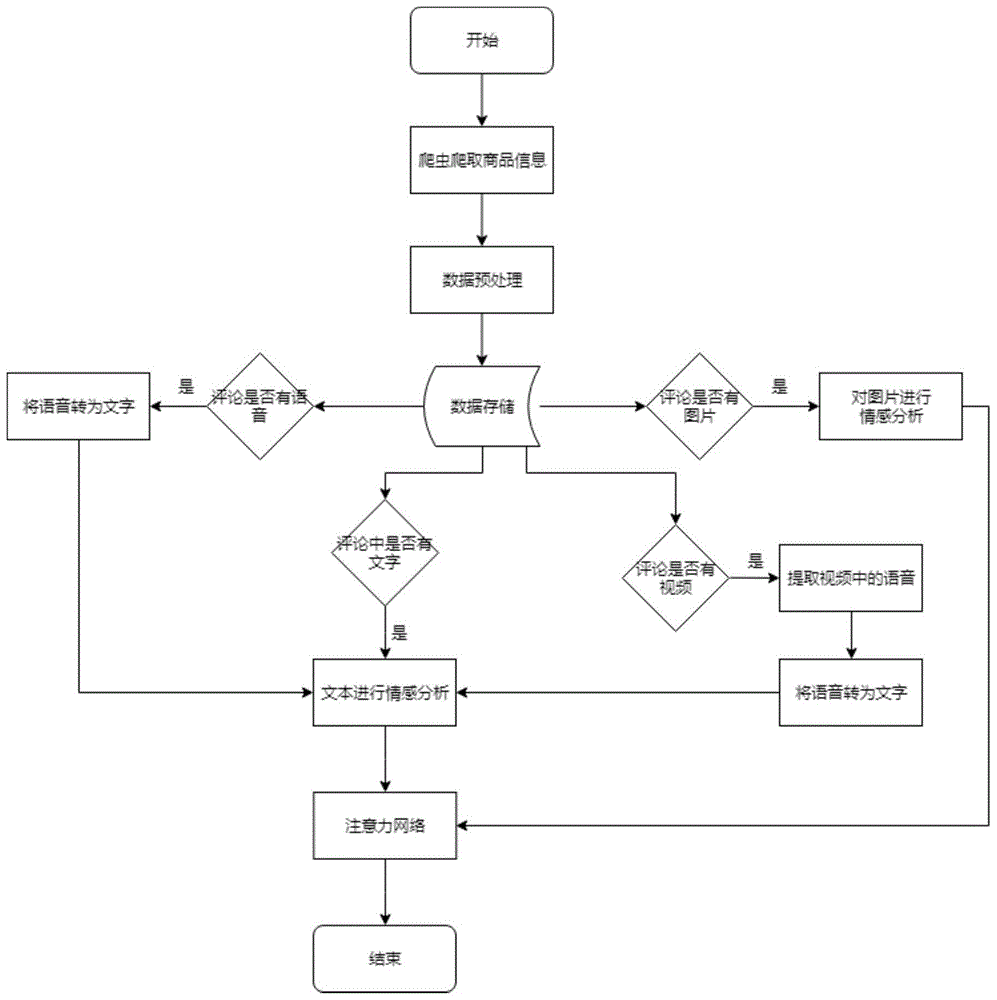
图1为本公开实施例一的基于多模态商品评论分析的店家辅助决策方法的流程图。
图2为本公开实施例一的bert+crf模型结构示意图;
图3为本公开实施例一的birnn结构示意图。
具体实施方式
下面结合附图与实施例对本公开作进一步说明。
实施例一,本实施例提供了基于多模态商品评论分析的商品推荐方法;
如图1所示,基于多模态商品评论分析的商品推荐方法,包括:
s1:获取某商品的评论信息;
s2:对获取的商品的评论信息进行数据预处理;
s3:判断评论信息中是否有图像,如果有图像,则对图像提取图像的情感标签;
判断评论信息中是否有视频,如果有视频,则将视频中的音频提取出来,将音频转换为文本;如果没有视频,则进入下一步;
判断评论信息中是否有音频,如果有音频,则将音频转换为文本;如果没有音频,则进入下一步;
判断评论信息中是否有文本,如果有文本,则将评论信息中的文本与转换得到的文本进行整合,得到整合后的文本;如果没有文本,则返回s1;
s4:对整合后的文本,提取文本的情感标签;
s5:根据图像的情感标签和文本的情感标签,提取当前商品的推荐标签。
作为一个或多个实施例,所述s1中,获取某商品的评论信息,是通过爬虫爬取网页上商品的评论信息。
应理解的,所述s1中,使用scrapy爬虫框架,模拟用户登录淘宝页面进行数据爬取,爬取包括商品名称,商品详细信息,商品类别,商品评论和评论时间。为了避免网页反爬虫机制,设置网络代理定期更新ip,并设置爬虫随机休眠时间。
应理解的,所述s1中,采用mongodb数据库进行存储,mongodb是一个高性能,开源,无模式的文档型数据库,适合实时的插入、更新与查询。存储商品名称,商品详细信息,商品类别,商品评论和评论时间。
作为一个或多个实施例,所述s2中,对获取的商品的评论信息进行数据预处理,包括:对评论信息中的图像进行数据预处理、对评论信息中的音频进行数据预处理、对评论信息中的视频进行数据预处理和对评论信息中的文本进行数据预处理。
应理解的,所述对评论信息中的文本进行数据预处理,具体步骤为:对于收集到的文本数据,采用jieba分词进行语句词语的切分。jieba分词是python的一款中文分词工具,对于一长段文字,其分词原理大体可分为三步:首先用正则表达式将中文段落粗略的分成一个个句子;然后将每个句子构造成有向无环图(dag),之后寻找最佳切分方案;最后对于连续的单字,采用隐马尔可夫模型(hmm模型)将其再次划分。例如,对于文本“我来到北京清华大学”,采用默认分词模式,切分为“我”“来到”“北京”“清华大学”。在采用jieba分词的过程中,我们预设停用词库,针对评论文本,我们将其中的表情符号,如“(^_^)”以及笑脸符号和一些阿拉伯字母、数字等加入停用词库,删除此类信息对于评论文本的影响。
应理解的,所述对评论信息中的图像进行数据预处理,具体步骤为:首先将评论中图片数据提取出来,删除清晰度低于设定阈值的图片,采用brenner梯度函数计算图片清晰度,并按照设定阈值删除低于阈值的图片。brenner梯度函数计算的是相邻两个像素灰度差的平方。
应理解的,所述对评论信息中的视频进行数据预处理,具体步骤为:使用opencv中videocapture类,python视频编辑库moviepy进行裁剪、拼接、标题插入、视频合成、视频处理和自定义效果,使用opencv获取视频的音频数据。
应理解的,所述对评论信息中的音频进行数据预处理,具体步骤为:使用python视频编辑库的speechrecognition模块,将语音转为文字。speechrecognition模块,不仅包含了ibm的语音识别api,还有微软、谷歌的语音识别api等等。使用该模块调用相应的api,来将语音转为文字。转为文字之后,采用jieba分词进行语句词语的切分,对转化的文字进行预处理。
作为一个或多个实施例,所述s3中,对图像提取图像的情感标签;具体步骤包括:
s301:构建卷积神经网络vgg16;
s302:利用imagenet图片数据库对卷积神经网络vgg16进行预训练;
s303:将已知情感标签的评论图像,输入到预训练后的卷积神经网络vgg16中,对卷积神经网络vgg16进行优化训练,得到优化训练后的卷积神经网络vgg16;
s304:将待特征提取的图像,输入到优化训练后的卷积神经网络vgg16中,输出图像的情感标签。
应理解的,首先在imagenet图片数据库中使用vgg16network神经网络进行预训练,设置隐藏层设置为5层,每层为全连接网络,神经元个数设置为200,一层sigmoid层,使用relu函数,一层softmax层,输出设置为5维,分别对应评论情感的5个类别。将训练好的神经网络模型保存下来。其中imagenet是一个计算机视觉系统识别项目名称,是目前世界上图像识别最大的数据库,imagenet能够从图片识别物体,被用来完成一些图像识别领域的监督学习模型训练。
基于迁移学习的思想,使用训练好的vgg16network神经网络,然后使用预处理好的带有情感标签的评论图片数据继续训练vgg16network神经网络,优化模型权重参数,使其更加适应评论情感预测任务。待vgg16network神经网络优化后,针对用户的评论图片,使用优化后的vgg16network神经网络提取其vgg16network神经网络中第三层隐藏层的输出作为图片特征fp,此处fp为200维。
作为一个或多个实施例,所述s3中,判断评论信息中是否有视频,如果有视频,则将视频中的音频提取出来;具体步骤包括:
使用opencv中videocapture类和python视频编辑库moviepy库,裁剪、拼接、标题插入、视频合成、视频处理和自定义效果,使用opencv获取视频的音频数据,然后将音频数据存储到数据库中。
作为一个或多个实施例,所述s3中,将音频转换为文本,具体步骤包括:
使用python视频编辑库的speechrecognition模块,来将语音转为文字。python视频编辑库的speechrecognition模块,不仅包含了ibm的语音识别api,还有微软、谷歌的语音识别api等等。我们使用该模块调用相应的api,来将视频转化后的语音和评论中原始语音转为文字。
作为一个或多个实施例,所述s4中,对整合后的文本,提取文本的情感标签;具体步骤包括:
s401:使用训练好的bert+crf模型对整合后的文本进行情感方面的识别,识别出文本评论中的表示情感方面的单词;具体结构图2所示;
s402:统计表示情感方面单词的上下文信息,上下文信息映射到一个向量中;
s403:将映射得到的向量,输入到预训练的gru模型中,输出整合后文本对应的情感标签。
进一步地,s401中,使用训练好的bert+crf模型对整合后的文本进行情感方面的识别;其中,训练好的bert+crf模型的训练过程中,对训练文本每个词进行标记,每个词中每个字被标记b、i或o标签,其中,b表示情感词的开始,i表示情感词除了第一字的其余部分,o表示非情感词。
bert+crf模型,包括:依次连接的输入端、bert模型、crf模型和输出端。
进一步地,s402中,统计表示情感方面单词的上下文信息,是利用训练好的birnn模型来统计表示情感方面单词的上下文信息。
birnn训练的过程中,训练文本为已知上下文信息的情感方面的单词。
birnn模型,如图3所示。
进一步地,所述预训练的gru模型,是利用已知情感标签的向量进行训练得到的。
作为一个或多个实施例,所述s5中,根据图像的情感标签和文本的情感标签,提取当前商品的推荐标签,是利用注意力网络来提取当前商品的推荐标签。
其中,注意力网络为注意力网络attentionnetwork。
作为一个或多个实施例,注意力网络的预训练过程包括:
构建注意力网络;
构建训练集;所述训练集,包括已知推荐标签的商品的文本情感标签和图像情感标签;
将训练集输入到注意力网络中,对注意力网络进行训练,得到训练好的注意力网络。
进一步地,所述推荐标签,包括:自定义的数字“-2、-1、0、1和2”负数表示不推荐,正数表示推荐,0表示中立,数字的大小表示推荐的程度。
将图像的情感标签和文本的情感标签,输入到注意力网络中,然后输入到一个全连接层,全连接层的输出为5维向量。使用softmax层计算每个情感分类的概率,然后选取概率最大的作为该评论的情感类别。
实施例二,本实施例提供了基于多模态商品评论分析的商品推荐系统;
基于多模态商品评论分析的商品推荐系统,包括:
获取模块,其被配置为:获取某商品的评论信息;
预处理模块,其被配置为:对获取的商品的评论信息进行数据预处理;
判断模块,其被配置为:判断评论信息中是否有图像,如果有图像,则对图像提取图像的情感标签;
判断评论信息中是否有视频,如果有视频,则将视频中的音频提取出来,将音频转换为文本;如果没有视频,则进入下一步;
判断评论信息中是否有音频,如果有音频,则将音频转换为文本;如果没有音频,则进入下一步;
判断评论信息中是否有文本,如果有文本,则将评论信息中的文本与转换得到的文本进行整合,得到整合后的文本;如果没有文本,则返回获取模块;
提取模块,其被配置为:对整合后的文本,提取文本的情感标签;
输出模块,其被配置为:根据图像的情感标签和文本的情感标签,提取当前商品的推荐标签。
实施例三,本实施例还提供了一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成实施例一所述方法的步骤。
实施例四,本实施例还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成实施例一所述方法的步骤。
上述虽然结合附图对本公开的具体实施方式进行了描述,但并非对本公开保护范围的限制,所属领域技术人员应该明白,在本公开的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本公开的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!